
11 Types of Variables in a Dataset
Beyond features, targets, etc.

Your natural language browser automation tool
Stagehand bridges the gap between fully agentic workflows and hardcoded automation by letting you control browsers with simple natural language commands.

Stagehand was used to test different LLM models (like Gemini, GPT, Claude, etc.) on their ability to perform specific browser automation tasks.
See the results for yourself and use Stagehand for free, fully open source, today.
Thanks to Browserbase for partnering today!
11 Types of Variables in a Dataset
In any tabular dataset, we typically categorize the columns as either a feature or a target.
However, there are so many variables that one may find/define in their dataset, as shown below:
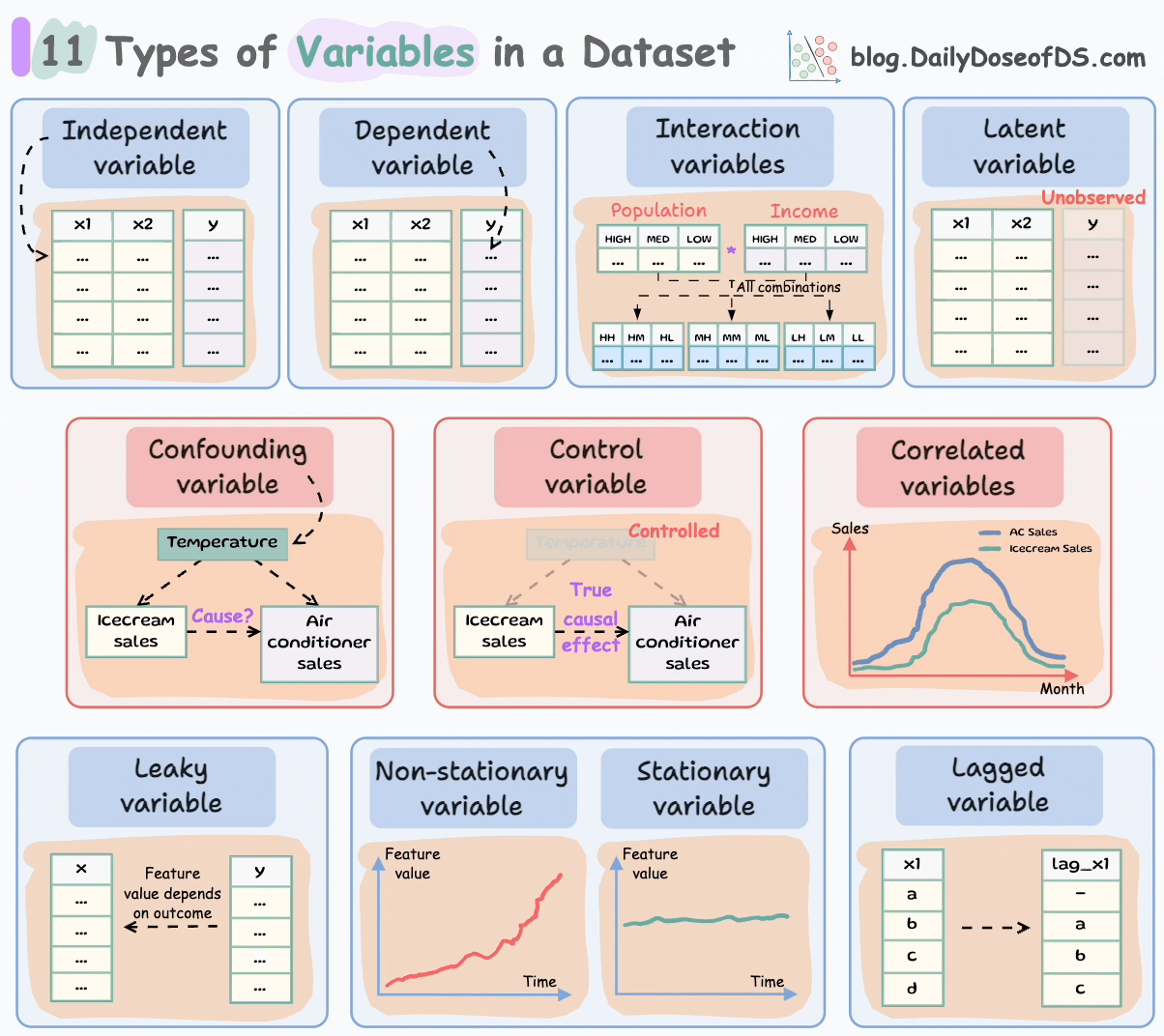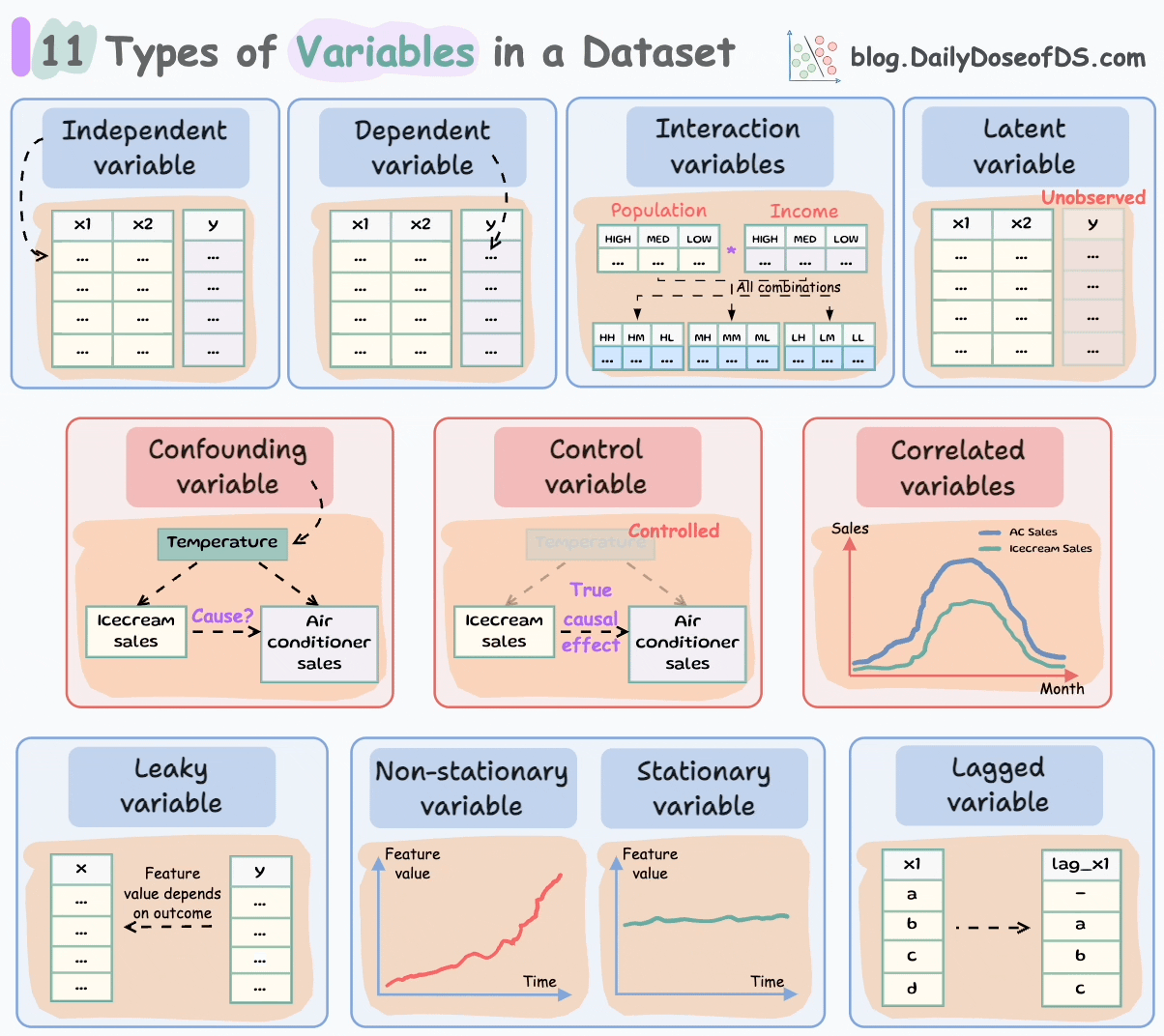