
4 Strategies for Multi-GPU Training
...explained visually.

Get End-to-end API observability with Postman
Devs constantly struggle with visibility into real-world API behavior.
This leads to issues surfacing late, debugging taking longer, and teams missing how their APIs actually behave in production.
Postman released API Observability to close that gap.
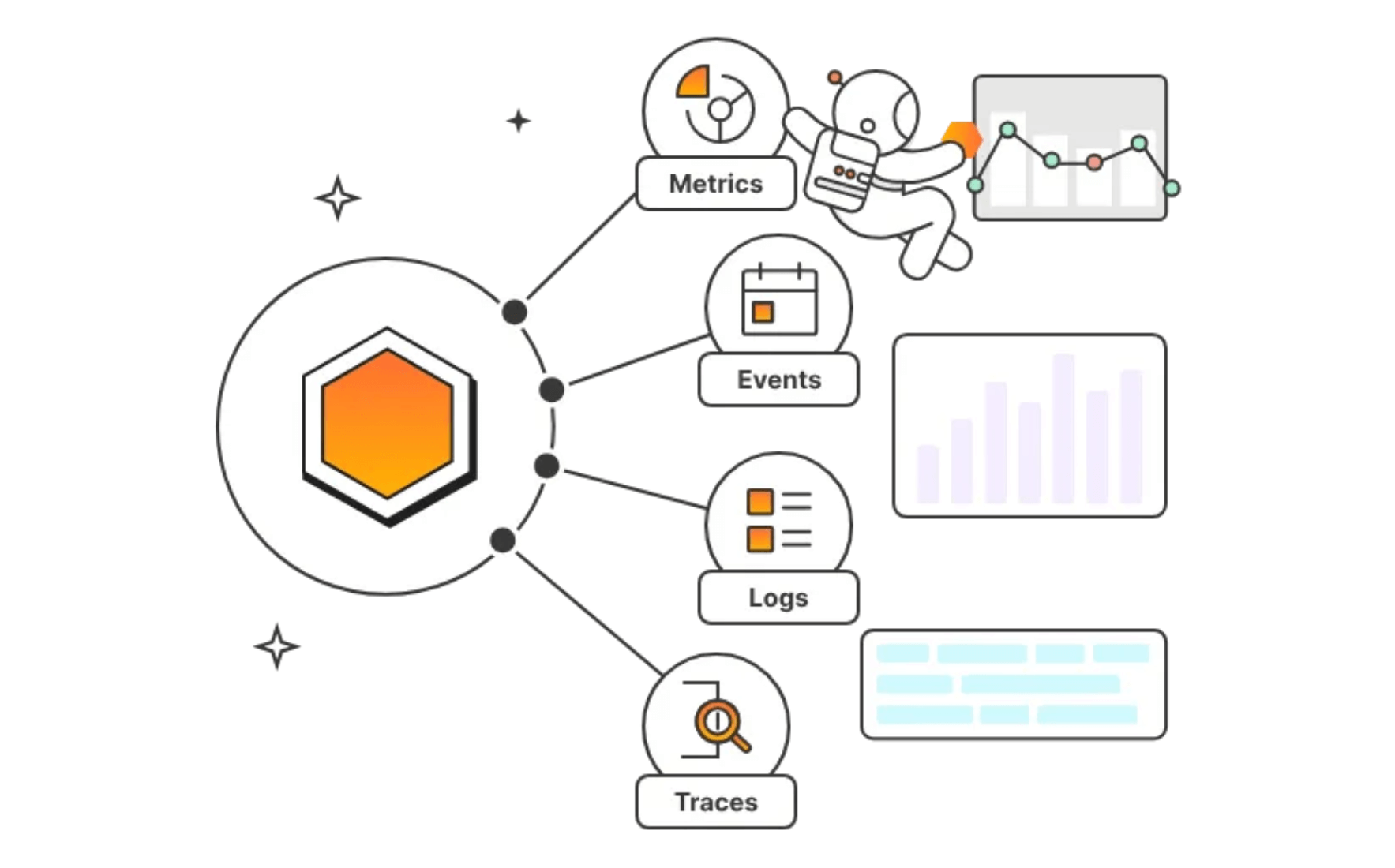
It makes an API’s internal state understandable through the signals it emits, like metrics, logs, events, and traces, so teams can spot latency and error regressions, validate real-world usage, and detect behavior that falls outside their expected baseline.
If you want a clearer picture of your API health and the insights to improve it, you can try Postman’s API Observability here →
Thanks to Postman for partnering today!
4 Strategies for Multi-GPU Training
By default, deep learning models only utilize a single GPU for training, even if multiple GPUs are available.
An ideal way to train models is to distribute the training workload across multiple GPUs.
