
4 Strategies for Multi-GPU Training
...explained visually.

Sourcery is making manual code reviews obsolete with AI. Every pull request instantly gets a human-like review from Sourcery with general feedback, in-line comments, and relevant suggestions.

What used to take over a day now takes a few seconds only.
Sourcery handles 500,000+ requests every month (reviews + refactoring + writing tests + documenting code, etc.), and I have been using it for over 1.5 years now.
If you care about your and your team’s productivity, get started right away:
Thanks to Sourcery for partnering with me today!
Let’s get to today’s post now.
4 Strategies for Multi-GPU Training
By default, deep learning models only utilize a single GPU for training, even if multiple GPUs are available.

An ideal way to proceed (especially in big-data settings) is to distribute the training workload across multiple GPUs.
The graphic below depicts four common strategies for multi-GPU training:
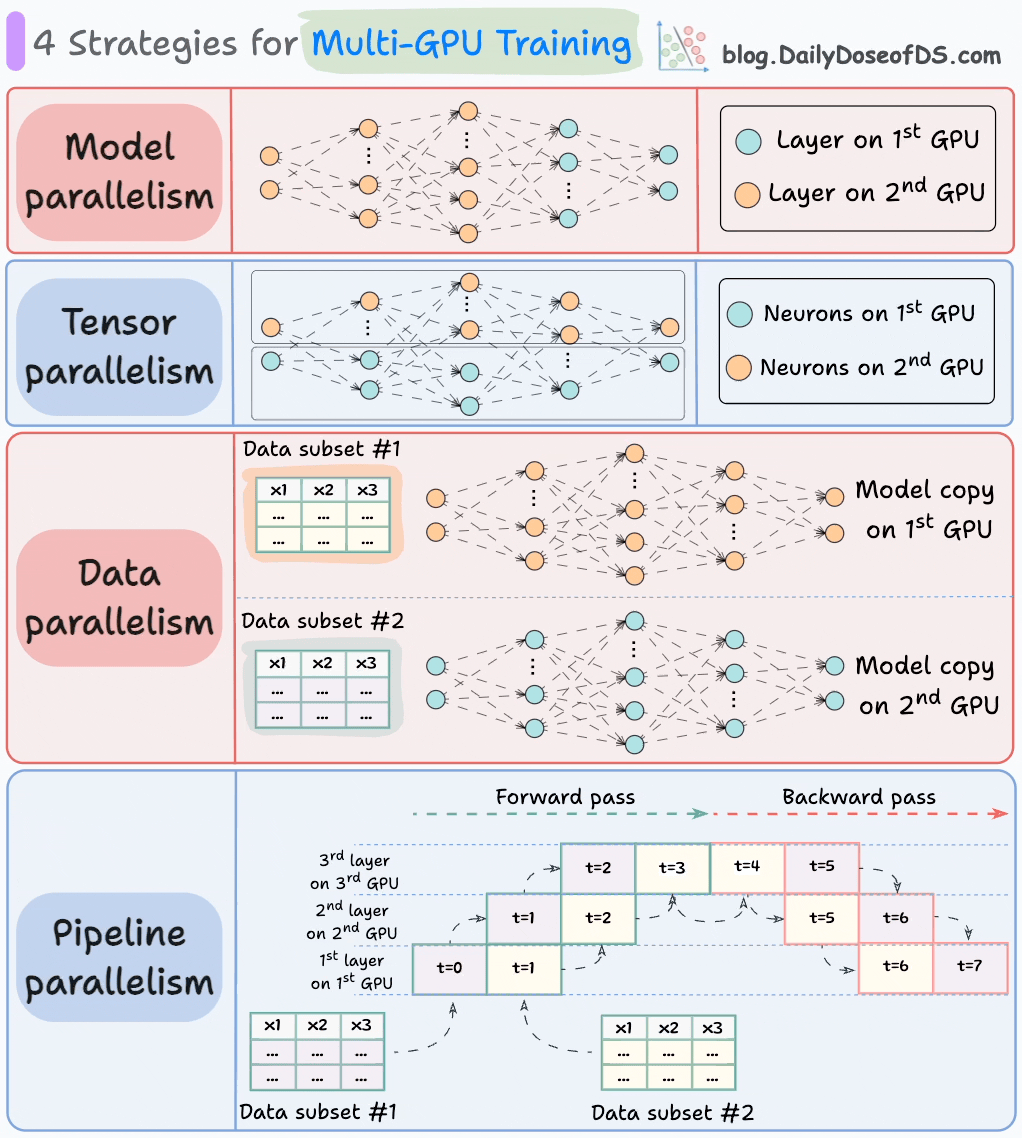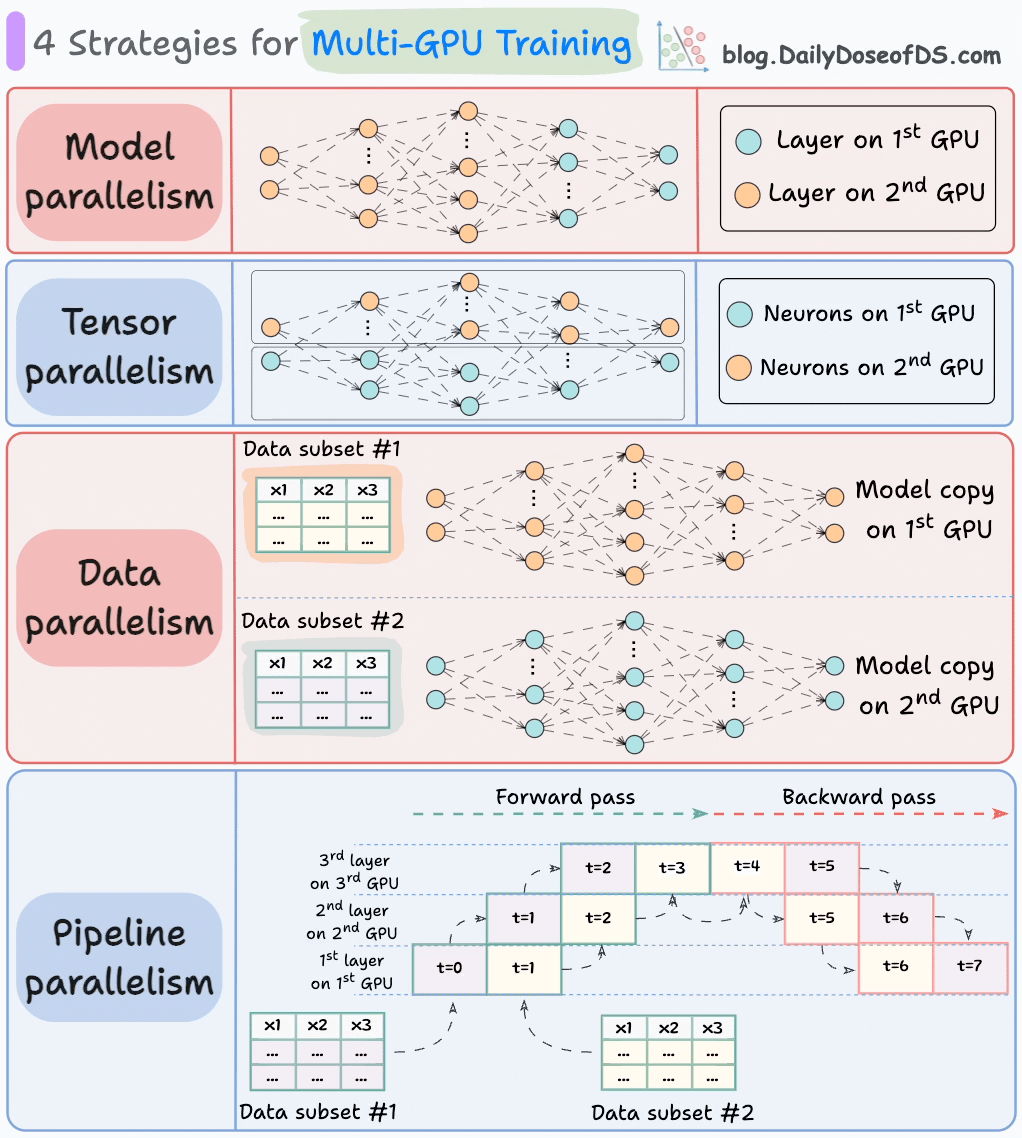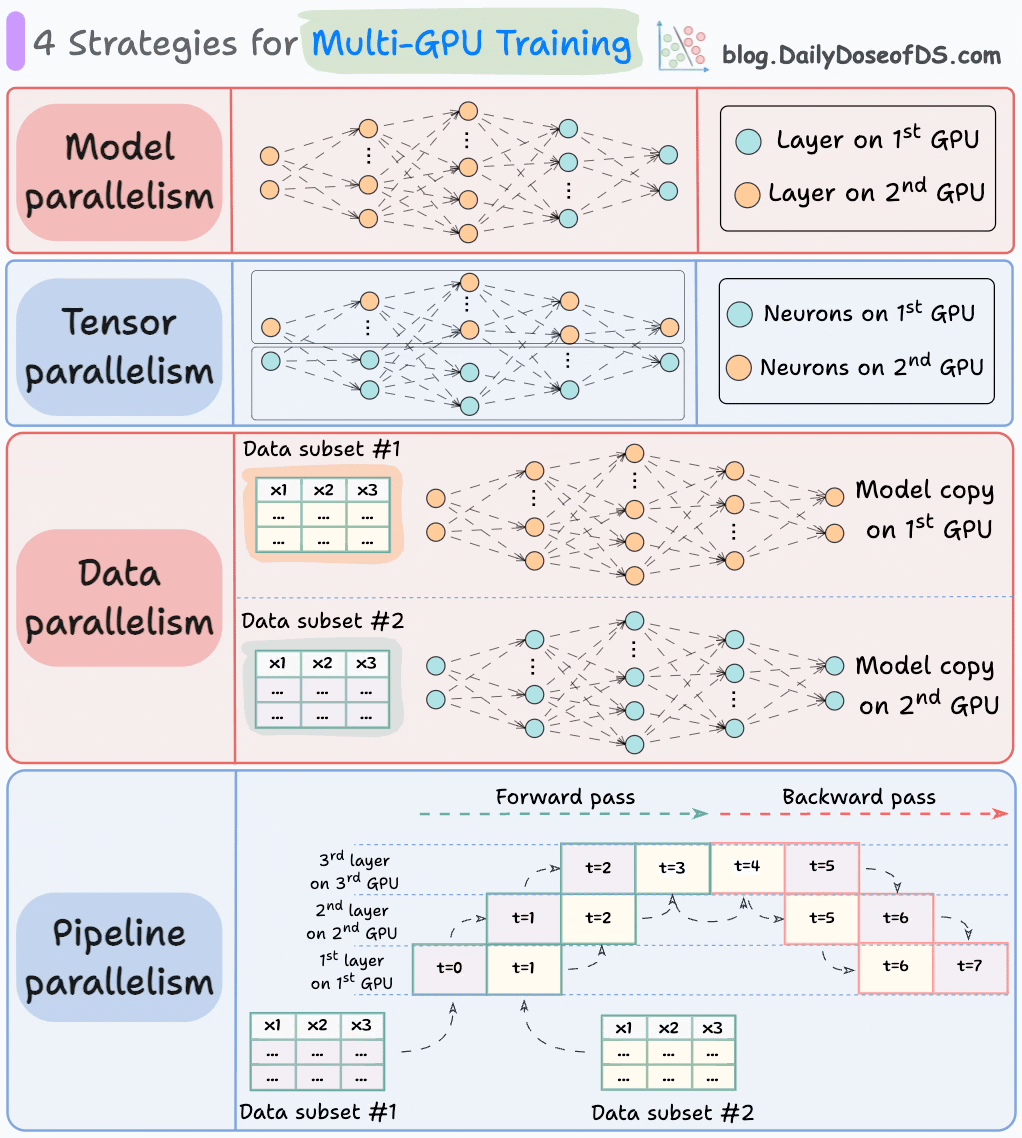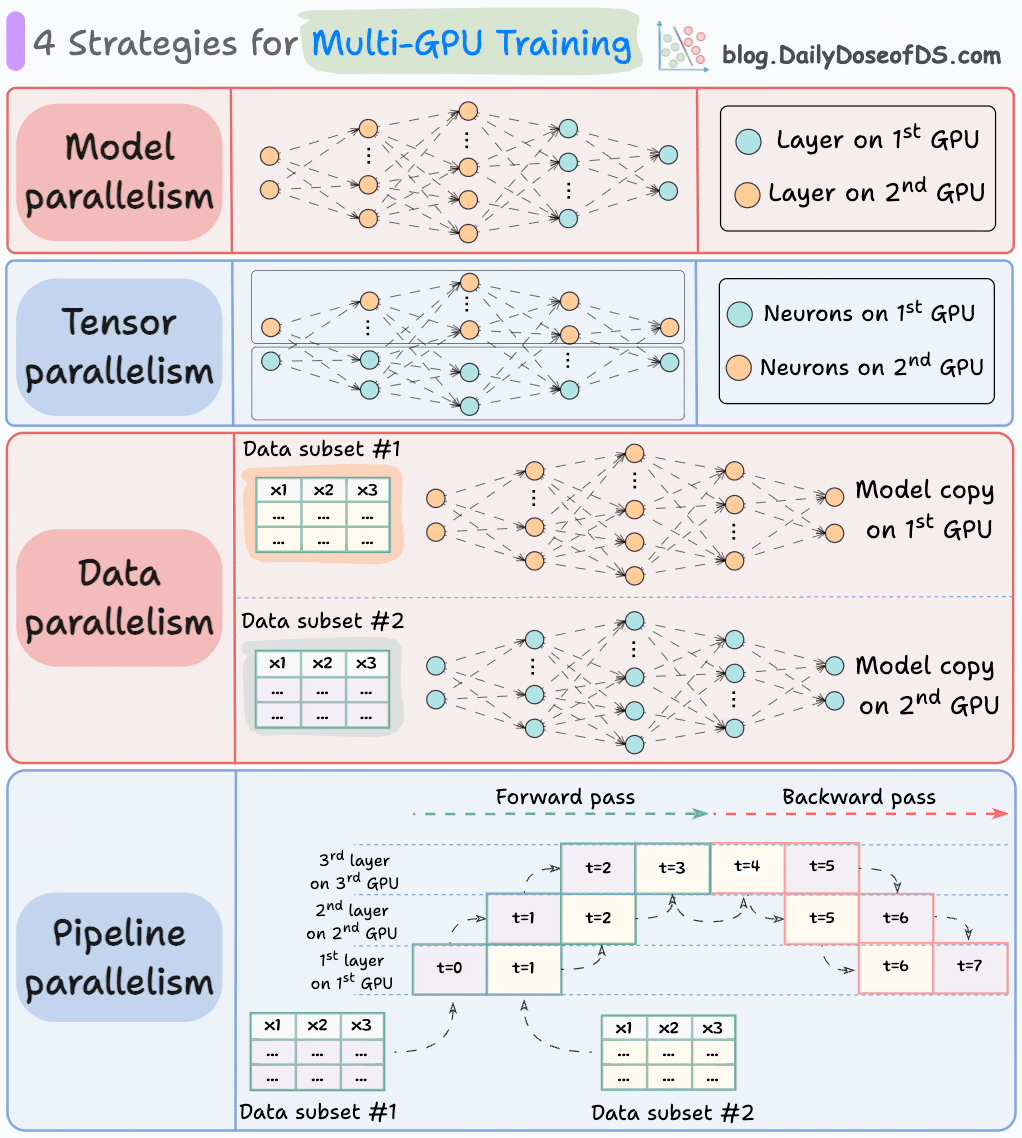
We covered multi-GPU training in detail with implementation here: A Beginner-friendly Guide to Multi-GPU Model Training.
Let’s discuss these four strategies below:
#1) Model parallelism

Different parts (or layers) of the model are placed on different GPUs.
Useful for huge models that do not fit on a single GPU.
However, model parallelism also introduces severe bottlenecks as it requires data flow between GPUs when activations from one GPU are transferred to another GPU.
#2) Tensor parallelism

Distributes and processes individual tensor operations across multiple devices or processors.
It is based on the idea that a large tensor operation, such as matrix multiplication, can be divided into smaller tensor operations, and each smaller operation can be executed on a separate device or processor.

Such parallelization strategies are inherently built into standard implementations of PyTorch and other deep learning frameworks, but they become much more pronounced in a distributed setting.