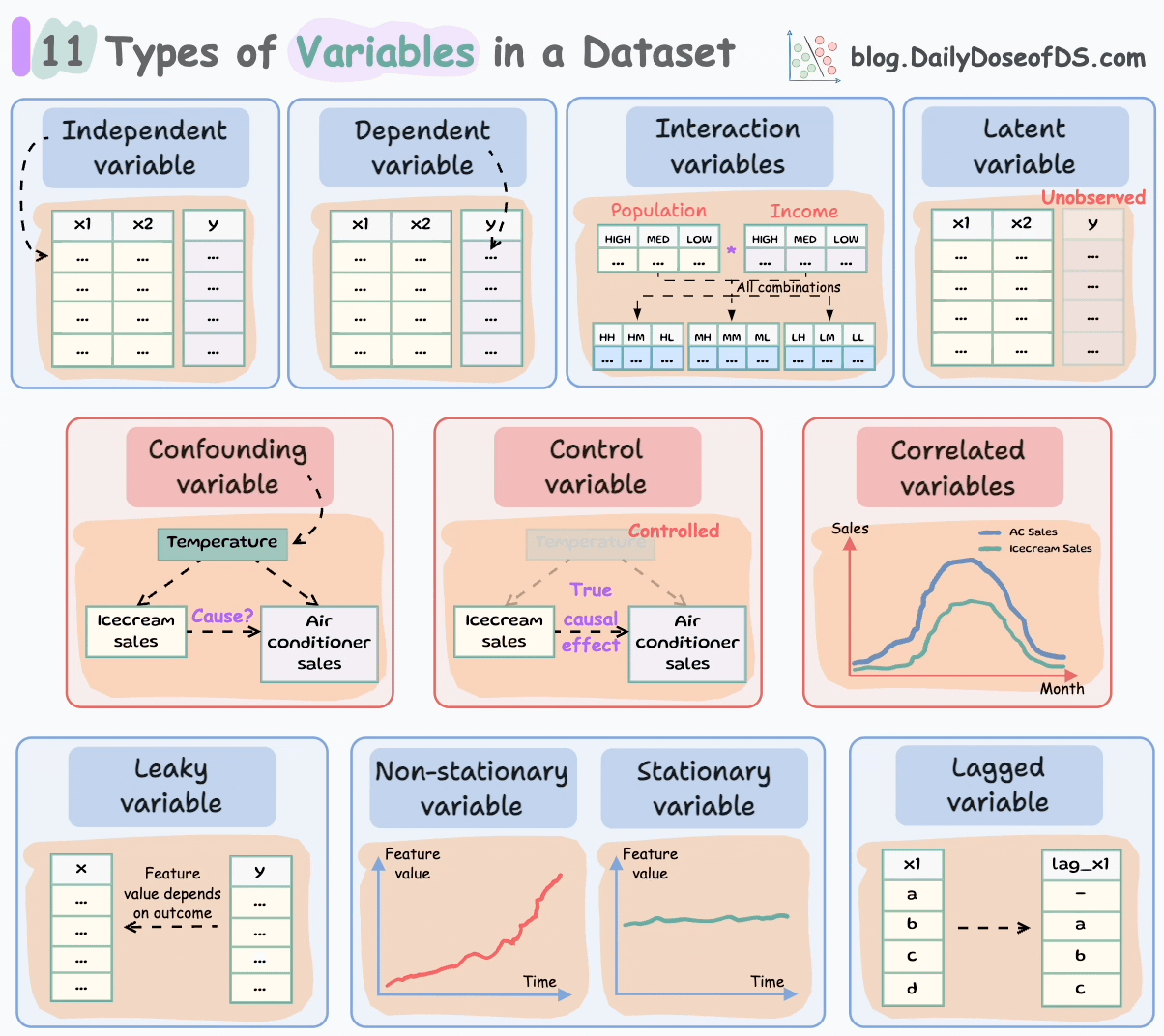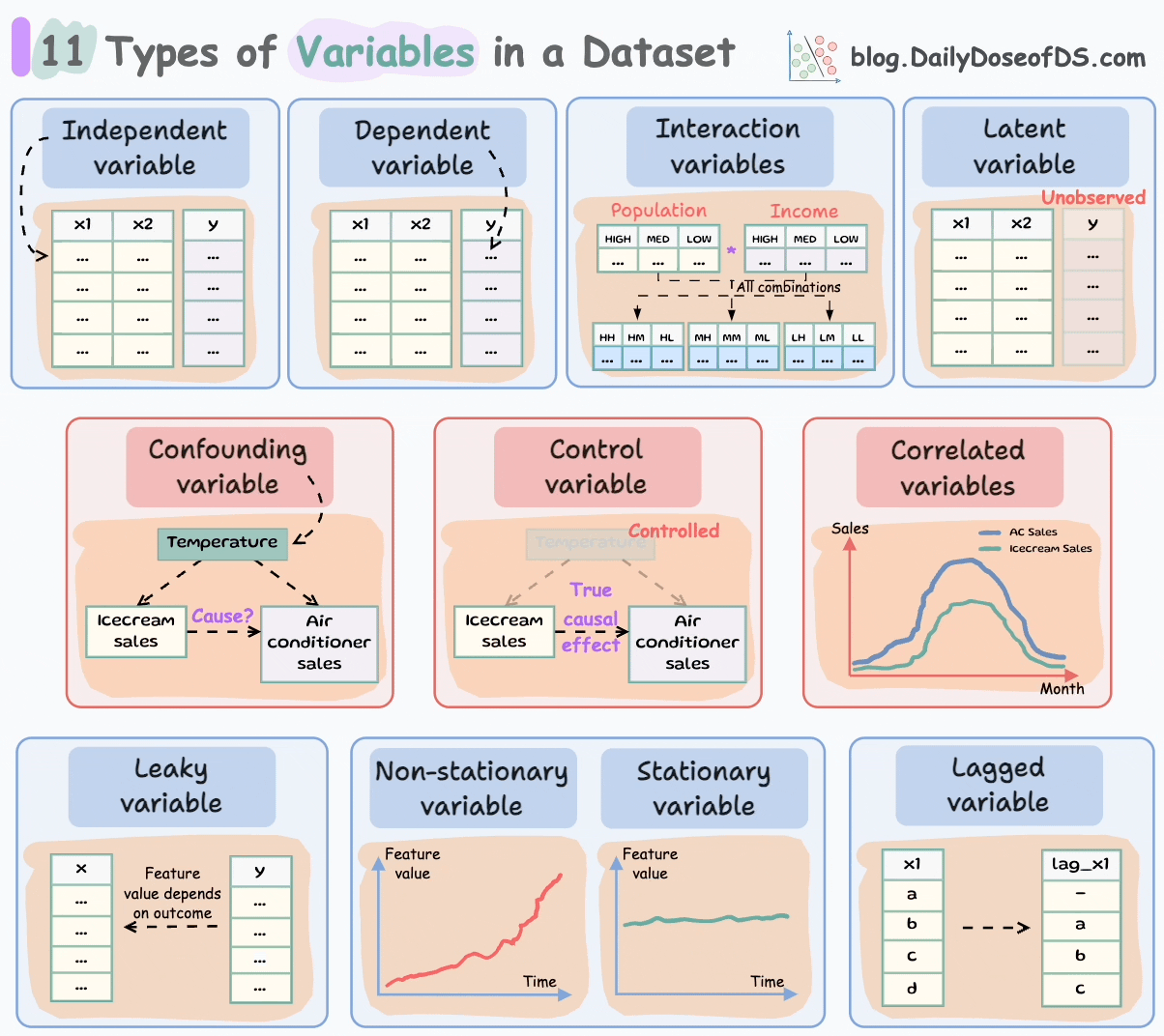
Let’s understand today!
#1-2) Independent and dependent variables
Independent variables are the features that are used as input to predict the outcome. They are also referred to as predictors/features/explanatory variables.
