
15 Techniques to Optimize Neural Network Training
...explained in a single frame.

In today's newsletter:
The ultimate Python framework for multimodal AI
15 techniques to optimize neural network training.
Fine-tuning, Transfer, Multitask & Federated Learning, explained visually.
The ultimate Python framework for multimodal AI

Data pipelines eat 90% of AI development time. They take weeks to deploy but can break in minutes when requirements change.
And it gets even worse when your data is multimodal.
Pixeltable is a framework that handles the entire multimodal pipeline (images, videos, audio, docs & structured data), from data storage to model execution.
It seamlessly manages images, videos, text, and tabular data—all in one place.
Fully open-source.
GitHub repo → (don’t forget to star)
15 techniques to optimize neural network training
Here are 15 ways we could recall in 2 minutes to optimize neural network training:

Some of them are pretty basic and obvious, like:
Use efficient optimizers: AdamW, Adam, etc.
Utilize hardware accelerators (GPUs/TPUs).
Max out the batch size.
Here are other methods with more context:
On a side note, we implemented all these techniques here →
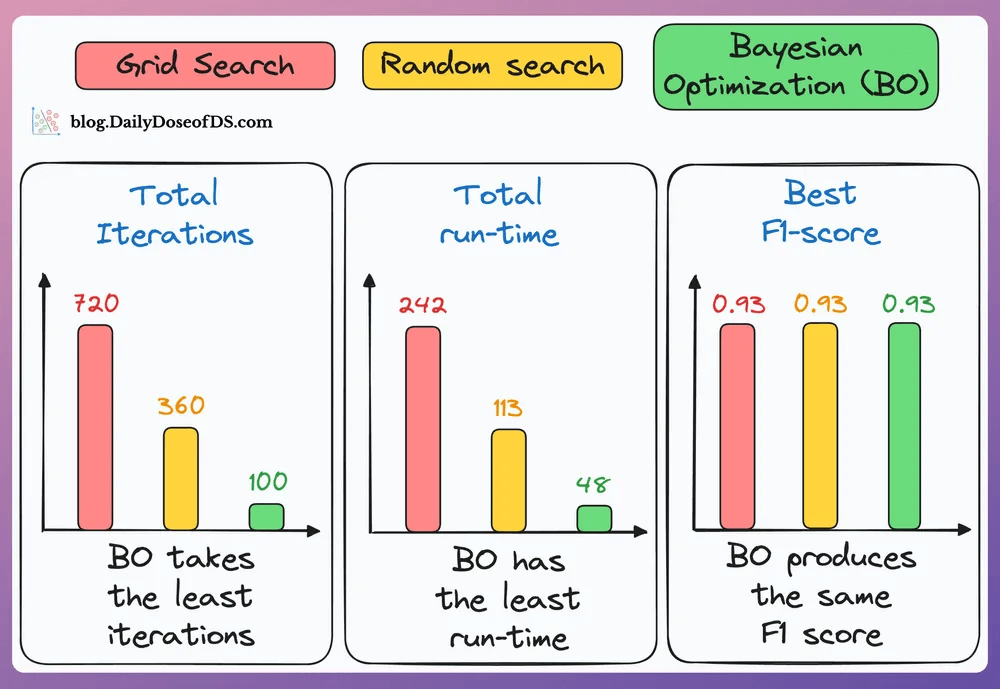
#4) Use Bayesian Optimization if the hyperparameter search space is big:
Take informed steps using the results of previous hyperparameter configs.
This lets it discard non-optimal configs, and the model converges faster.
As shown in the results below, Bayesian optimization (green bar) takes the least number of iterations, consumes the lowest time, and still finds the configuration with the best F1 score:

#5) Use mixed precision training:
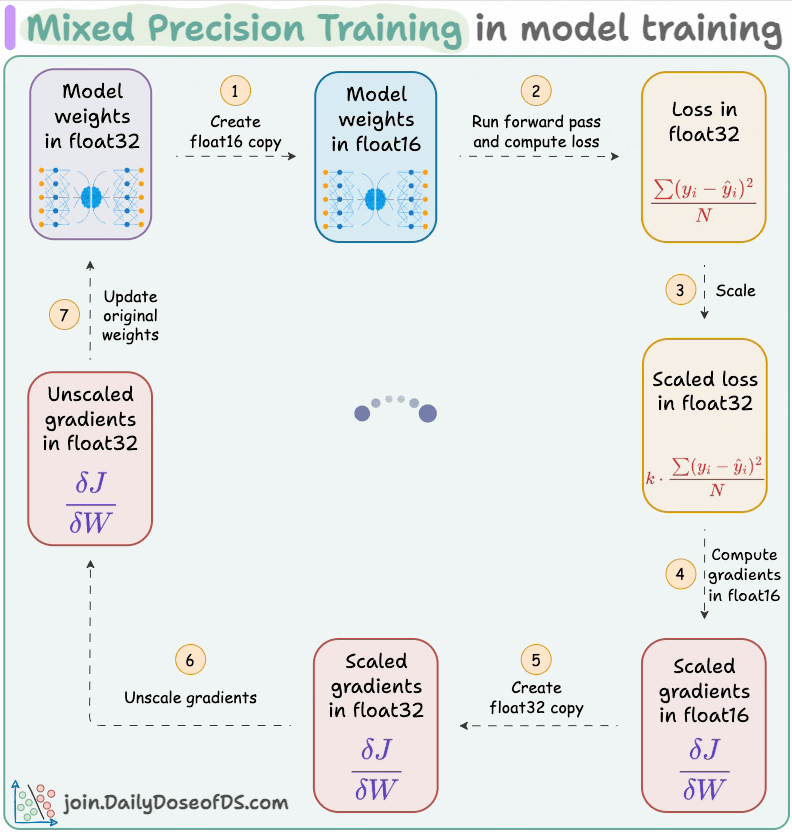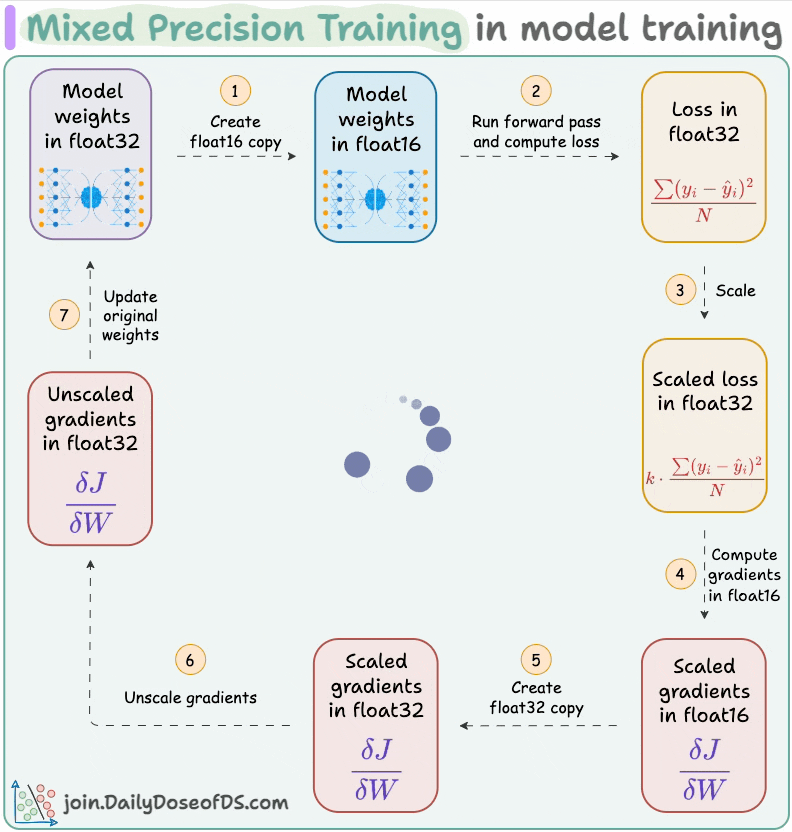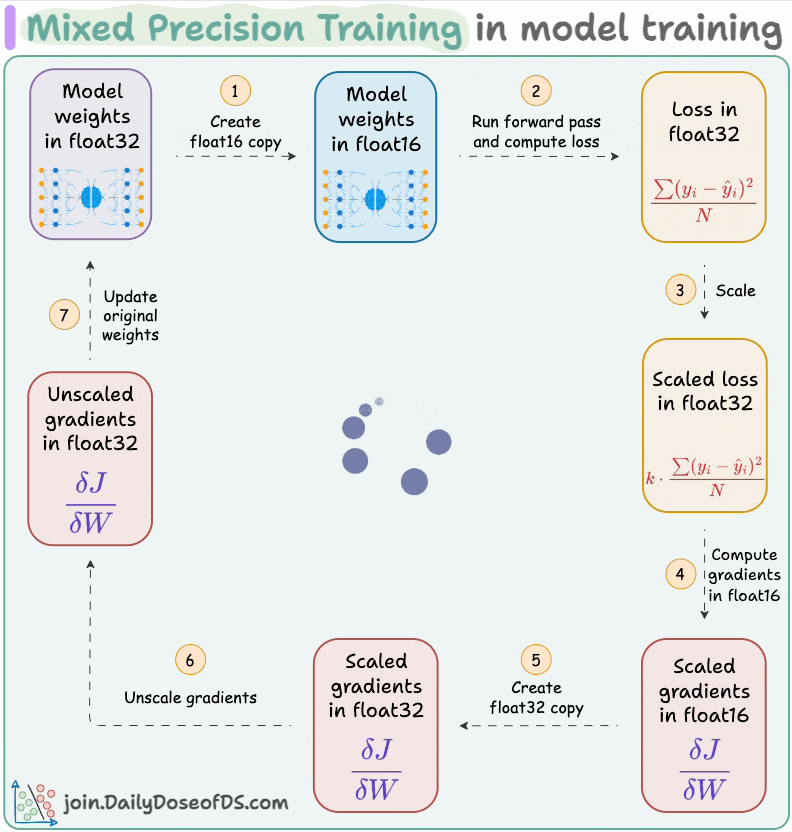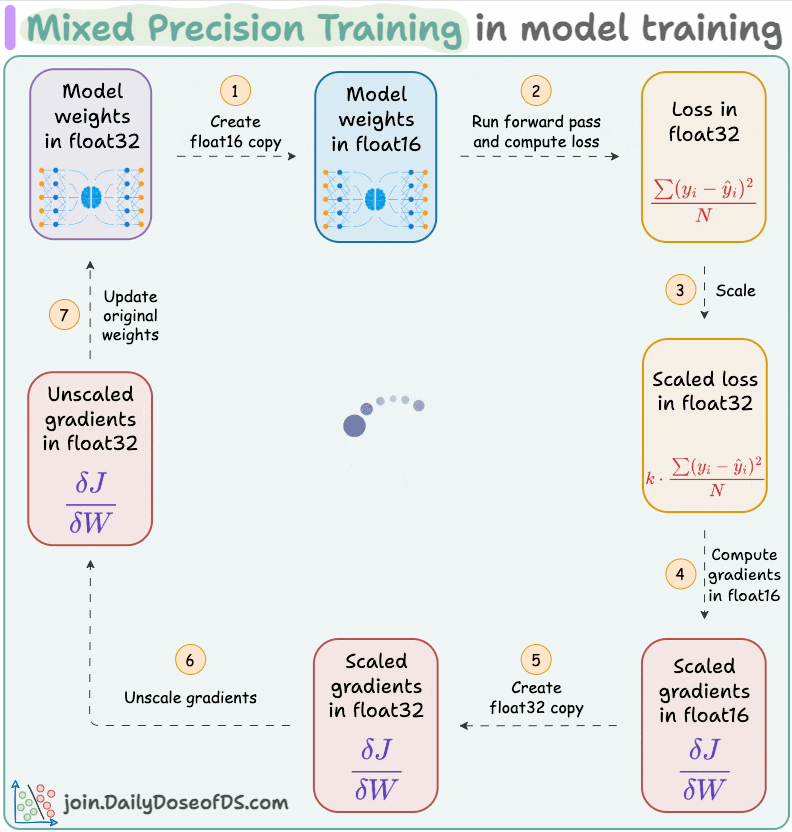
Use lower precision
float16(wherever feasible, like in convolutions and matrix multiplications) along withfloat32.List of some models trained using mixed precision (indicating popularity):

#6) Use He or Xavier initialization for faster convergence (usually helps).
