
4 Stages of Training LLMs from Scratch
...explained with visuals.

Apply LLMs to any Audio File in 5 lines of code
Using AssemblyAI’s LeMUR, you can apply LLMs to query, summarize, or generate any info about any audio file.
Here’s how it works:
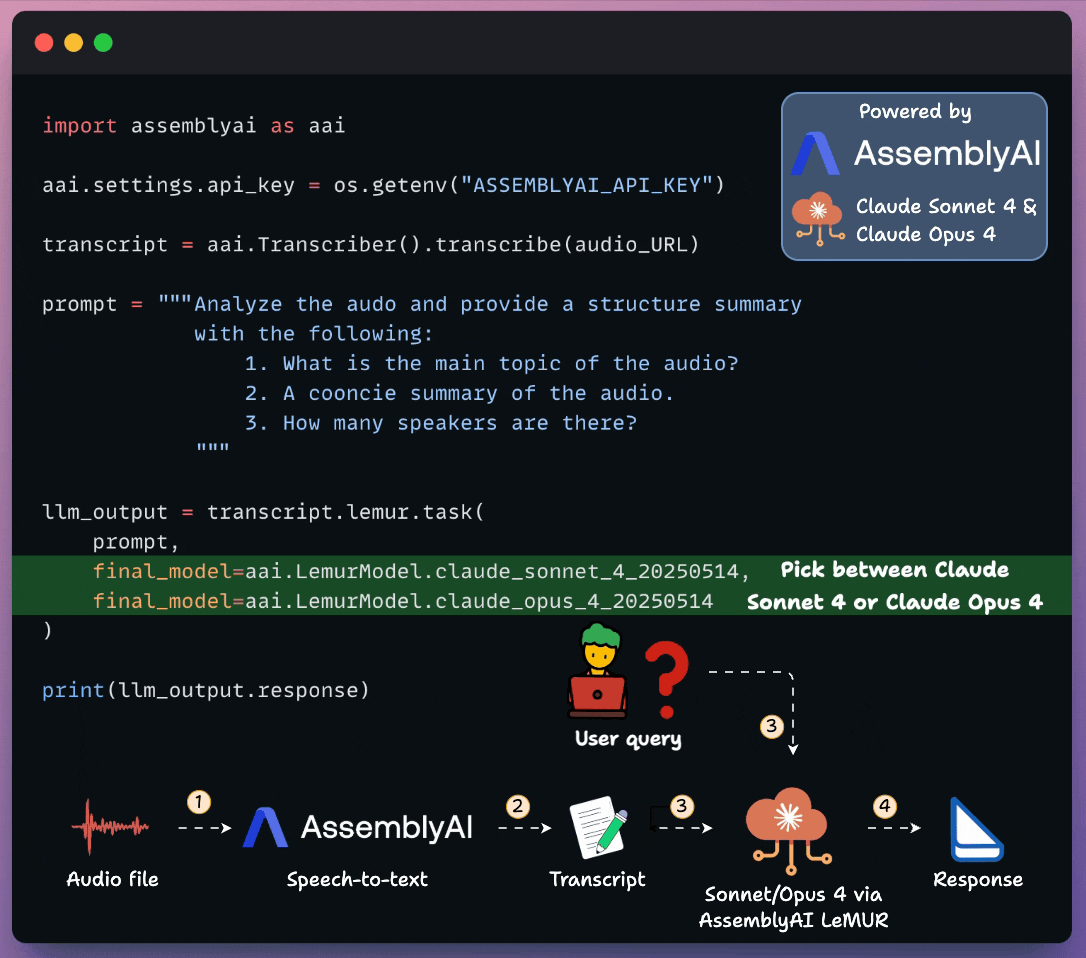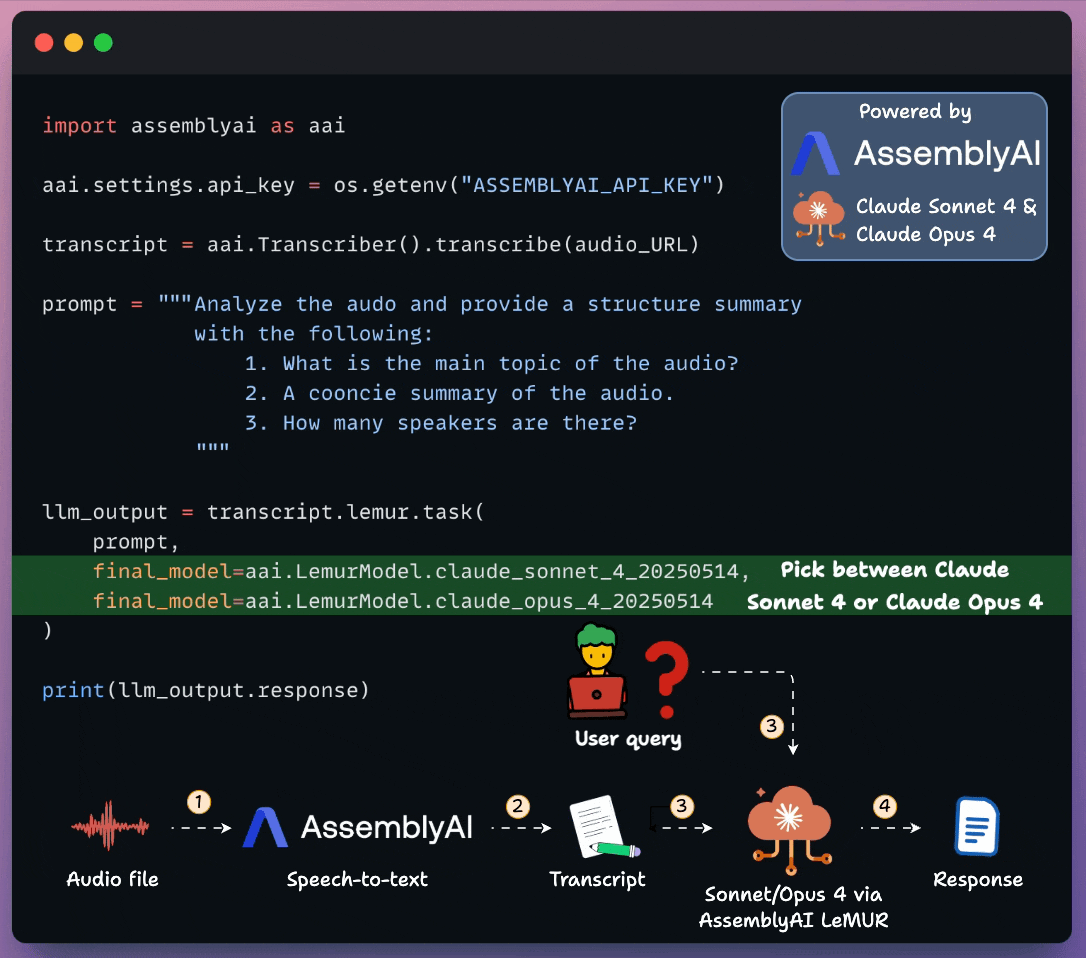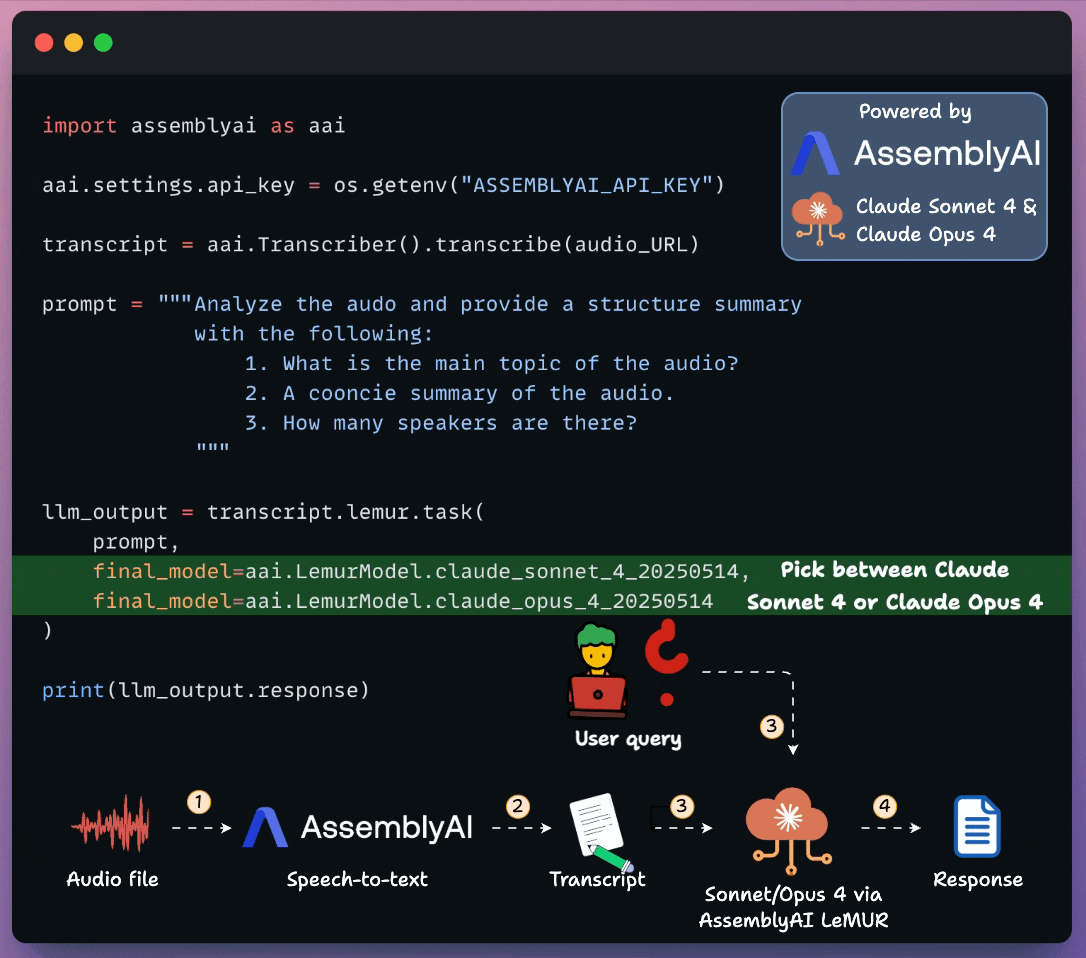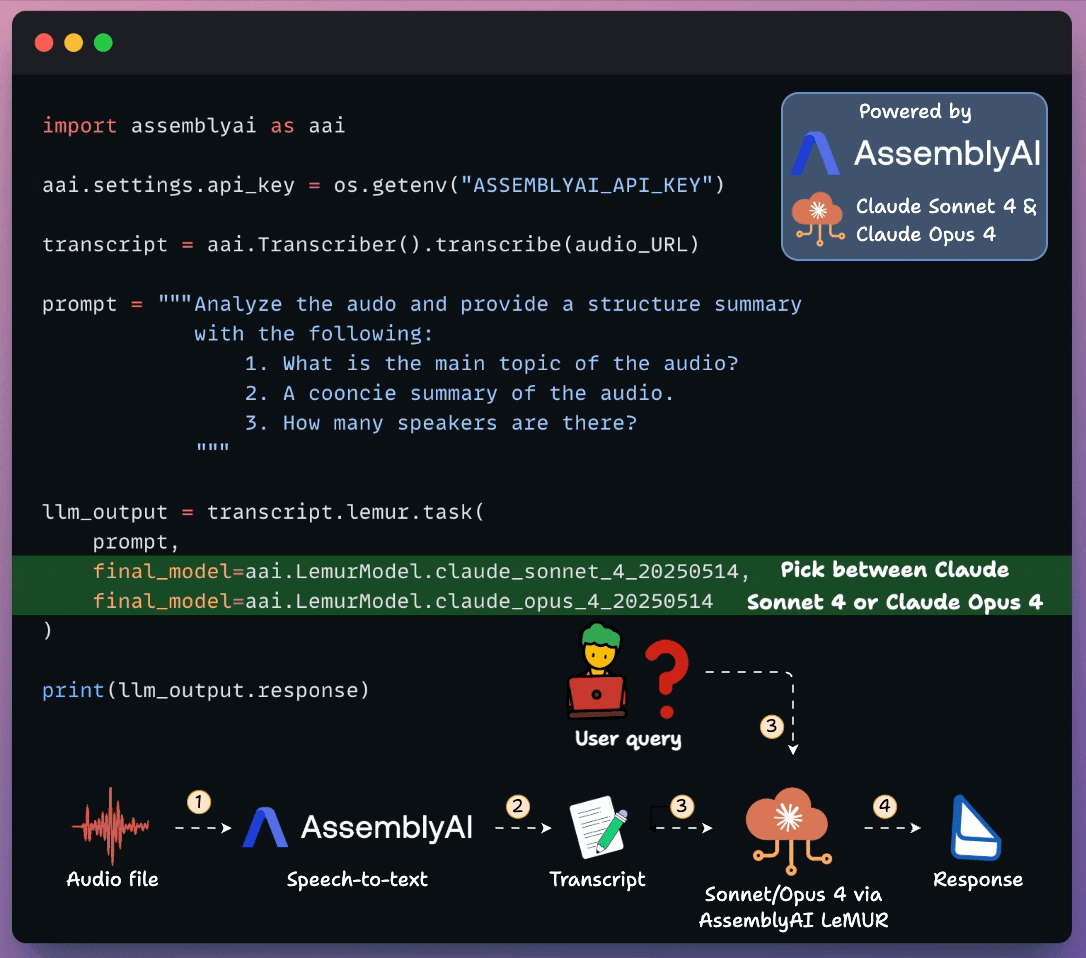
Specify an audio URL.