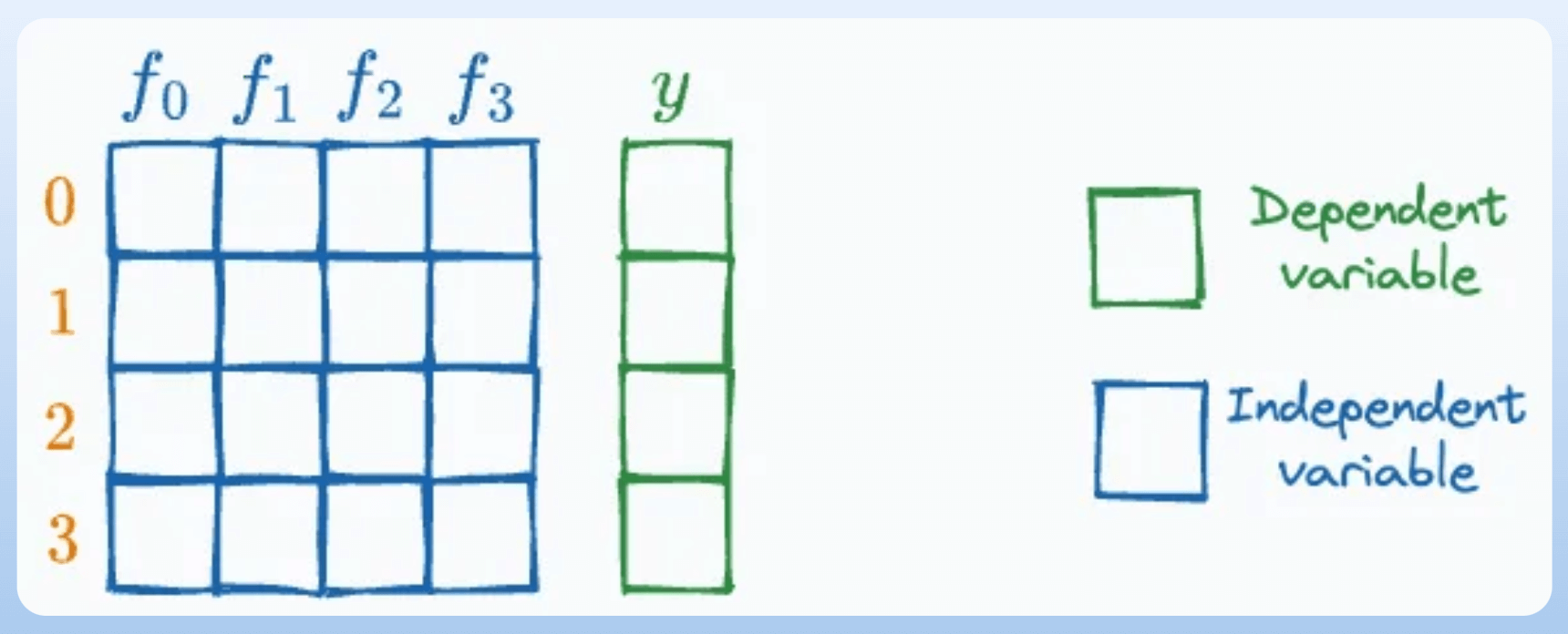
The dependent variable is the outcome that is being predicted. It is also called the target, response, or output variable.
#3-4) Confounding and correlated variables
Confounding variables are usually found in a cause-and-effect study (causal inference).
These are not always of primary interest, but can lead to weird associations if not handled correctly.
Say we want to measure the effect of ice cream sales on the sales of air conditioners, both of which are highly correlated:

However, there’s a confounding variable—temperature, which influences both ice cream sales and the sales of air conditioners.
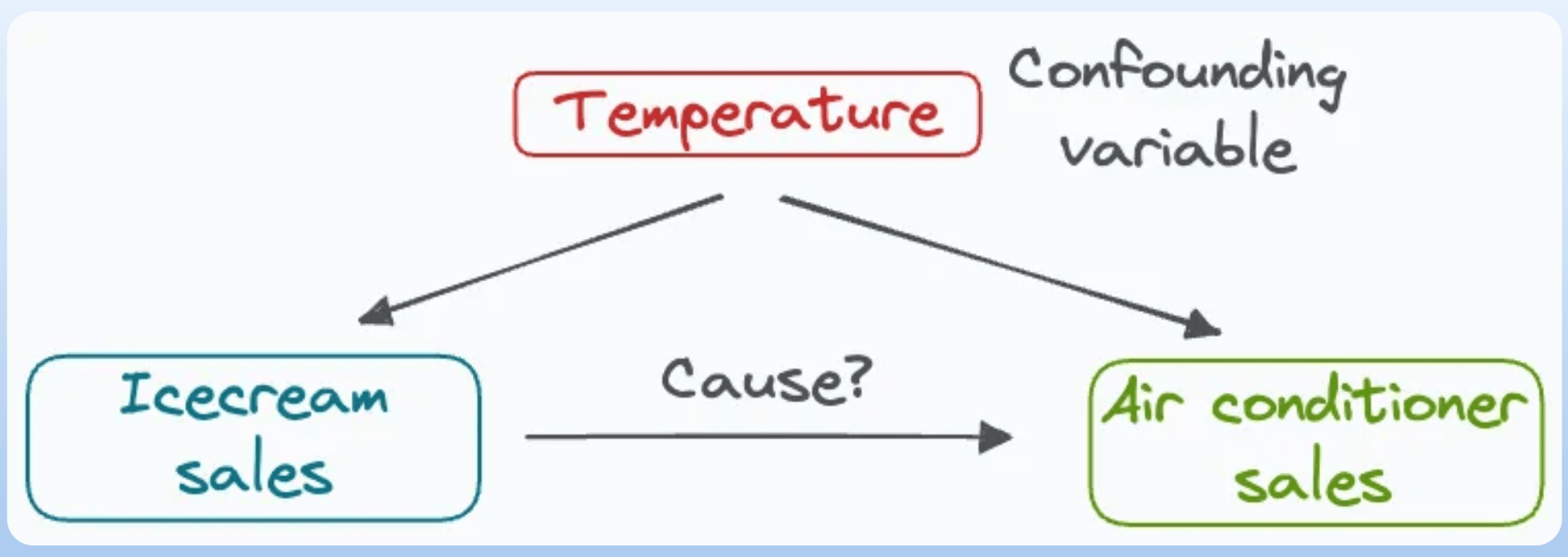
To study the actual causal impact, one must consider the confounder (temperature). Otherwise, the study will produce misleading results.