#7) Utilize multi-GPU training through Model/Data/Pipeline/Tensor parallelism.
#8) For large models, use techniques like DeepSpeed, FSDP, YaFSDP, etc.
#9) Always use DistributedDataParallel, not DataParallel in your data loaders, even if you are not using distributed training.
#10) Use activation checkpointing to optimize memory (run-time will go up).
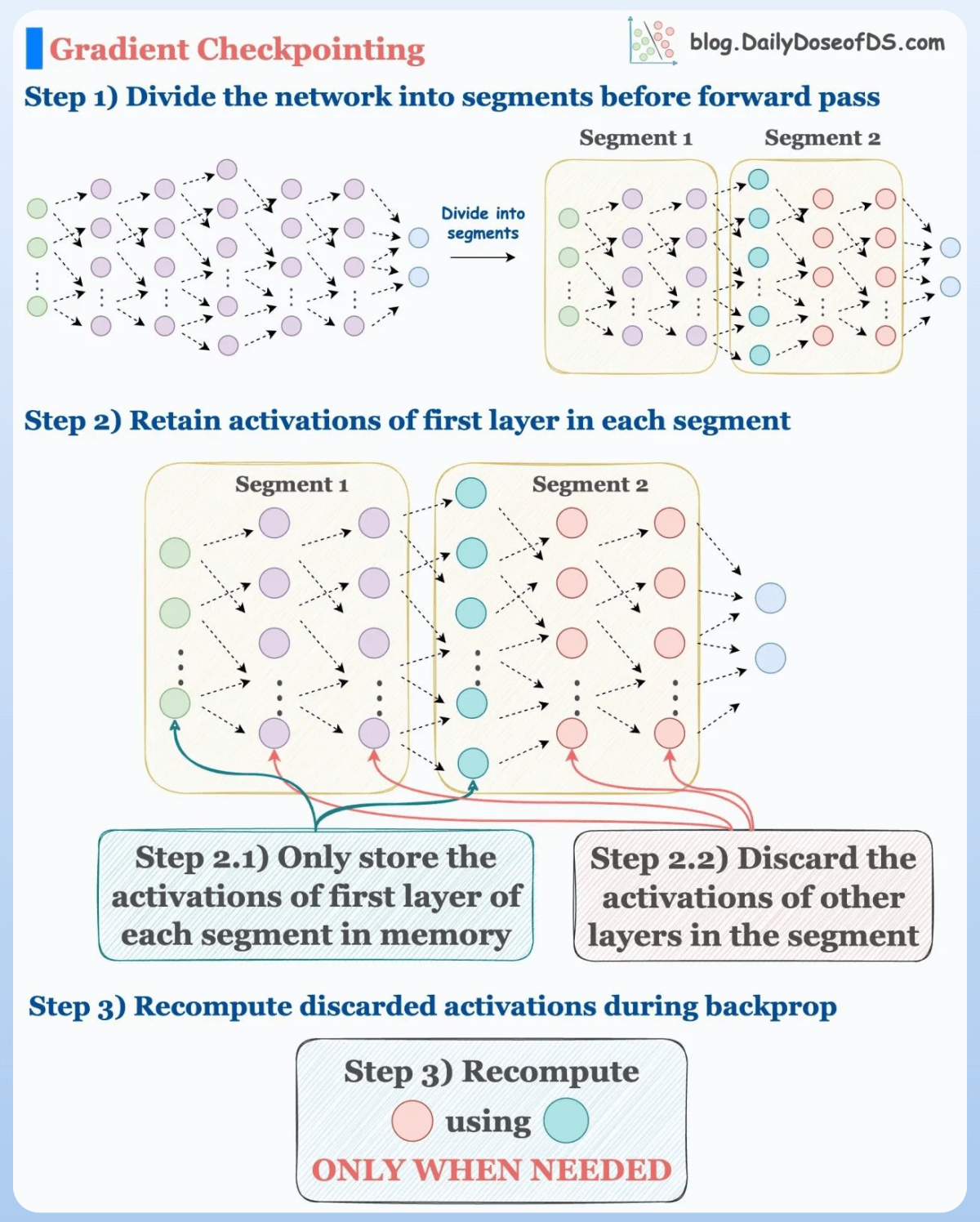
We don’t need to store all the intermediate activations in memory. Instead, storing a few of them and recomputing the rest when needed can significantly reduce the memory requirement.
This can reduce memory usage by a factor of
sqrt(M), whereMis the memory consumed without activation checkpointing.But due to recomputations, it increases run-time.
#11) Normalize data after transferring to GPU (for integer data, like pixels):

Consider image data, which has pixels (8-bit integer values).
Normalizing it before transferring to the GPU would mean we need to transfer 32-bit floats.
But normalizing after transfer means 8-bit integers are transferred, consuming less memory.
#12) Use gradient accumulation (may have marginal improvement at times).

Under memory constraints, it is always recommended to train the neural network with a small batch size.
Despite that, there’s a technique called gradient accumulation, which lets us (logically) increase batch size without explicitly increasing the batch size.
