
2 Techniques to Synchronize ML Models in Multi-GPU Training
...explained visually.

Learn How AI Agents Are Reshaping Software Development [Free Webinar]

Join a 30-minute technical deep dive into how agentic systems allow LLMs to interface with APIs to drive real-time decisions and autonomous workflows.
Postman’s Head of Product, Rodric Rabbah, examines the architecture behind AI agents, shares four emerging design patterns, and outlines how teams are integrating LLMs into production systems.
The session also covers practical approaches to building, testing, and iterating on agents using Postman Flows and APIs.
If you’re exploring the infrastructure needed to support agentic workloads, this session offers a forward-looking perspective grounded in real-world examples.
Thanks to Postman for partnering today!
2 Techniques to Synchronize ML Models in Multi-GPU Training
One major run-time bottleneck in multi-GPU training happens during model synchronization, when we sync the gradients across devices:
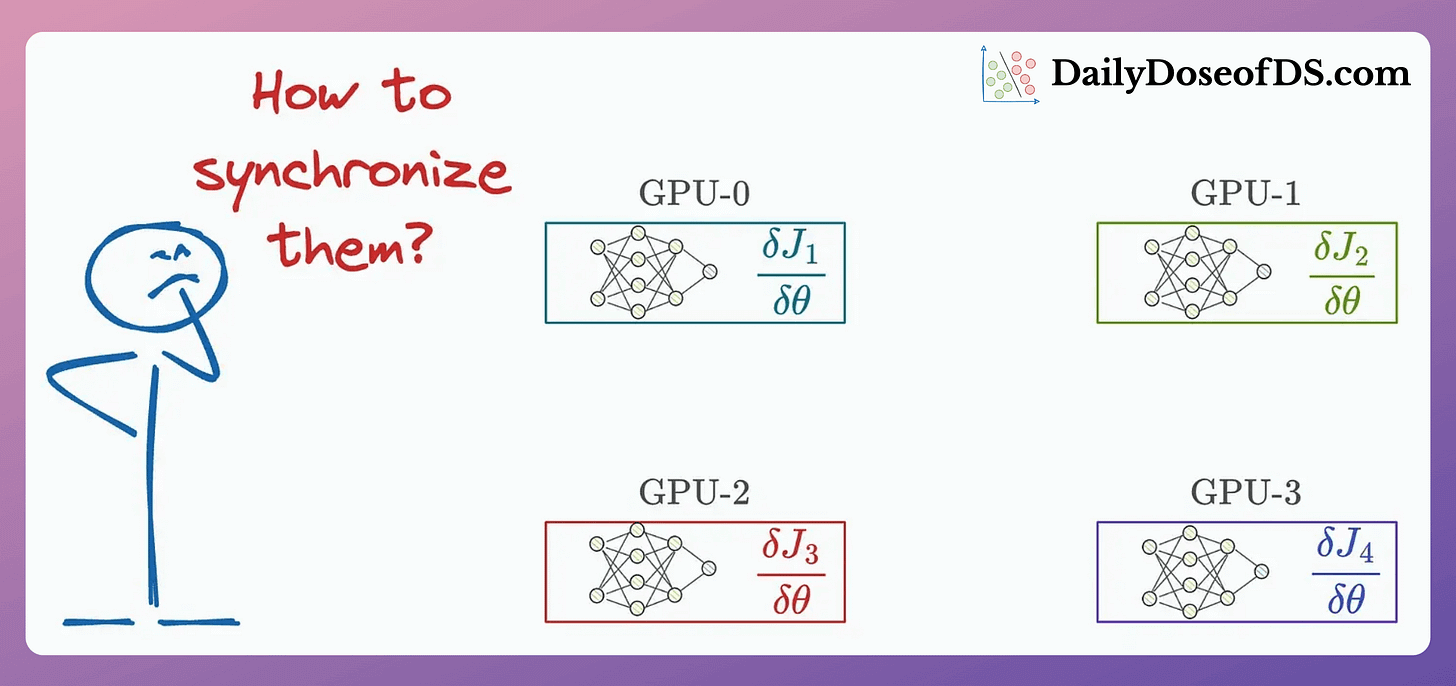
