
4 Strategies for Multi-GPU Training
...explained visually.

Integrate 100,000+ APIs into AI Agents in 3 clicks!
Agents, on their own, may not hold much practical value. To work well, they need context from data/services/APIs.
But every API requires us to manually process API documentation, configure authentication, handle parameters, and write boilerplate code before even testing if the integration works.

Postman’s AI Agent Builder provides a Tool Generation API—a massive time saver for anyone working with AI agents.
With just three clicks, you can:
Find an API in Postman’s Network.
Pick a programming language and agent framework.
Generate production-ready code that integrates seamlessly into your AI agent.
This means AI developers can focus on building and optimizing workflows instead of spending hours troubleshooting API integrations.
Postman’s AI Agent Builder will save you plenty of time and manual workload if you're working with agentic workflows.
Thanks to Postman for partnering on today’s issue!
4 Strategies for Multi-GPU Training
By default, deep learning models only utilize a single GPU for training, even if multiple GPUs are available.
An ideal way to train models is to distribute the training workload across multiple GPUs.
The graphic below depicts four common strategies for multi-GPU training:
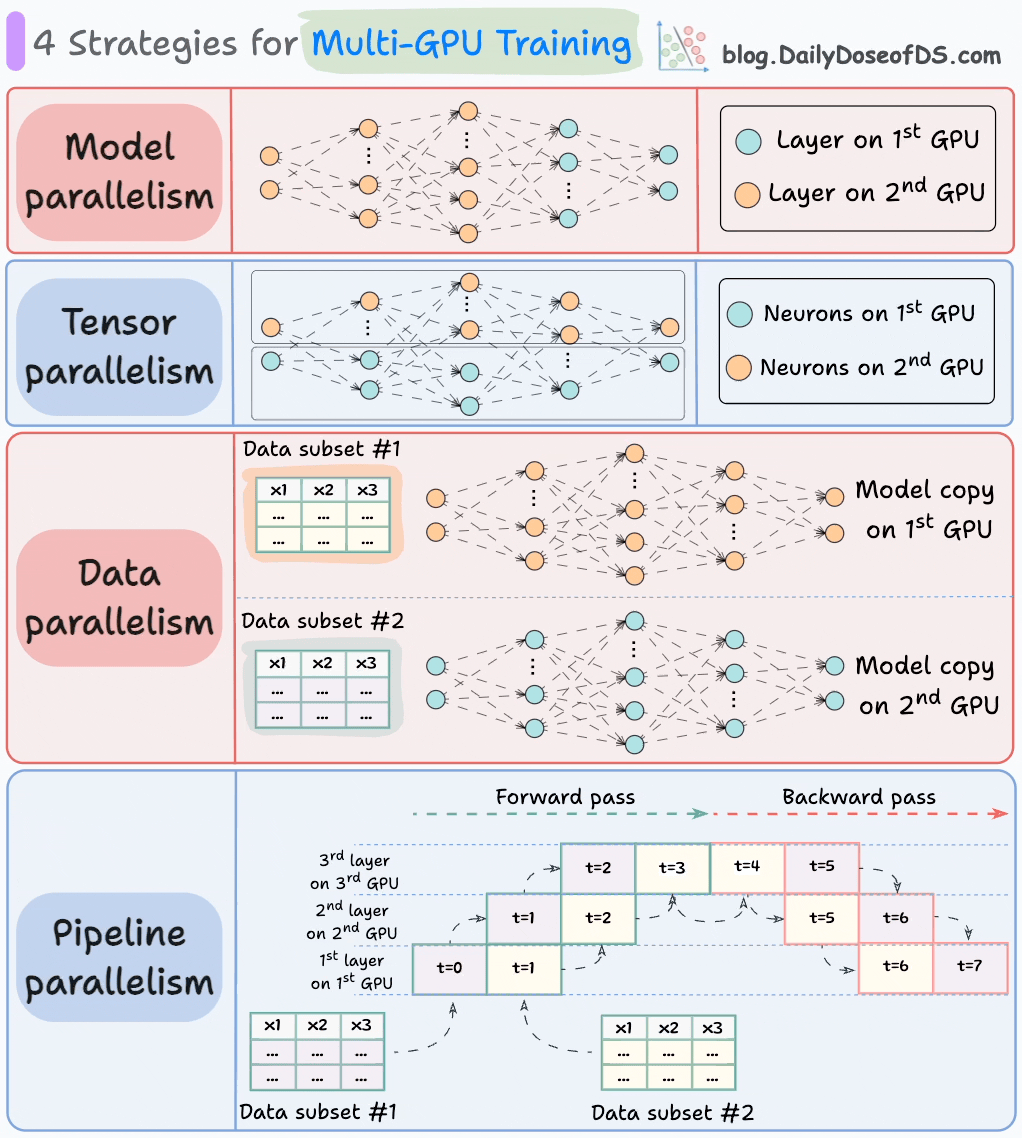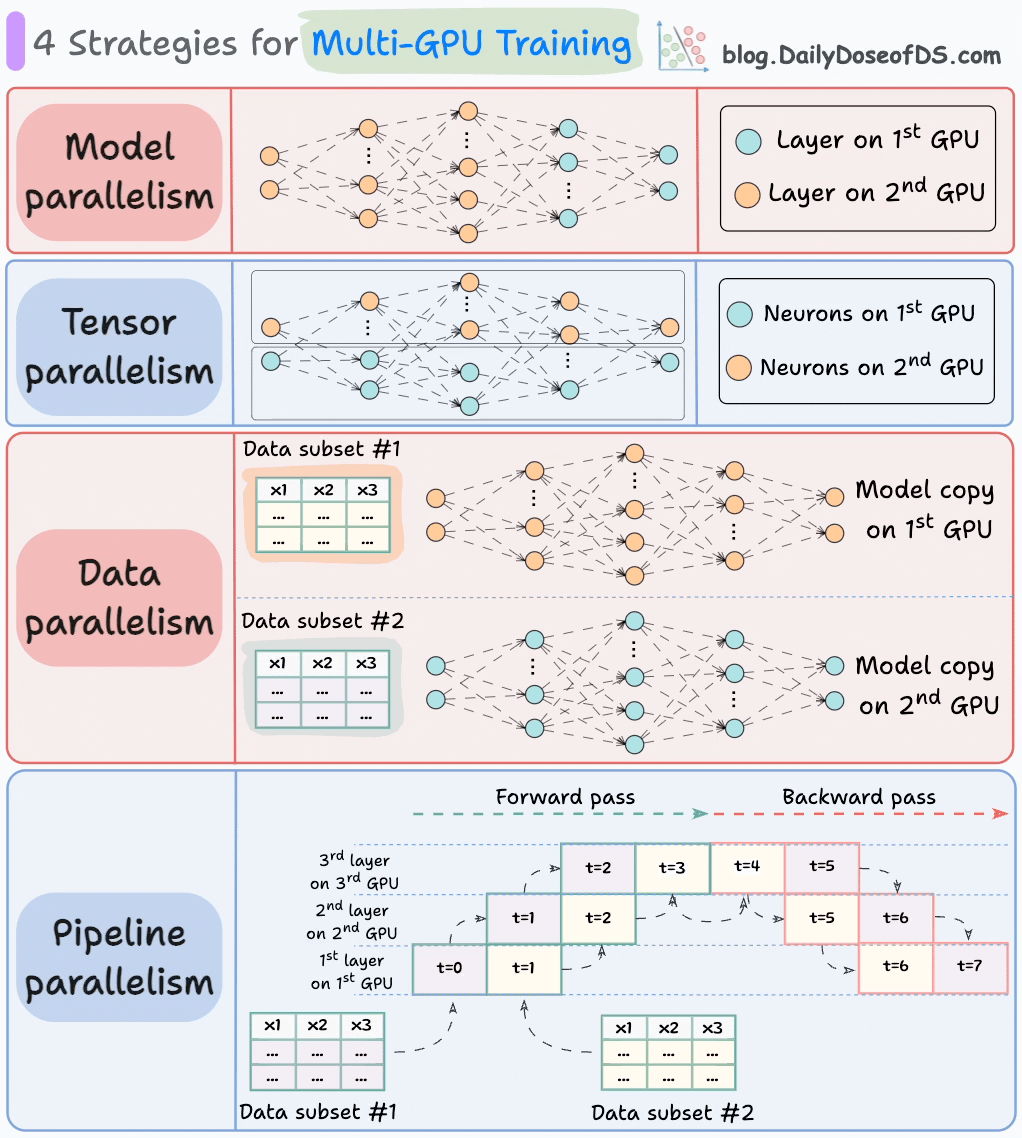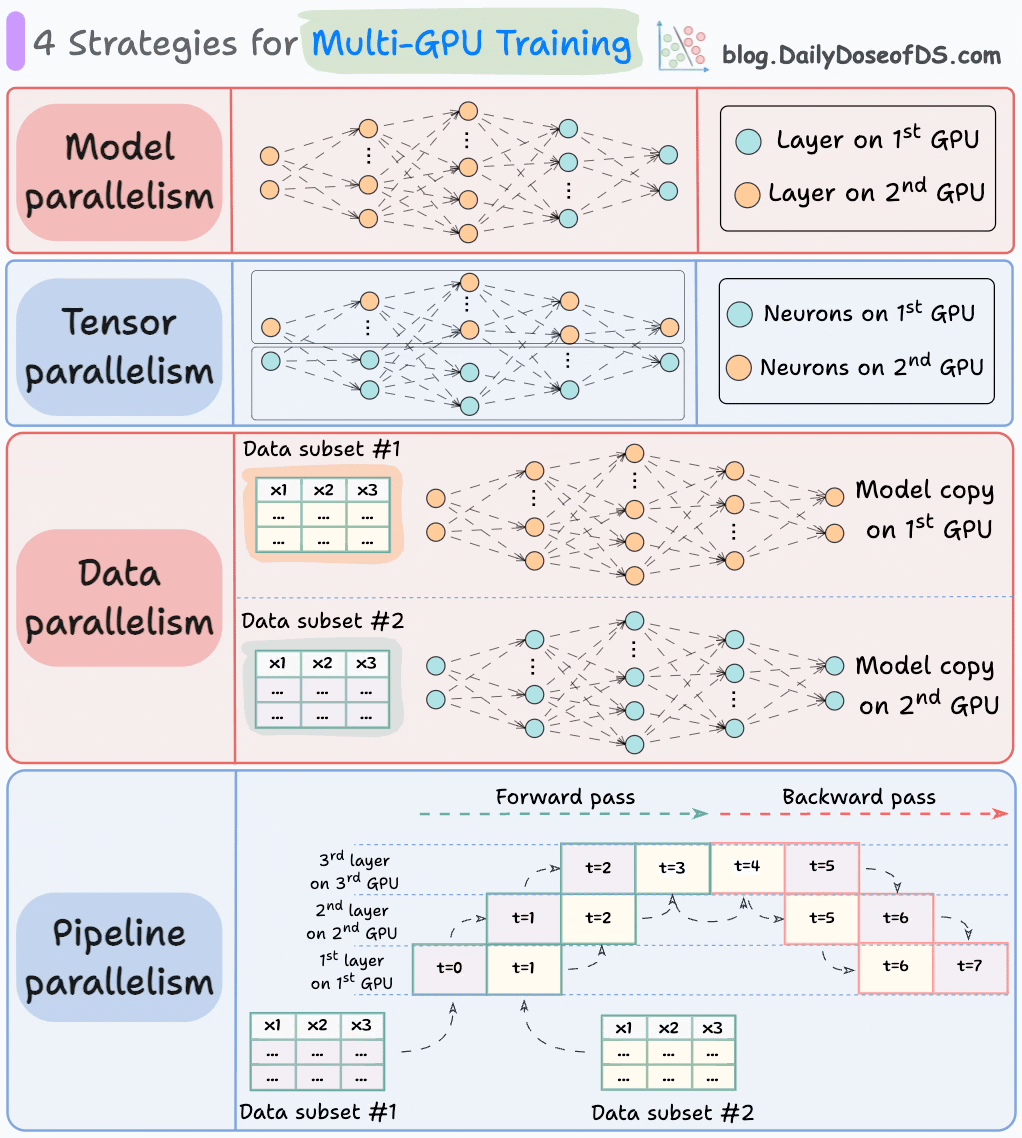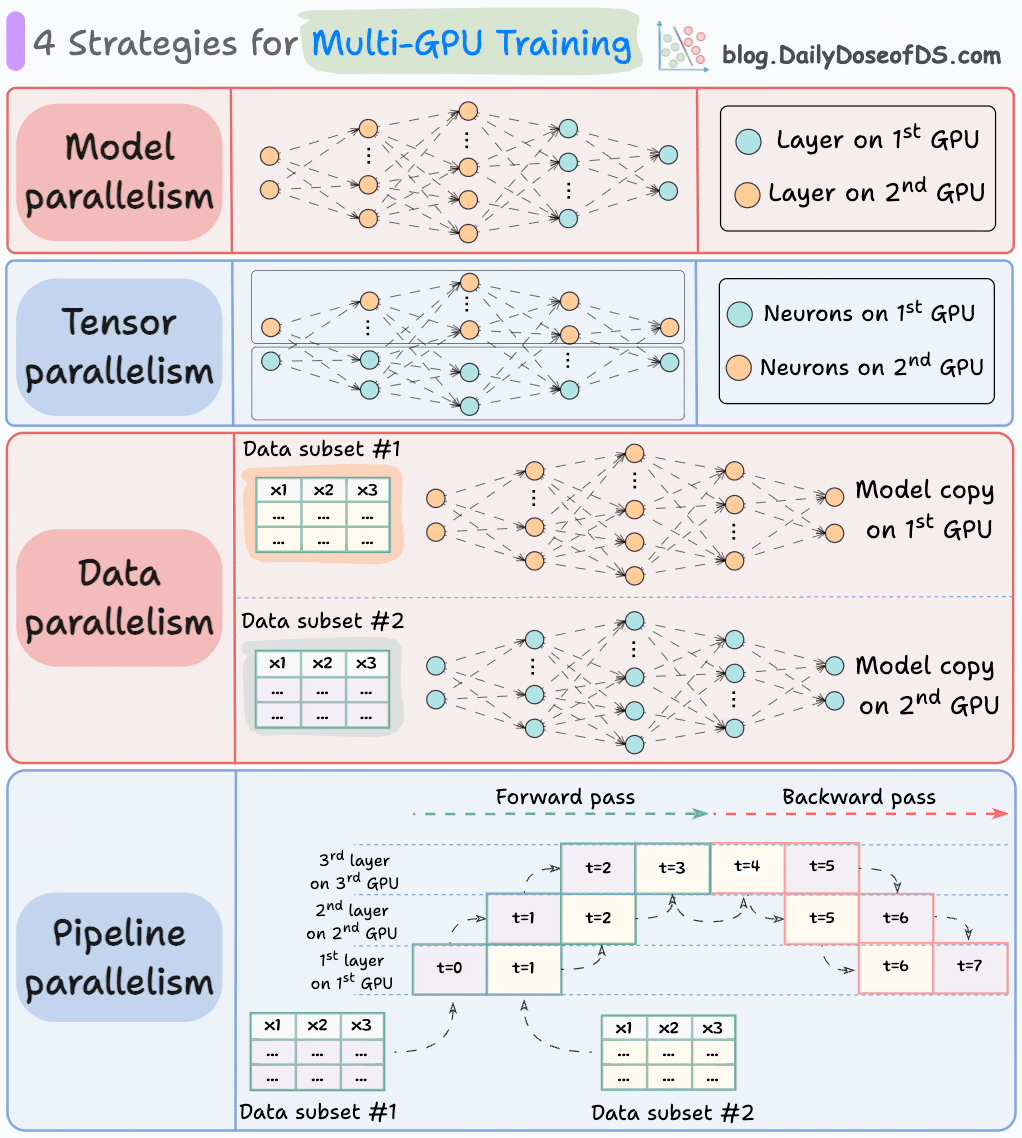
We covered multi-GPU training in detail with implementation here: A Beginner-friendly Guide to Multi-GPU Model Training.
Let’s discuss these four strategies below:
#1) Model parallelism

Different parts (or layers) of the model are placed on different GPUs.
Useful for huge models that do not fit on a single GPU.
However, model parallelism also introduces severe bottlenecks as it requires data flow between GPUs when activations from one GPU are transferred to another GPU.
#2) Tensor parallelism

Distributes and processes individual tensor operations across multiple devices or processors.
It is based on the idea that a large tensor operation, such as matrix multiplication, can be divided into smaller tensor operations, and each smaller operation can be executed on a separate device or processor.
