
4 LLM Text Generation Strategies
...explained visually.

A visual canvas to build AI workflows!
Postman’s AI Agent Builder provides a suite of tools that streamline agent development. Developers can integrate from 100,000+ APIs on the Postman network in less than a minute.
One interesting feature is the visual, no-code canvas to quickly build, configure, and test multi-step AI workflows.
To understand better, imagine you have a customer support workflow:
It accepts the user query.
Retrieves relevant context (from past conversations, docs, etc.)
Decide if the context is relevant (this is a conditional):
If yes, it produces a response and returns it to the user.
If not, it notifies the human support team.
As shown in the video below, you can build these workflows inside Postman’s AI Agent Builder and test all integrations to ensure they run as expected:
This way, AI developers can only do what they are supposed to: build agentic workflows and improve them without worrying about integration and testing challenges.
Thanks to Postman for partnering today!
4 LLM Text Generation Strategies
Every time you prompt an LLM, it doesn’t “know” the whole sentence in advance. Instead, it predicts the next token step by step.
But here’s the catch: predicting probabilities is not enough. We still need a strategy to pick which token to use at each step.
And different strategies lead to very different styles of output.
Here are the 4 most common strategies for text generation:
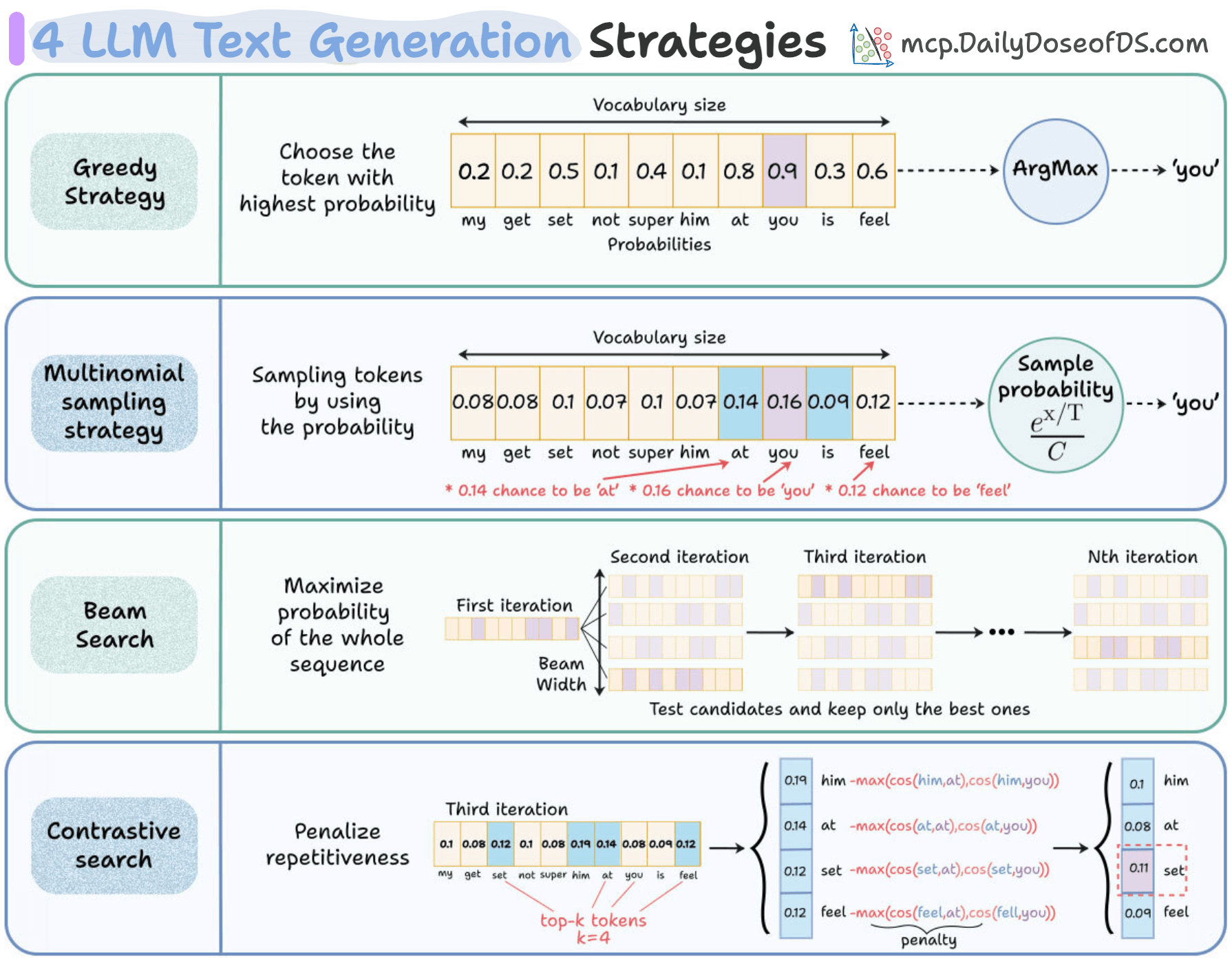
Approach 1: Greedy strategy
The naive approach greedily chooses the word with the highest probability from the probability vector, and autoregresses. This is often not ideal since it leads to repetitive sentences.
Approach 2: Multinomial sampling strategy
Instead of always picking the top token, we can sample from the probability distribution available in the probability vector.