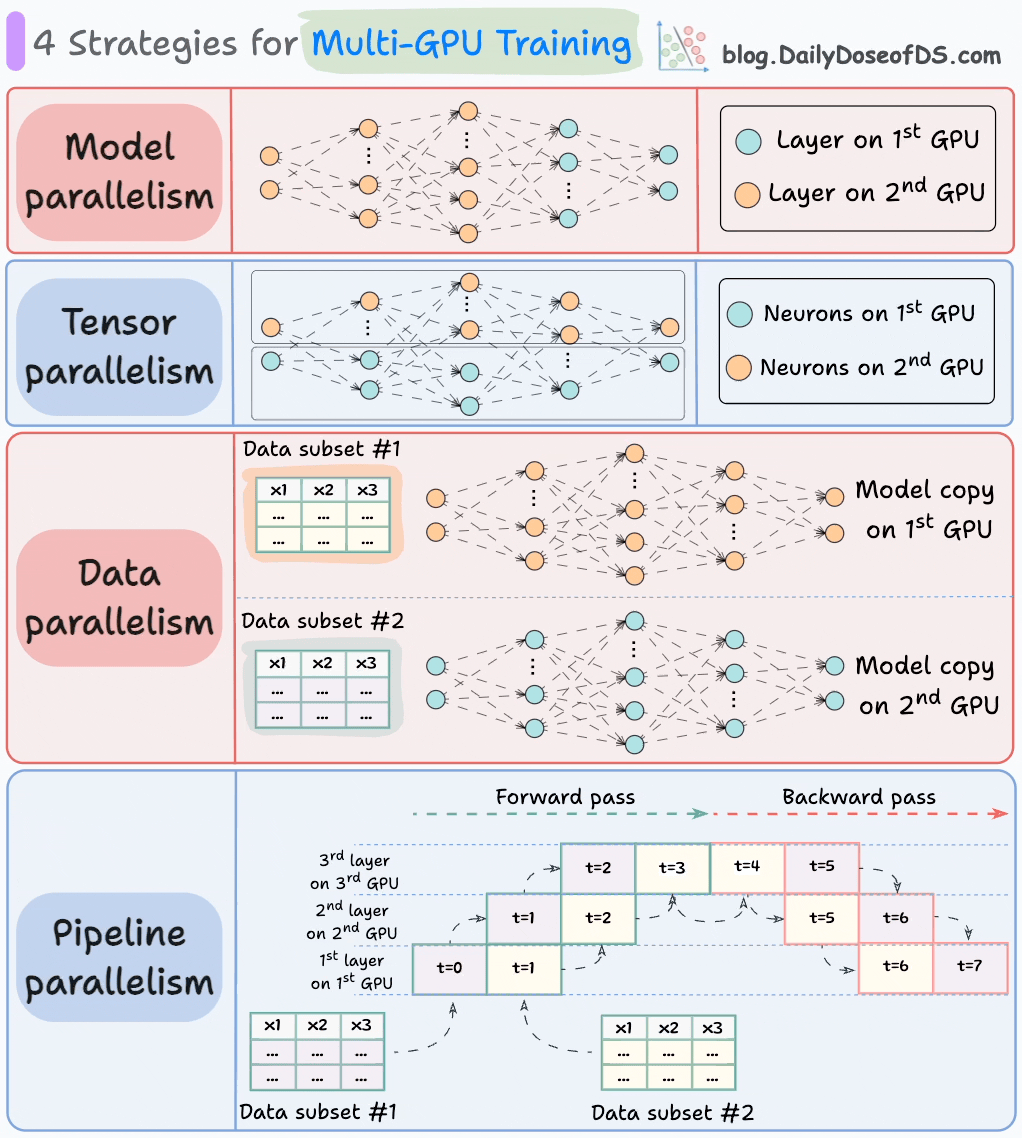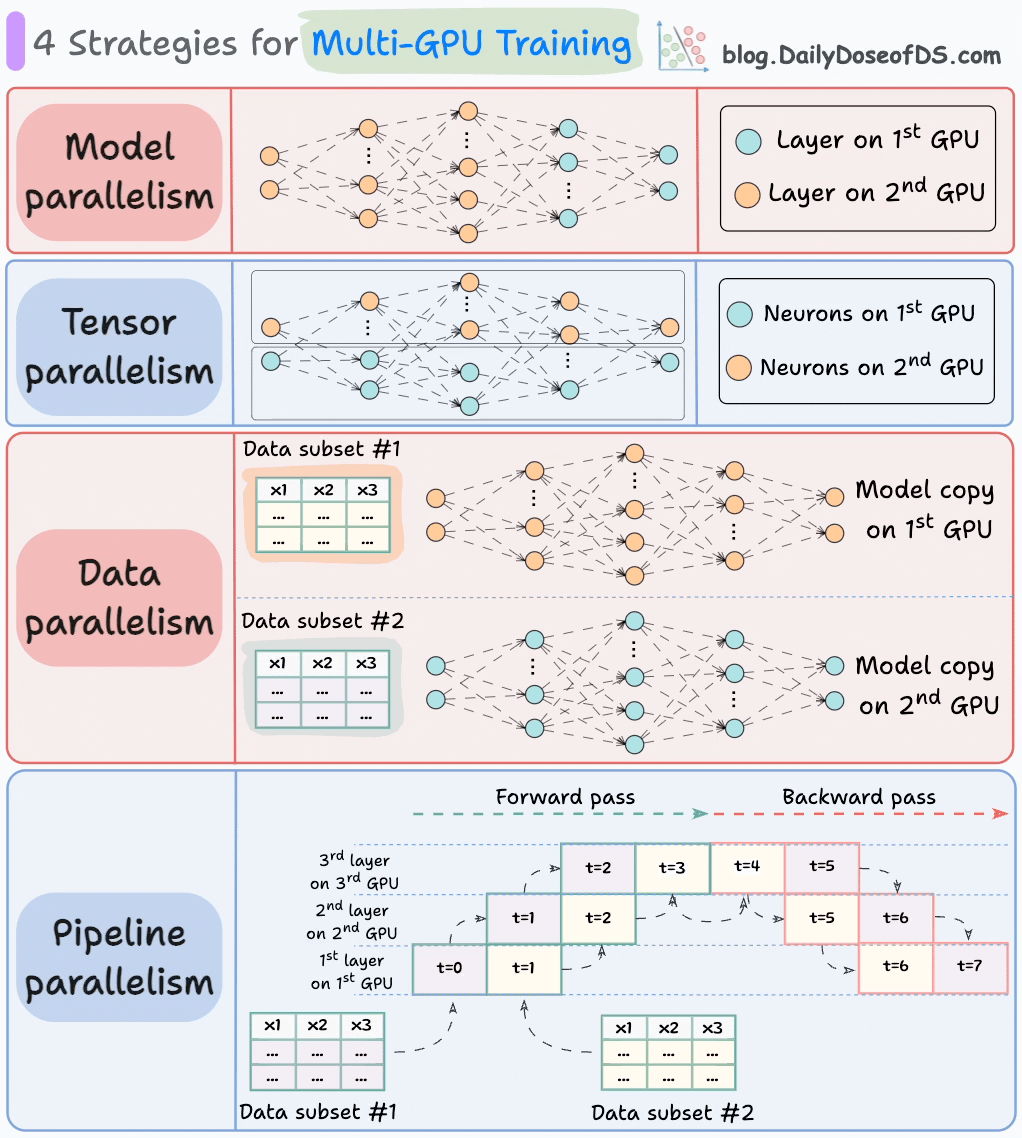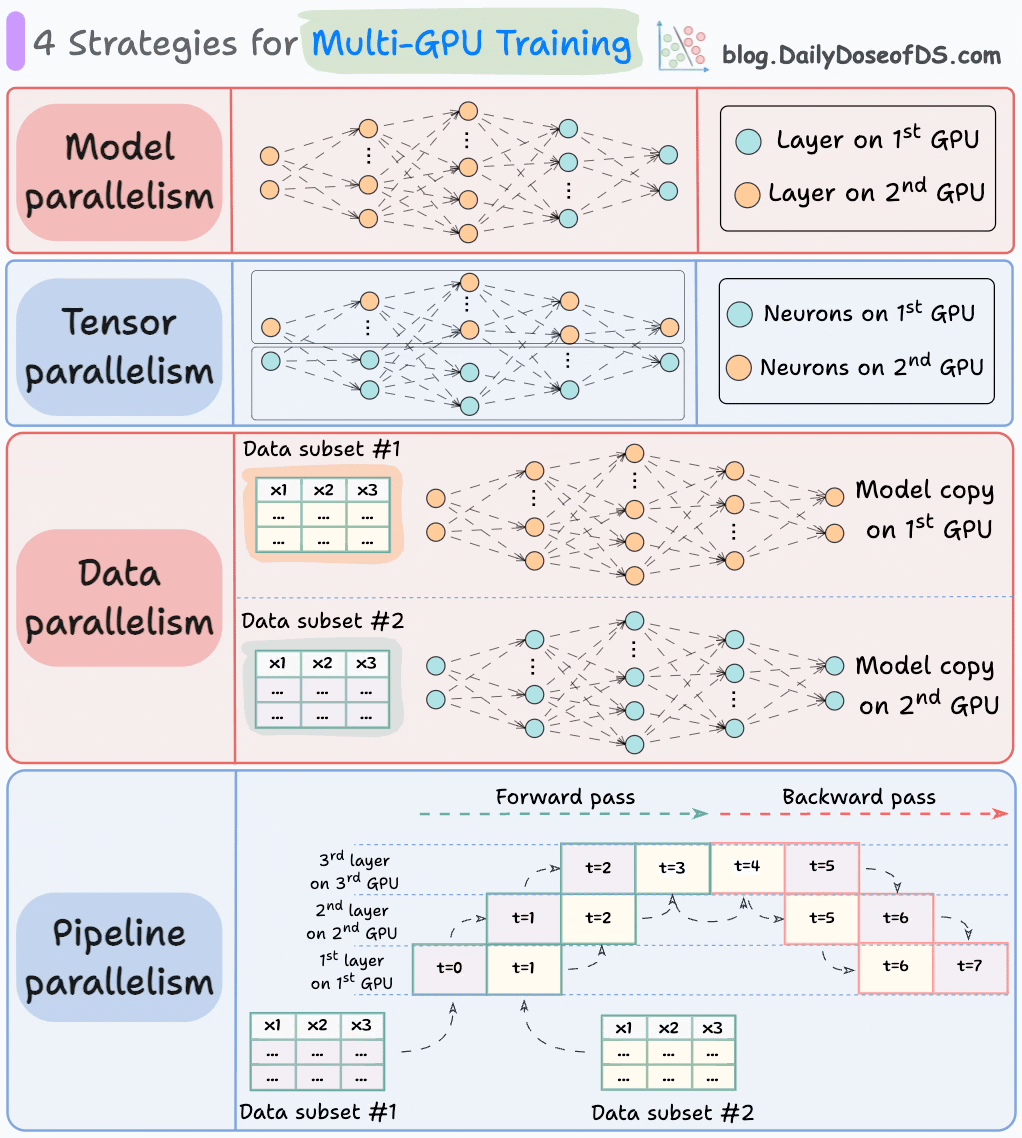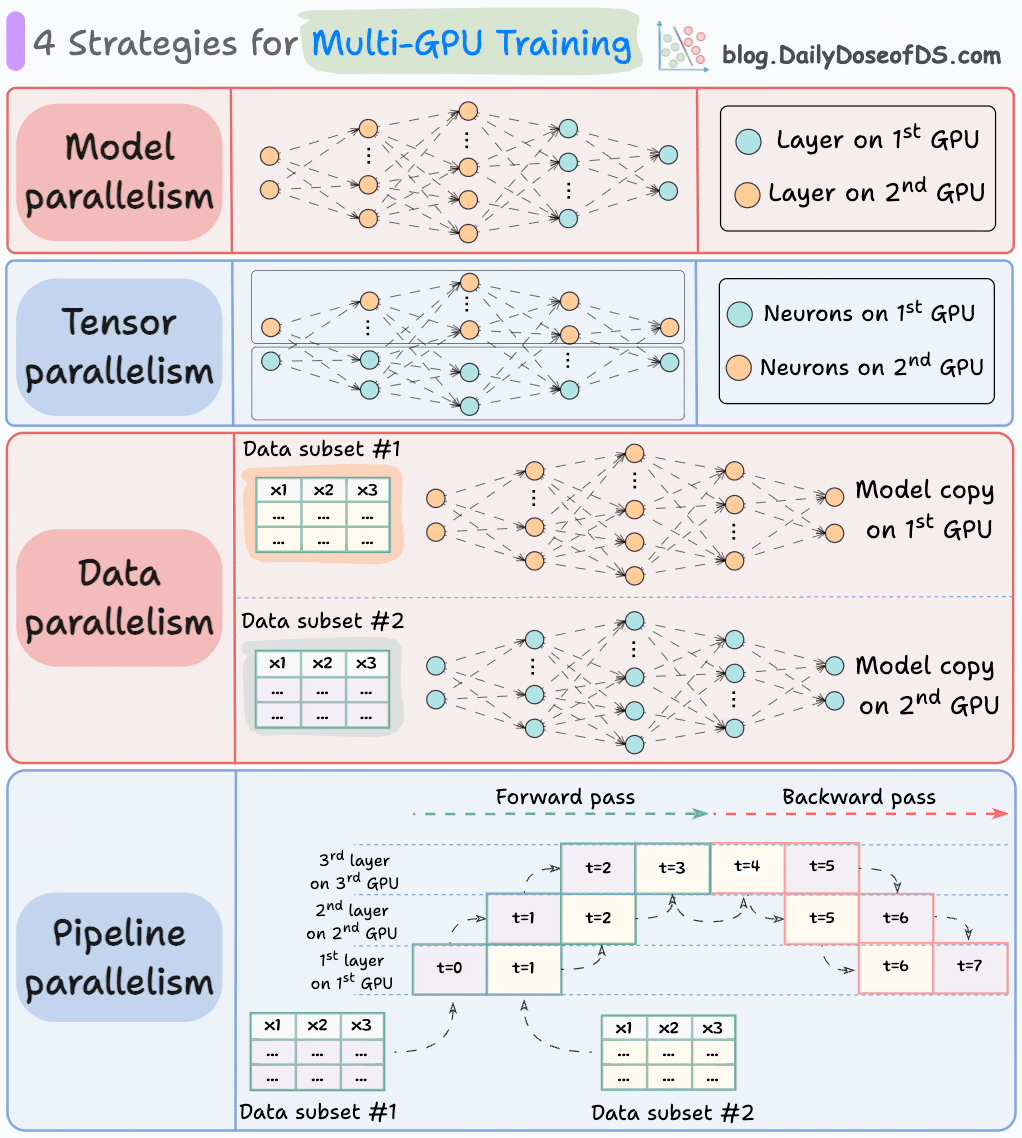
The graphic below depicts four common strategies for multi-GPU training:
We covered multi-GPU training in detail with implementation here: A Beginner-friendly Guide to Multi-GPU Model Training.
Let’s discuss these four strategies below:
#1) Model parallelism

