
3 Techniques to Train An LLM Using Another LLM
(techniques used in DeepSeek, Llama 4 & Gemma 3)

Track and debug any LLM app in 2 lines of code!
If you are building LLM apps, you absolutely need observability!
LangWatch simplifies this with its fully integrated OpenTelemetry SDK.
Takes just a few lines of code to integrate.
Works with all your LLMs and agent frameworks.
Gives full pipeline visibility, from databases to microservices.
Provides real-time debugging logs to quickly identify and fix issues.
Connects directly with Evaluations to monitor performance of LLM apps.
Check this code snippet:

Decorate your LLM application method with the
@tracedecorator.Enable provider-specific autotracking in the function, and done!
Check the open-source GitHub repo here (don’t forget to star it) →
3 Techniques to Train An LLM Using Another LLM
LLMs don't just learn from raw text; they also learn from each other:
Llama 4 Scout and Maverick were trained using Llama 4 Behemoth.
Gemma 2 and 3 were trained using Google's proprietary Gemini.
Distillation helps us do so, and the visual below depicts three popular techniques.
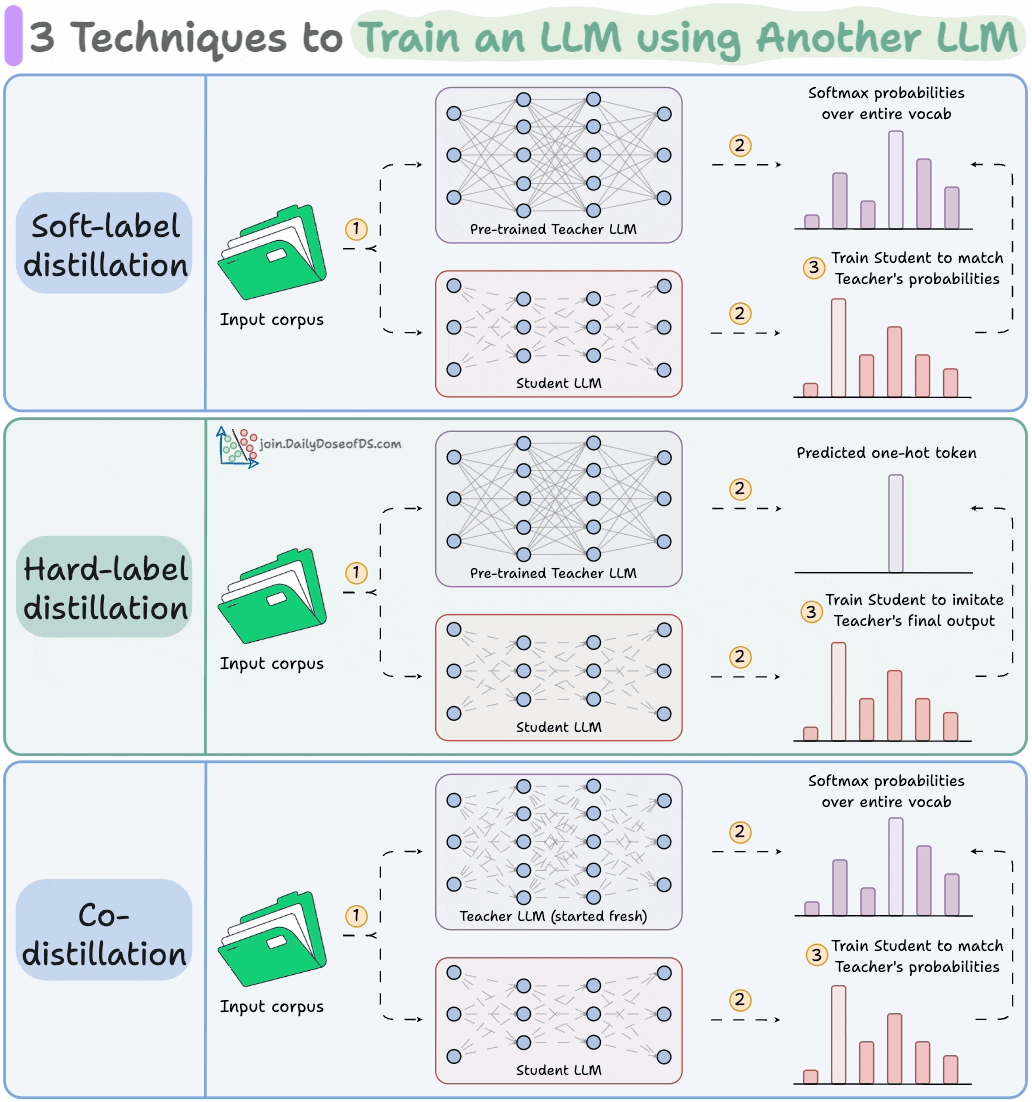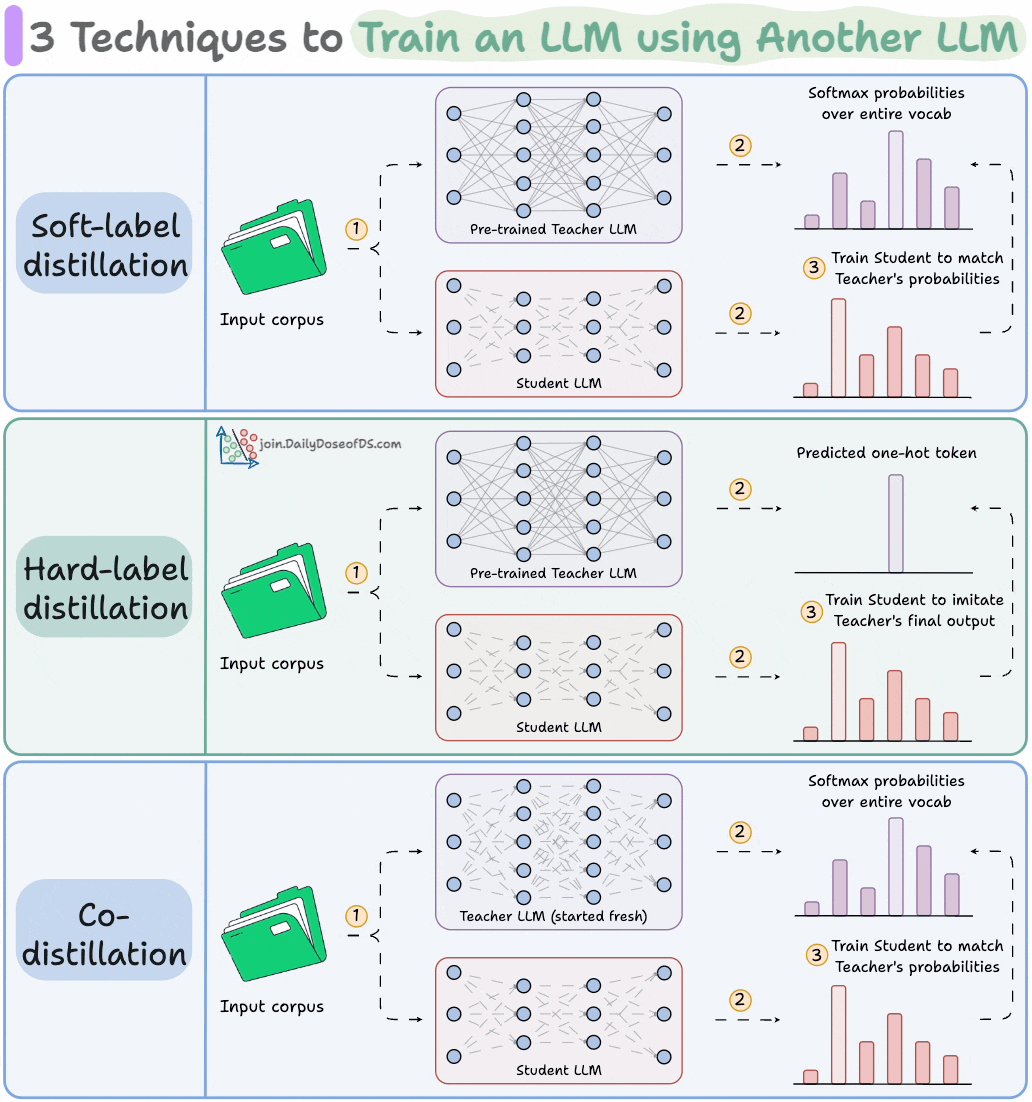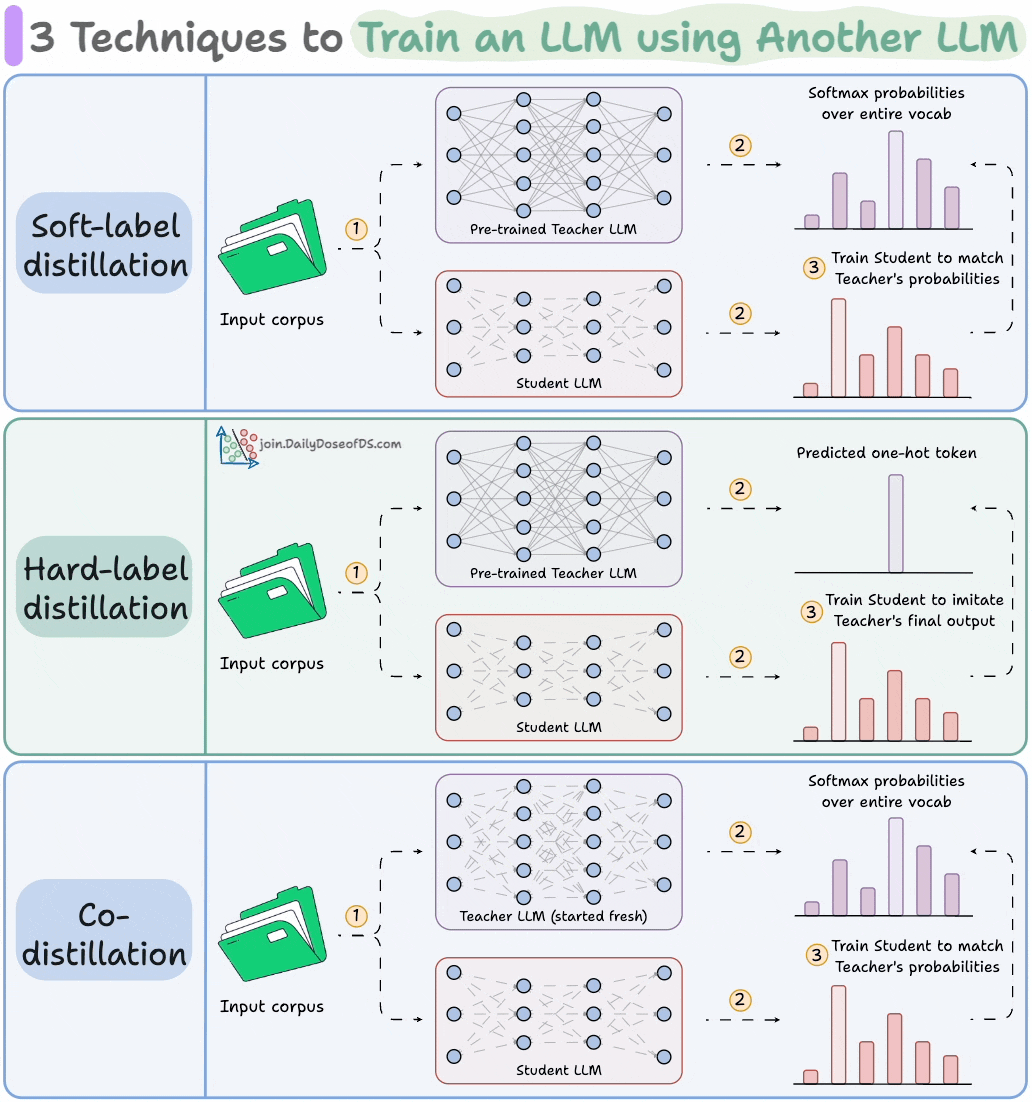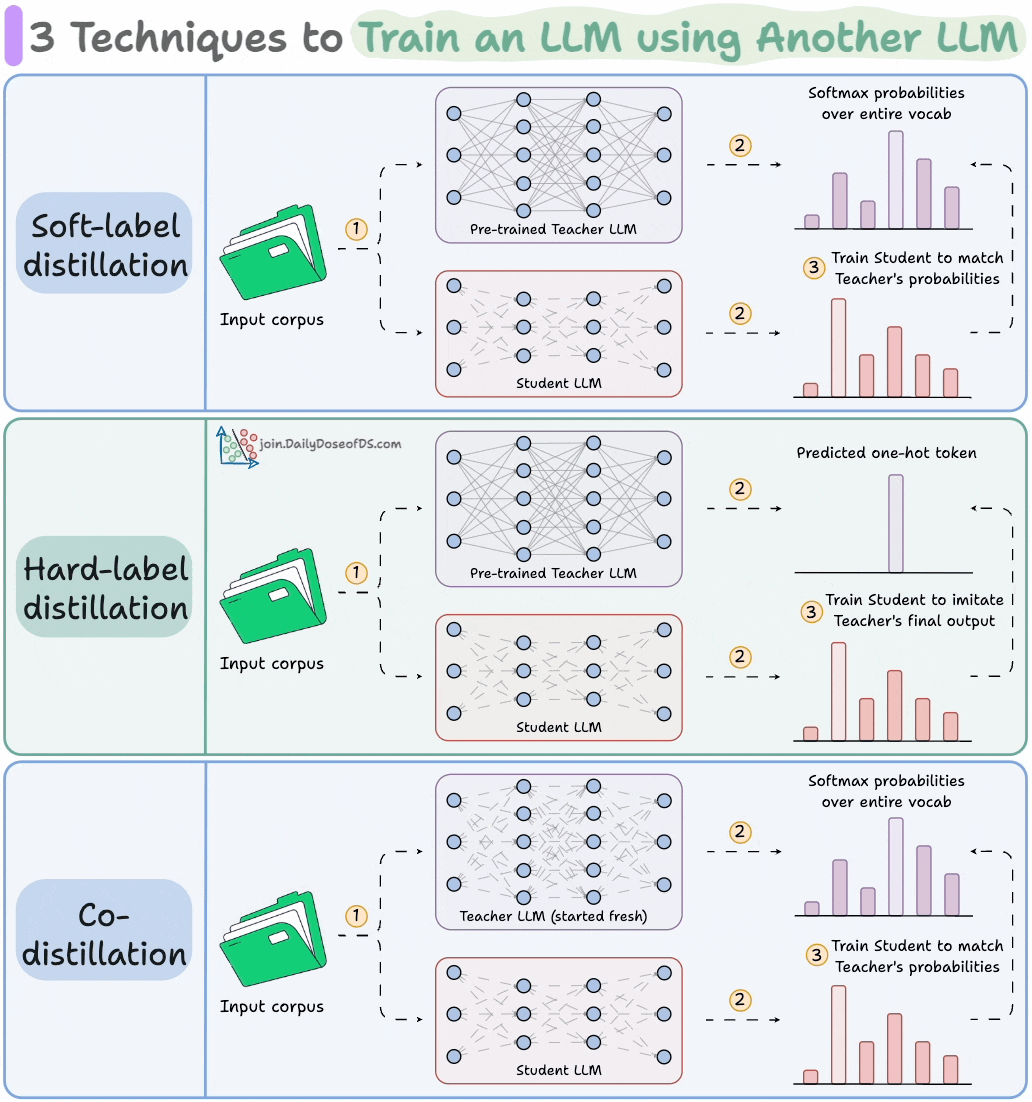
The idea is to transfer "knowledge" from one LLM to another, which has been quite common in traditional deep learning (like we discussed here).