#13) torch.rand(2, 2, device = ...) creates a tensor directly on the GPU. But torch.rand(2,2).cuda() first creates on the CPU, then transfers to the GPU, which is slow. The speedup is evident from the image below:

#14-15) Set max_workers and pin_memory in DataLoader.
The typical neural network training procedure is as follows:
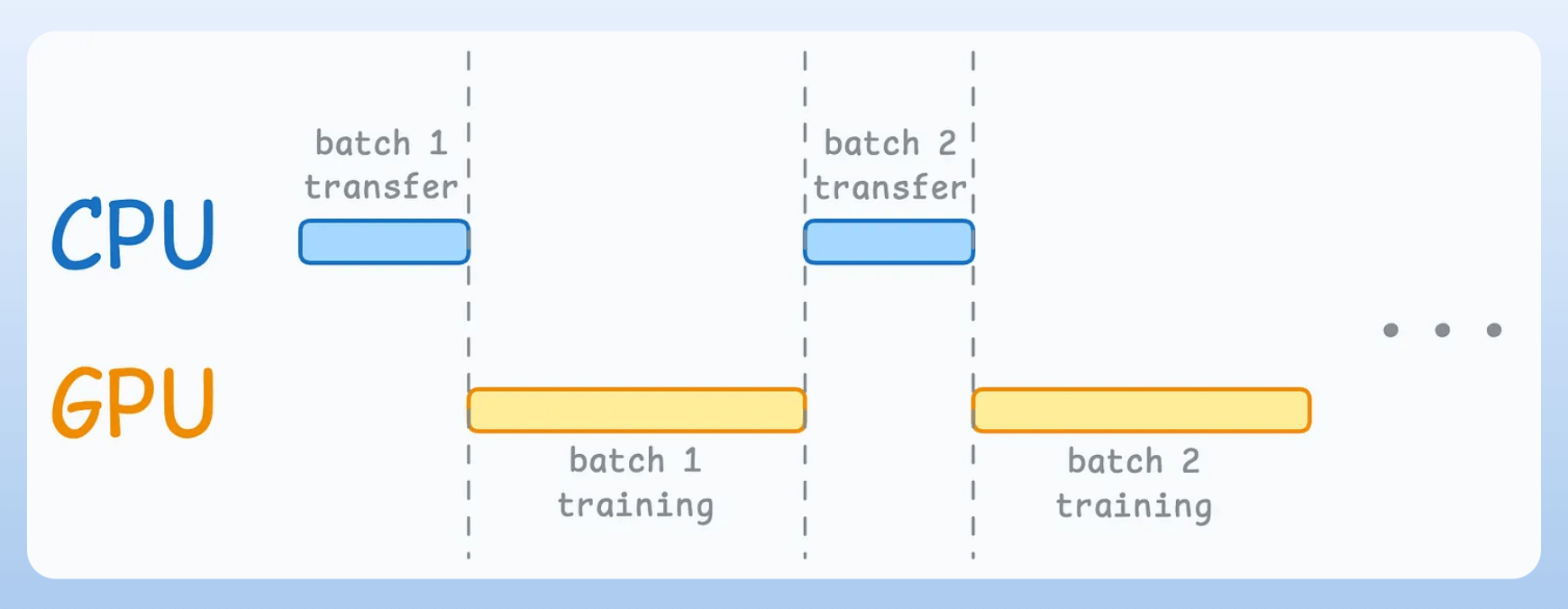
As shown above, when the GPU is working, the CPU is idle, and when the CPU is working, the GPU is idle.
But here’s what we can do to optimize this:

When the model is being trained on the 1st mini-batch, the CPU can transfer the 2nd mini-batch to the GPU.
This ensures that the GPU does not have to wait for the next mini-batch of data as soon as it completes processing an existing mini-batch.
While the CPU may remain idle, this process ensures that the GPU (which is the actual accelerator for our model training) always has data to work with.
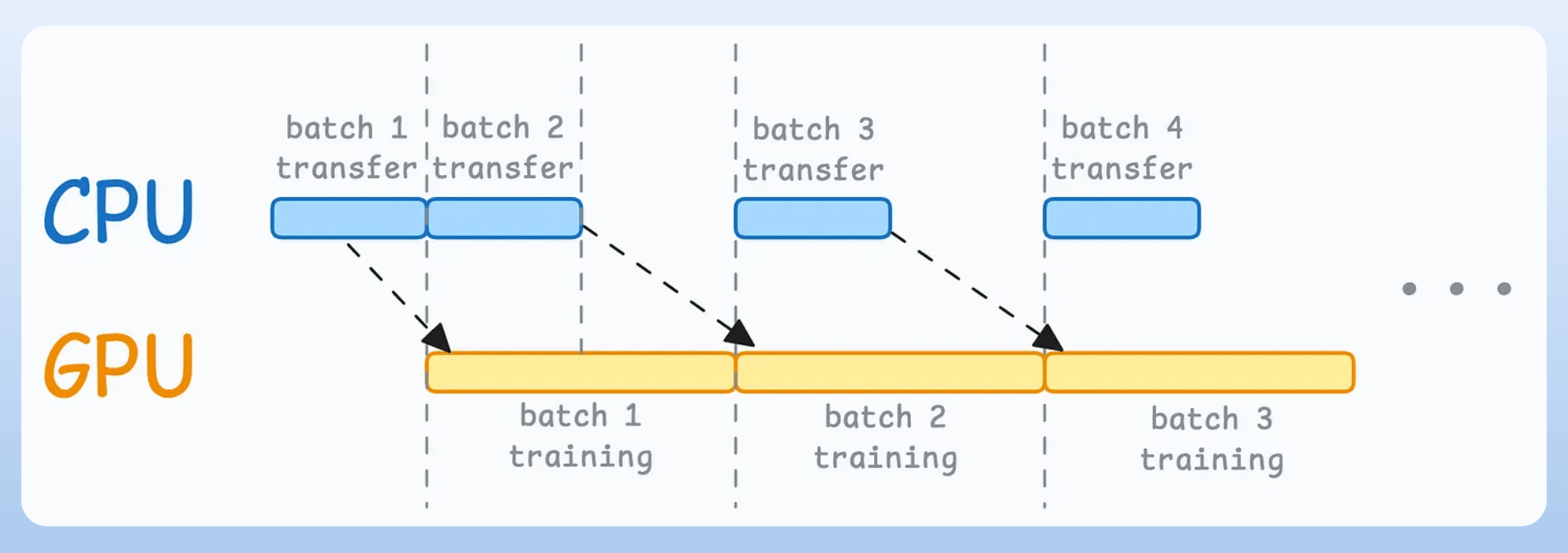
Of course, the above is not an all-encompassing list.