Today, let’s understand 2 common strategies to optimize this for intermediate-sized ML models.
If you want to get into the implementation details of multi-GPU training, we covered it here: A Beginner-friendly Guide to Multi-GPU Model Training.
Let’s begin!
Consider data parallelism, which:
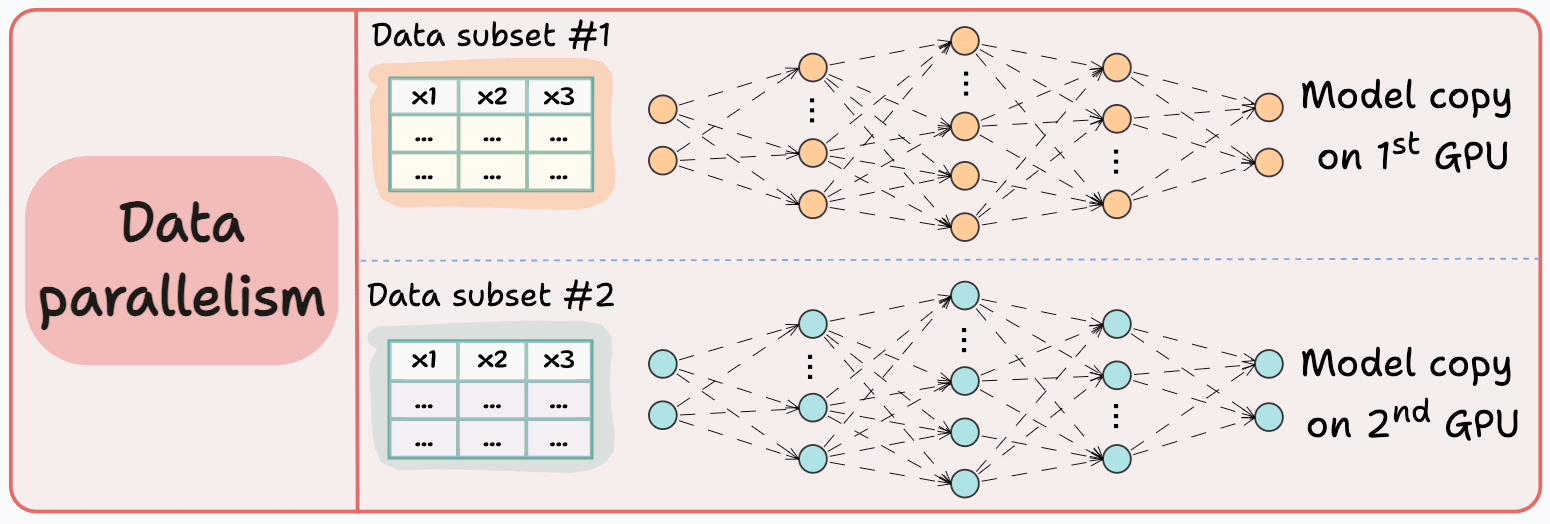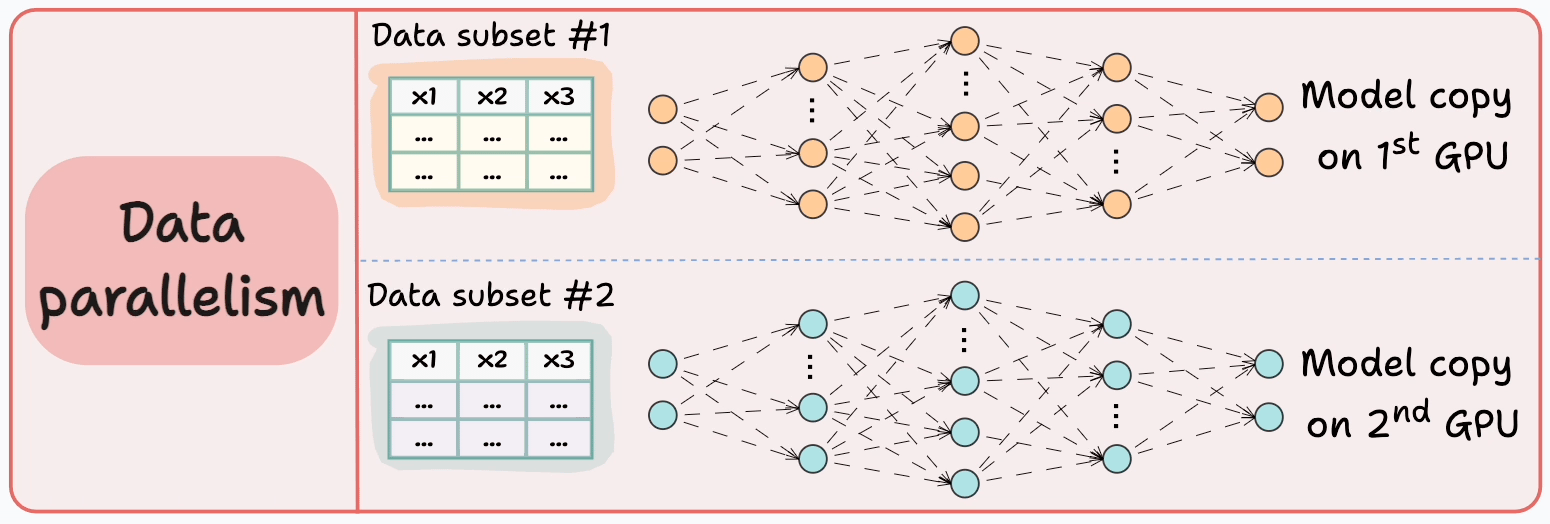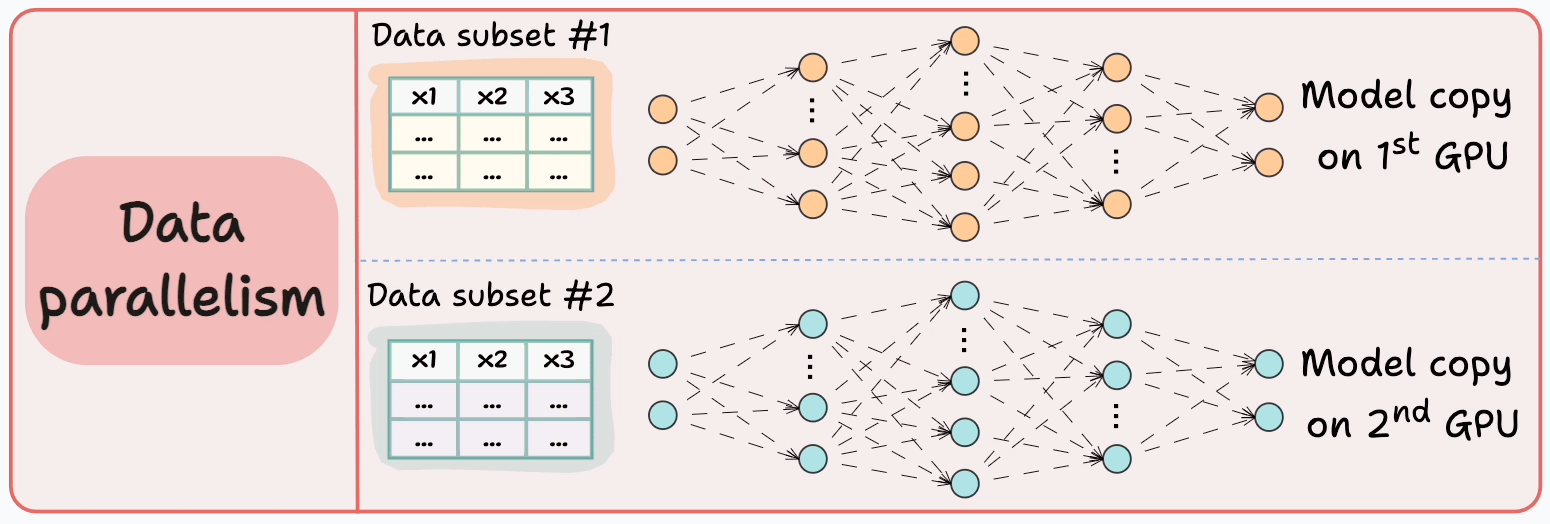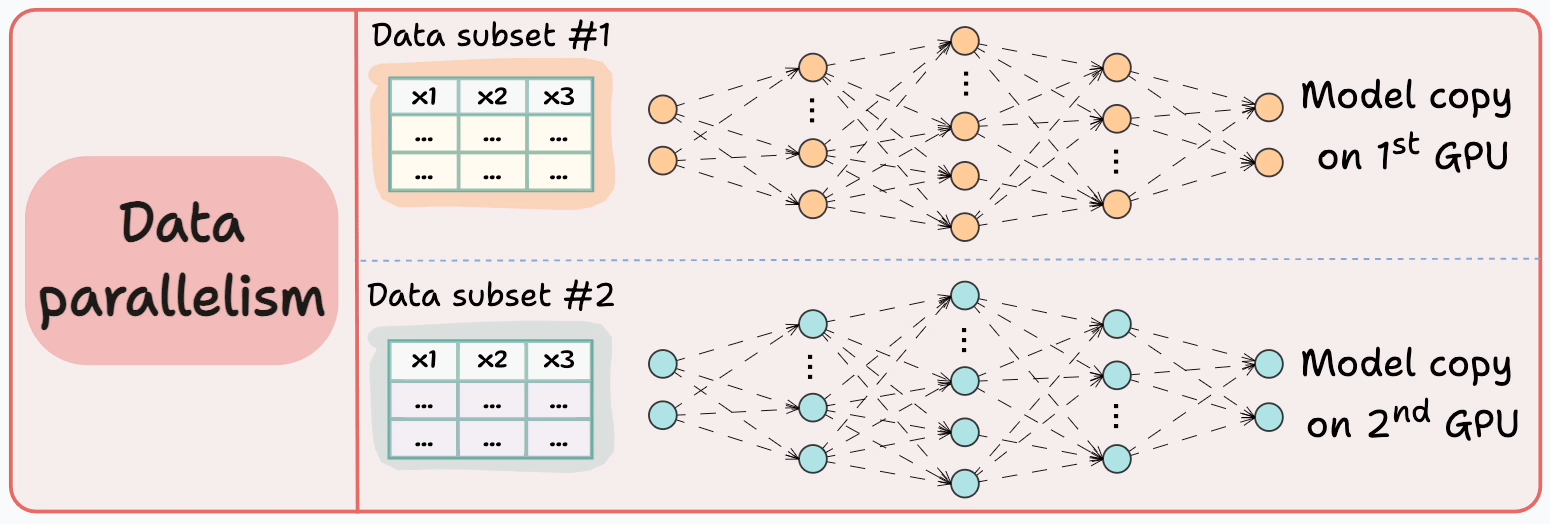
Replicates the model across all GPUs.
Divides the data into smaller batches.
Processes one batch per GPU.
Computes the gradients on each GPU
Communicates the gradients to every other GPU before the next iteration.
Since every GPU processes a different data chunk, the gradients are also different:

Thus, before updating the model parameters on each GPU device, we must communicate these gradients to all other devices.
Algorithm #1) All-reduce
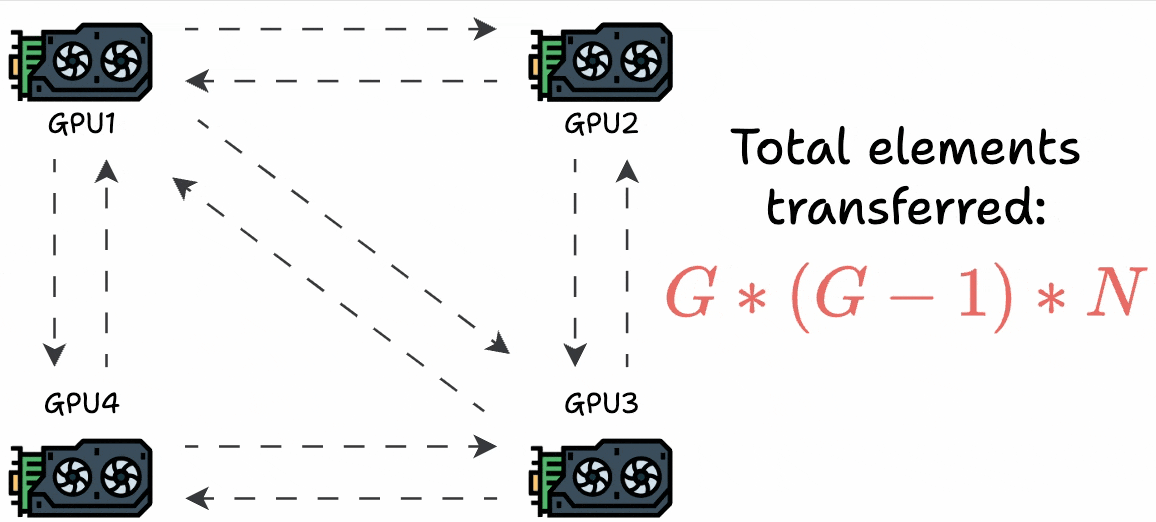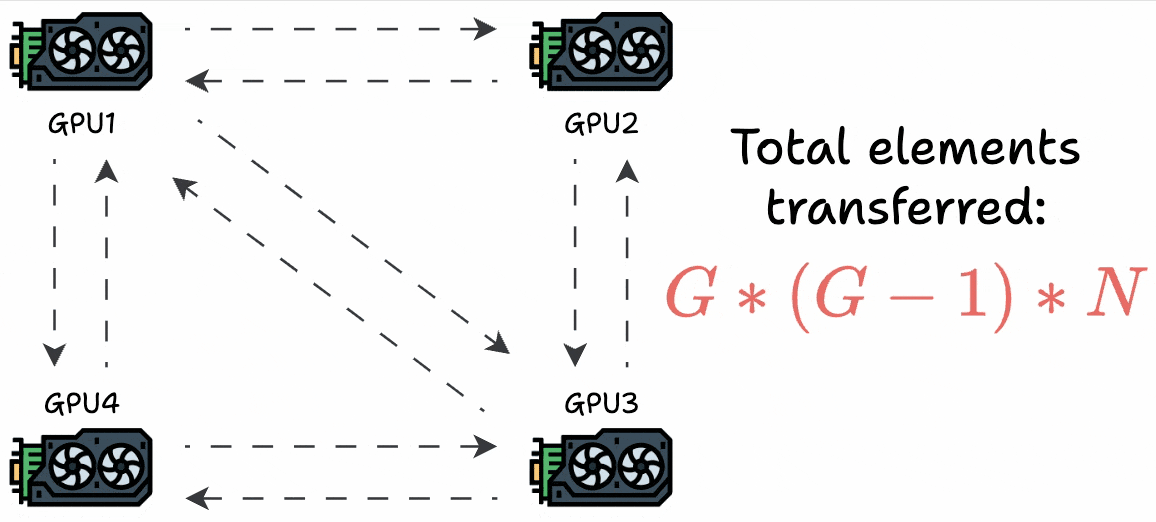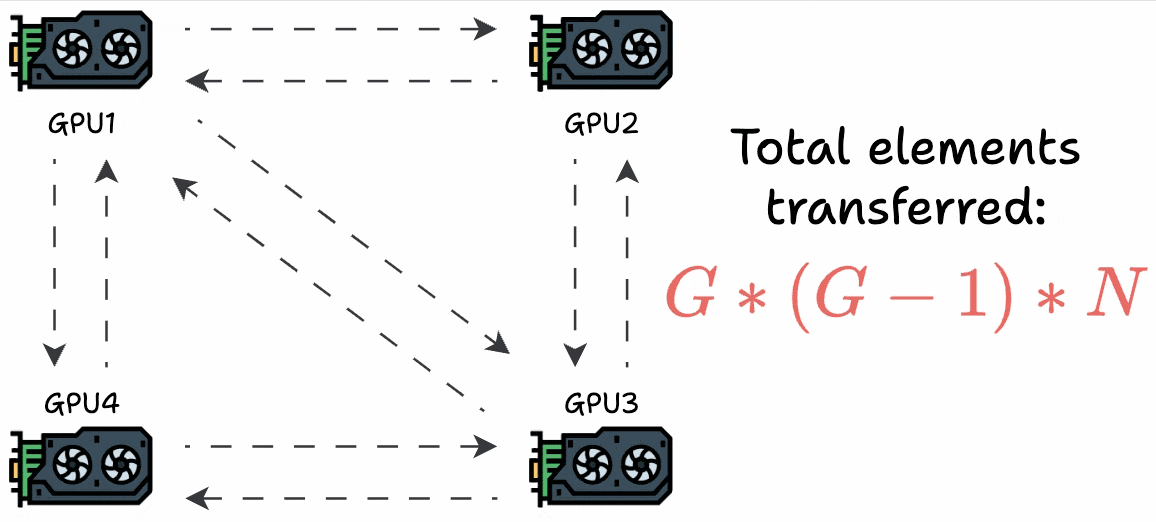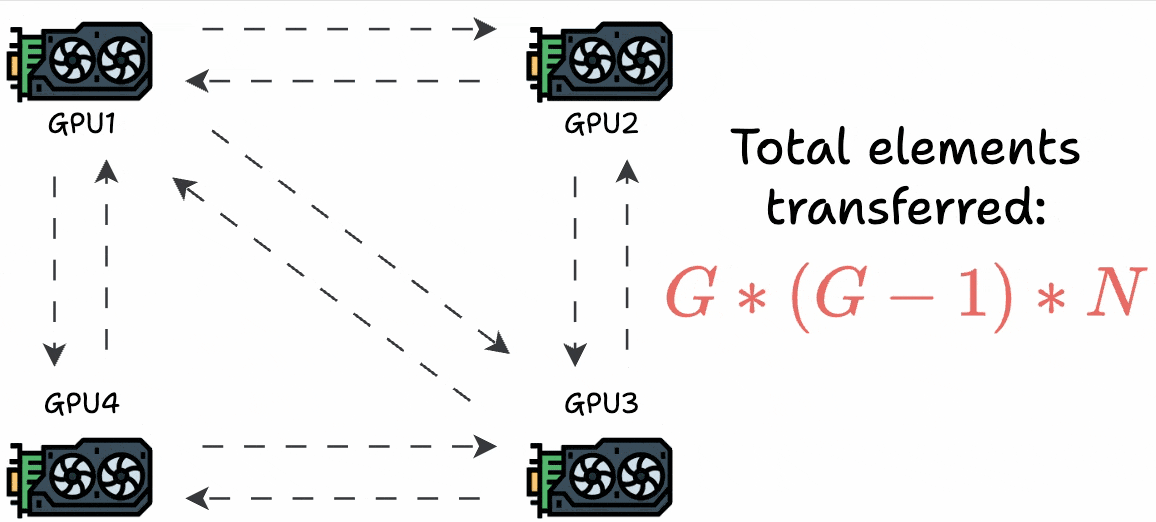