It is due to the confounding variables that we say, “Correlation does not imply causation.”
We did a crash course on Causal inference some time back:
#5) Control variables
In the above example, we must ensure that the temperature is controlled to measure the true effect of ice cream sales on AC sales.

Once controlled, temperature becomes a control variable.
These variables are not the primary focus of the study, but are crucial to account for. This ensures that the effect we intend to measure is not biased or confounded by other factors.
#6) Latent variables
A variable that is not directly observed but is inferred from other observed variables.
For instance, there is no true label in clustering—it is a latent variable.
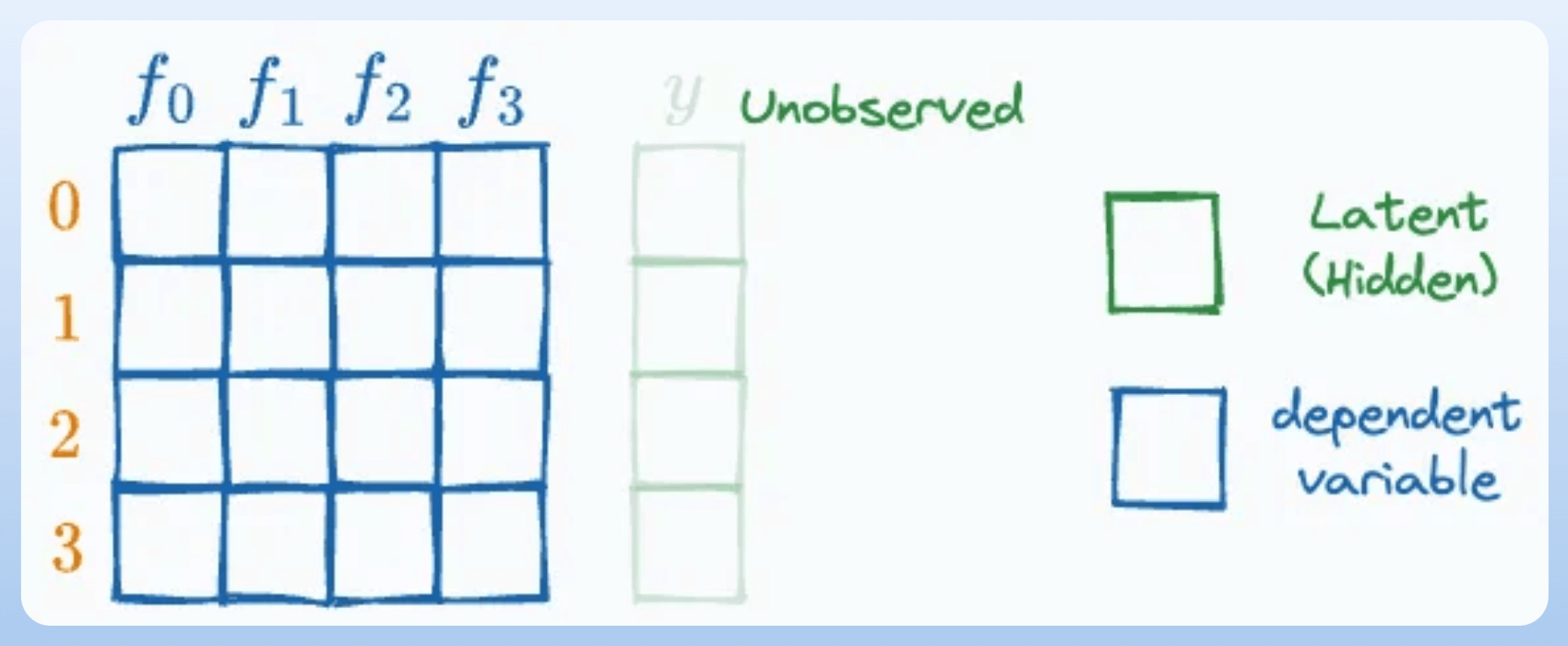
We also learned about Latent variables when we implemented Gaussian mixture models from scratch.