#3) Data parallelism
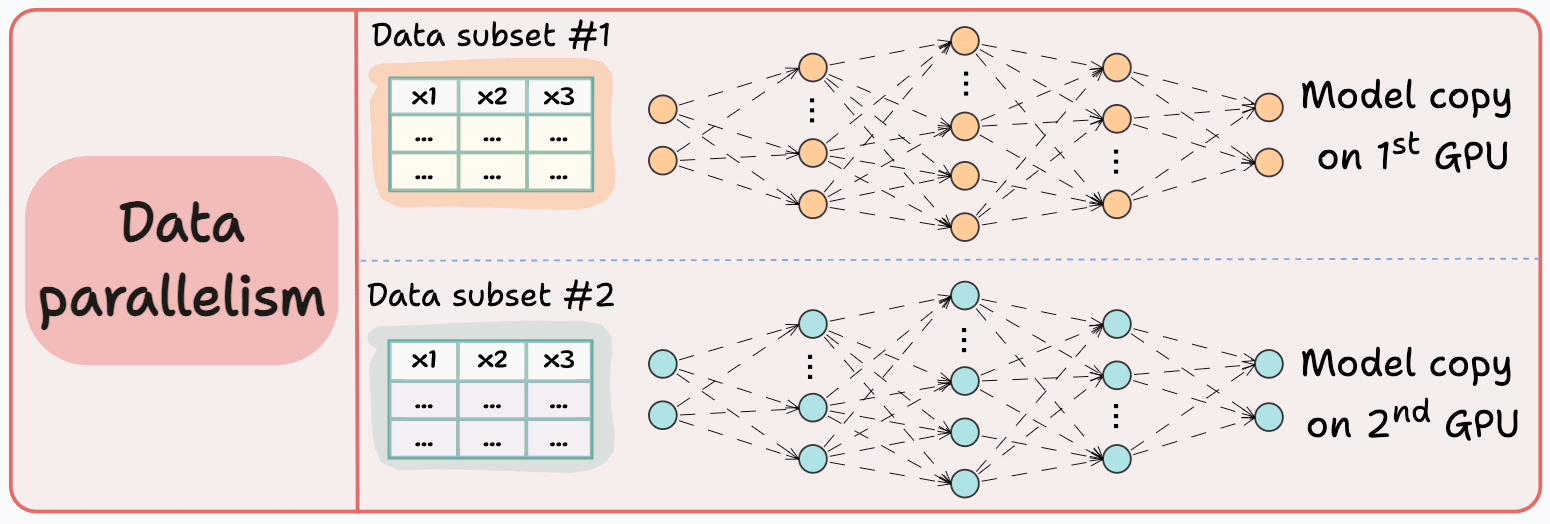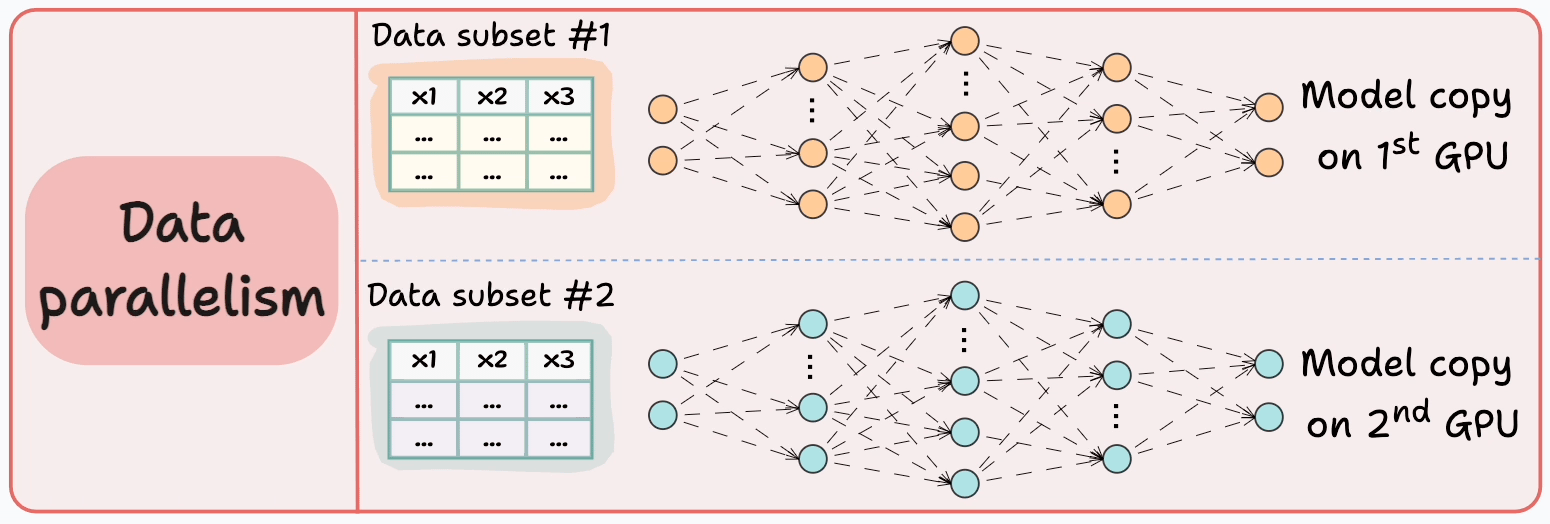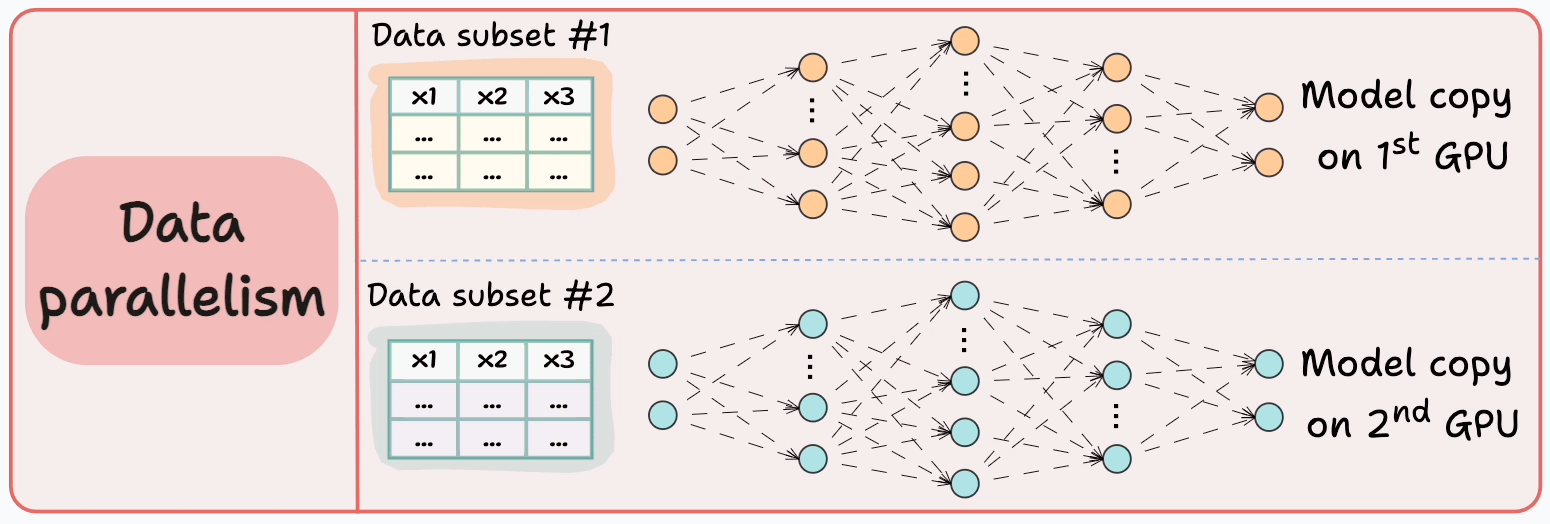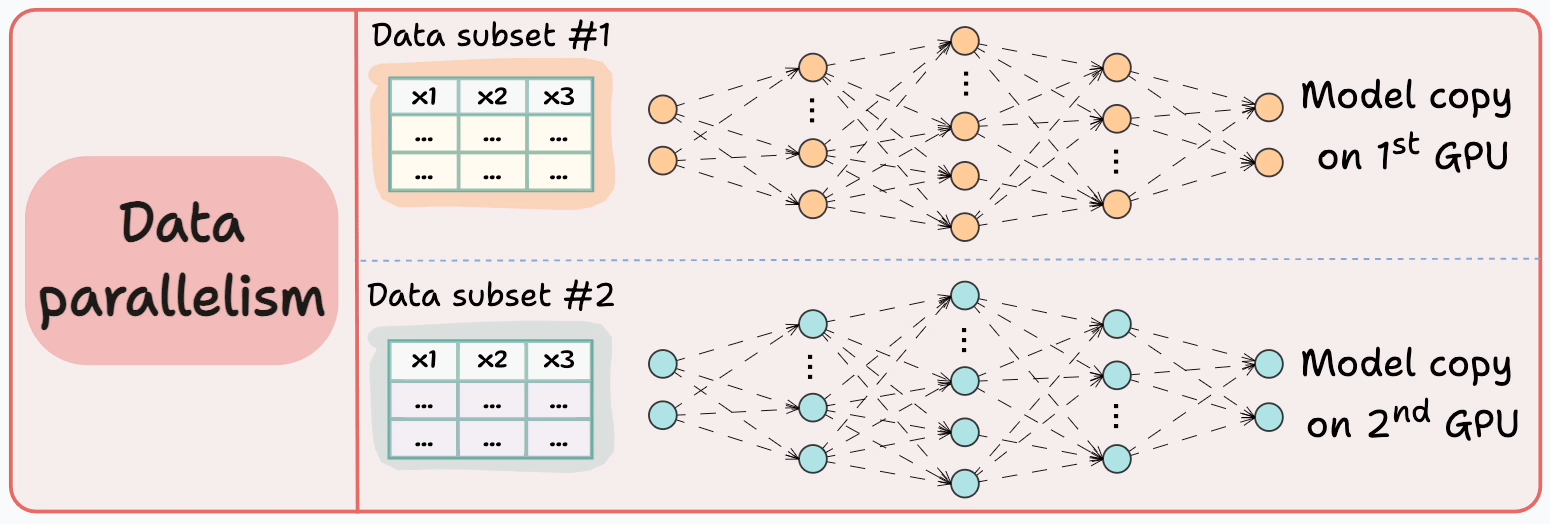
Replicate the model across all GPUs.
Divide the available data into smaller batches, and each batch is processed by a separate GPU.
The updates (or gradients) from each GPU are then aggregated and used to update the model parameters on every GPU.
#4) Pipeline parallelism
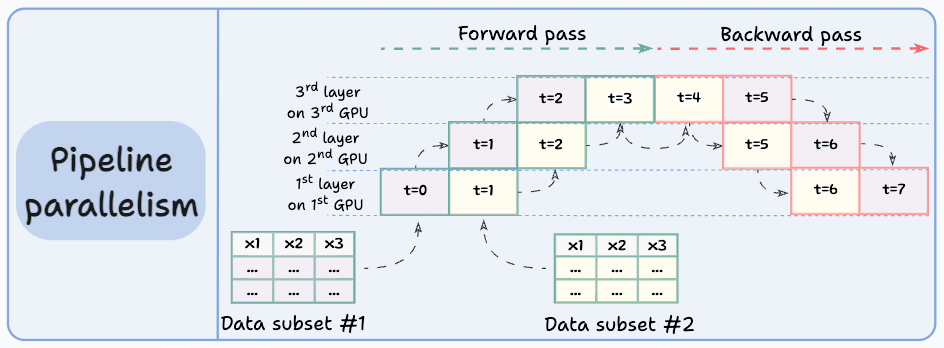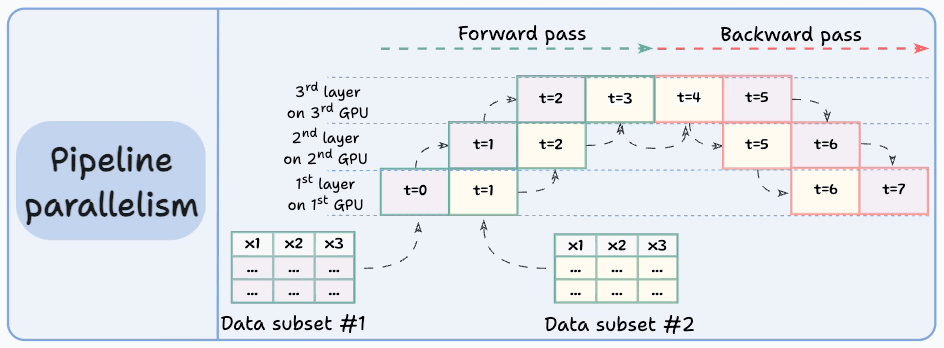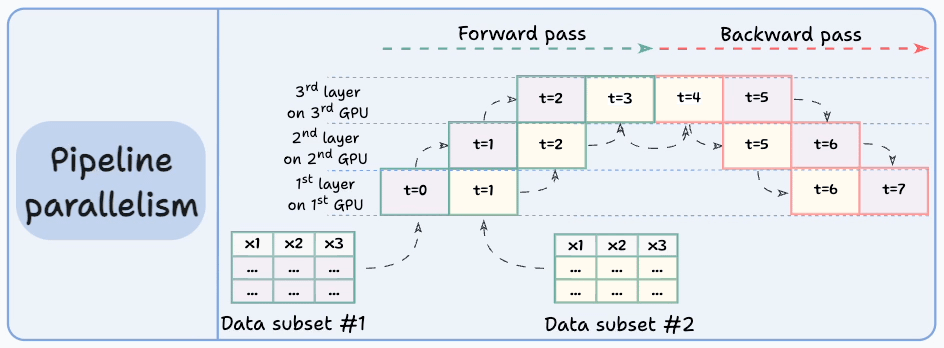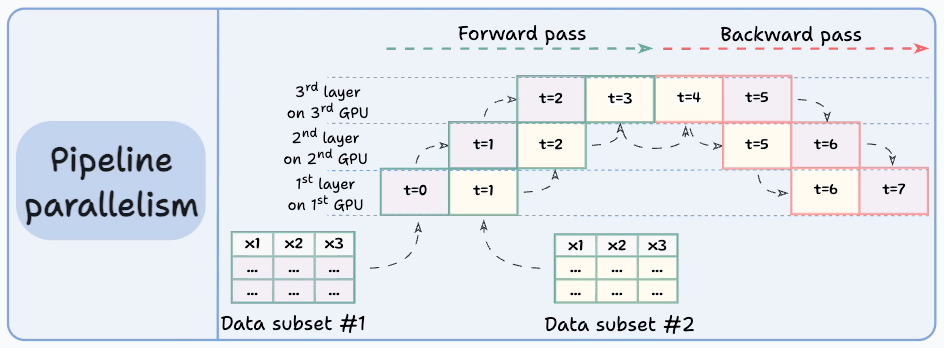