Use AssemblyAI's speech-to-text for transcription.
Pass it to LeMUR with your prompt. Two latest additions to LeMUR are:
Claude 4 Sonnet.
Claude 4 Opus (Anthropic’s most capable model yet).
Receive the info you asked for..
Try it here and get 100+ hours of FREE transcription →
Read more in the documentation →
Thanks to AssemblyAI for partnering today!
4 stages of training LLMs from scratch
Today, we are covering the 4 stages of building LLMs from scratch that are used to make them applicable for real-world use cases.
We’ll cover:
Pre-training
Instruction fine-tuning
Preference fine-tuning
Reasoning fine-tuning
The visual summarizes these techniques.
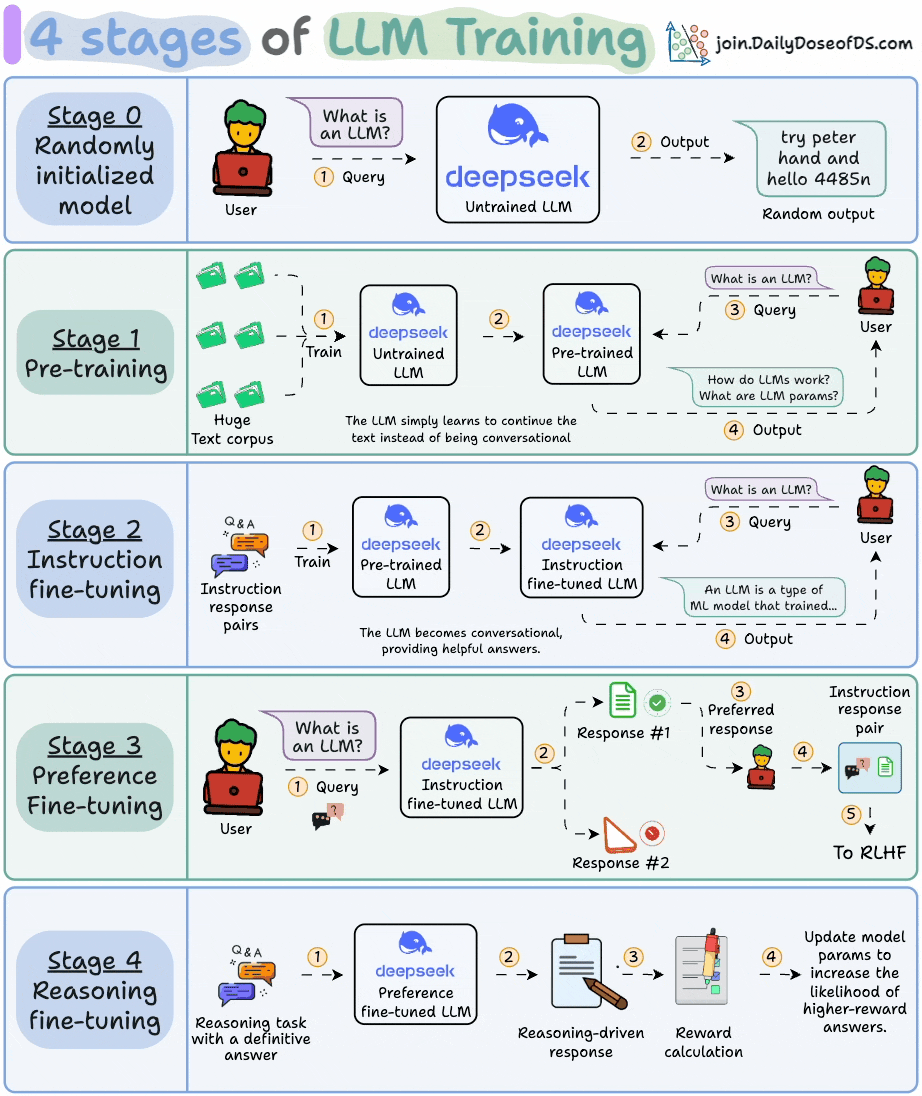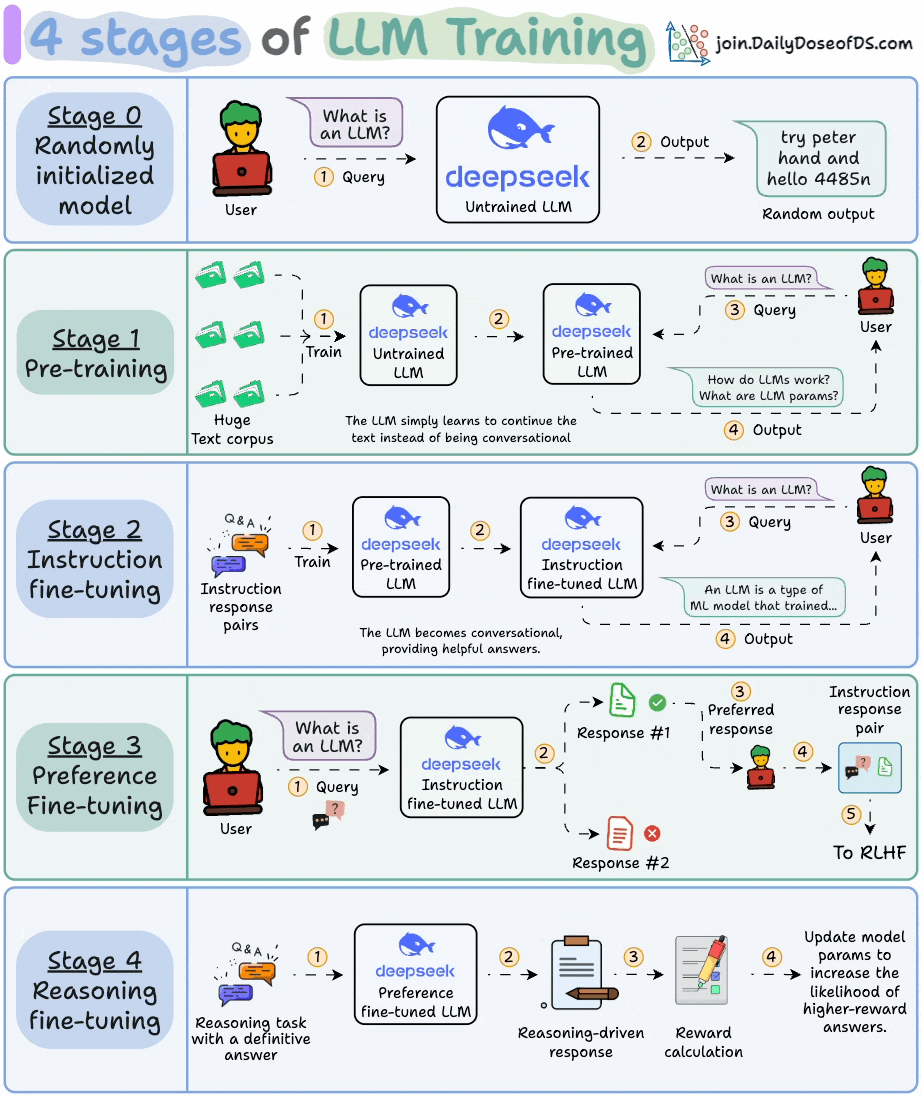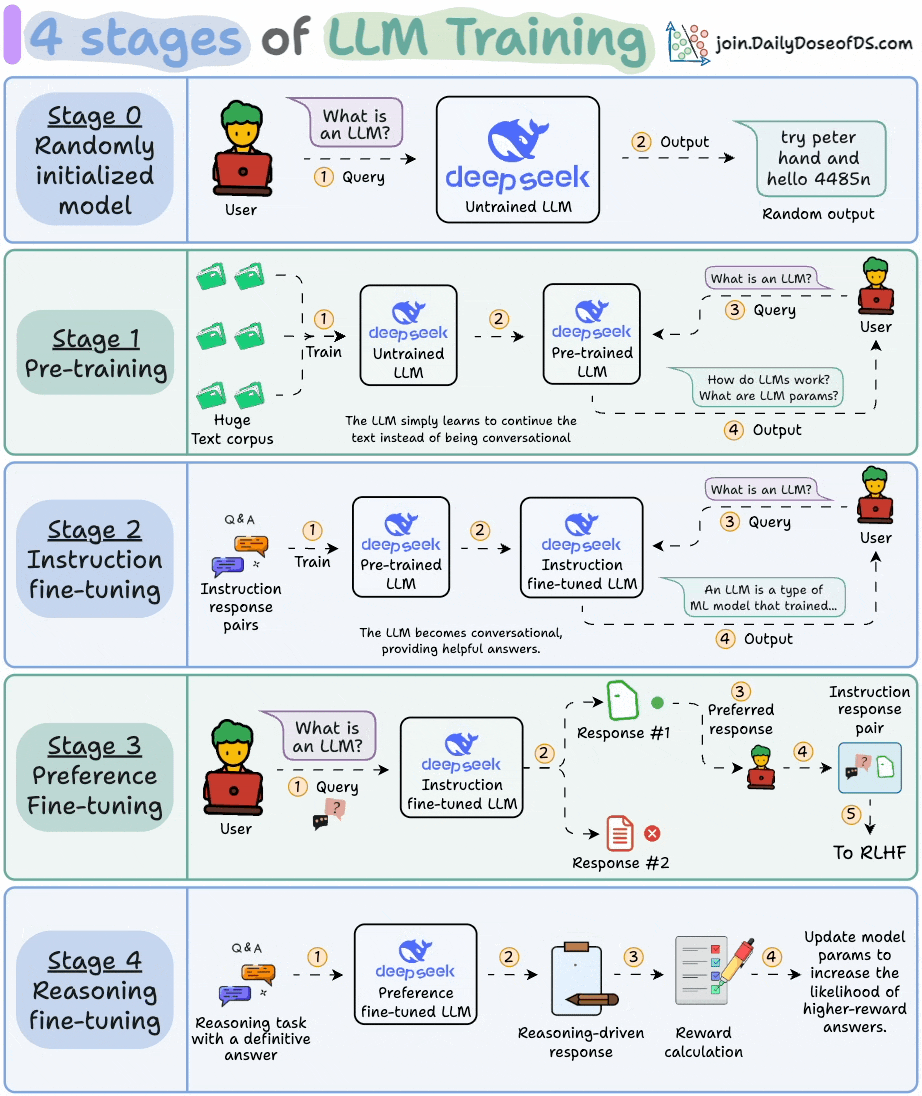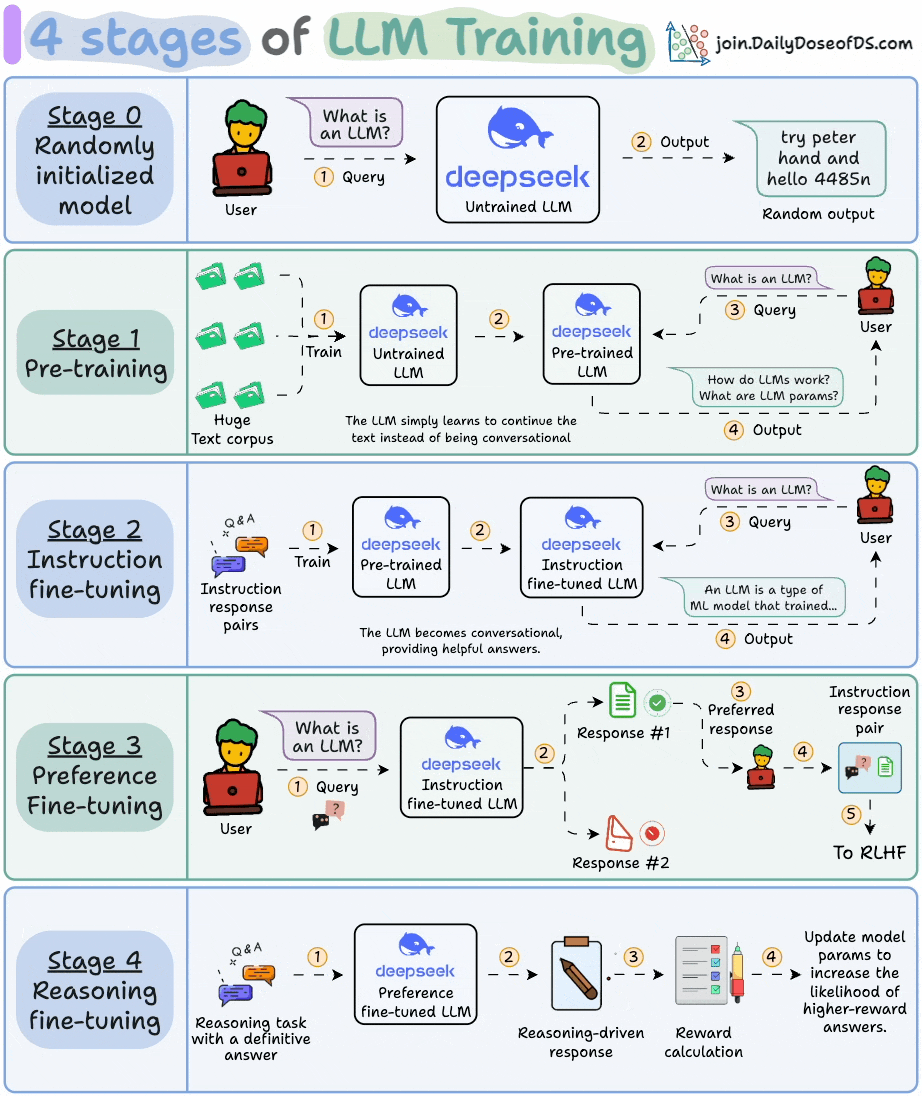
Let's dive in!