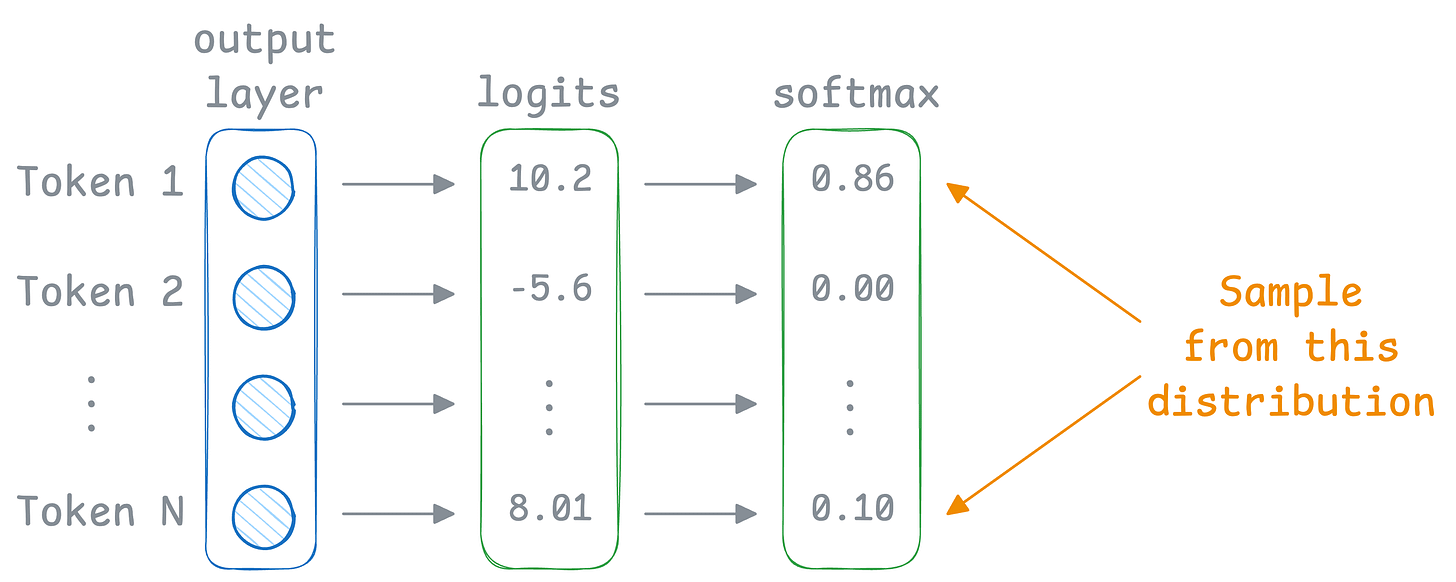
The temperature parameter controls the randomness in the generation (covered in detail here).
Approach 3: Beam search
Both approach 1 and approach 2 have a problem. They only focus on the most immediate token to be generated. Ideally, we care about maximizing the probability of the whole sequence, not just the next token.
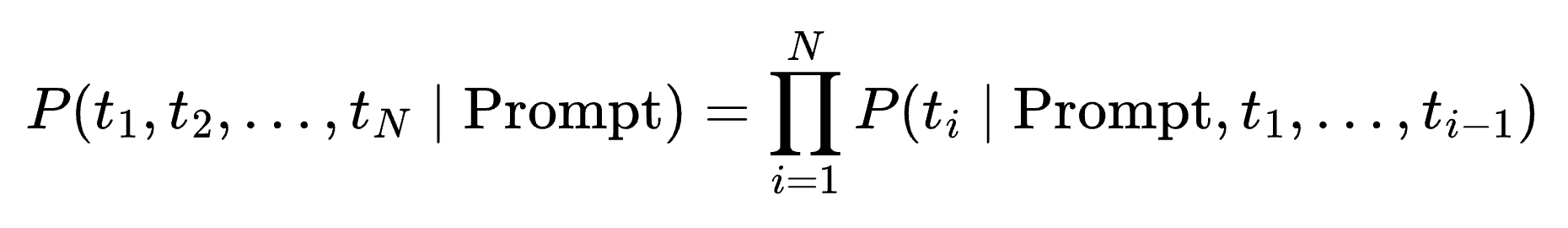
To maximize this product, you’d need to know future conditionals (what comes after each candidate).
But when decoding, we only know probabilities for the next step, not the downstream continuation.
Beam search tries to approximate the true global maximization:

At each step, it expands the top k partial sequences (the beam).
Some beams may have started with less probable tokens initially, but lead to much higher-probability completions.
By keeping alternatives alive, beam search explores more of the probability tree.
This is widely used in tasks like machine translation, where correctness matters more than creativity.
Approach 4: Contrastive search

This is a newer method that balances fluency with diversity.
Essentially, it penalizes repetitive continuations by checking how similar a candidate token is to what’s already been generated to have more diversity in the output.
At each step, the model considers candidate tokens.
Applies a penalty if the token is too similar to what’s already been generated.
Selects the token that balances probability and diversity.
This way, it also prevents “stuck in a loop” problems while keeping coherence high.
It’s especially effective for longer generations like stories, where repetition can easily creep in.
👉 Over to you: Which decoding strategy have you found most effective in your projects?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.