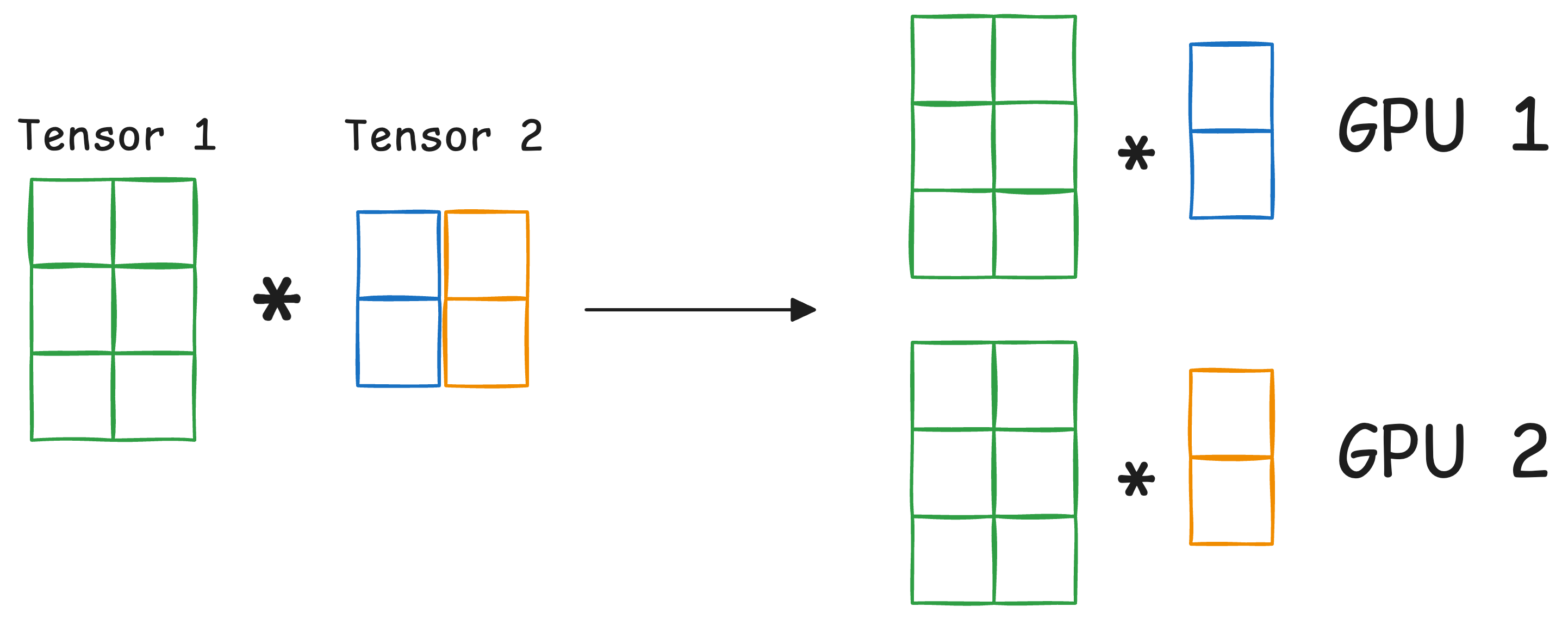
Such parallelization strategies are inherently built into standard implementations of PyTorch and other deep learning frameworks, but they become much more pronounced in a distributed setting.