The most obvious technique is to send the gradients from one GPU device to all other GPU devices to synchronize the weights across all devices:

But this utilizes too much bandwidth.
Consider every GPU has a single matrix with “N” elements and they are a “G” GPUs. This results in a total transfer of G*(G-1)*N elements:
We can optimize this by transferring all the elements to one GPU, computing the average, and communicating the average back to all other GPUs:
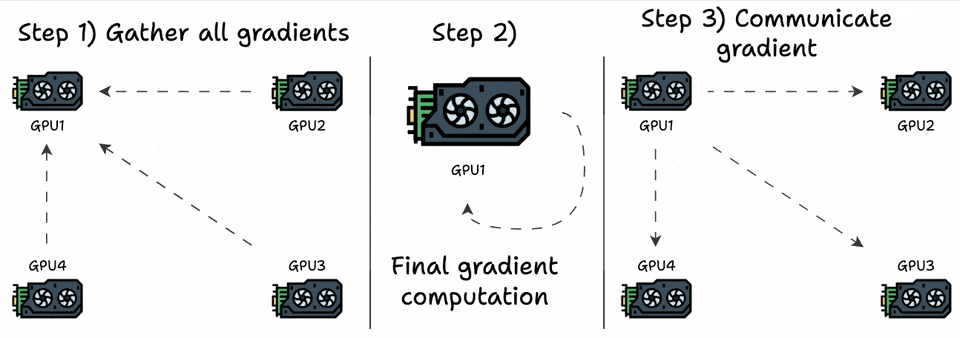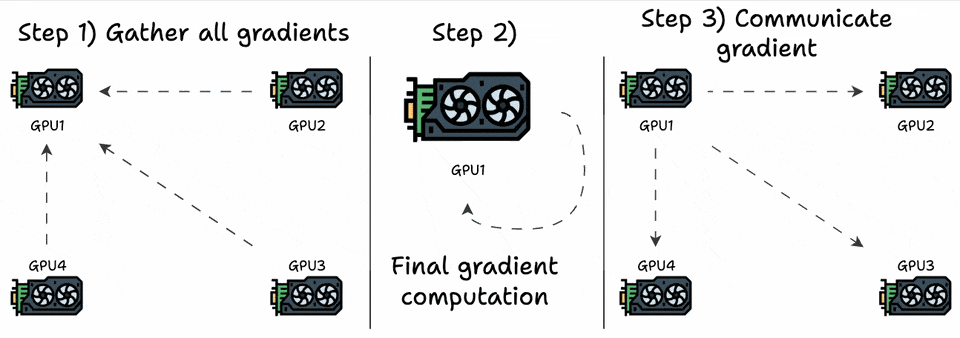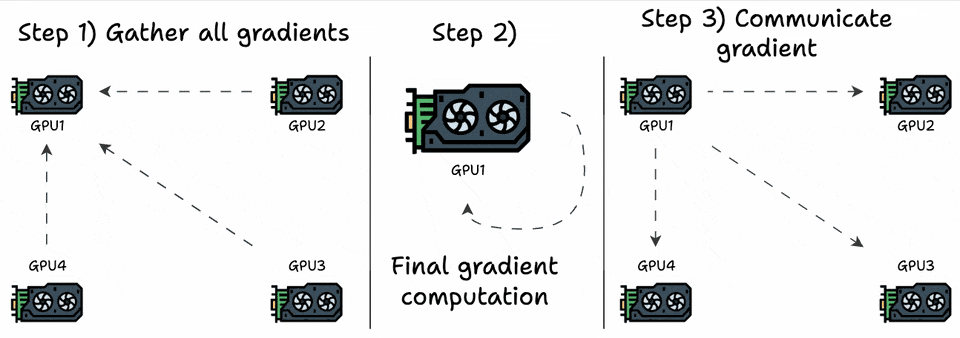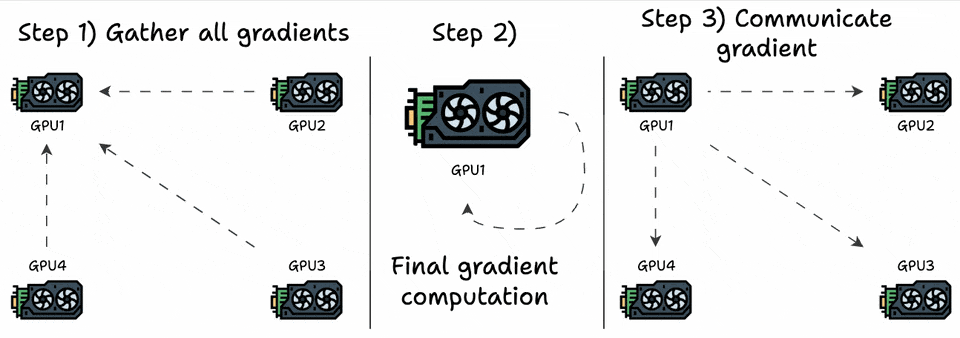
The number of elements transferred is:
Step 1:
(G-1)GPUs transfer “N” elements to the 1st GPU.Step 3: 1st GPU transfers “
N” elements to(G-1)GPUs.
This is a significant improvement, but now a single GPU must receive, compute, and communicate back the gradients, so this does not scale.
Algorithm #2) Ring All-reduce (or Ring-reduce)
There are two phases:
Share-reduce
Share-only
Here’s how each of them works.