Different parts (or layers) of the model are placed on different GPUs.
Useful for huge models that do not fit on a single GPU.
However, model parallelism also introduces severe bottlenecks as it requires data flow between GPUs when activations from one GPU are transferred to another GPU.
#2) Tensor parallelism

Distributes and processes individual tensor operations across multiple devices or processors.
It is based on the idea that a large tensor operation, such as matrix multiplication, can be divided into smaller tensor operations, and each smaller operation can be executed on a separate device or processor.
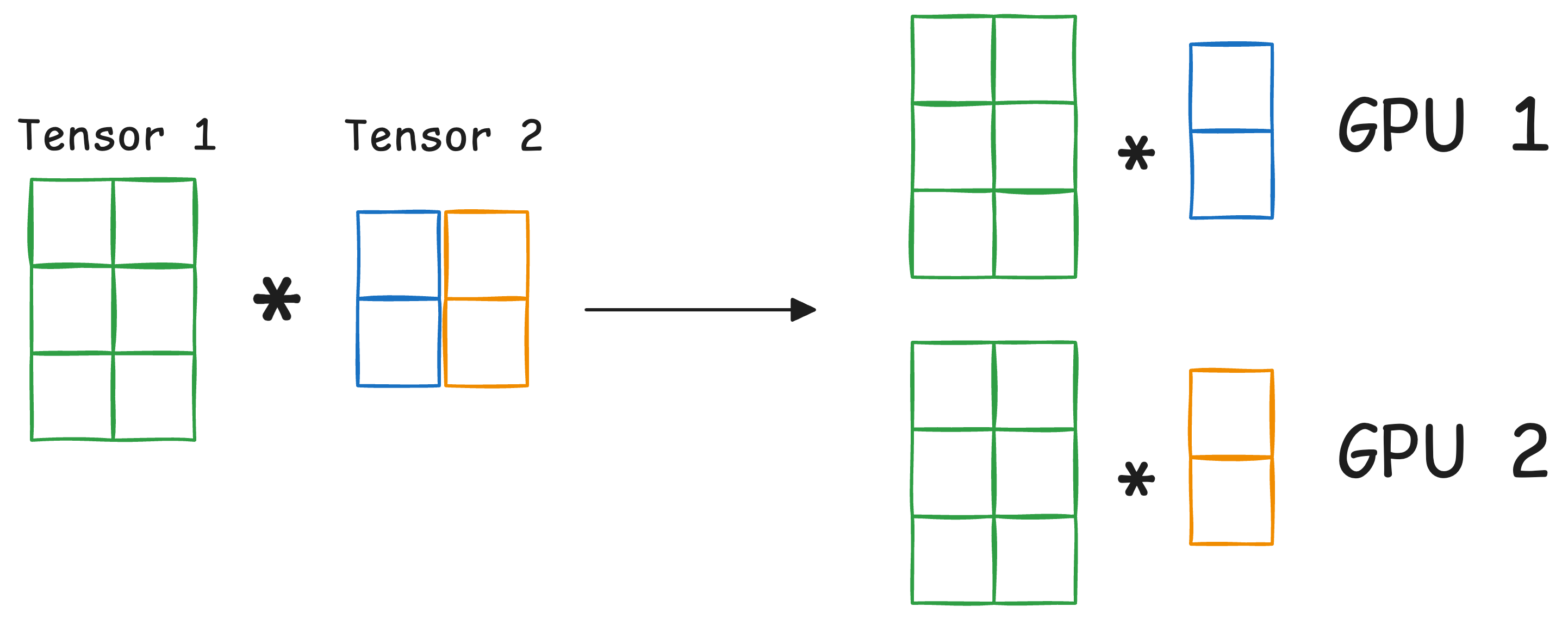
Such parallelization strategies are inherently built into standard implementations of PyTorch and other deep learning frameworks, but they become much more pronounced in a distributed setting.