0️⃣ Randomly initialized LLM
At this point, the model knows nothing.
You ask it “What is an LLM?” and get gibberish like “try peter hand and hello 448Sn”.
It hasn’t seen any data yet and possesses just random weights.

1️⃣ Pre-training
This stage teaches the LLM the basics of language by training it on massive corpora to predict the next token. This way, it absorbs grammar, world facts, etc.
But it’s not good at conversation because when prompted, it just continues the text.
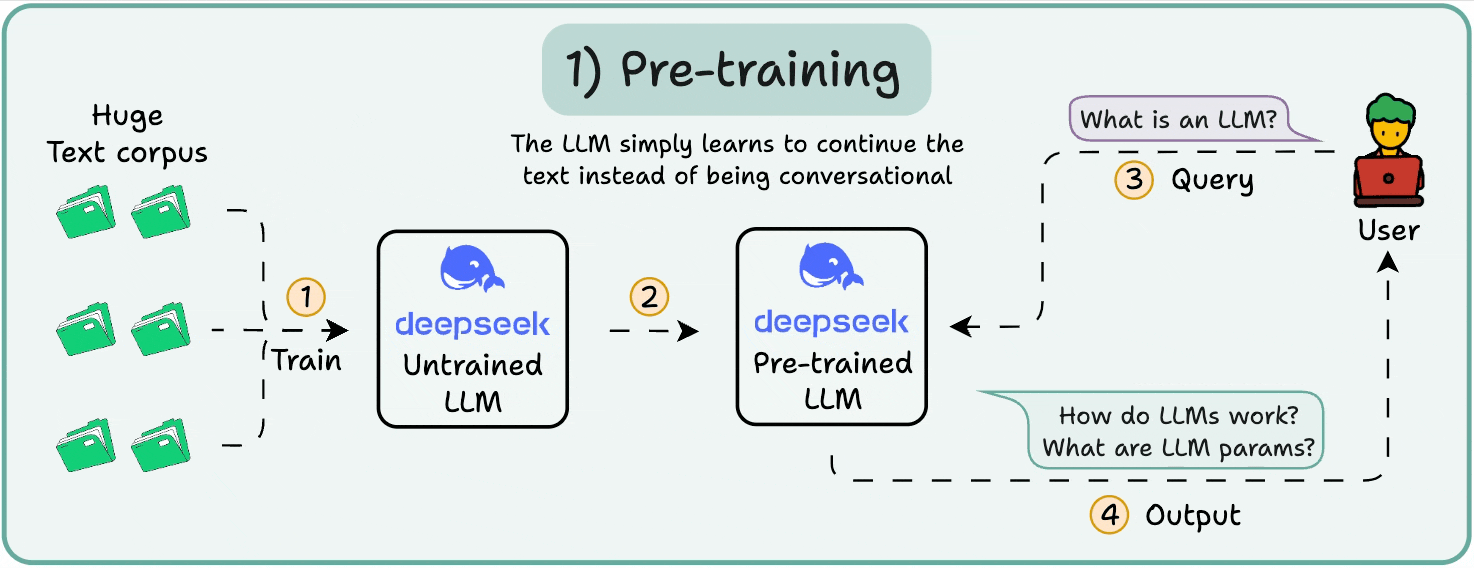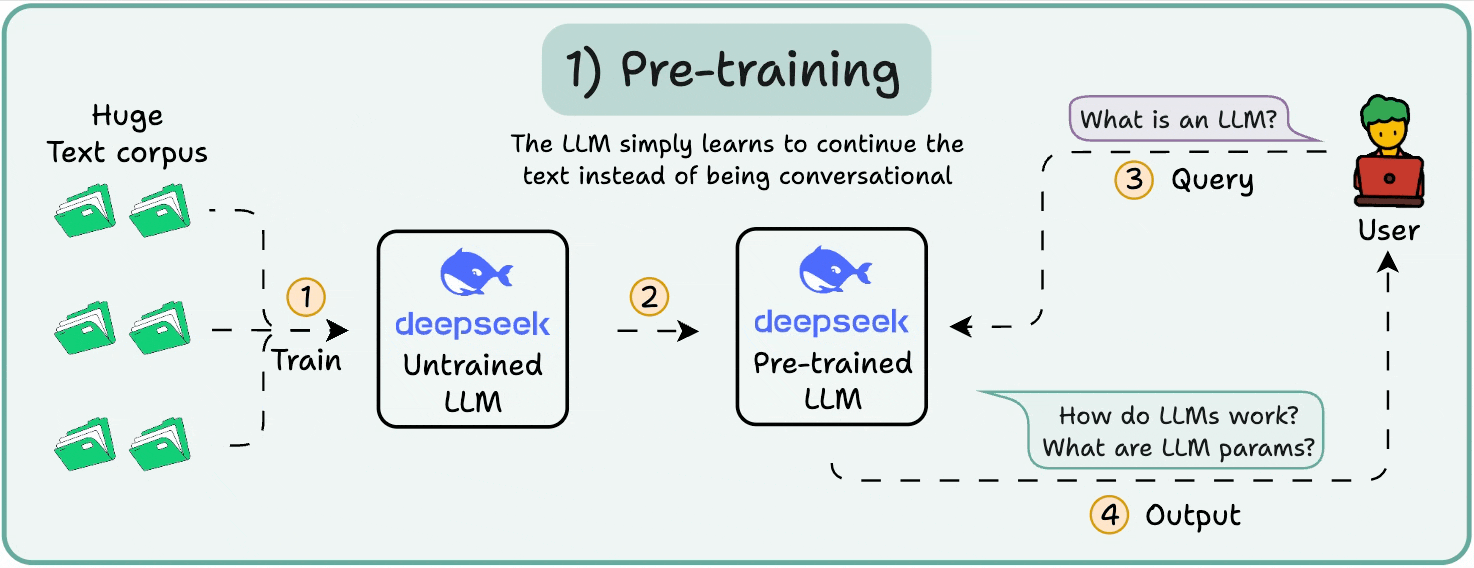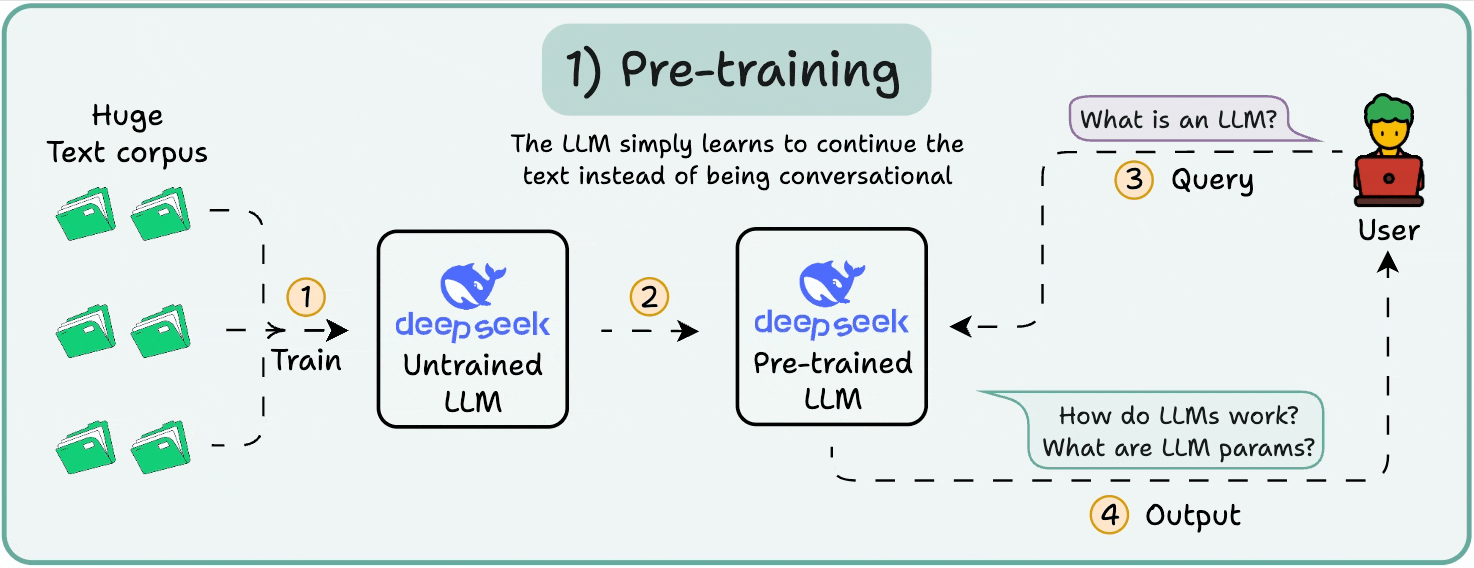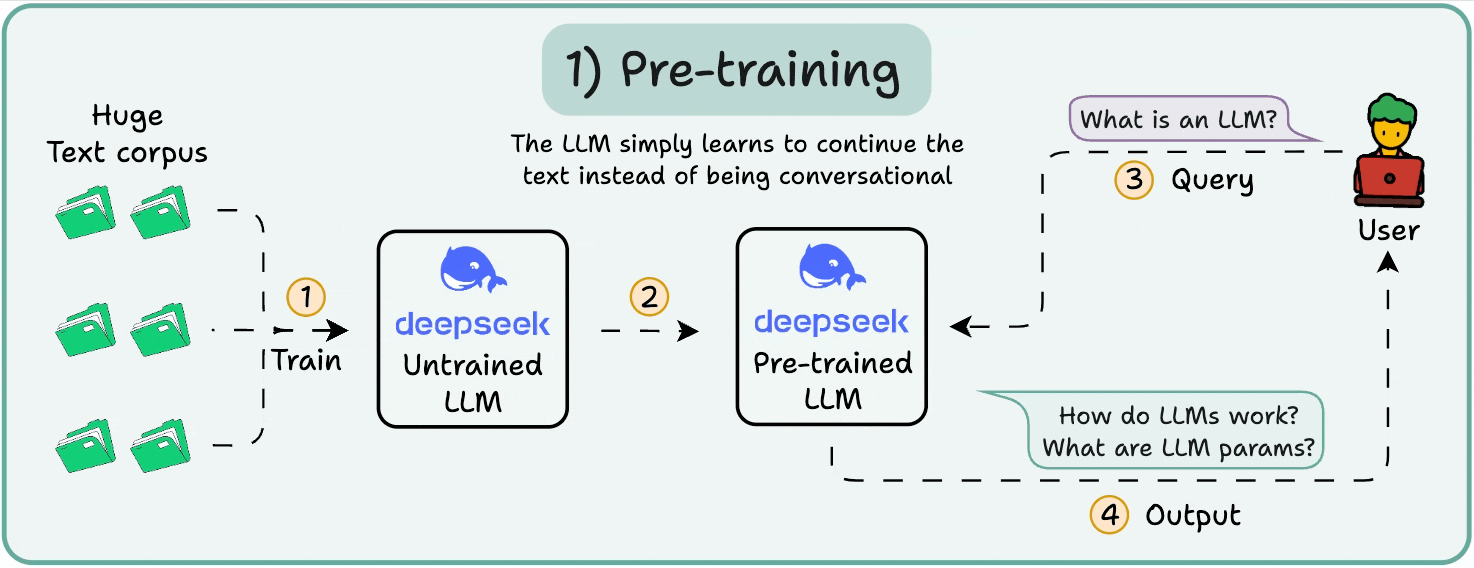