Distillation in LLMs can happen at two stages:
Pre-training
Train the bigger Teacher LLM and the smaller student LLM together.
Llama 4 did this.
Post-training:
Train the bigger Teacher LLM first and distill its knowledge to the smaller student LLM.
DeepSeek did this by distilling DeepSeek-R1 into Qwen and Llama 3.1 models.
You can also apply distillation during both stages, which Gemma 3 did.
Here are the three commonly used distillation techniques:
1) Soft-label distillation:

Use a fixed pre-trained Teacher LLM to generate softmax probabilities over the entire corpus.
Pass this data through the untrained Student LLM as well to get its softmax probabilities.
Train the Student LLM to match the Teacher's probabilities.
Visibility over the Teacher's probabilities ensures maximum knowledge (or reasoning) transfer.
However, you must have access to the Teacher’s weights to get the output probability distribution.
Even if you have access, there's another problem!
Say your vocab size is 100k tokens and your data corpus is 5 trillion tokens.
Since we generate softmax probabilities of each input token over the entire vocabulary, you would need 500 million GBs of memory to store soft labels under float8 precision.
The second technique solves this.
2) Hard-label distillation
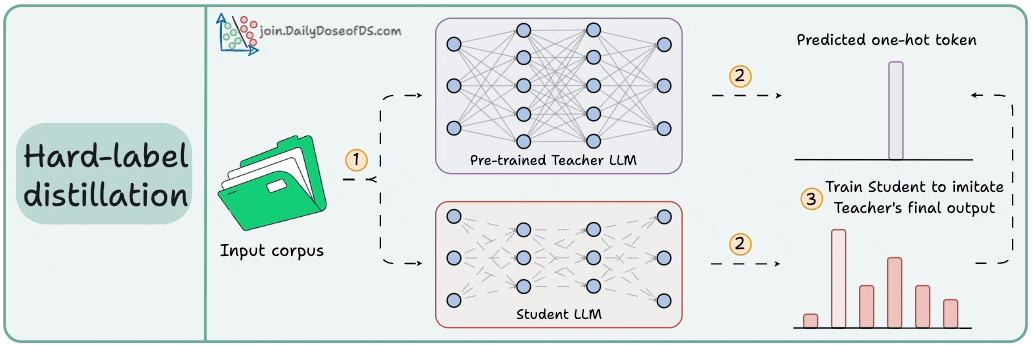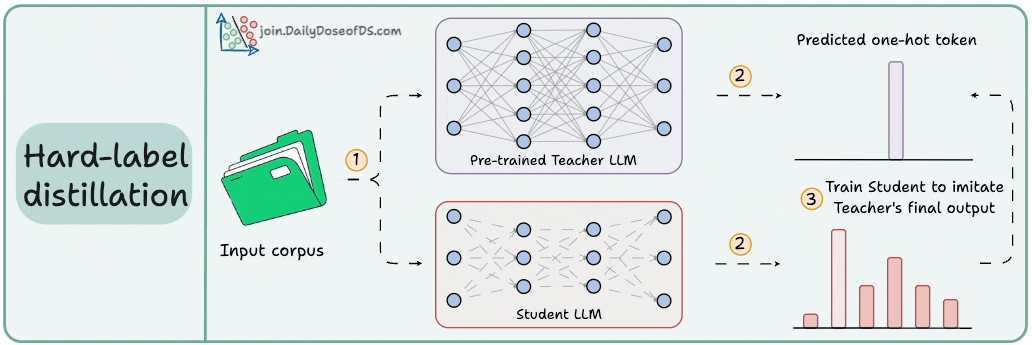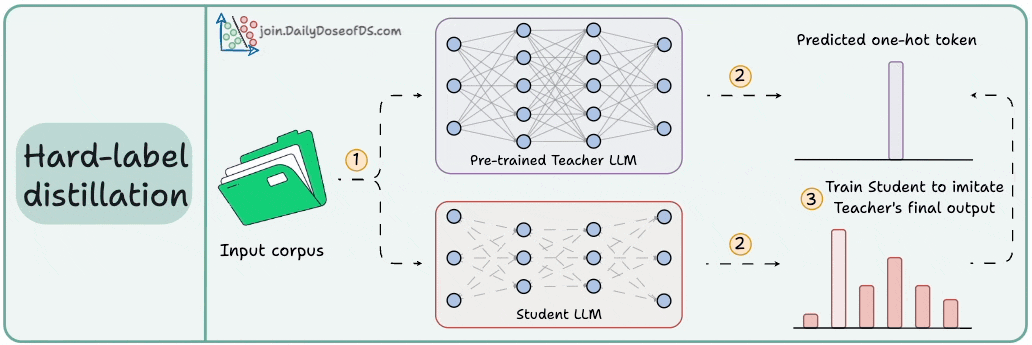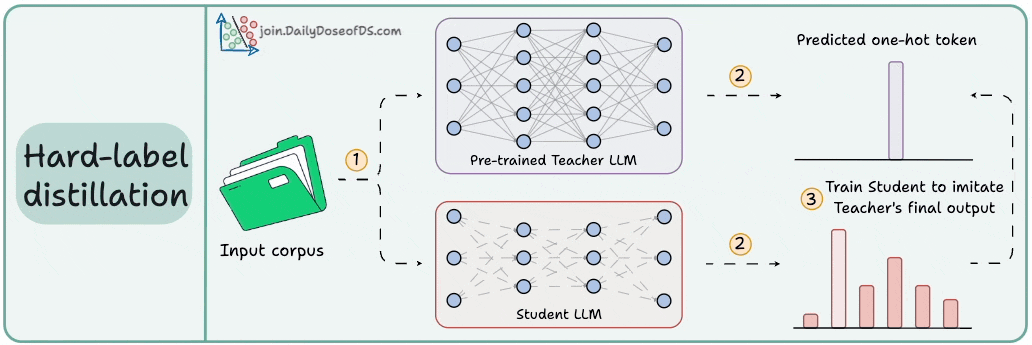
Use a fixed pre-trained Teacher LLM to just get the final one-hot output token.
Use the untrained Student LLM to get the softmax probabilities from the same data.
Train the Student LLM to match the Teacher's probabilities.
DeepSeek did this by distilling DeepSeek-R1 into Qwen and Llama 3.1 models.
3) Co-distillation