#3) Data parallelism
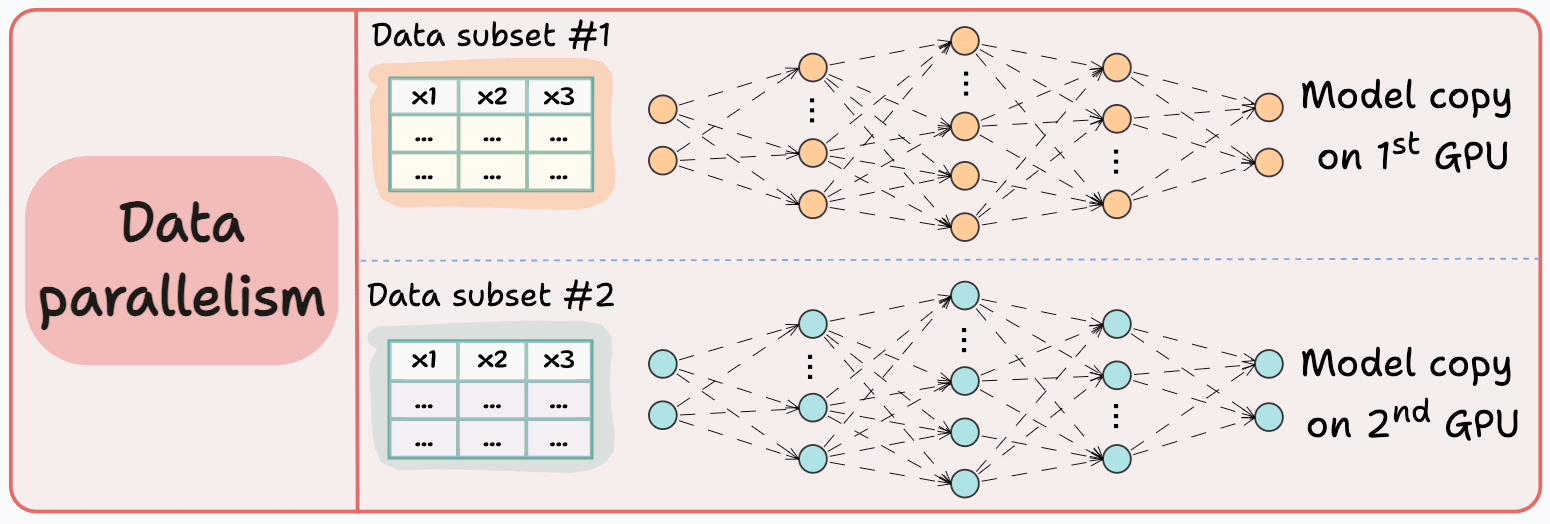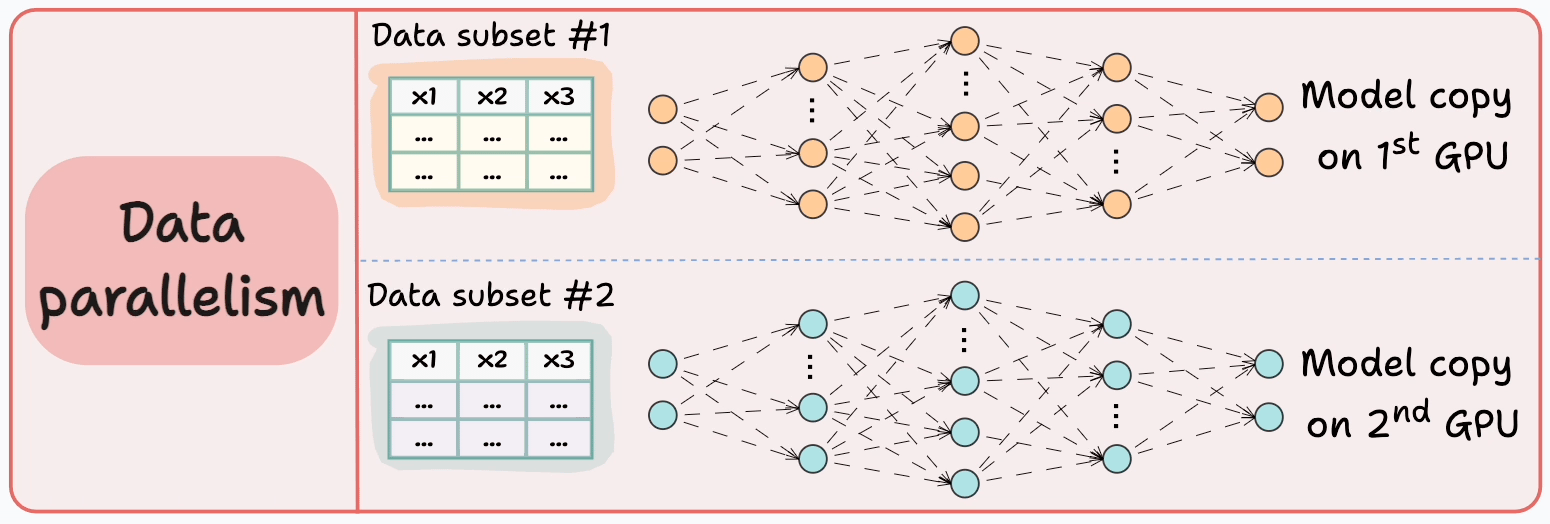