
17 Popular Open-source Contributions by Big Tech
...summarized in a single frame.

AI isn’t magic. It’s math.

Understand the concepts powering technology like ChatGPT in minutes a day with Brilliant. Thousands of quick, hands-on lessons in AI, programming, logic, data science, and more make it easy. Level up fast with:
Bite-sized, interactive lessons that make complex AI concepts accessible and engaging
Personalized learning paths and competitive features to keep you motivated and on track
Building skills to tackle real-world problems—not just memorizing information
Join over 10M people and try it free for 30 days. Plus, Daily Dose of Data Science readers can snag a special discount on an annual premium subscription with this link.
Thanks to Brilliant for partnering today!
17 popular open-source contributions by big tech
We prepared a visual that depicts the most popular open-source contributions by big tech in ML:
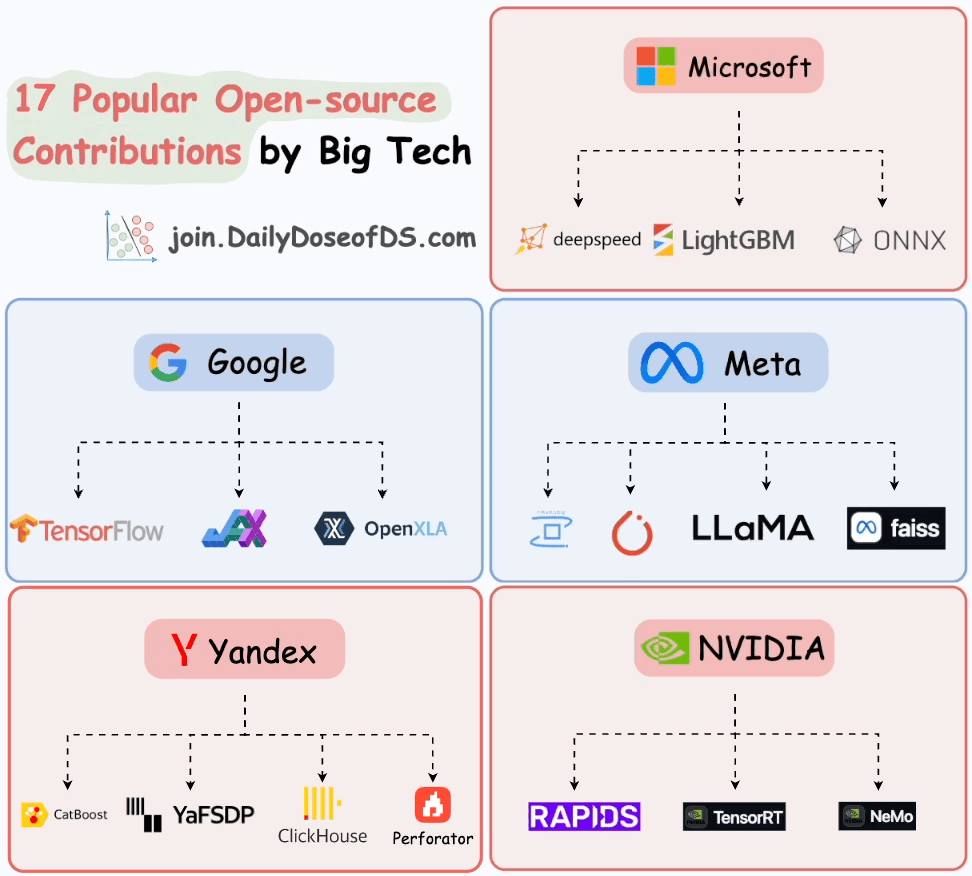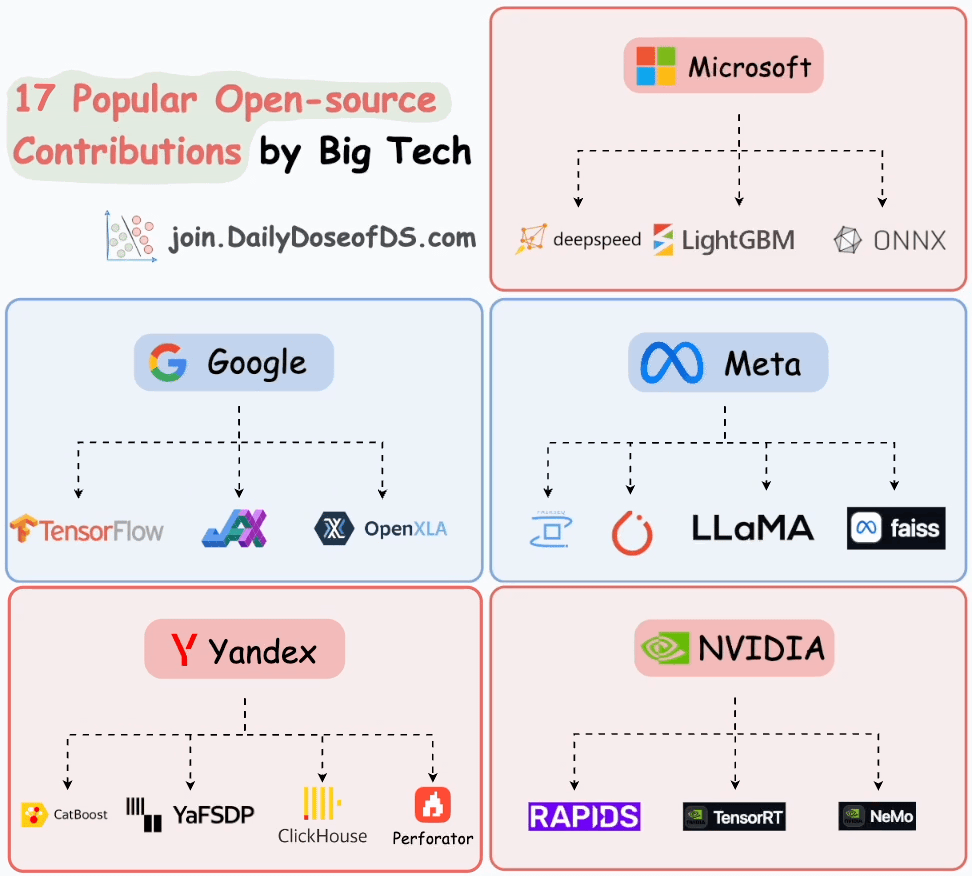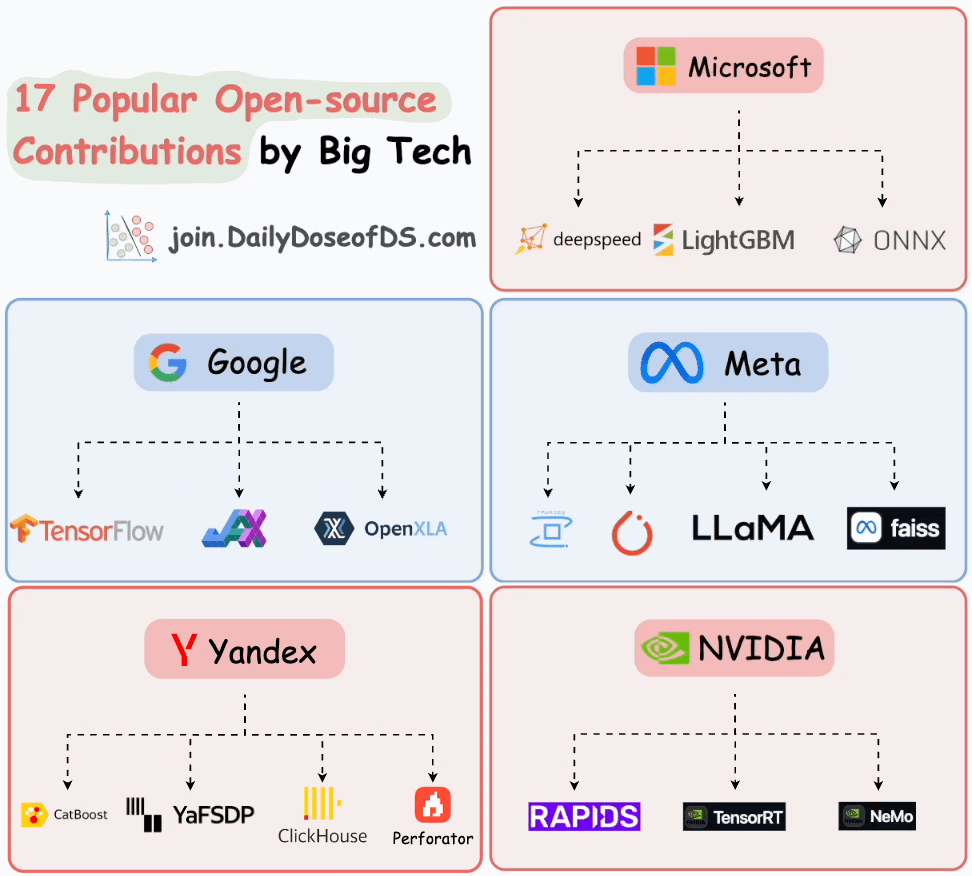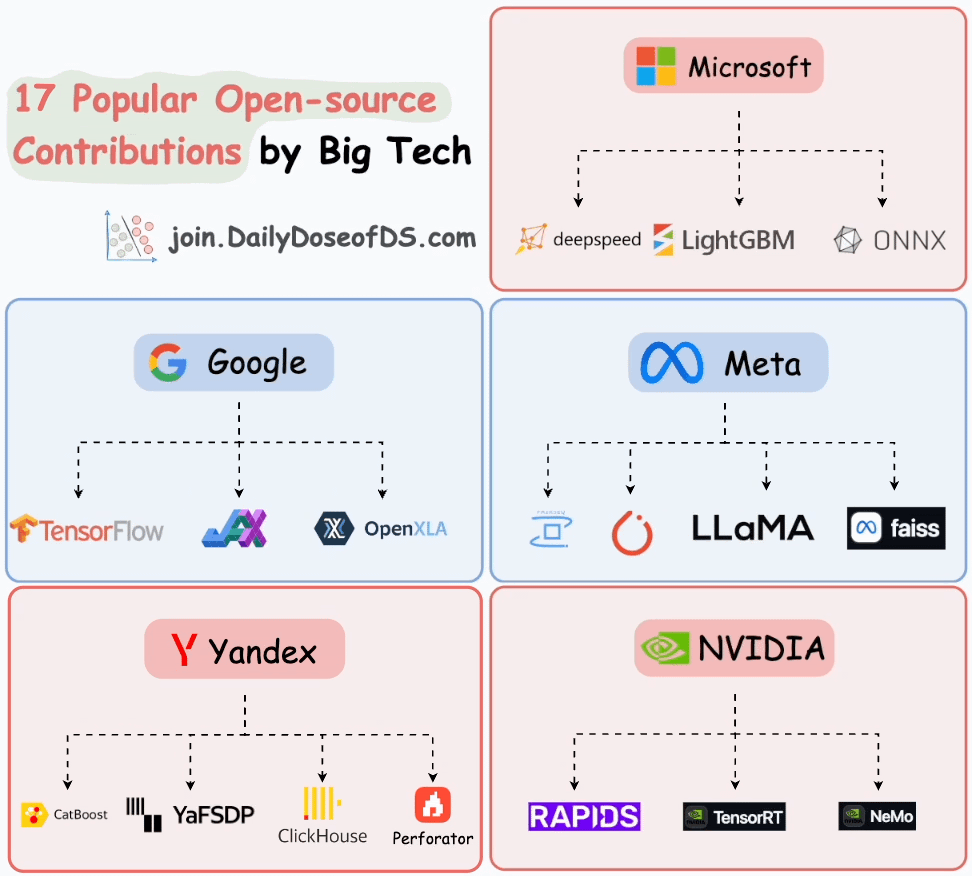
The motivation was to lay out and understand some of the key contributions from big techs in shaping the ML ecosystem over the years through their open-source contributions.