Phase #1) Share-reduce
Gradients are divided into G segment on every GPU (G = total number of GPUs)
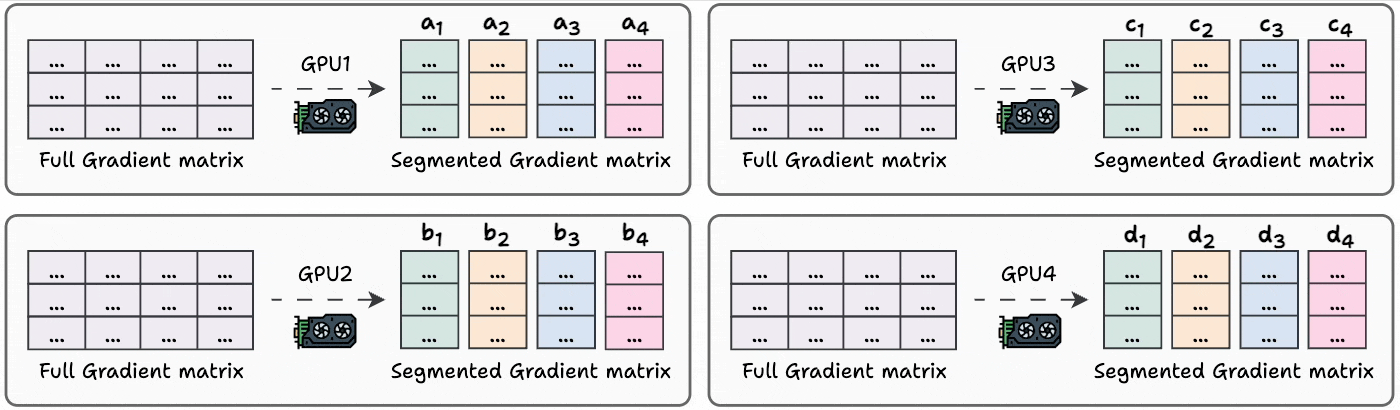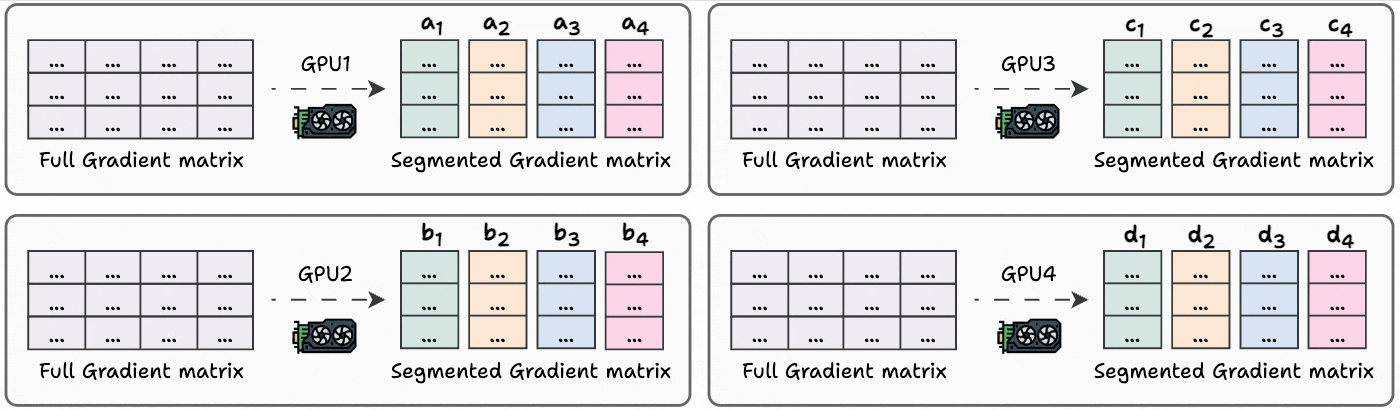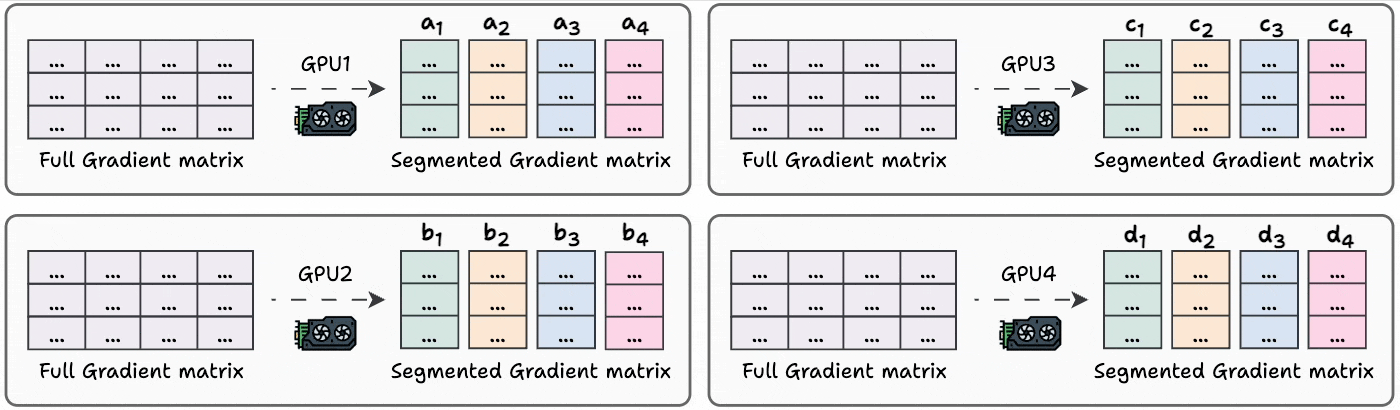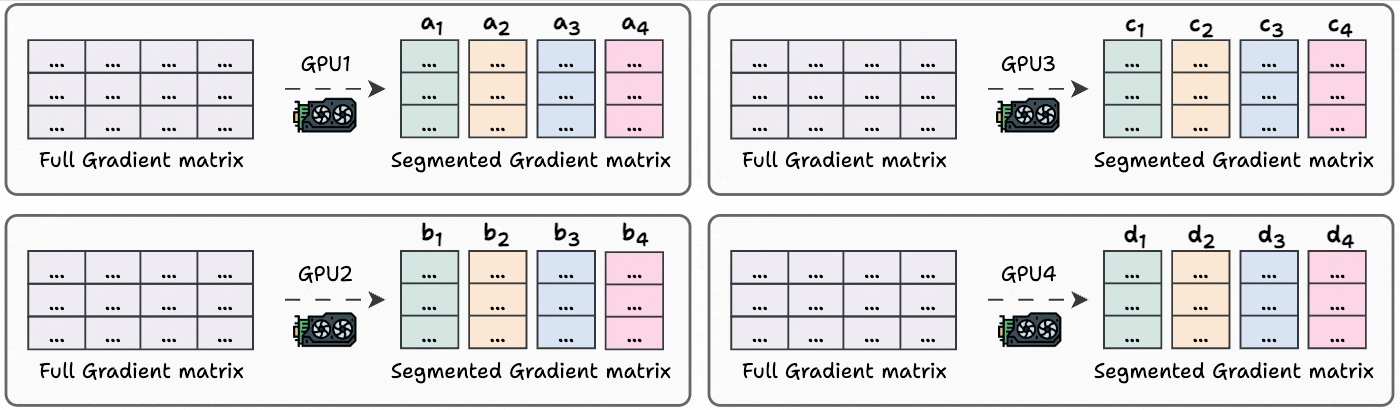
In an iteration, each GPU communicates a segment to the next GPU:

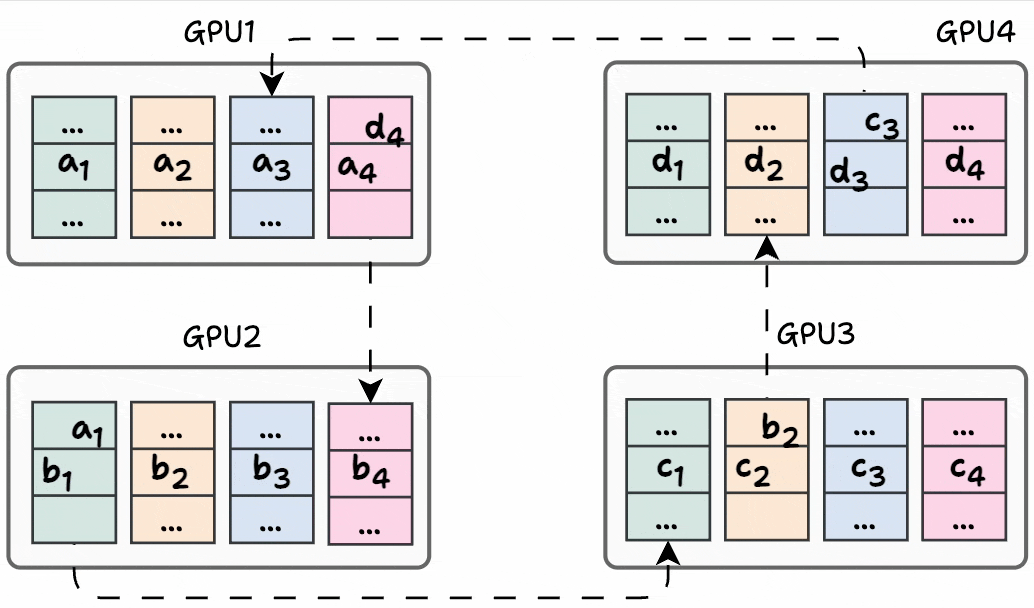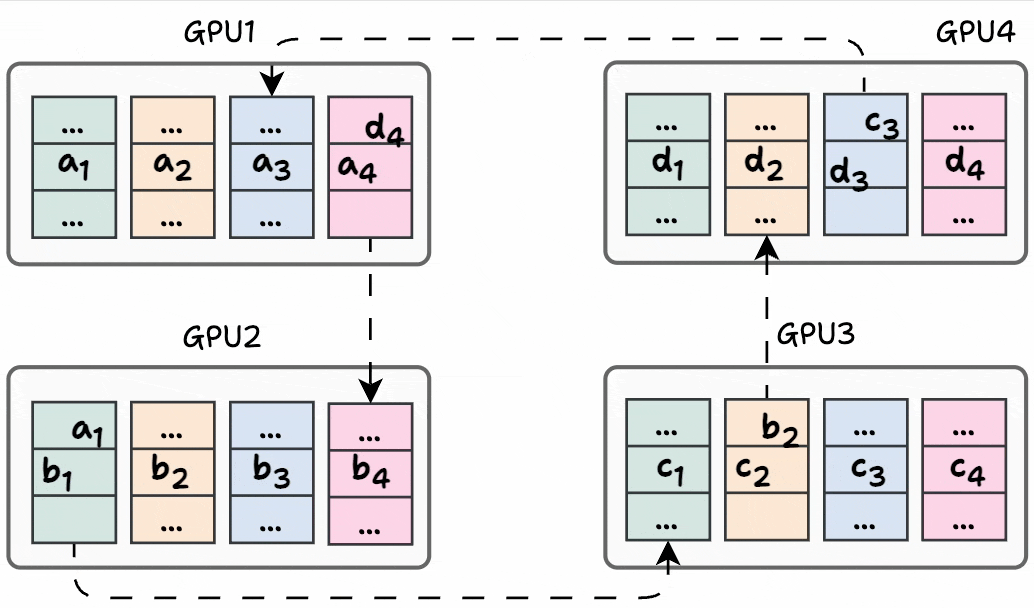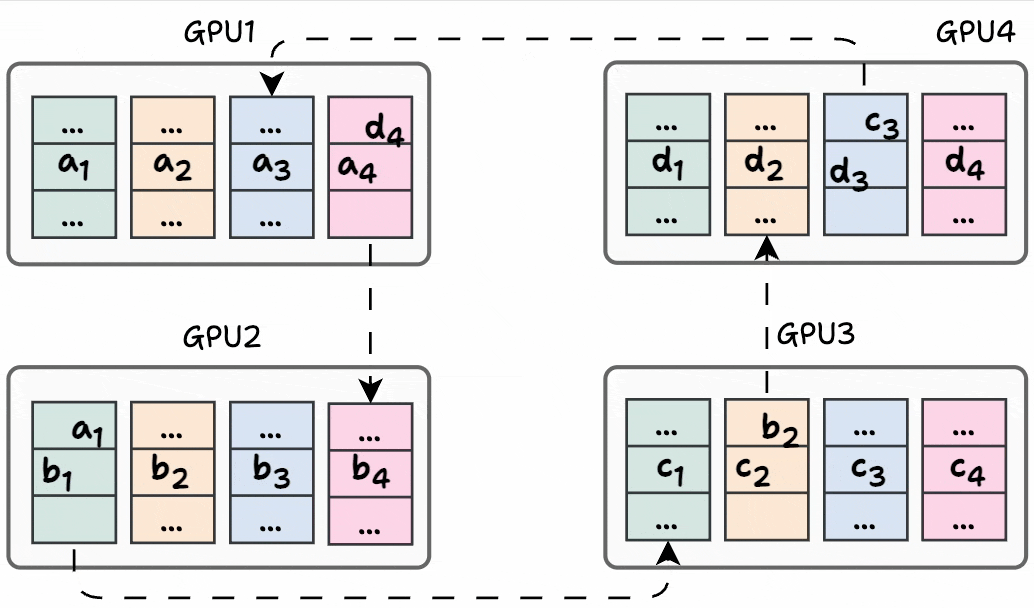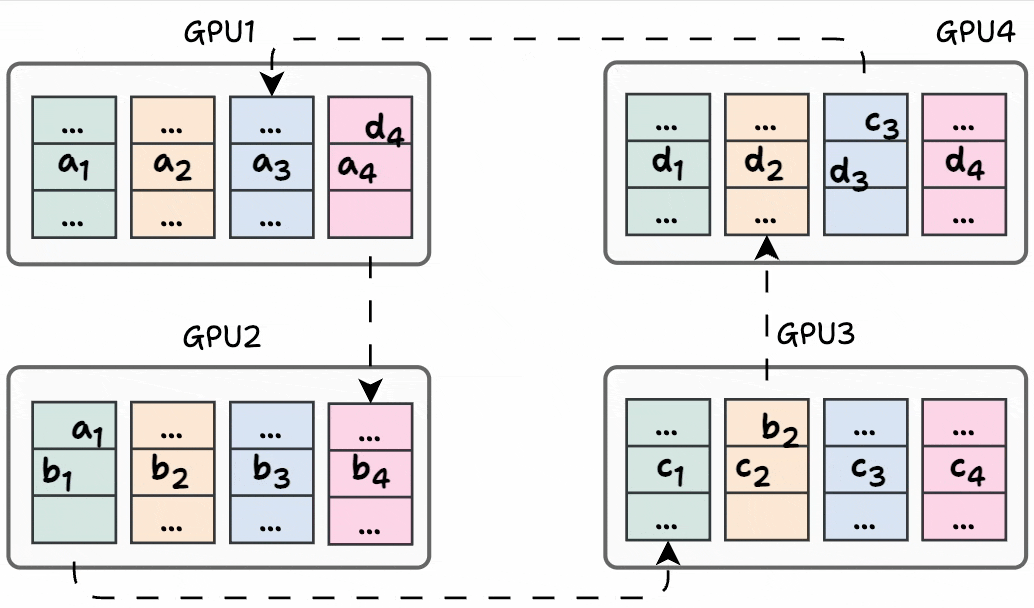
GPU1 sends a₁ to GPU2, where it gets added to b₁.