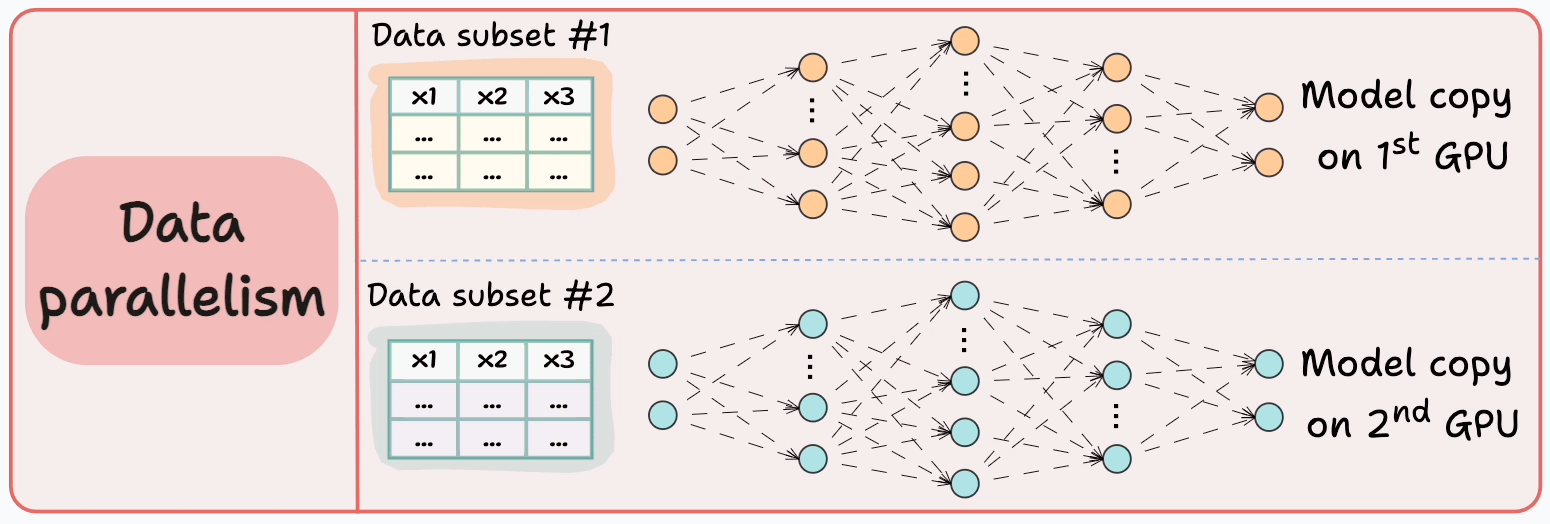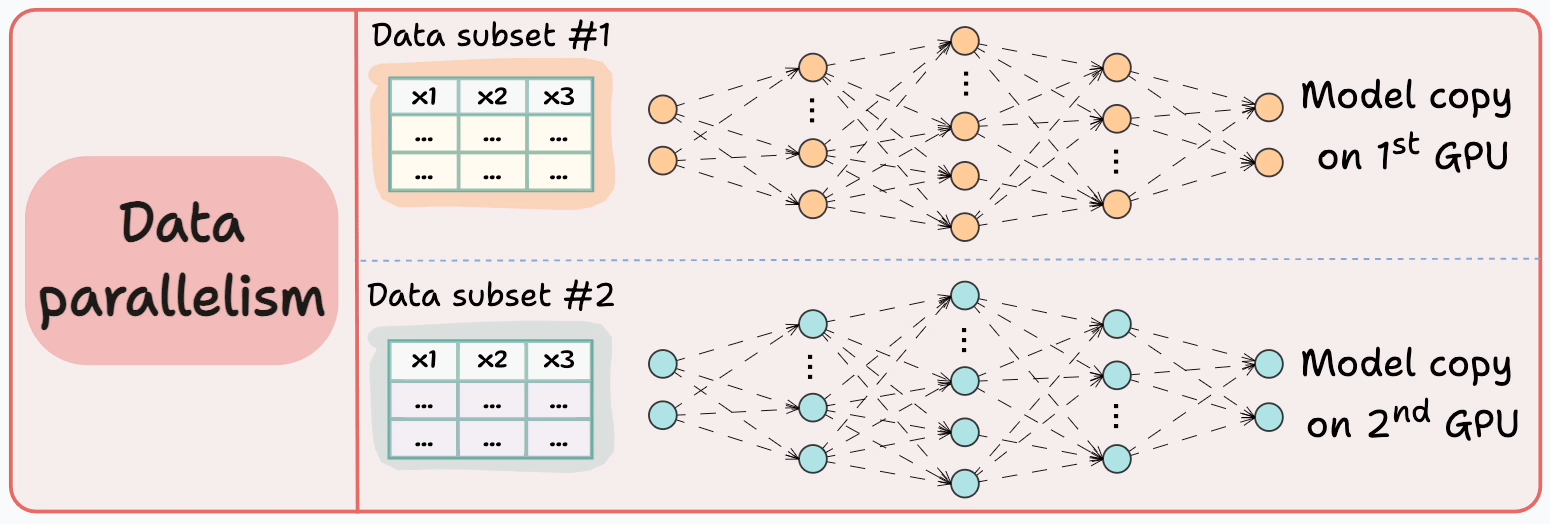
Replicate the model across all GPUs.