#7) Interaction variables
They measure the interaction effect between two or more variables and are often used in regression analysis.
For instance, if you have two variables:
Population density → HIGH, MEDIUM, and LOW (one-hot encoded).
Income levels → HIGH, MEDIUM, and LOW (one-hot encoded).

You can multiply them to get interaction variables, which will produce 9 interaction variables. Studying them will likely produce better insights.
#8-9) Stationary and Non-Stationary variables:
Stationary variables are those whose statistical properties (mean, variance) DO NOT change over time.
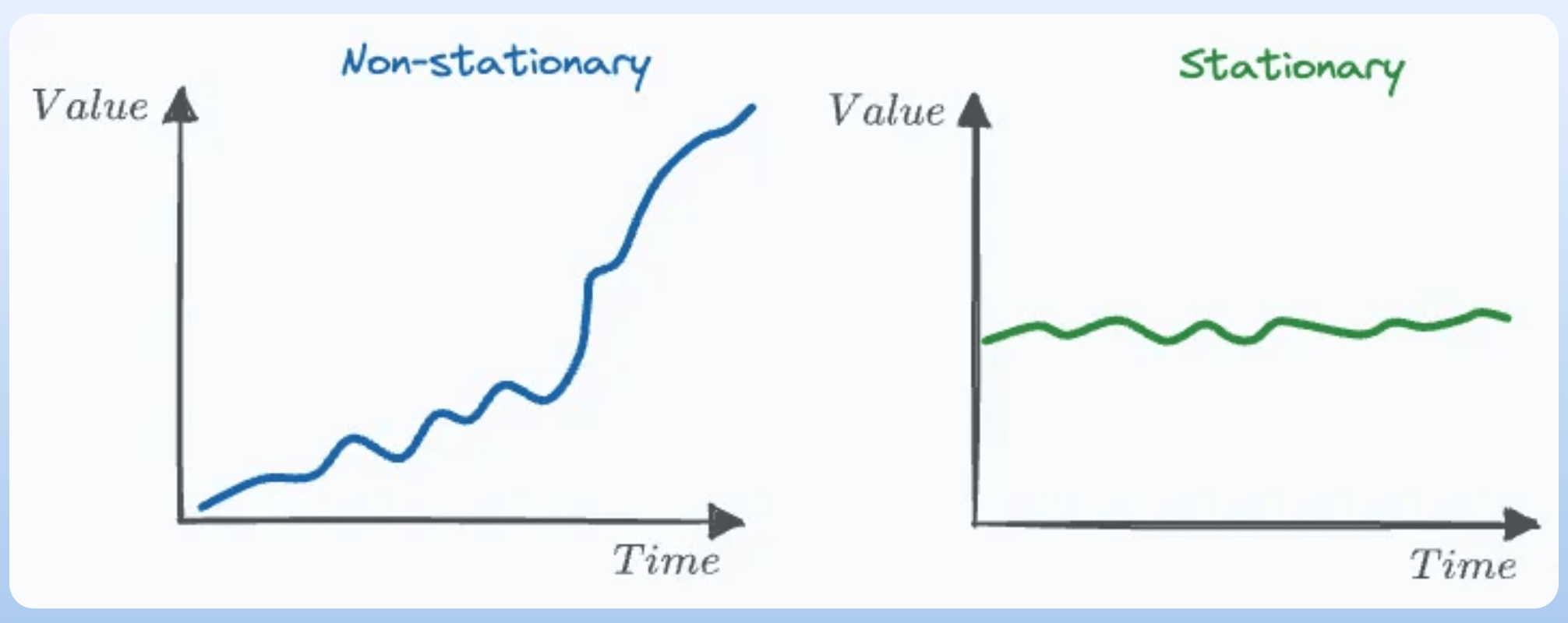
If it does, the variable is called a non-stationary variable.