2️⃣ Instruction fine-tuning
To make it conversational, we do Instruction Fine-tuning by training on instruction-response pairs. This helps it learn how to follow prompts and format replies.
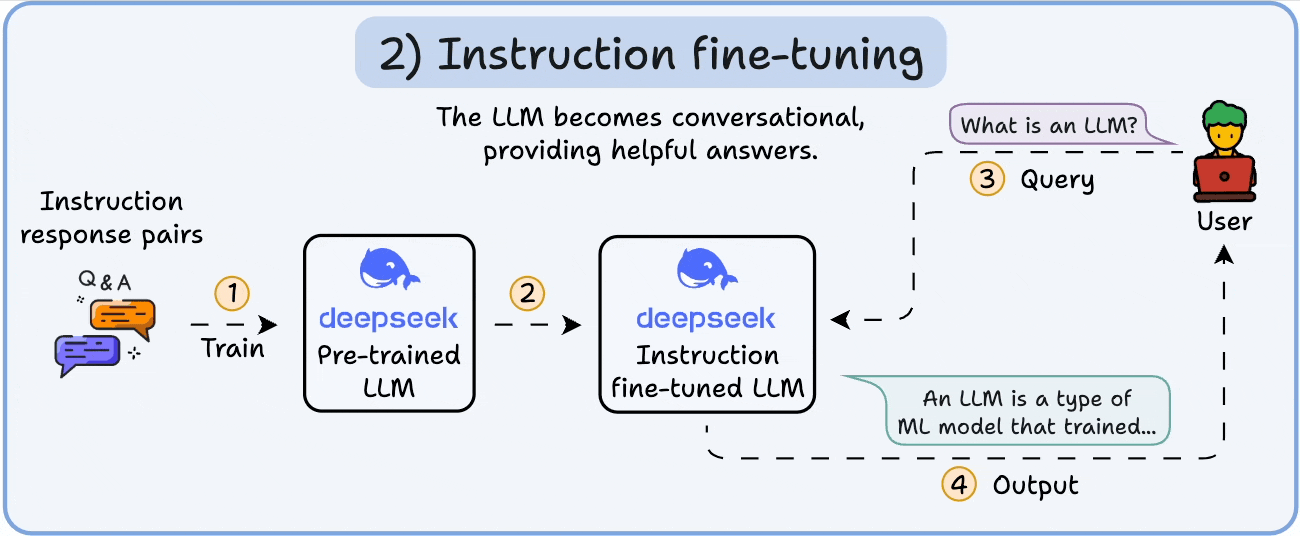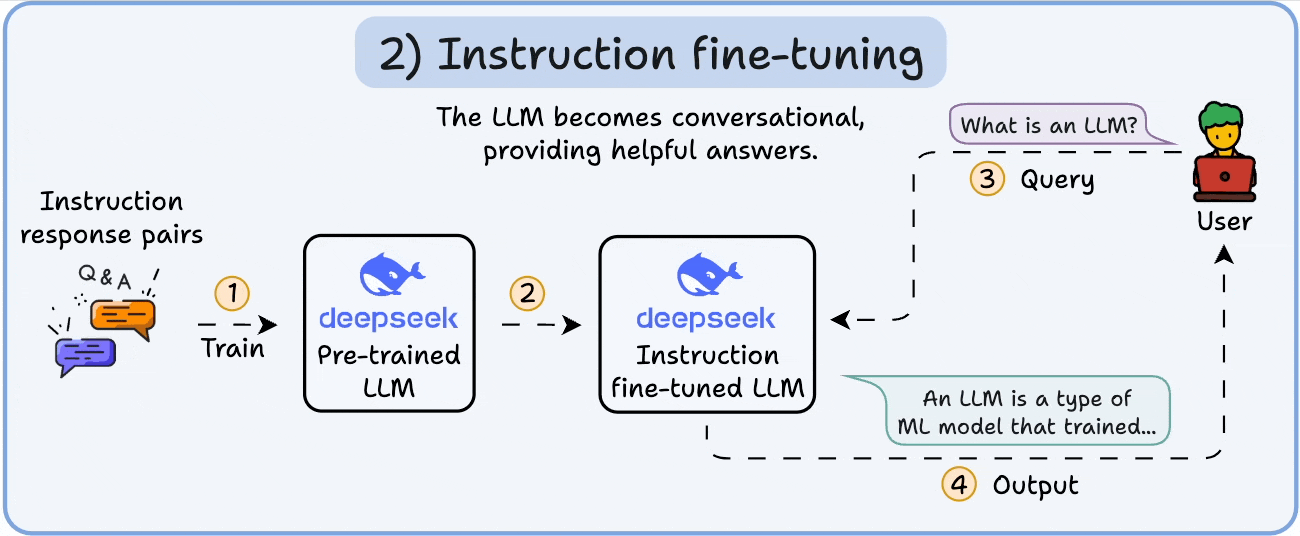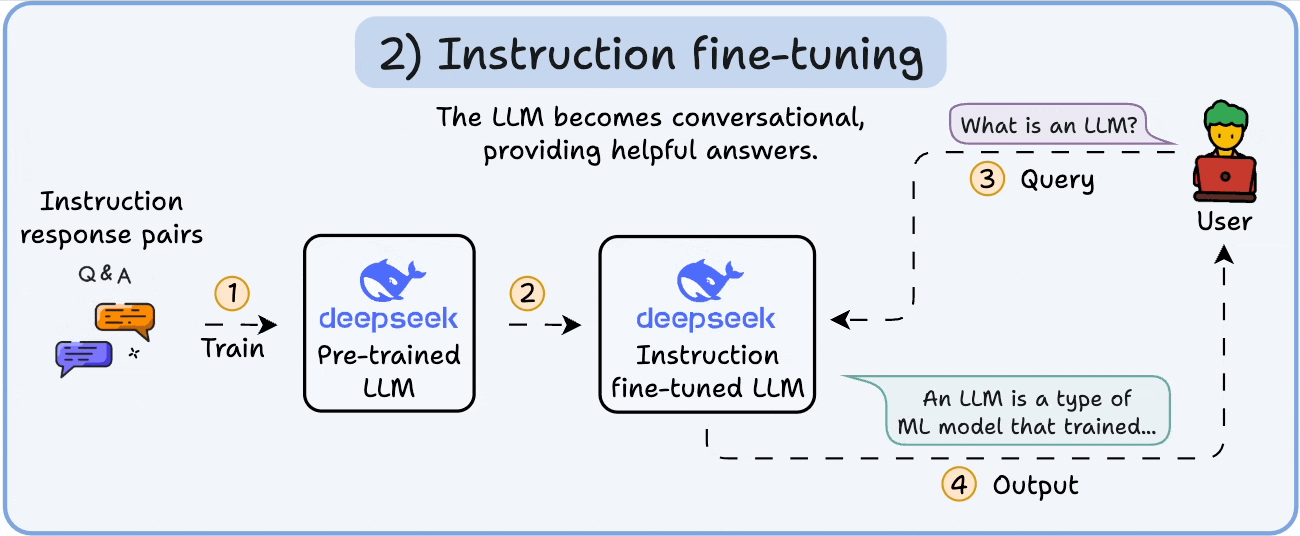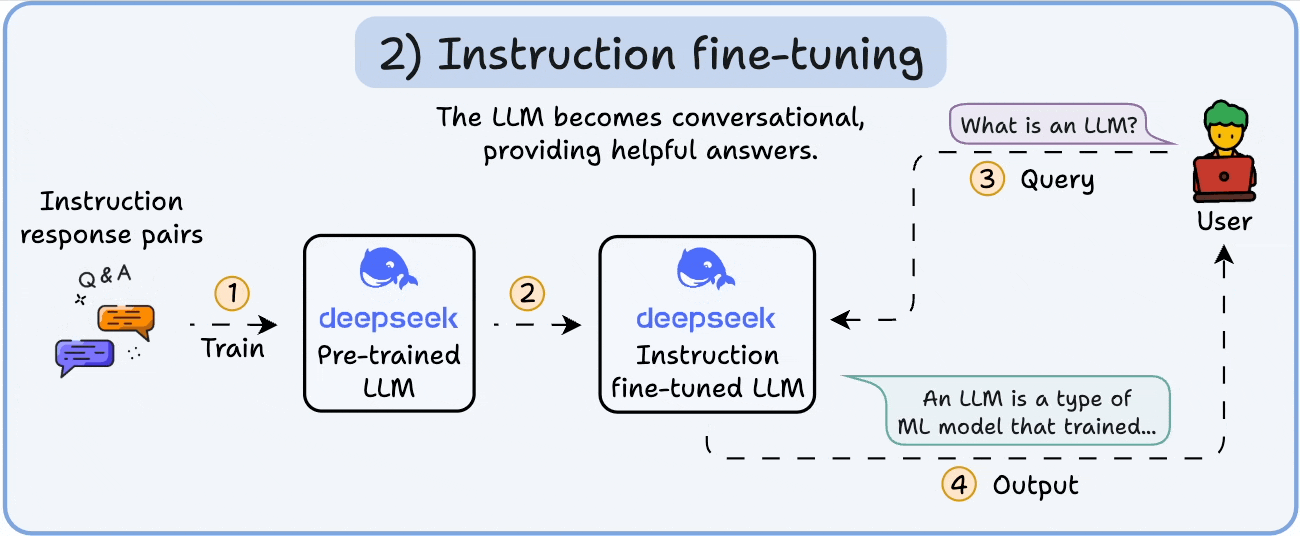
Now it can:
Answer questions
Summarize content
Write code, etc.
At this point, we have likely:
Utilized the entire raw internet archive and knowledge.
The budget for human-labeled instruction response data.