Divide the available data into smaller batches, and each batch is processed by a separate GPU.
The updates (or gradients) from each GPU are then aggregated and used to update the model parameters on every GPU.
#4) Pipeline parallelism
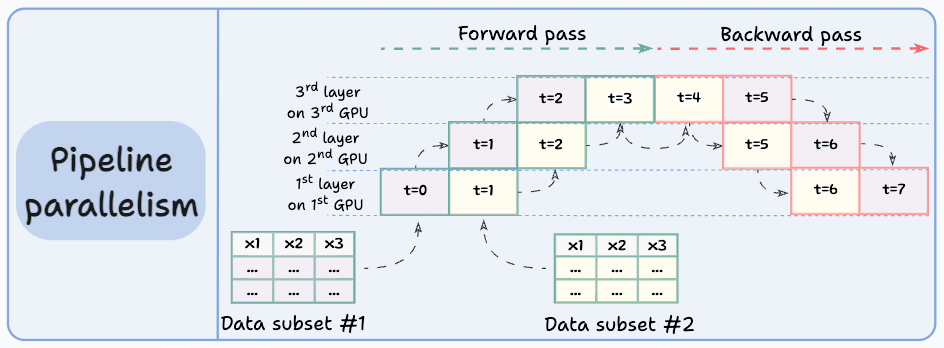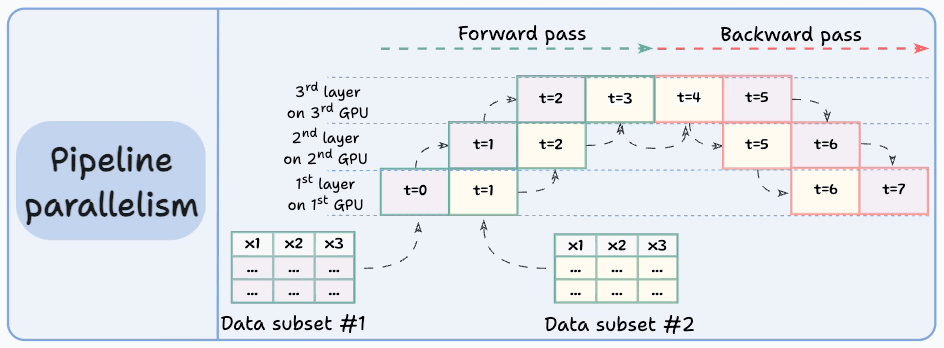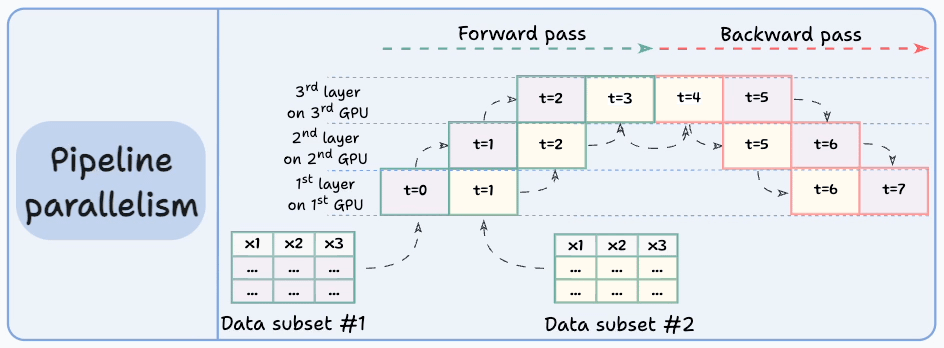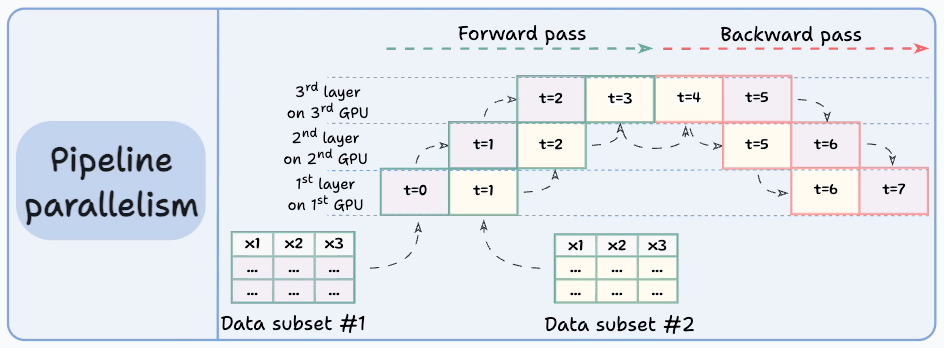
This is often considered a combination of data parallelism and model parallelism.