This is often considered a combination of data parallelism and model parallelism.
So the issue with standard model parallelism is that 1st GPU remains idle when data is being propagated through layers available in 2nd GPU:
Pipeline parallelism addresses this by loading the next micro-batch of data once the 1st GPU has finished the computations on the 1st micro-batch and transferred activations to layers available in the 2nd GPU. The process looks like this:
1st micro-batch passes through the layers on 1st GPU.
2nd GPU receives activations on 1st micro-batch from 1st GPU.
While the 2nd GPU passes the data through the layers, another micro-batch is loaded on the 1st GPU.
And the process continues.
GPU utilization drastically improves this way. This is evident from the animation below where multi-GPUs are being utilized at the same timestamp (look at t=1, t=2, t=5, and t=6):
Those were four common strategies for multi-GPU training.
To get into more details about multi-GPU training and implementation, read this article: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, what happens under the hood when we do .cuda()?
It’s SO EASY to accelerate model training with GPUs today. All it takes is just a simple .cuda() call.

Yet, GPUs are among the biggest black-box aspects, despite being so deeply rooted in deep learning.
If you are always curious about underlying details, I have written an article about CUDA programming: Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming.
We cover the end-to-end details of CUDA and do a hands-on demo on CUDA programming by implementing parallelized implementations of various operations we typically perform in deep learning.
The article is beginner-friendly, so if you have never written a CUDA program before, that’s okay.
👉 Over to you: What are some other strategies for multi-GPU training?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 78,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.