
10 Most Common (and Must-Know) Loss Functions in ML
...depicted in a single frame.
FREE 3-Day Object Detection Challenge
⭐️ Build your own object detection model from start to finish!
Hey friends! Lately, I have been in touch with Data-Driven Science. They offer self-paced and hands-on learning on practical data science challenges.
A 3-day object detection challenge is available for free. Here, you’ll get to train an end-to-end ML model for object detection using computer vision techniques.

The challenge is guided, meaning you don’t need any prior expertise. Instead, you will learn as you follow the challenge.
Also, you’ll get to apply many of my previous tips around Image Augmentation, Run-time optimization, and more.
All-in-all, it will be an awesome learning experience.
👉 Register for the challenge here: https://datadrivenscience.com/free-object-detection-challenge/.
Let’s get to today’s post now.
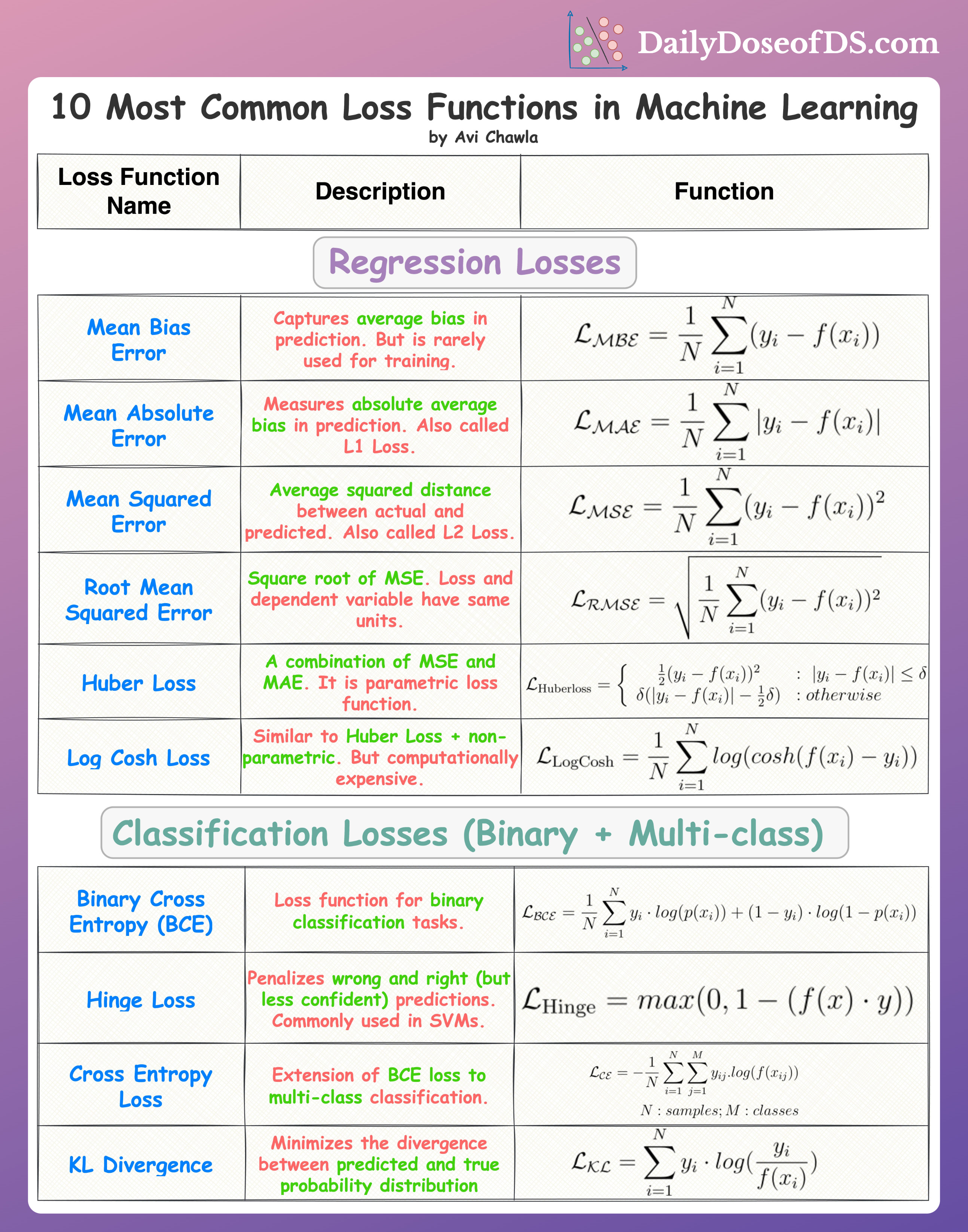
Loss functions are a key component of ML algorithms.
They specify the objective an algorithm should aim to optimize during its training. In other words, loss functions tell the algorithm what it should be trying to minimize or maximize in order to improve its performance.
Therefore, knowing about the most common loss functions in machine learning is extremely crucial.
The above visual depicts the most commonly used loss functions for regression and classification tasks.
Regression
Mean Bias Error