Here’s a quick summary of these open-source projects:
Microsoft:
DeepSpeed: A library for deep learning optimization, designed to train large models efficiently using features like model parallelism and mixed precision.
LightGBM: A gradient boosting framework optimized for speed and performance, commonly used for ranking, classification, and regression tasks.
ONNX: An open format to represent machine learning models, enabling interoperability between different frameworks.
Google:
TensorFlow: A widely-used deep learning framework for building, training, and deploying machine learning models across various platforms.
JAX: A library for high-performance numerical computing and deep learning, emphasizing differentiable programming and GPU/TPU support.
OpenXLA: An open-source compilation ecosystem for accelerating machine learning models on various hardware platforms.
Meta:
Fairseq: A sequence-to-sequence learning toolkit for training and evaluating custom models for tasks like machine translation, text generation, and speech recognition.
PyTorch: A popular machine learning framework known for its flexibility and ease of use in research and production environments.
LLaMA: A family of foundational language models designed for efficient and scalable NLP tasks.
Faiss: A library for efficient similarity search and clustering of dense vectors, widely used in recommendation systems and search.
Yandex:
CatBoost: A gradient boosting library optimized for categorical features, offering state-of-the-art accuracy and efficiency.
YaFSDP: An optimized data parallelism library that is an enhanced version of FSDP (a framework in PyTorch) with additional optimizations, especially for LLMs.
ClickHouse: A columnar database management system optimized for analytical queries and real-time data processing.
Perforator: A modern profiling tool designed for large data centers, which can be easily deployed onto your Kubernetes cluster to collect performance profiles with negligible overhead.
NVIDIA:
RAPIDS: A collection of GPU-accelerated libraries for data science, enabling faster data processing and machine learning workflows.
TensorRT: A platform for high-performance deep learning inference, offering model optimization and deployment on NVIDIA GPUs.
NeMo: A framework for building and fine-tuning large language models, particularly in speech, NLP, and multimodal AI.