#3) Data parallelism
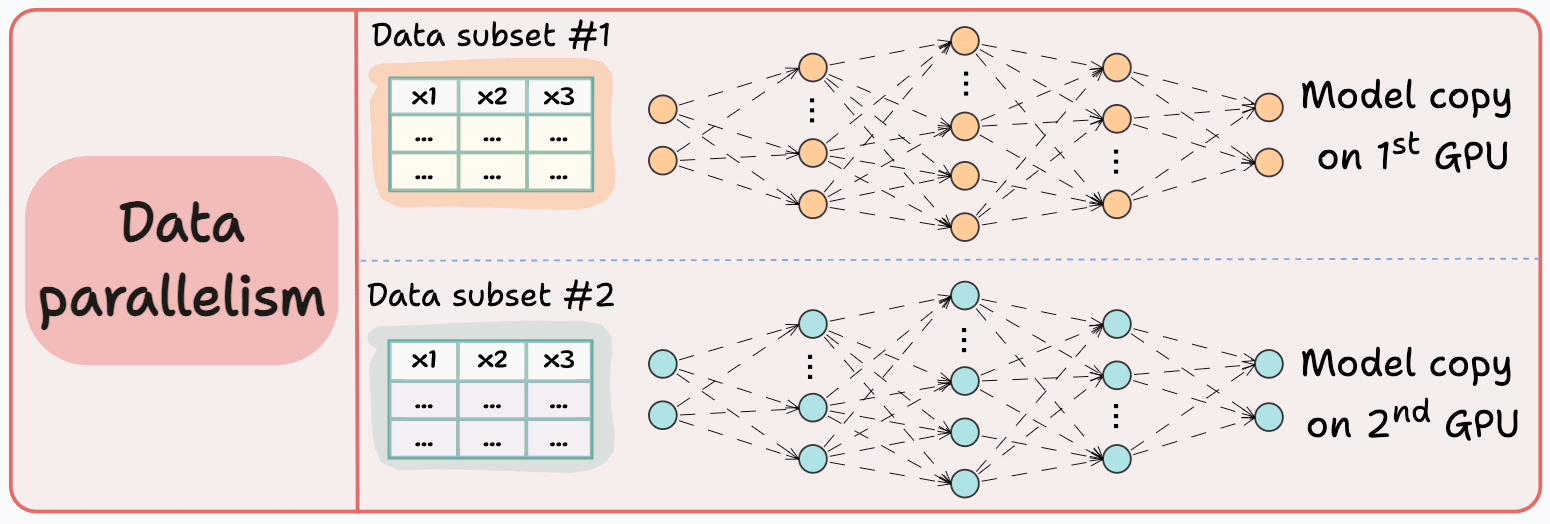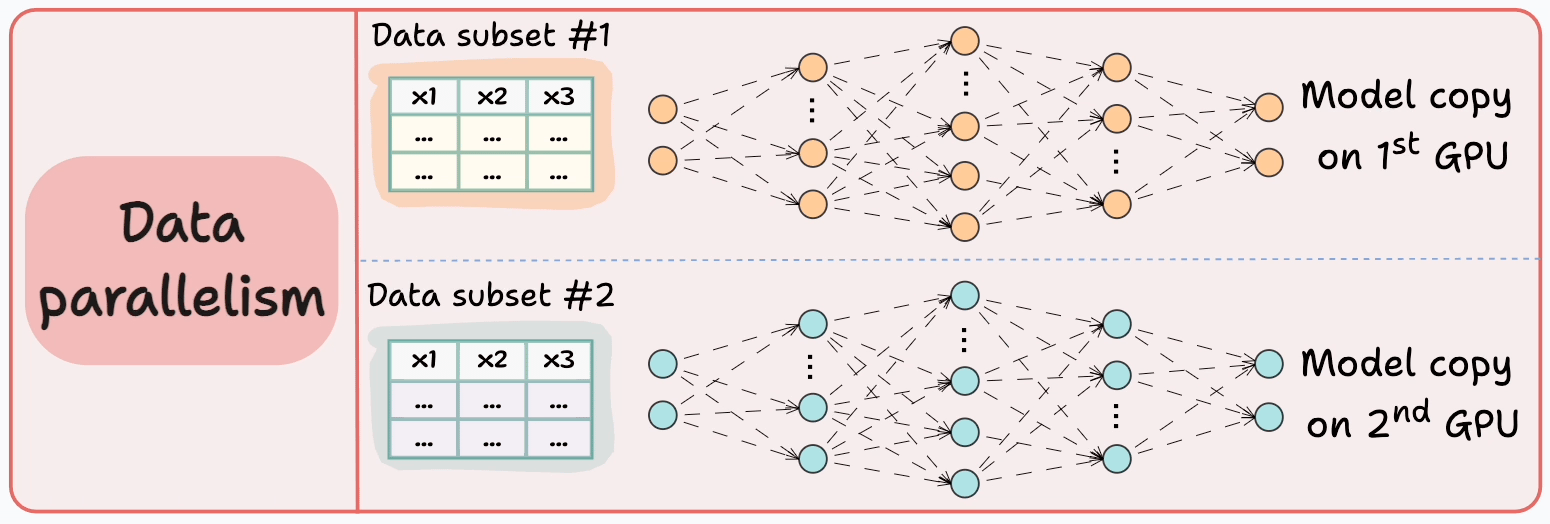