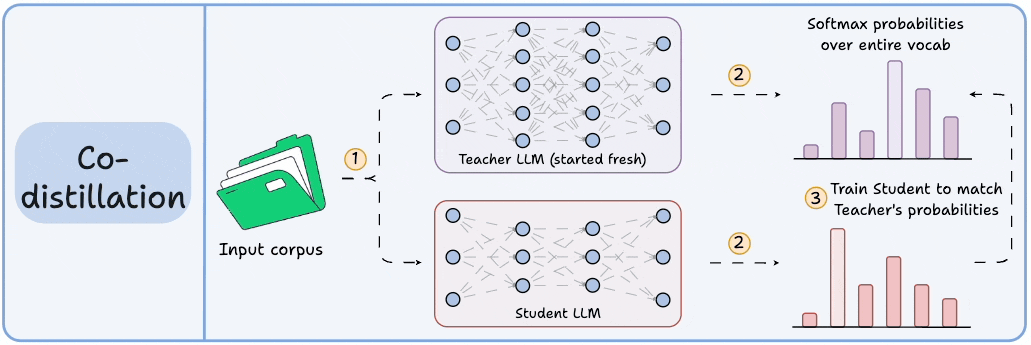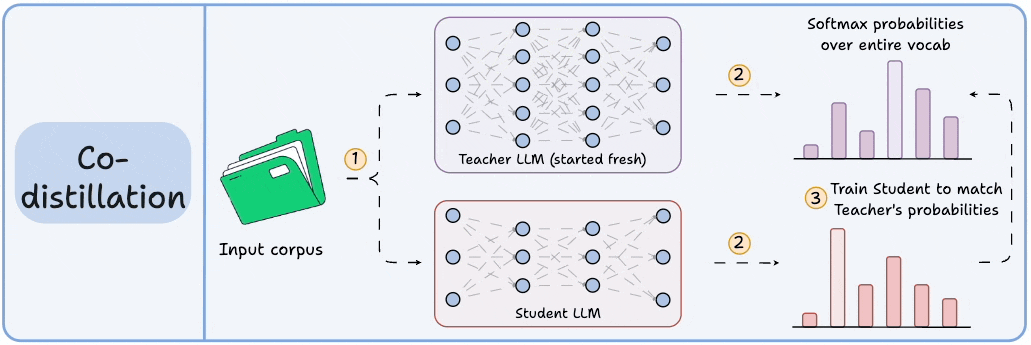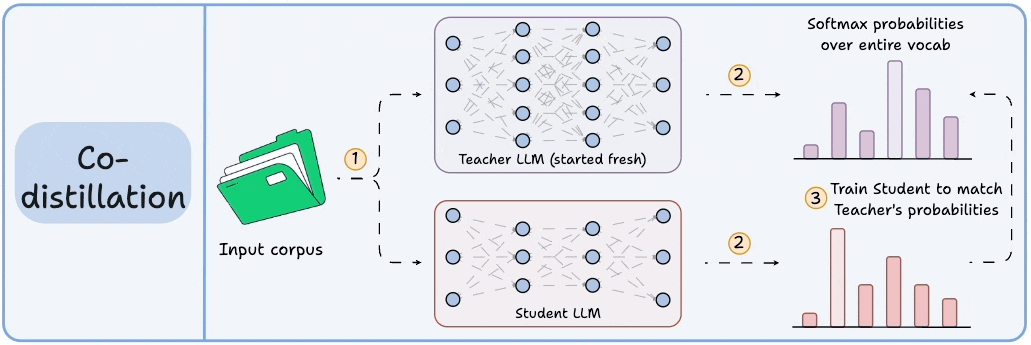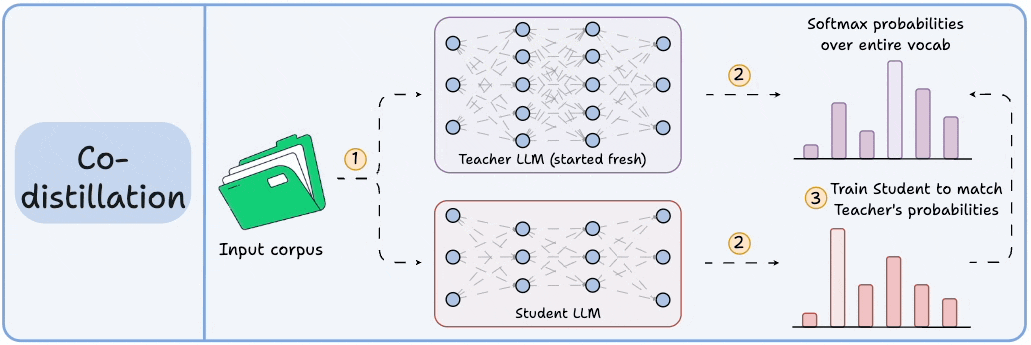
Start with an untrained Teacher LLM and an untrained Student LLM.
Generate softmax probabilities over the current batch from both models.
Train the Teacher LLM as usual on the hard labels.
Train the Student LLM to match its softmax probabilities to those of the Teacher.
Llama 4 did this to train Llama 4 Scout and Maverick from Llama 4 Behemoth.
Of course, during the initial stages, soft labels of the Teacher LLM won't be accurate.
That is why Student LLM is trained using both soft labels + ground-truth hard labels.
👉 Over to you: Which technique do you find the most promising?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in an ongoing crash course with 13 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.