
25 Most Important Mathematical Definitions in Data Science
...in a single frame.

Is mathematical knowledge important in data science and machine learning?
This is a question that so many people have, especially those who are just getting started.
Short answer: Yes, it’s important, and here’s why I say so.
See…these days, one can do “ML” without understanding any mathematical details of an algorithm.
For instance (and thanks to sklearn, by the way):

One can use any clustering algorithm in 2-3 lines of code.
One can train classification models in 2-3 lines of code.
And more.
This is both good and bad:
It’s good because it saves us time.
It’s bad because this tempts us to ignore the underlying details.
In fact, I know many data scientists (mainly on the applied side) who do not entirely understand the mathematical details but can still build and deploy models.
Nothing wrong.
However, when I talk to them, I also see some disconnect between “What they are using” and “Why they are using it.”

Due to a lack of understanding of the underlying details:
They find it quite difficult to optimize their models.
They struggle to identify potential areas of improvement.
They take a longer time to debug when things don’t work well.
They do not fully understand the role of specific hyperparameters.
They use any algorithm without estimating their time complexity first.
If it feels like you are one of them, it’s okay. This problem can be solved.
That said, if you genuinely aspire to excel in this field, building a curiosity for the underlying mathematical details holds exponential returns.
Algorithmic awareness will give you confidence.
It will decrease your time to build and iterate.
Gradually, you will go from a hit-and-trial approach to “I know what should work.”
To help you take that first step, I prepared the following visual, which lists some of the most important mathematical formulations used in Data Science and Statistics (in no specific order).
Before reading ahead, look at them one by one and calculate how many of them do you already know:

Some of the terms are pretty self-explanatory, so I won’t go through each of them, like:
Gradient Descent, Normal Distribution, Sigmoid, Correlation, Cosine similarity, Naive Bayes, F1 score, ReLU, Softmax, MSE, MSE + L2 regularization, KMeans, Linear regression, SVM, Log loss.
Here are the remaining terms:
MLE (Maximum Likelihood Estimation): A method for estimating the parameters of a statistical model by maximizing the likelihood of the observed data.
To understand how it works, read this newsletter issue.
Z-score: A standardized value that indicates how many standard deviations a data point is from the mean.
Ordinary Least Squares: A closed-form solution for linear regression obtained using the MLE step mentioned above.
Entropy: A measure of the uncertainty or randomness of a random variable. It is often utilized in decision trees and the t-SNE algorithm.
Eigen Vectors: The non-zero vectors that do not change their direction when a linear transformation is applied. It is widely used in dimensionality reduction techniques like PCA. Here’s how.
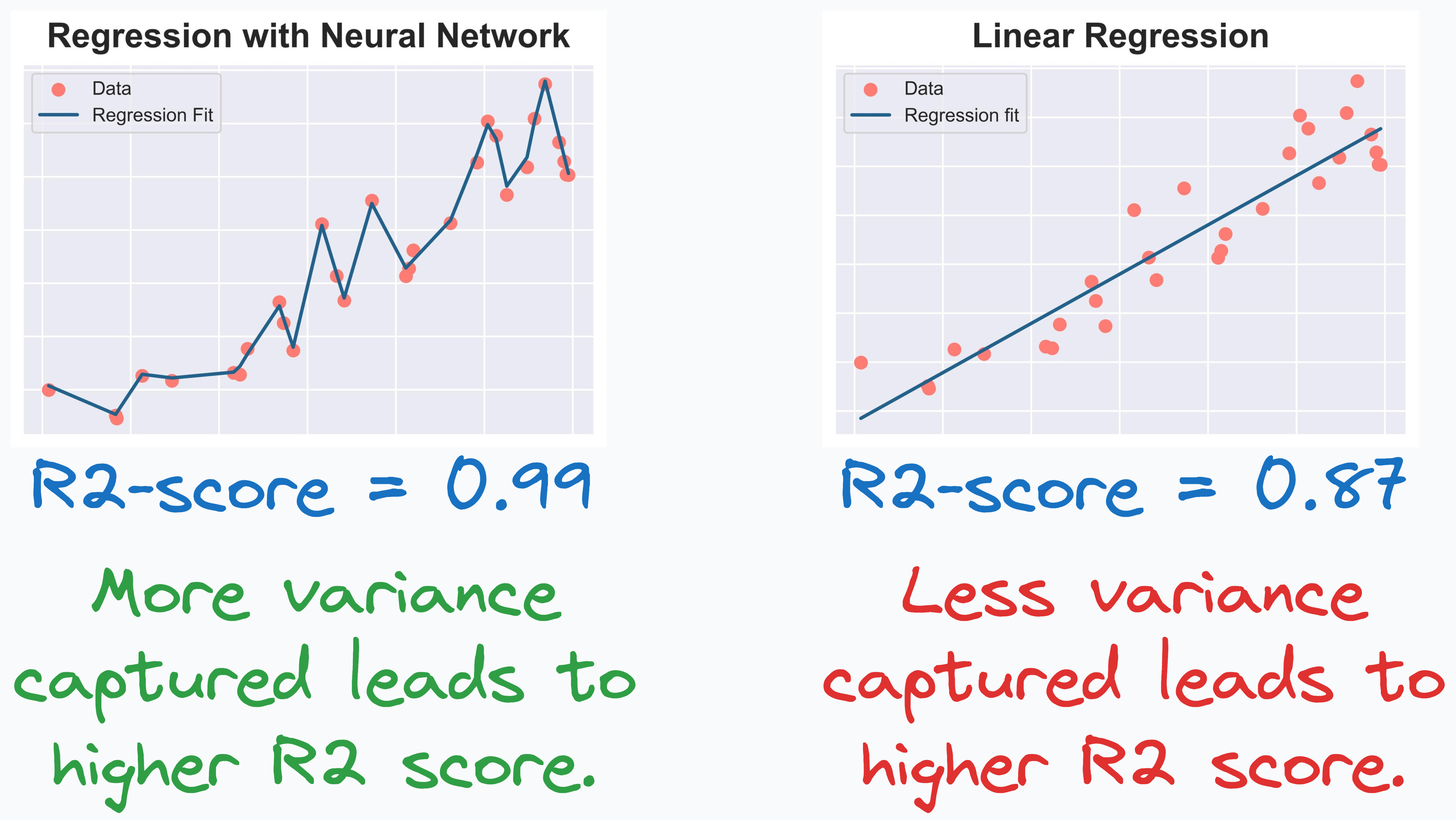
R2 (R-squared): A statistical measure that represents the proportion of variance explained by a regression model:
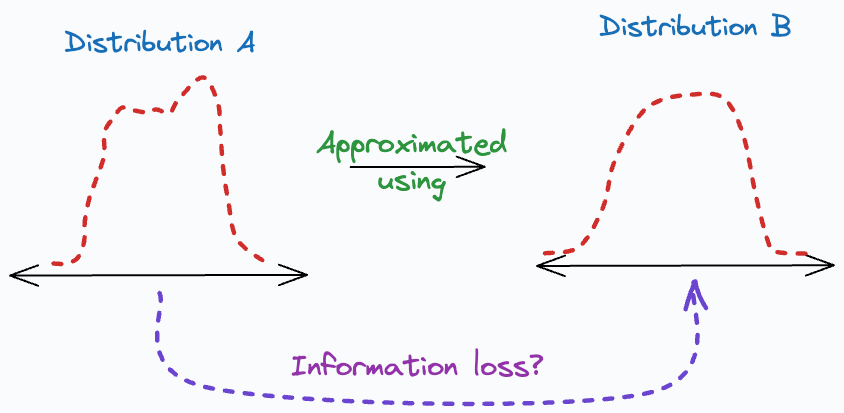
KL divergence: Assess how much information is lost when one distribution is used to approximate another distribution. It is used as a loss function in the t-SNE algorithm. We discussed it here: t-SNE article.

SVD: A factorization technique that decomposes a matrix into three other matrices, often noted as U, Σ, and V. It is fundamental in linear algebra for applications like dimensionality reduction, noise reduction, and data compression.
Lagrange multipliers: They are commonly used mathematical techniques to solve constrained optimization problems.
For instance, consider an optimization problem with an objective function
f(x)and assume that the constraints areg(x)=0andh(x)=0. Lagrange multipliers help us solve this.

We covered them in detail here.

How many terms did you know? Let me know.
Here are some of the questions I am leaving you with today.
Have you ever wondered:
Where did L2 regularization originate from? Why did someone say that adding a square term will reduce model complexity? Here’s the mathematical origin.
Why sklearn’s logistic regression has no learning rate hyperparamter? Here is the answer.
Why do we use mean squared error (MSE)? Here is the mathematical answer.
Why do we use log-loss in logistic regression? Here is the mathematical answer.
How can trigonometry help you build robust ML models? Here’s the answer.
👉 Over to you: Of course, this is not an all-encompassing list. What other mathematical definitions will you include here?
Thanks for reading!
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)