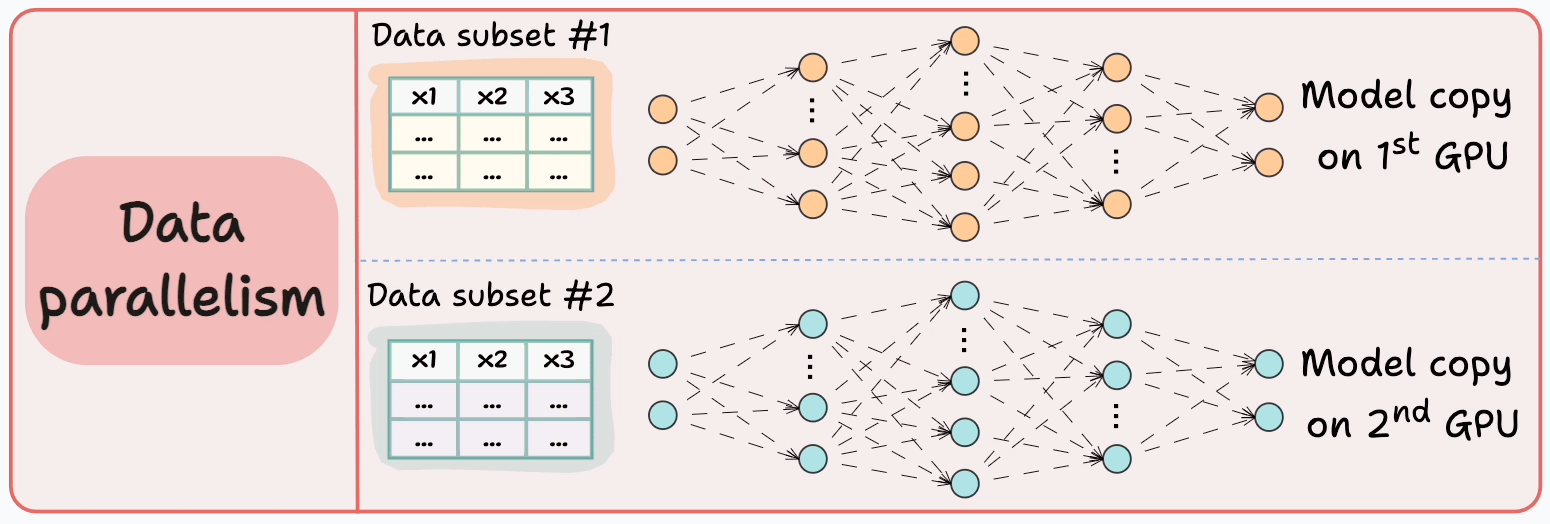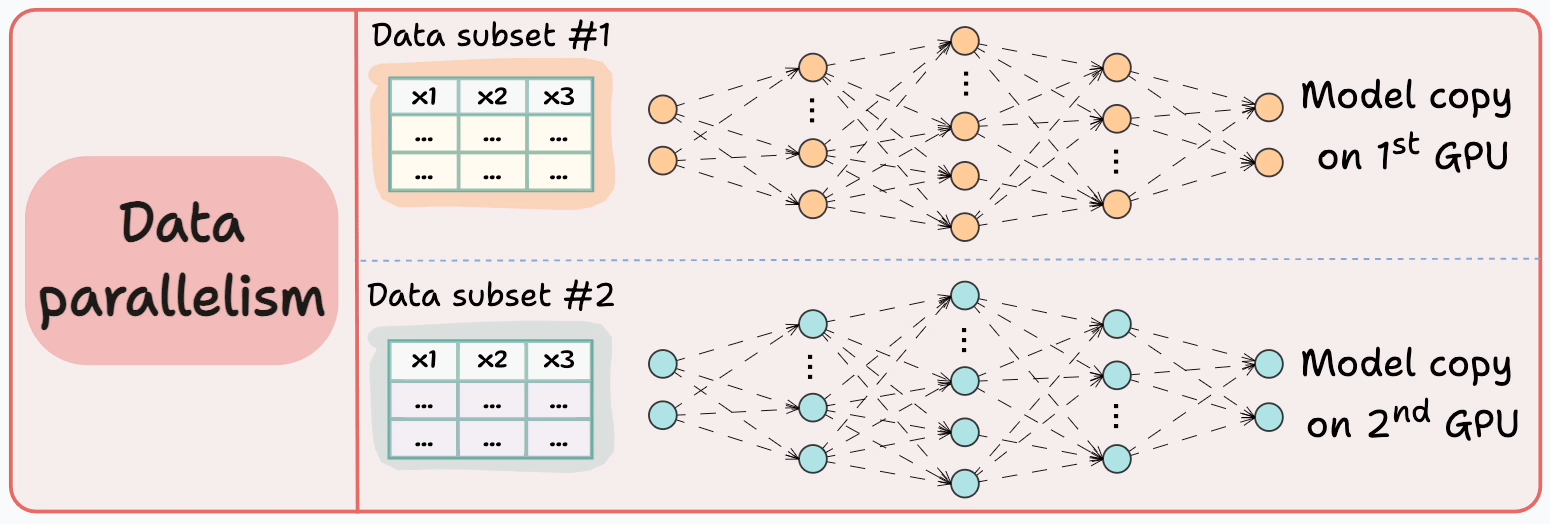
Replicate the model across all GPUs.