Preserving stationarity is critical in statistical learning because these models assume samples are identically distributed. That is why using direct values of the non-stationary feature (like stock price) is not recommended.
Instead, it is better to define features in terms of relative changes:
#10) Lagged variables
A lagged variable represents previous time points’ values of a given variable:

For instance, when predicting next month’s sales figures, we might include the sales figures from the previous month as a lagged variable.
Lagged features may include:
7-day lag on website traffic to predict current website traffic.
30-day lag on stock prices to predict the next month’s closing prices.
And so on…
#11) Leaky variables
These variables provide information about the target variable that would not be available during prediction.
This leads to overly optimistic model performance during training but fails to generalize to new data.
For instance, creating forward-lag features leads to a leaky variable:
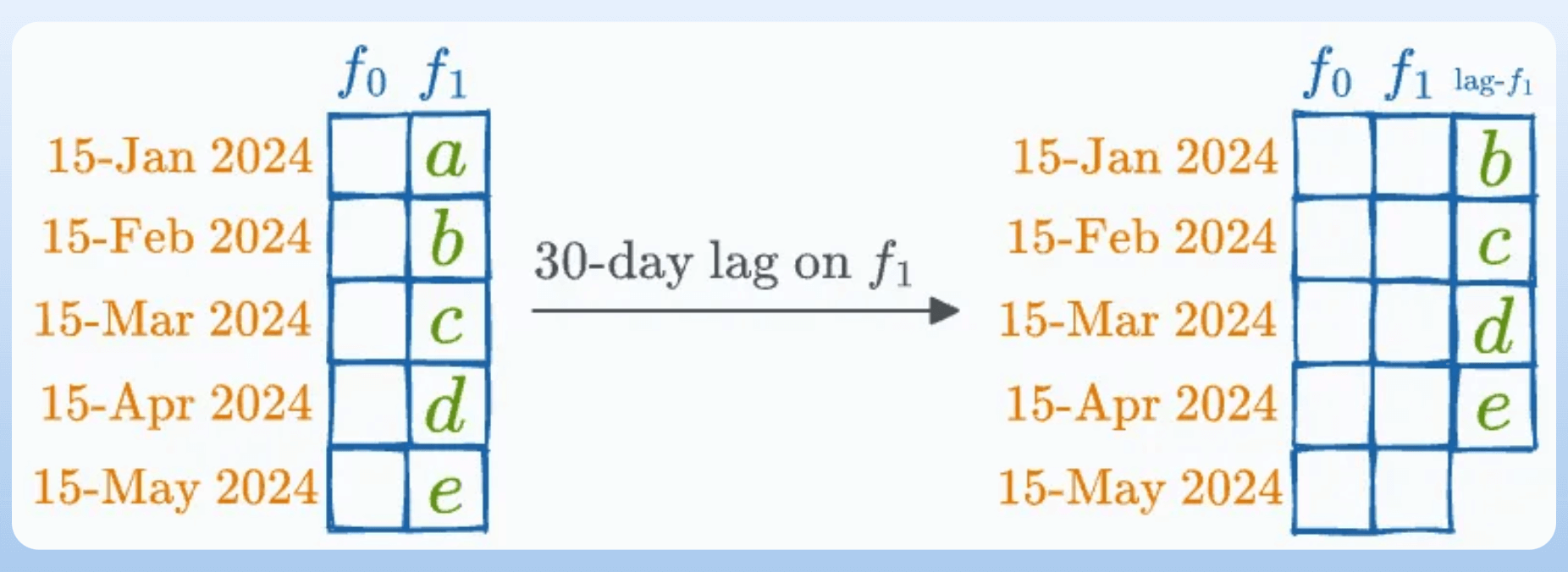
That’s a wrap!
Over to you: Have we missed any variable types?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in an ongoing crash course with 11 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data in this crash course.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.