👉 Over to you: Can you add more techniques?
Fine-tuning, Transfer, Multitask & Federated Learning
Most ML models are trained independently without any interaction with other models.
But real-world ML uses many powerful learning techniques that rely on model interactions.
The following animation summarizes four such well-adopted and must-know training methodologies:
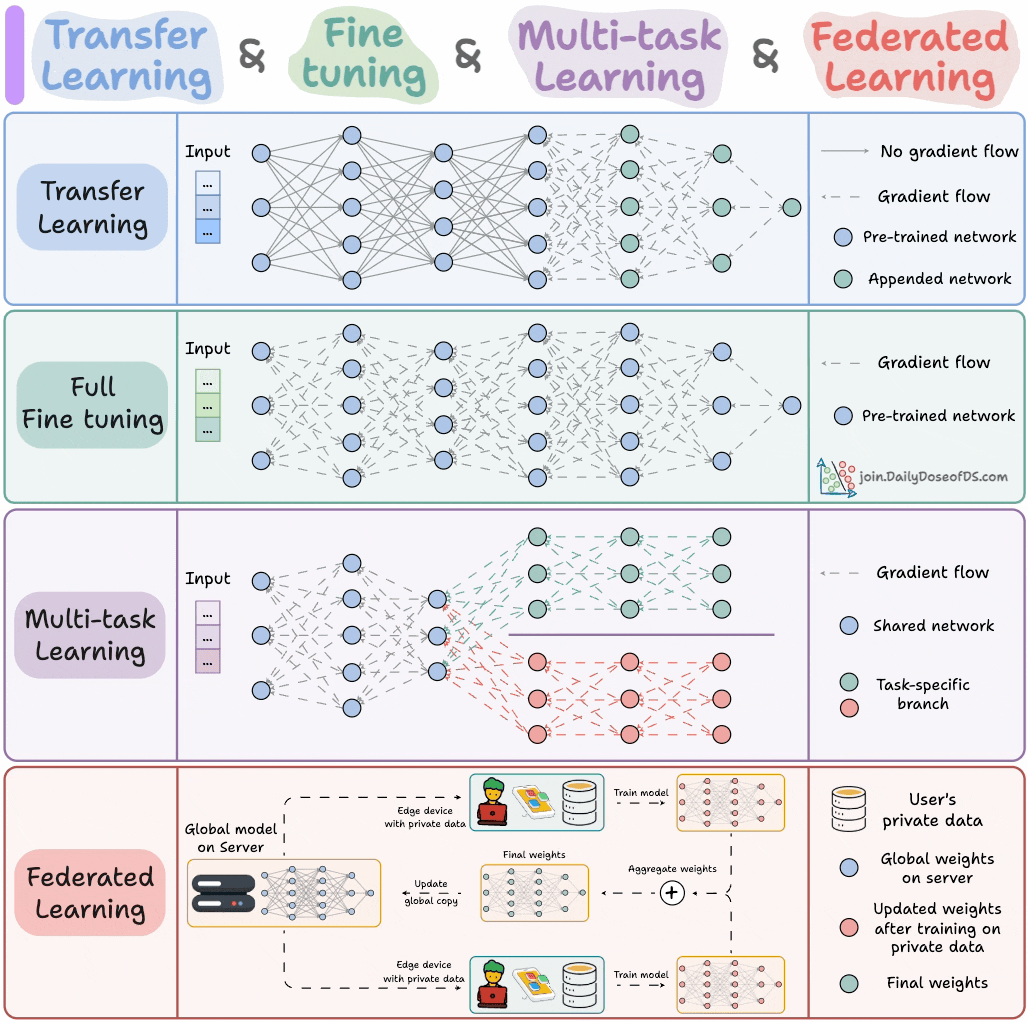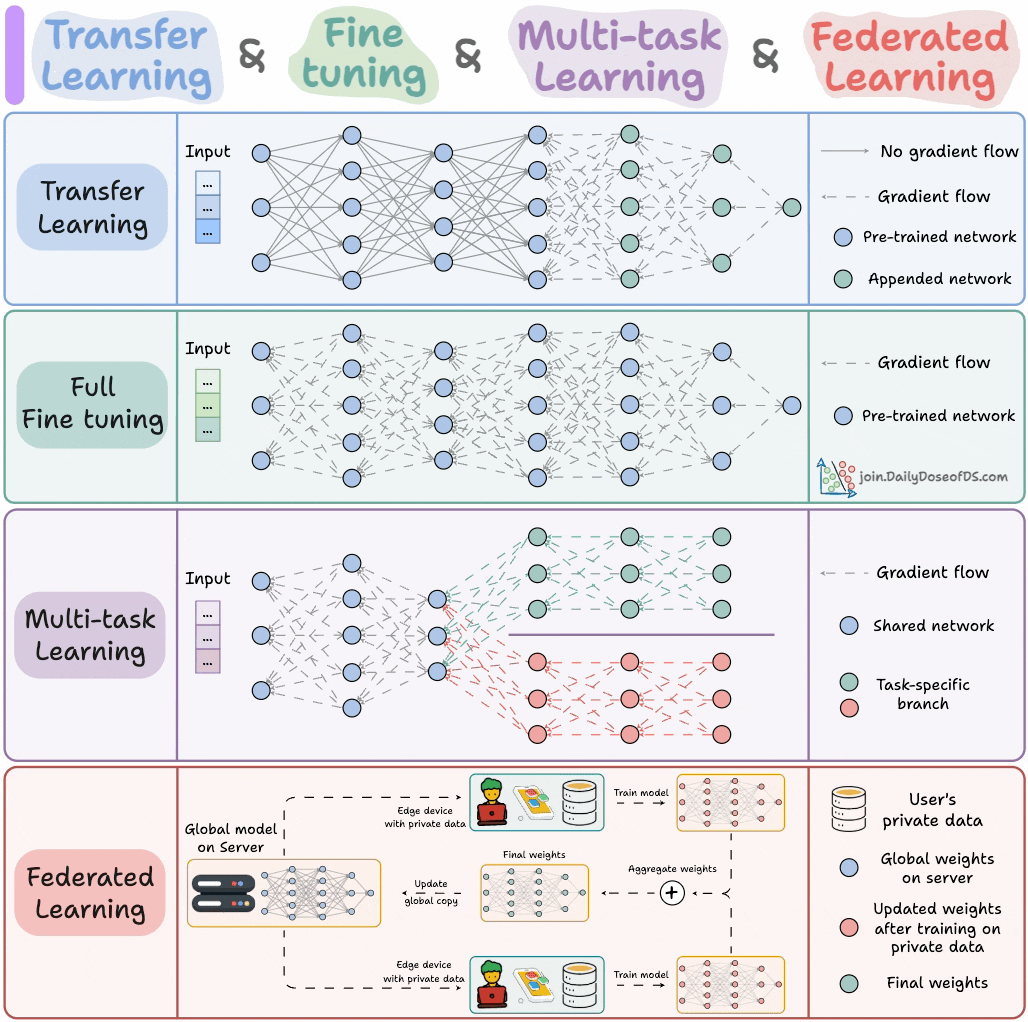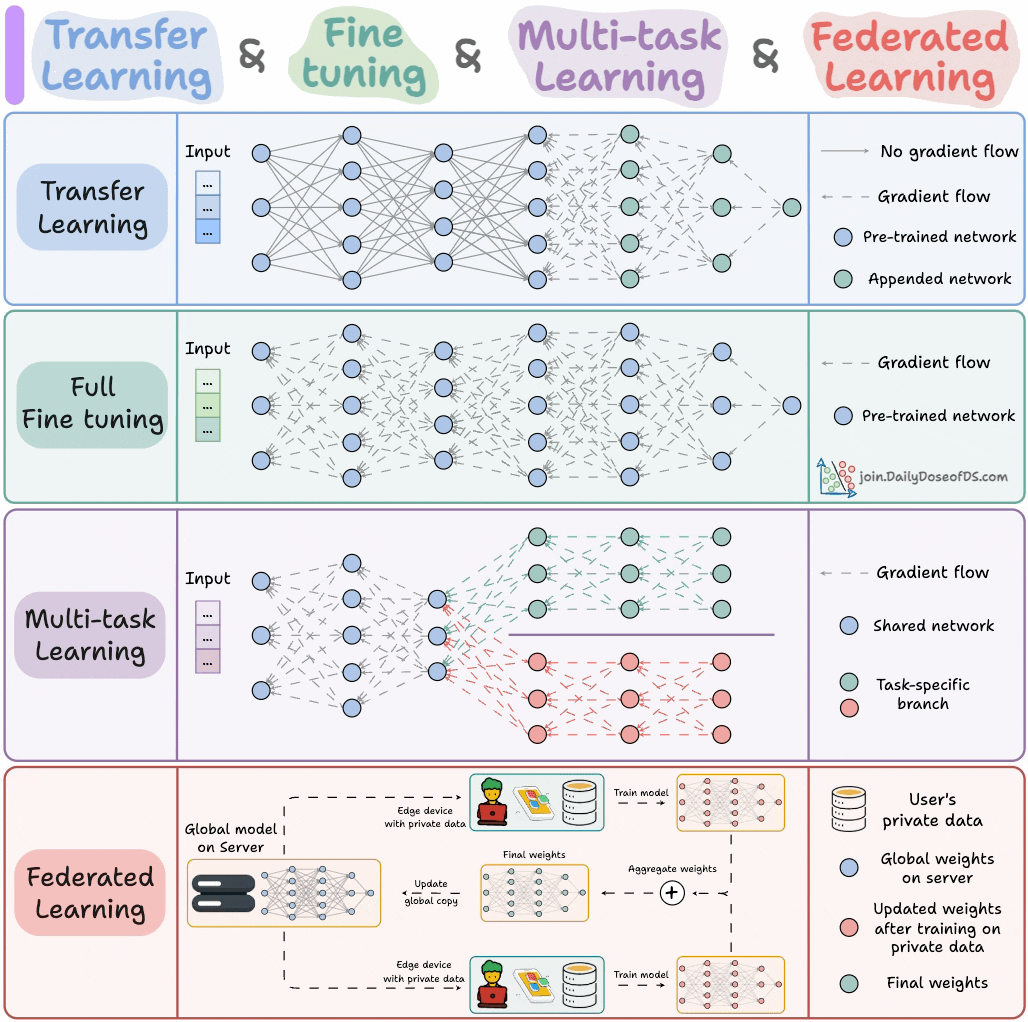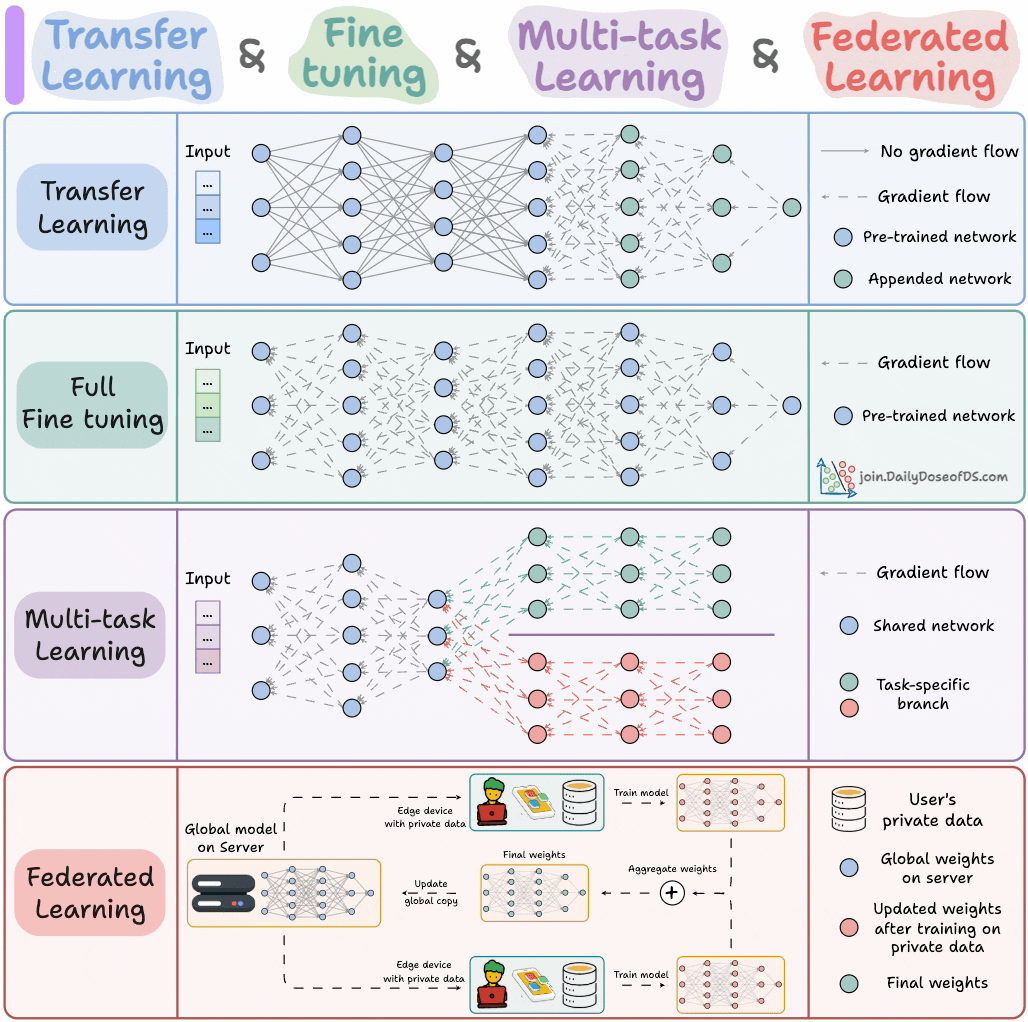