So what can we do to further improve the model?
We enter into the territory of Reinforcement Learning (RL).
3️⃣ Preference fine-tuning (PFT)
You must have seen this screen on ChatGPT where it asks: Which response do you prefer?
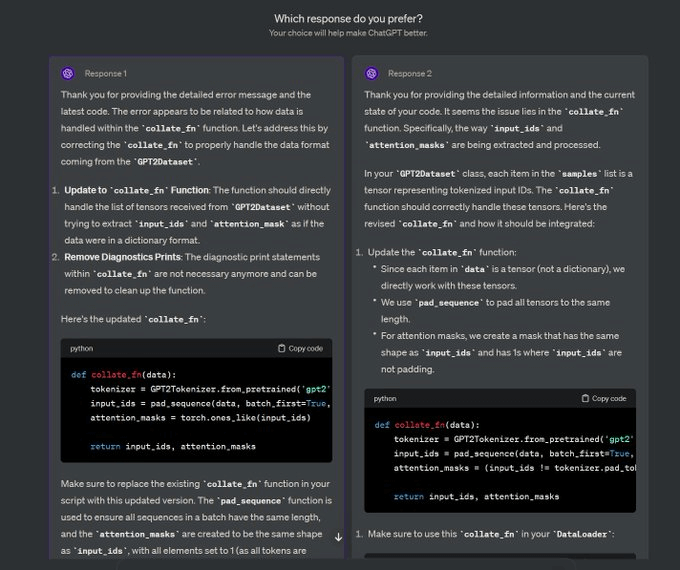
That’s not just for feedback, but it’s valuable human preference data.
OpenAI uses this to fine-tune their models using preference fine-tuning.
In PFT:
The user chooses between 2 responses to produce human preference data.
A reward model is then trained to predict human preference and the LLM is updated using RL.