Captures the average bias in the prediction.
However, it is rarely used in training ML models.
This is because negative errors may cancel positive errors—leading to zero loss and consequently, no weight updates.
Mean Bias Error is foundational to the more advanced regression losses discussed below.
Mean Absolute Error

Measures the average absolute difference between predicted and actual value.
Also called L1 Loss.
Positive errors and negative errors don’t cancel out.
One caveat is that small errors are as important as big ones. Thus, the magnitude of the gradient is independent of error size.
Mean Squared Error
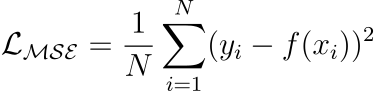
Measures the squared difference between predicted and actual value.
Also called L2 Loss.
Larger errors contribute more significantly than smaller errors.
The above point may also be a caveat as it is sensitive to outliers.
Root Mean Squared Error

Mean Squared Error with a square root.
Loss and the dependent variable (y) have the same units.
Huber Loss

It is a combination of Mean Absolute Error and Mean Squared Error.
For smaller errors → Mean Squared Error.
For larger errors → Mean Absolute Error.
Offers advantages of both.
For smaller errors, mean squared error is used, which is differentiable through (unlike MAE, which is non-differentiable at
x=0).For smaller errors, mean absolute error is used, which is less sensitive to outliers.
One caveat is that it is parameterized—adding another hyperparameter to the list.
Log Cosh Loss

For small errors, log cash loss is approximately:
\(\frac{x^{2}}{2}\)For large errors, log cash loss is approximately:
\(|x| - log(2)\)Thus, it is very similar to Huber loss.
Also, it is non-parametric.
The only caveat is that it is a bit computationally expensive.






Classification
Binary Cross Entropy (BCE)

A loss function used for binary classification tasks.
Measures the dissimilarity between predicted probabilities and true binary labels, through the logarithmic loss.
Hinge Loss

Penalizes both wrong and right (but less confident) predictions).
It is based on the concept of margin, which represents the distance between a data point and the decision boundary.
The larger the margin, the more confident the classifier is about its prediction.
Particularly used to train Support Vector Machines (SVMs).
Cross-Entropy Loss

An extension of Binary Cross Entropy loss to multi-class classification tasks.
KL Divergence

It minimizes the divergence between predicted and true probability distribution.
For classification, using KL divergence is the same as minimizing cross entropy.
Thus, it is recommended to use cross-entropy loss because of the ease of computation.
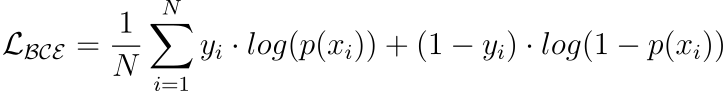

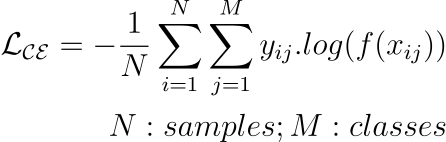

👉 Over to you: What other common loss functions have I missed?
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.