1) Transfer learning

Useful when:
The task of interest has less data.
But a related task has abundant data.
This is how it works:
Train a neural network model (base model) on the related task.
Replace the last few layers on the base model with new layers.
Train the network on the task of interest, but don’t update the weights of the unreplaced layers.
Training on a related task first allows the model to capture the core patterns of the task of interest.
Next, it can adapt the last few layers to capture task-specific behavior.
2) Fine-tuning

Update the weights of some or all layers of the pre-trained model to adapt it to the new task.
The idea may appear similar to transfer learning. But here, the whole pretrained model is typically adjusted to the new data.
3) Multi-task learning (MTL)
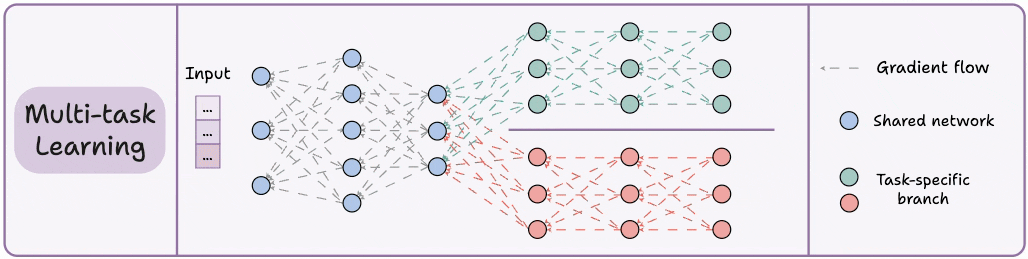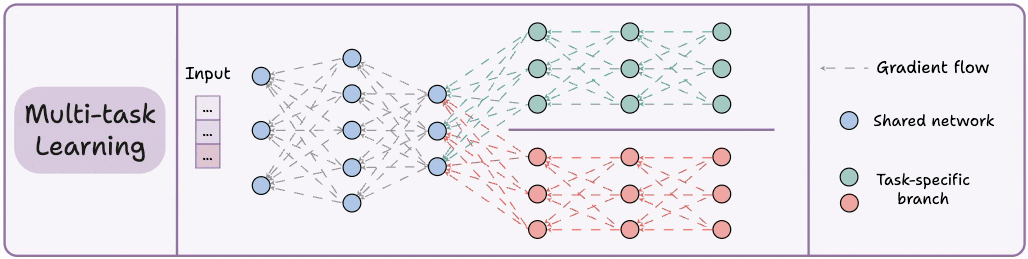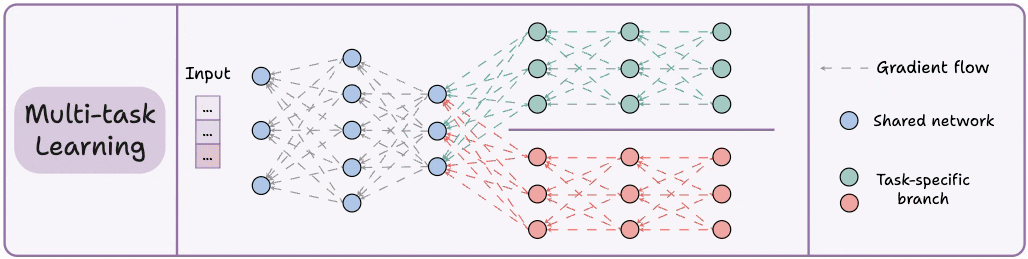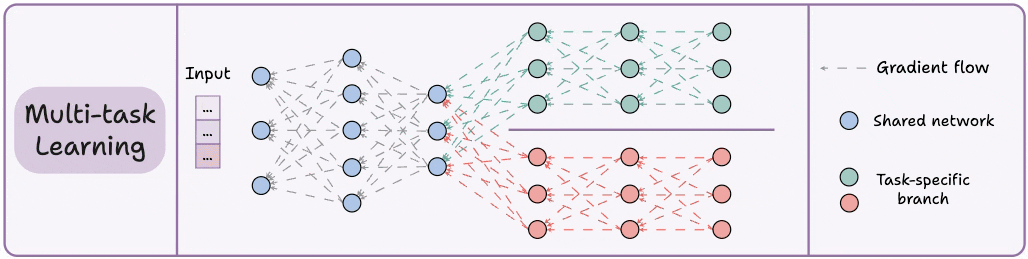
A model is trained to perform multiple related tasks simultaneously.