So the issue with standard model parallelism is that 1st GPU remains idle when data is being propagated through layers available in 2nd GPU:
Pipeline parallelism addresses this by loading the next micro-batch of data once the 1st GPU has finished the computations on the 1st micro-batch and transferred activations to layers available in the 2nd GPU. The process looks like this:
1st micro-batch passes through the layers on 1st GPU.
2nd GPU receives activations on 1st micro-batch from 1st GPU.
While the 2nd GPU passes the data through the layers, another micro-batch is loaded on the 1st GPU.
And the process continues.
GPU utilization drastically improves this way. This is evident from the animation below where multi-GPUs are being utilized at the same timestamp (look at t=1, t=2, t=5, and t=6):
Those were four common strategies for multi-GPU training.
To get into more details about multi-GPU training and implementation, read this article: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, we covered 15 ways to optimize neural network training here (with implementation).
👉 Over to you: What are some other strategies for multi-GPU training?
Train LLMs 3× faster without any accuracy loss
Unsloth just dropped new Triton kernels + auto packing that makes fine-tuning much easier!
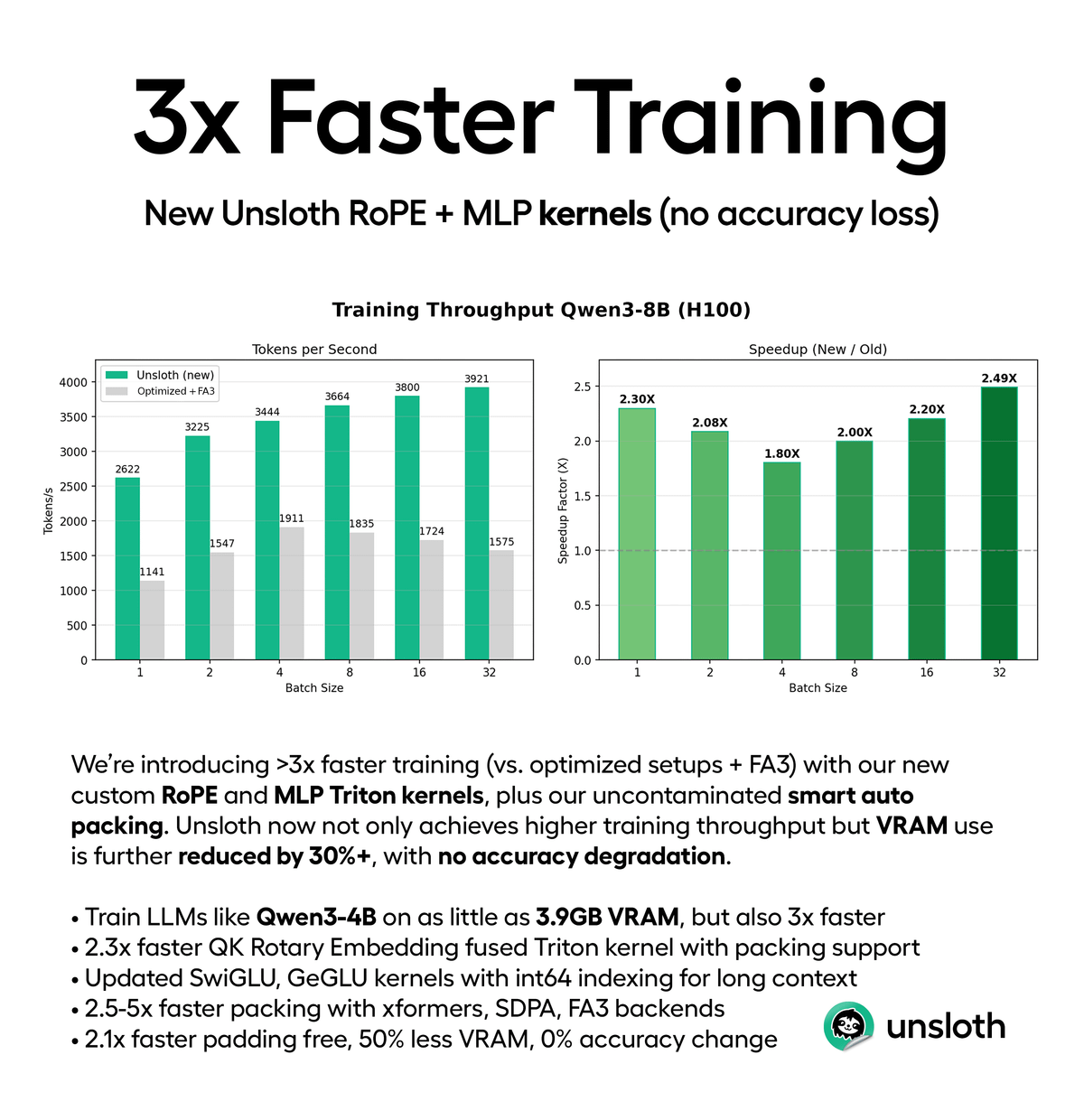
Here’s why this matters:
You can now fine-tune Qwen3-4B on just 3GB VRAM. That’s a consumer GPU. Your GPU.
The new release includes:
↳ Fused QK RoPE kernel that’s 2.3x faster on long contexts
↳ Smart padding-free packing is enabled by default
↳ Works with FlashAttention 3, xFormers, and SDPA
↳ 30-90% less VRAM usage
The math behind this is elegant:
Real datasets have varying sequence lengths. Padding short sequences to match long ones wastes compute. If 80% of your sequences are short, packing gives you 5x speedup by eliminating that waste entirely.
The barrier for local fine-tuning keeps dropping.
We’re moving from “who can afford cloud compute” to “who can iterate fastest on their own GPUs.”
To get started, here’s a blog and starter notebooks →
We’ll cover this in a more hands-on demo soon.
Thanks for reading!