GPU2 sends b₂ to GPU3, where it gets added to c₂.
GPU3 sends c₃ to GPU4, where it gets added to d₃.
GPU4 sends d₄ to GPU1, where it gets added to a₄.
Before the start of the next iteration, the state of every GPU looks like this:

In the next iteration, a similar process is carried out again:
GPU1 sends (d₄+a₄) to GPU2, where it gets added to b₄.
GPU2 sends (a₁+b₁) to GPU3, where it gets added to c₁.
GPU3 sends (b₂+c₂) to GPU4, where it gets added to d₂.
GPU4 sends (c₃+d₃) to GPU1, where it gets added to a₃.
In the final iteration, the following segments are transferred to the next GPU:

Done!
This leads to the following state on every GPU has one entire segment:

Now, we can transfer these complete segments to all other GPUs.
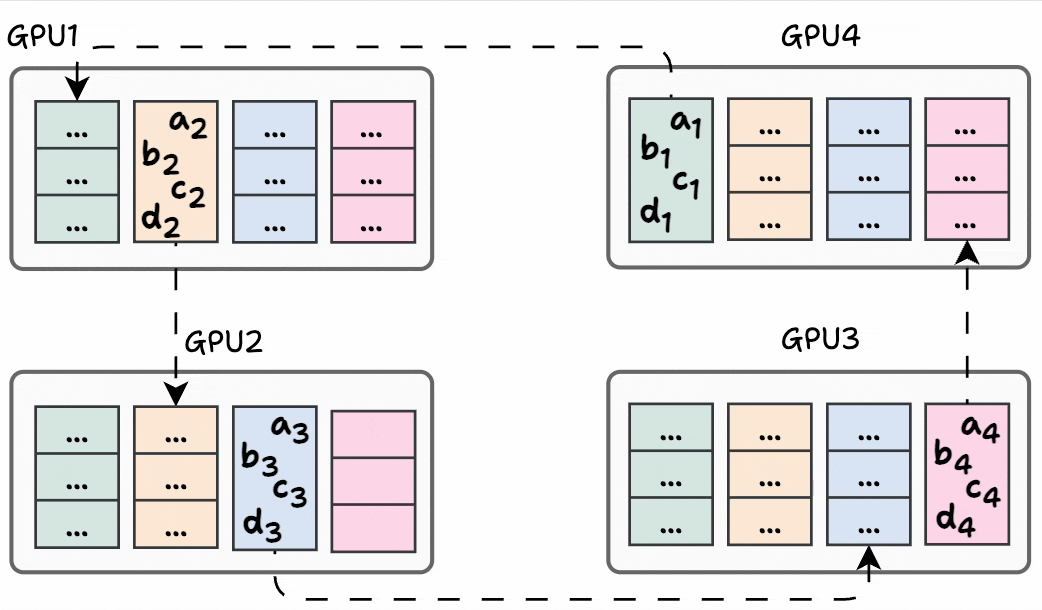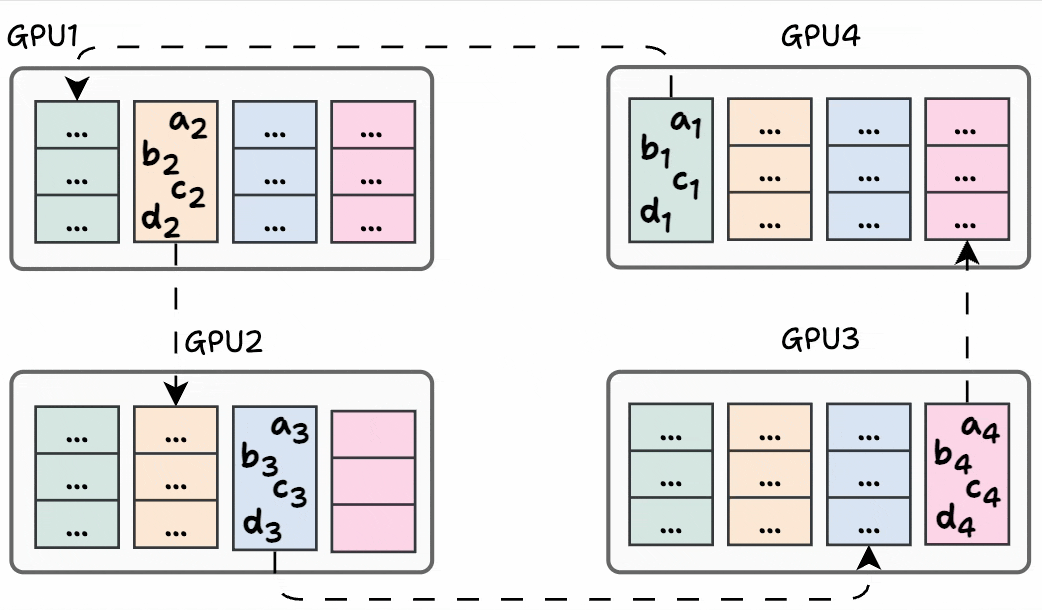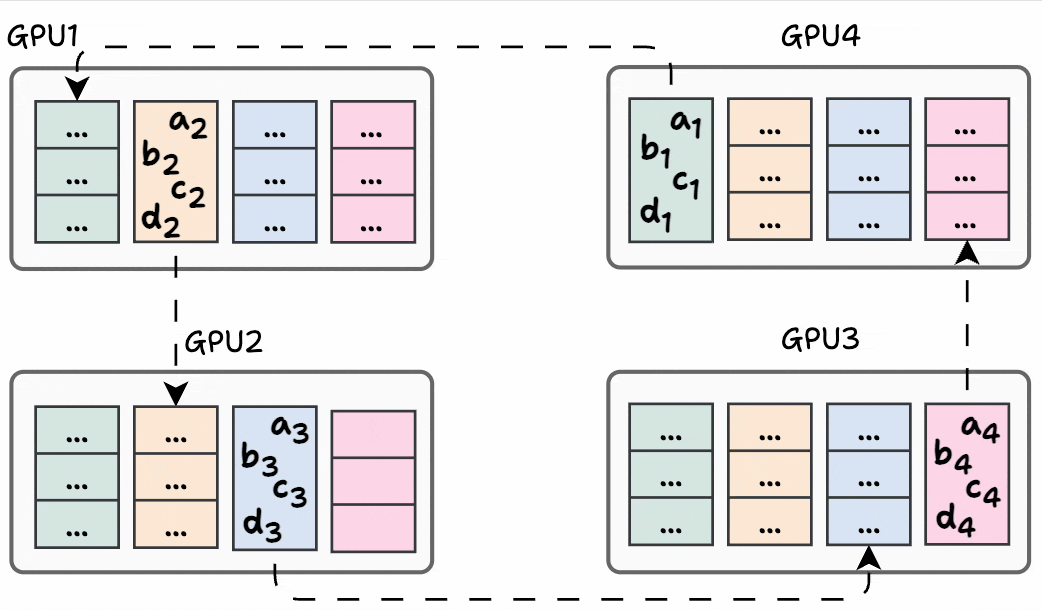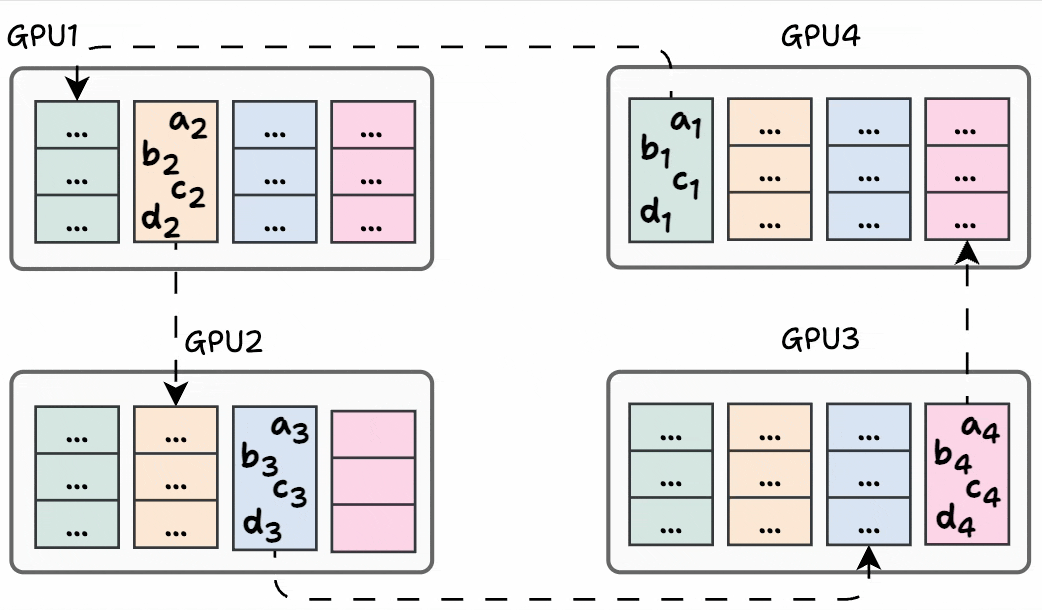
Phase #2) Share-only
The process is similar to what we discussed above, so we won’t go into full detail.
Iteration 1 is shown below:
Iteration 2 is shown below:
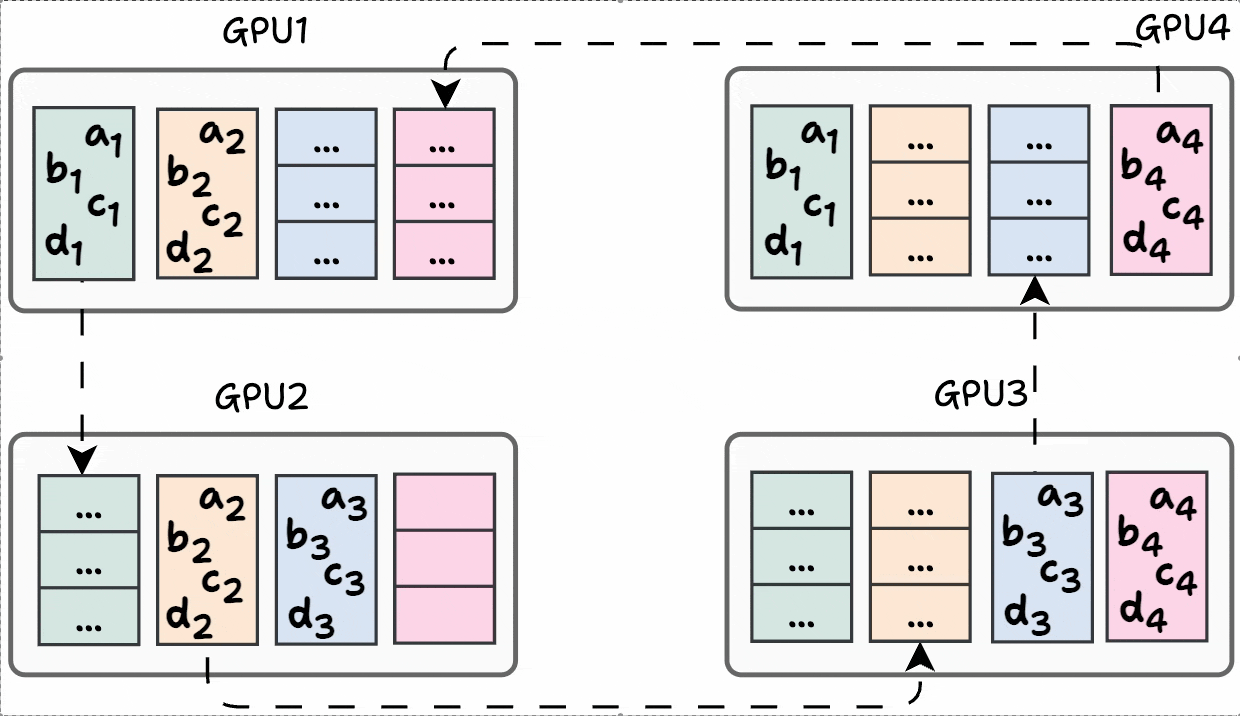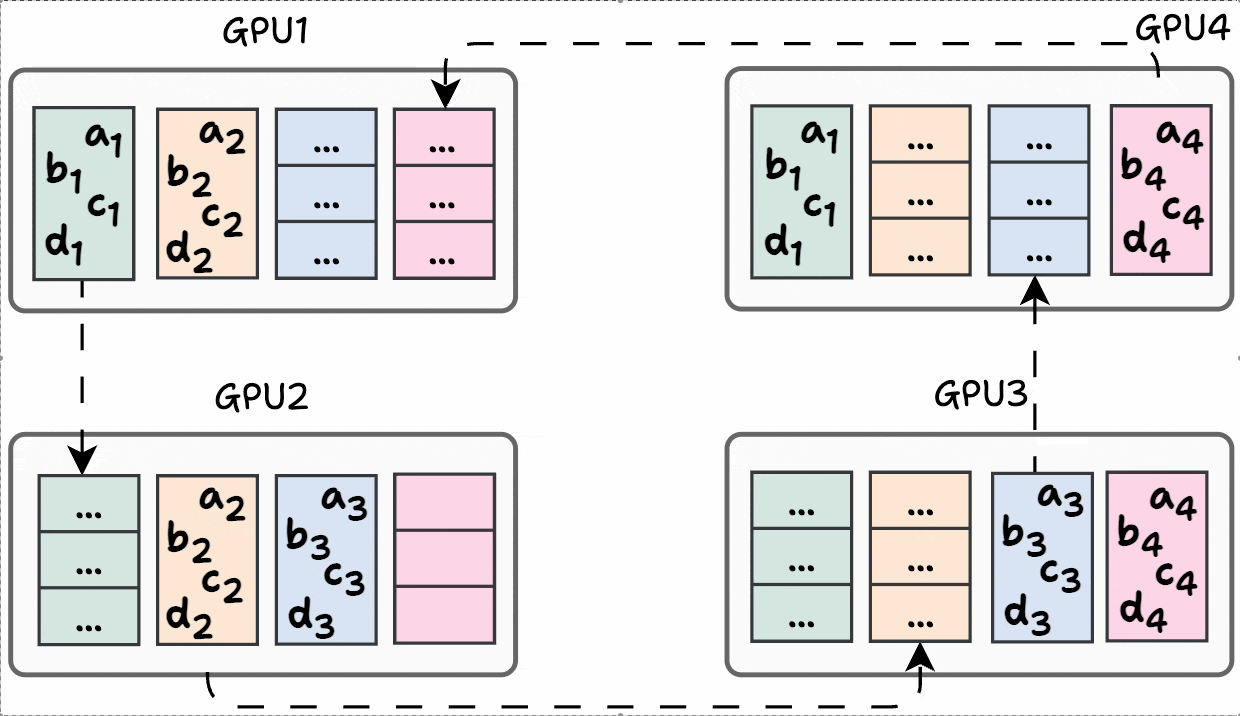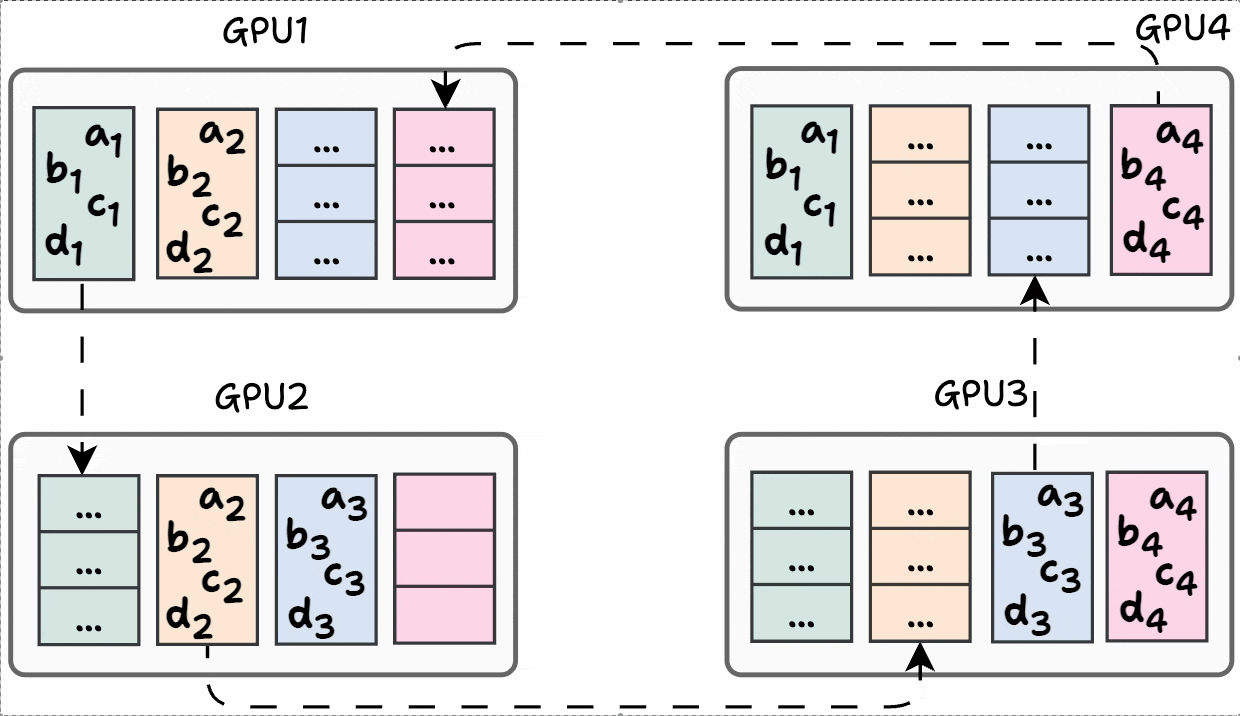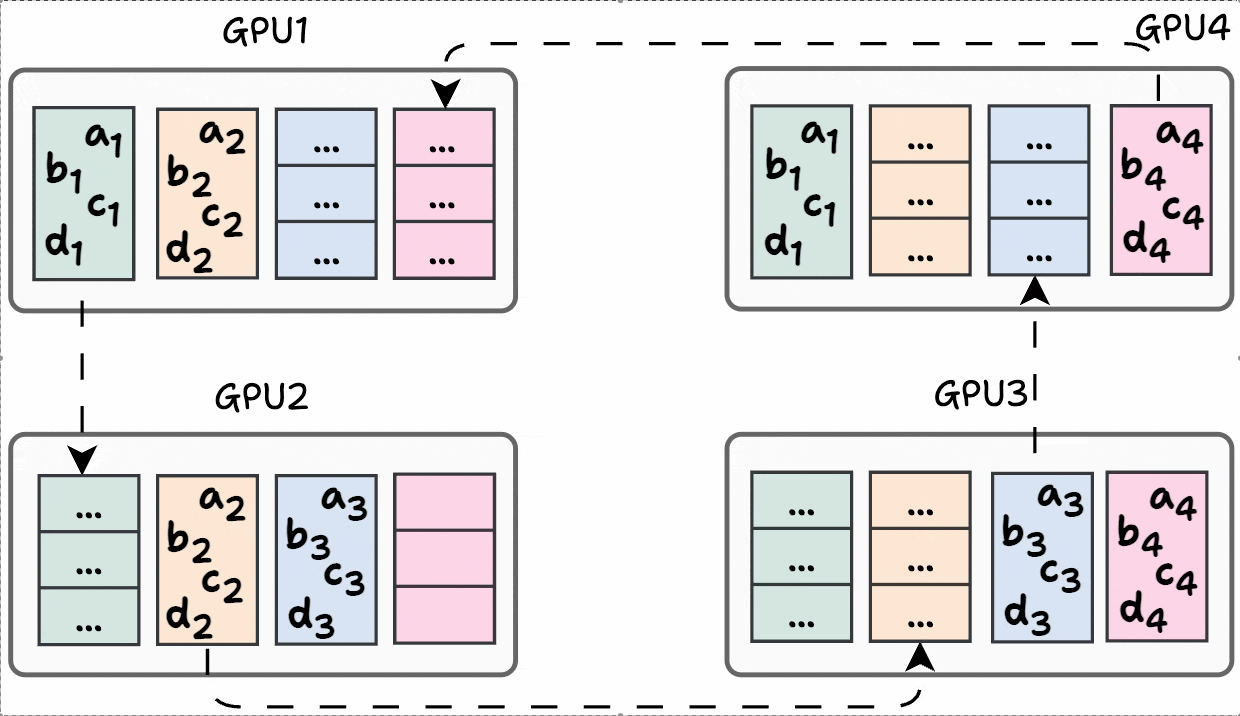
Finally, iteration 3 is shown below:
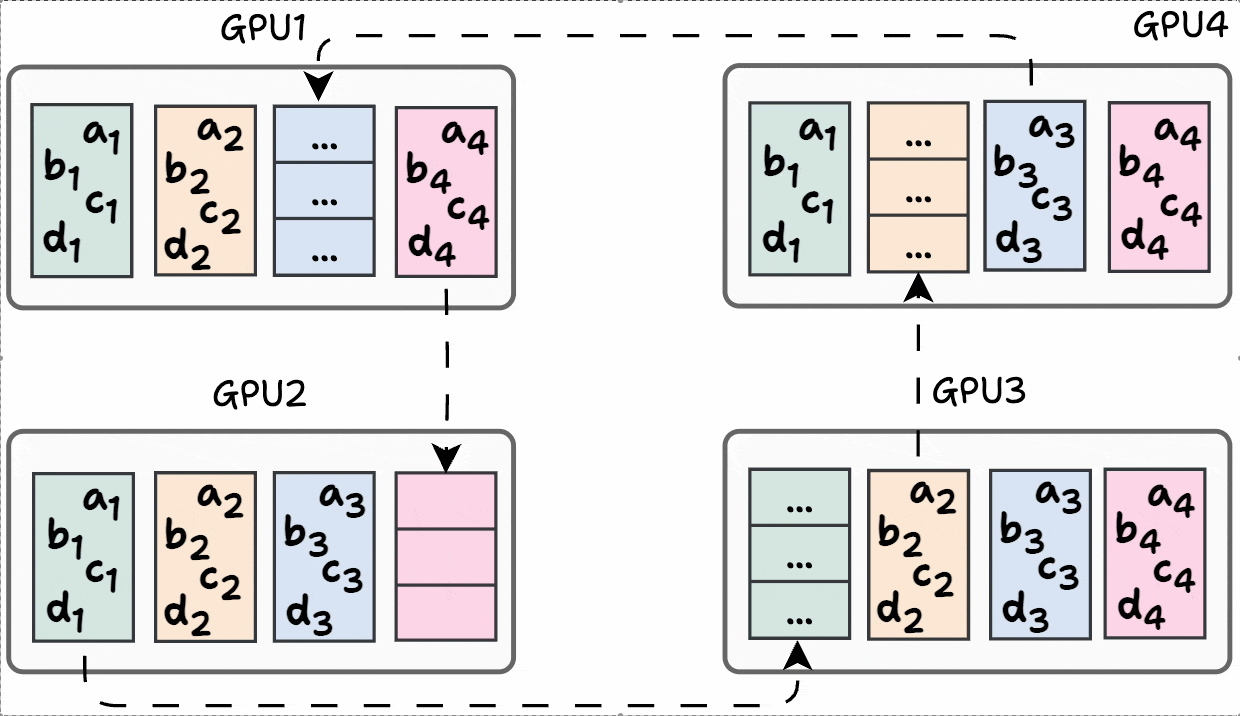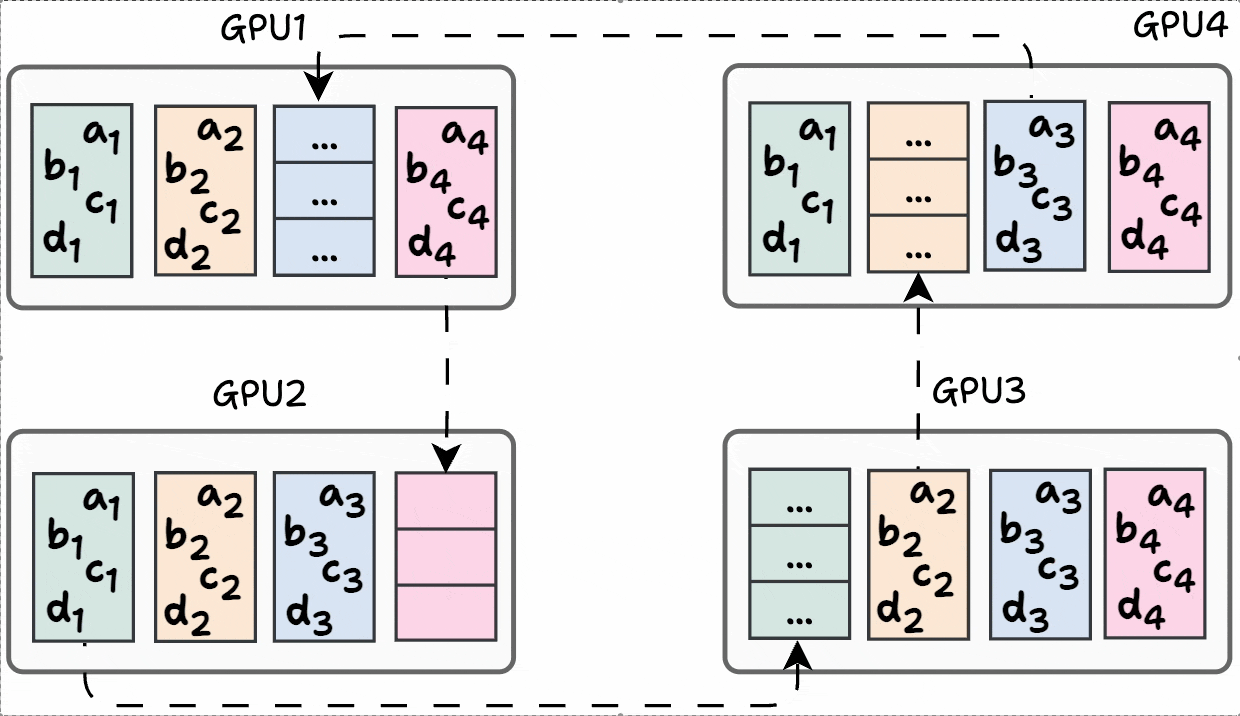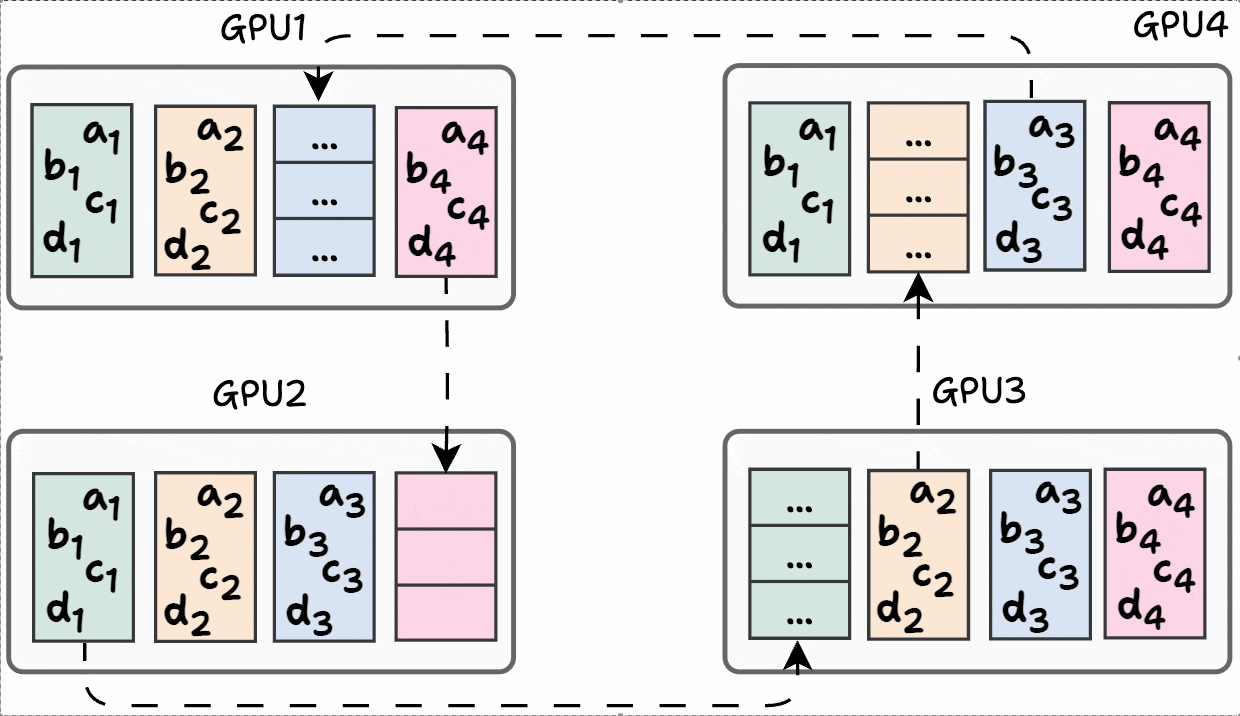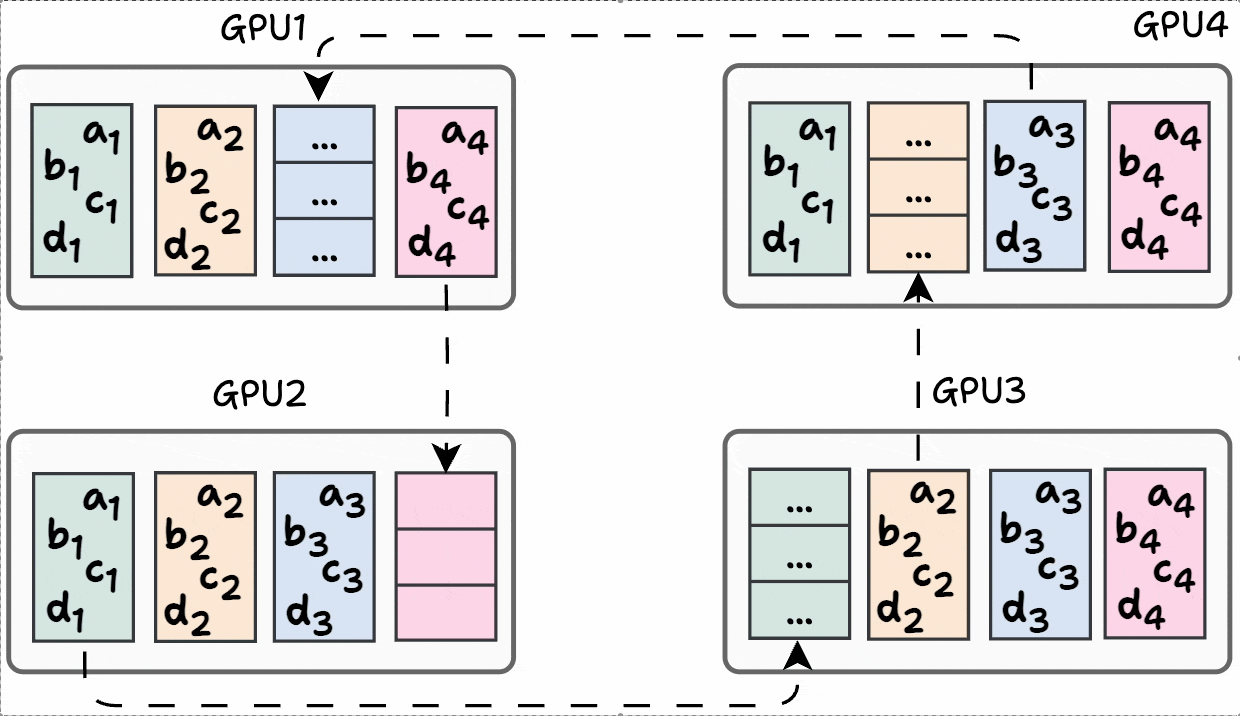
And there you go!
Model weights across GPUs have been synchronized:

While the number of elements transferred is still the same as we had in the “single-GPU-master” approach, this ring approach is much more scalable since it does not put the entire load on one GPU for communication.
If you want to get into the implementation-related details of multi-GPU training, we covered it here: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, methods like ring-reduce are only suitable for small and intermediate models.
We discussed many more advanced methods for large models here: A Practical Guide to Scaling ML Model Training.
👉 Over to you: Can you optimize ring-reduce even further?
Thanks for reading!