👉 Over to you: What are some other key contributions of big tech in ML that we missed here?
[IN CASE YOU MISSED IT] A crash course on building RAG systems (Part 1-3)
Over the last few weeks, we have spent plenty of time understanding the key components of real-world NLP systems (like the deep dives on bi-encoders and cross-encoders for context pair similarity scoring).
RAG is another key NLP system that got massive attention due to one of the key challenges it solved around LLMs.
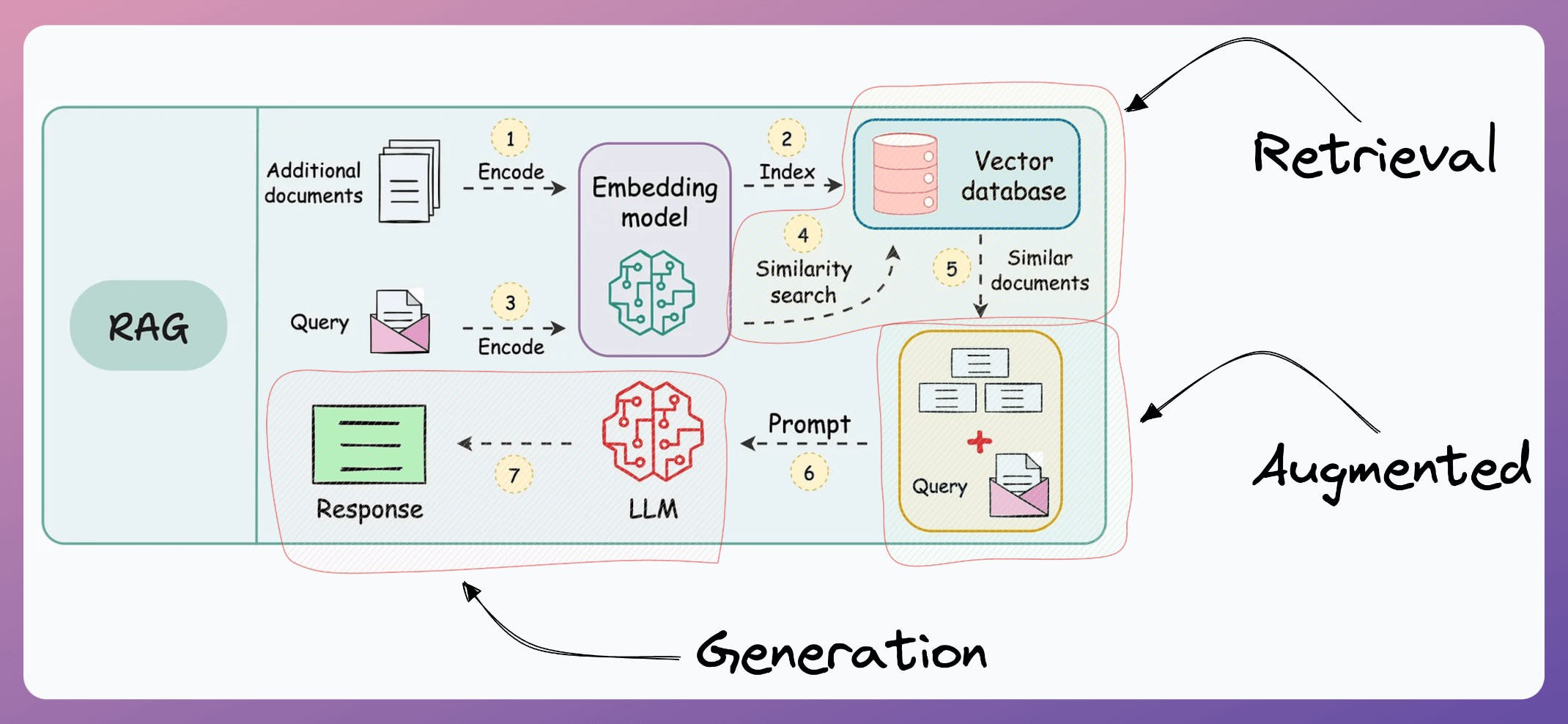
More specifically, if you know how to build a reliable RAG system, you can bypass the challenge and cost of fine-tuning LLMs.
That’s a considerable cost saving for enterprises.
And at the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Can you drive more revenue?
Can you scale ML training/inference?
Can you predict trends before they happen?
Thus, the objective of this crash course is to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
We have published three parts so far:
Learn the foundations of RAG and build them from scratch in the first part here.
Learn how to evaluate your RAG systems in the second part here.
Learn how to optimize your RAG systems in the third part here.
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 110,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Using which tool we can create such a interactive diagrams…
Where can you create images like this?