Architecture-wise, the model has:
A shared network
And task-specific branches
The rationale is to share knowledge across tasks to improve generalization.
In fact, we can also save computing power with MTL:
Imagine training 2 independent models on related tasks.
Now compare it to having a network with shared layers and then task-specific branches.
Option 2 will typically result in:
Better generalization across all tasks.
Less memory to store model weights.
Less resource usage during training.
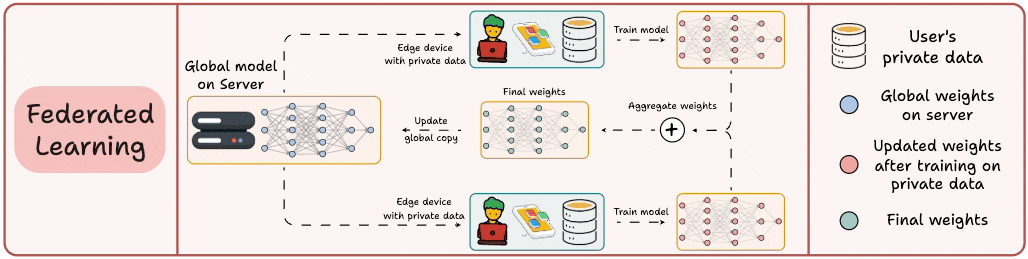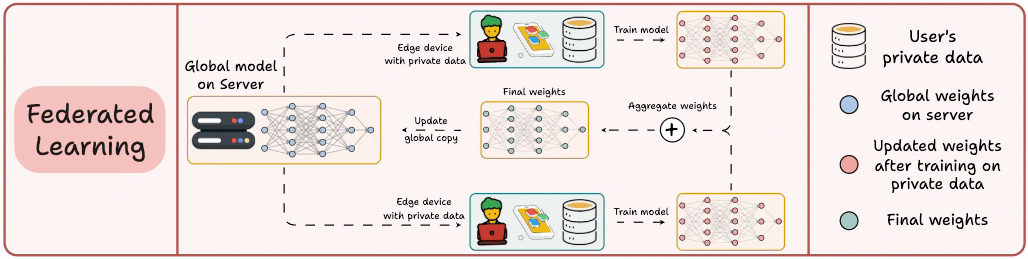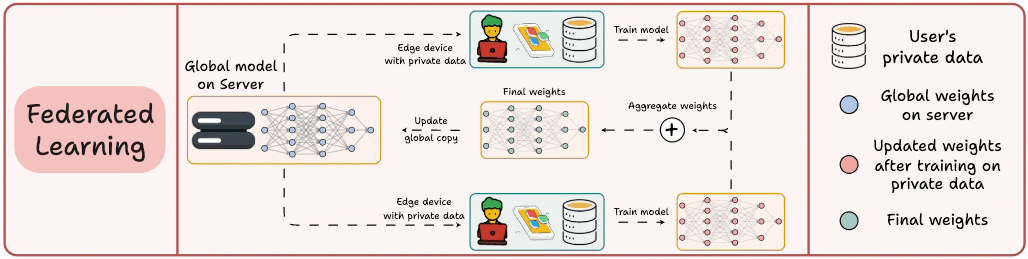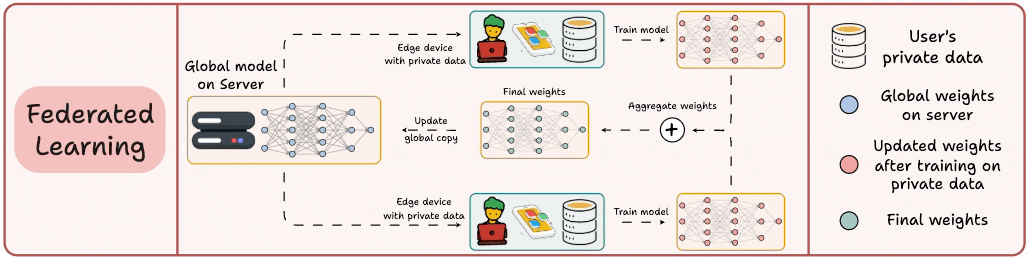
This is a decentralized approach to ML. Here, the training data remains on the user’s device.
So in a way, it’s like sending the model to the data. To preserve privacy, only model updates are gathered from devices and sent to the server.
The keyboard of our smartphone is a great example of this.
It uses FL to learn typing patterns. This happens without transmitting sensitive keystrokes to a central server.
Note: Here, the model is trained on small devices. Thus, it MUST be lightweight yet useful.
We implemented federated learning here →
Thanks for reading!