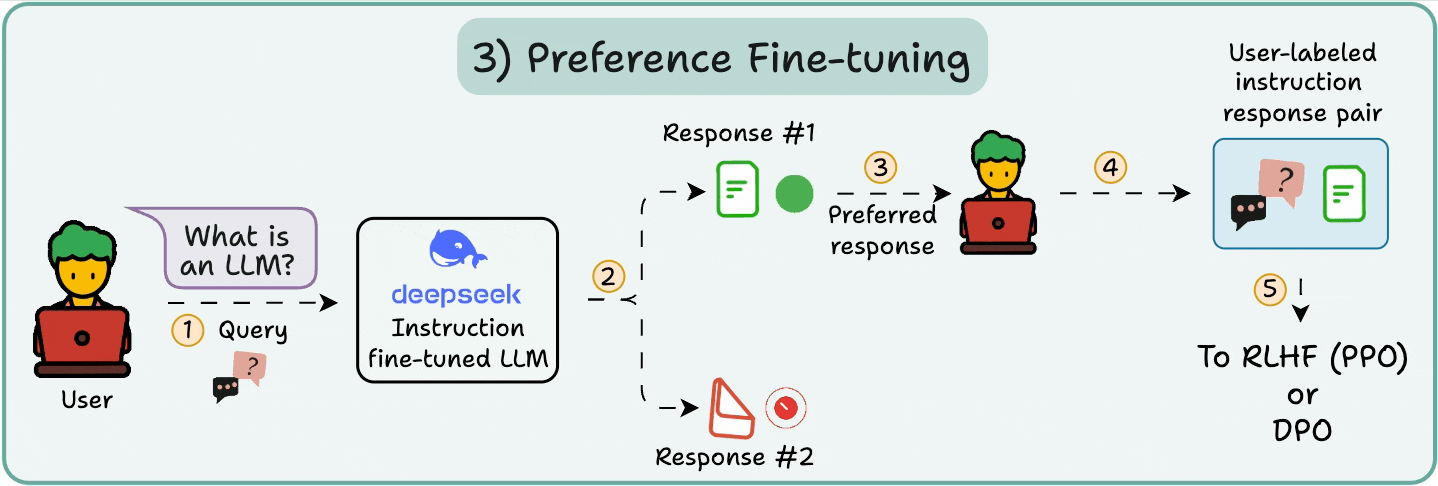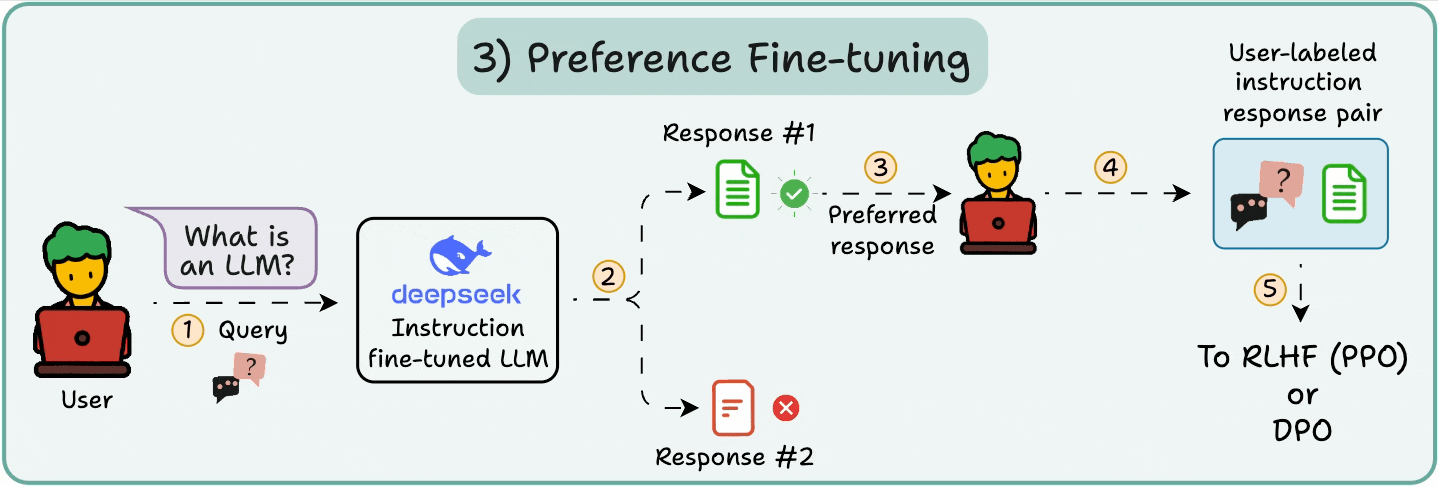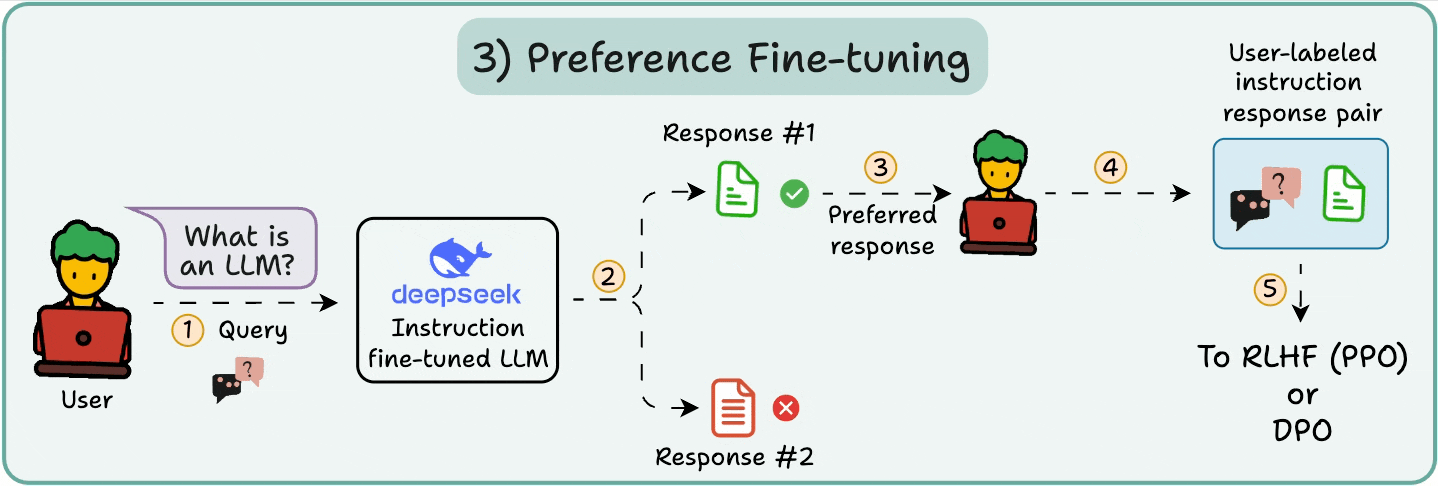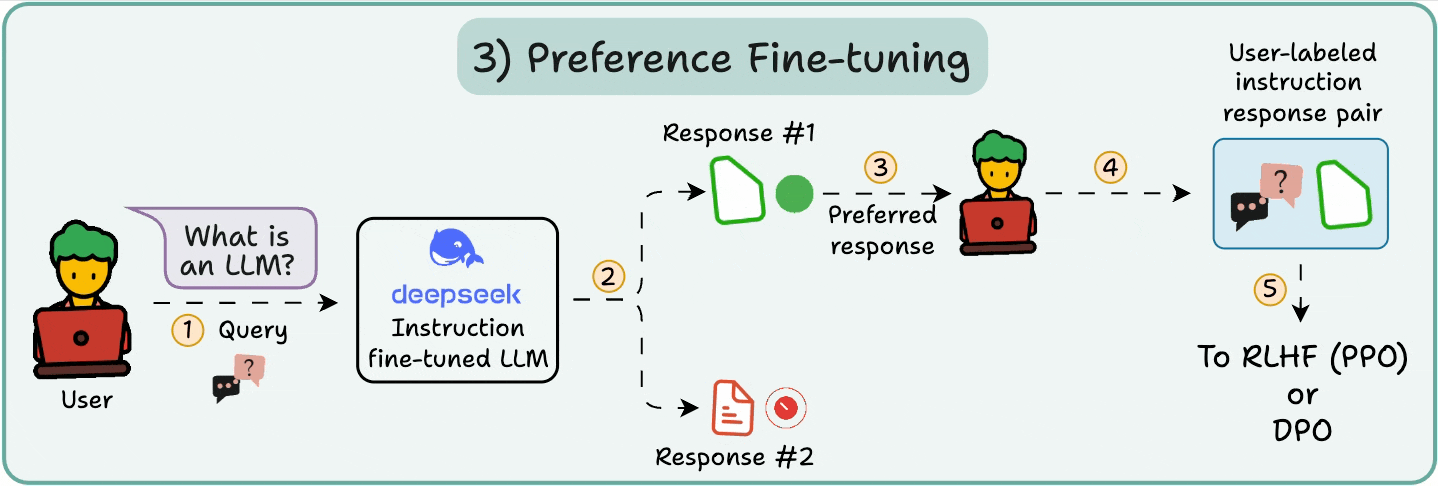
The above process is called RLHF (Reinforcement Learning with Human Feedback), and the algorithm used to update model weights is called PPO.
It teaches the LLM to align with humans even when there’s no "correct" answer.
But we can improve the LLM even more.
4️⃣ Reasoning fine-tuning
In reasoning tasks (maths, logic, etc.), there's usually just one correct response and a defined series of steps to obtain the answer.
So we don’t need human preferences, and we can use correctness as the signal.
This is called reasoning fine-tuning
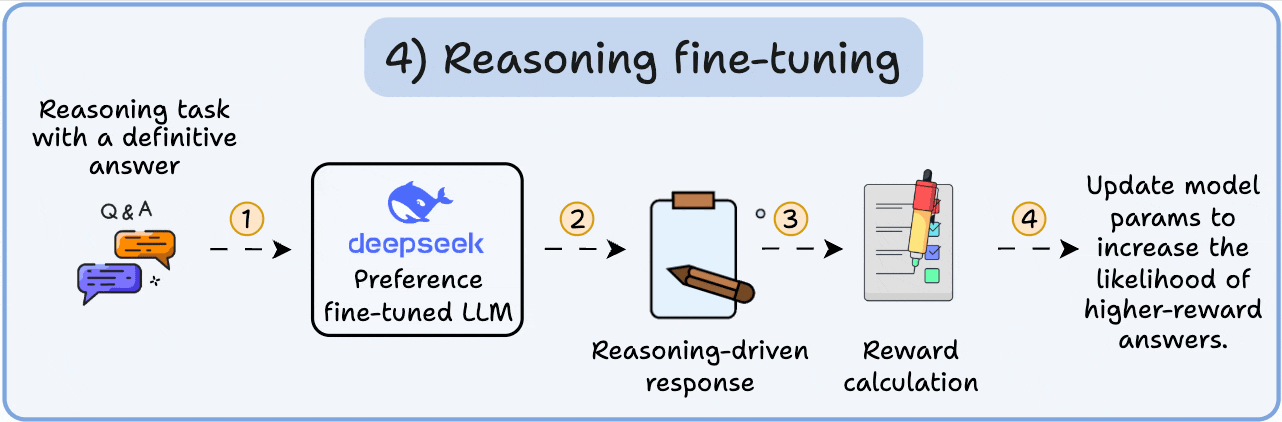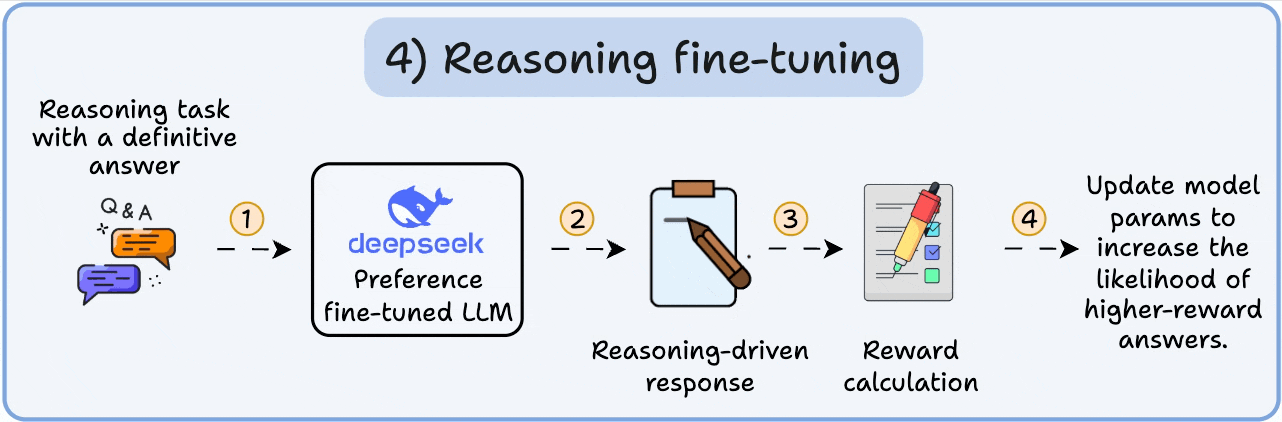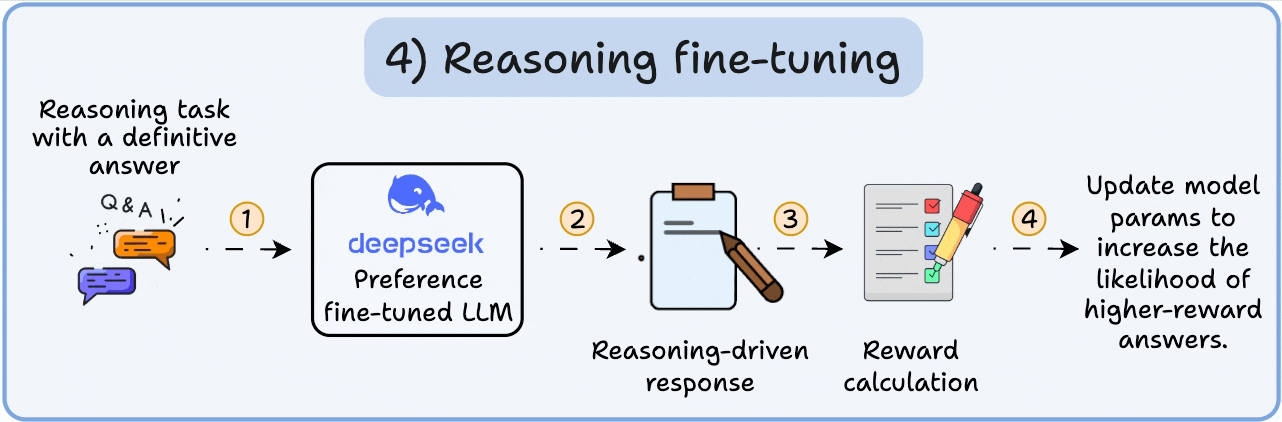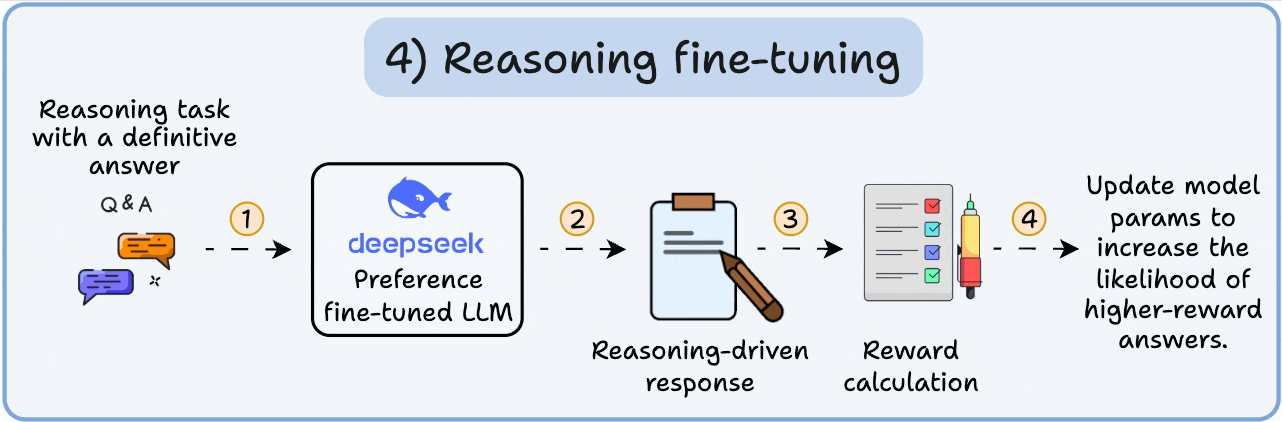
Steps:
The model generates an answer to a prompt.
The answer is compared to the known correct answer.
Based on the correctness, we assign a reward.
This is called Reinforcement Learning with Verifiable Rewards. GRPO by DeepSeek is a popular technique for this.
Those were the 4 stages of training an LLM.
Start with a randomly initialized model.
Pre-train it on large-scale corpora.
Use instruction fine-tuning to make it follow commands.
Use preference & reasoning fine-tuning to sharpen responses.
In a future issue, we shall dive into the specific implementation of these.
In the meantime, read this where we implemented pre-training of Llama 4 from scratch here →
It covers:
Character-level tokenization
Multi-head self-attention with rotary positional embeddings (RoPE)
Sparse routing with multiple expert MLPs
RMSNorm, residuals, and causal masking
And finally, training and generation.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
+1
Hi Avi, I love the flow diagram you created. May I know which drawing tools you used, for creating these stunning flow animation? Thanks!