Divide the available data into smaller batches, and each batch is processed by a separate GPU.
The updates (or gradients) from each GPU are then aggregated and used to update the model parameters on every GPU.
#4) Pipeline parallelism
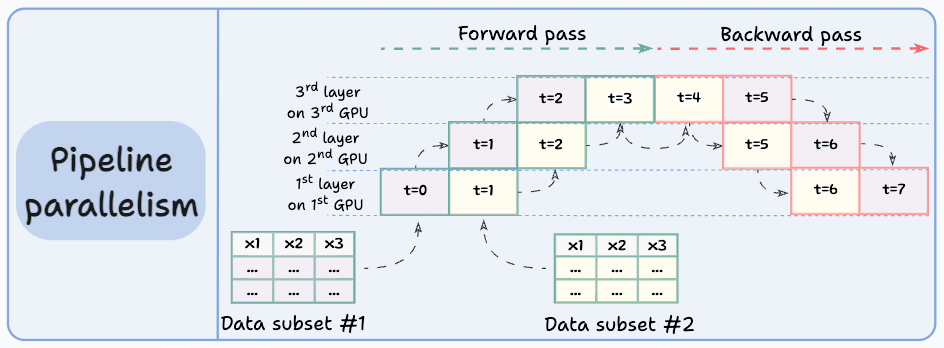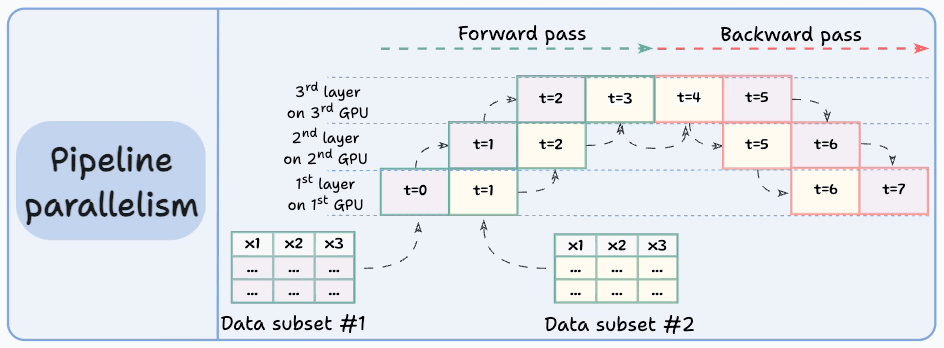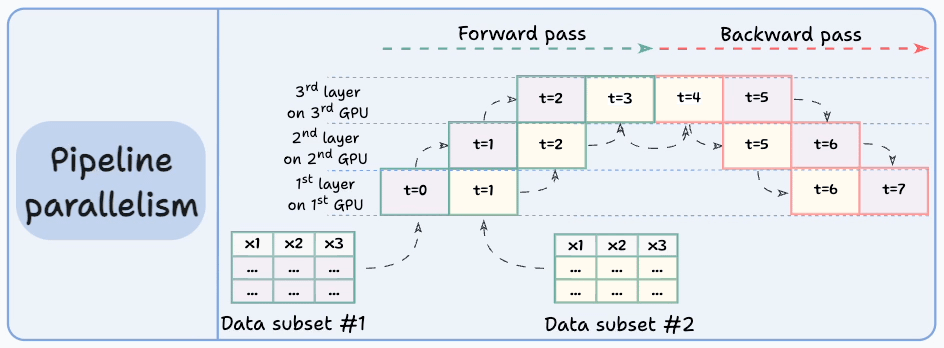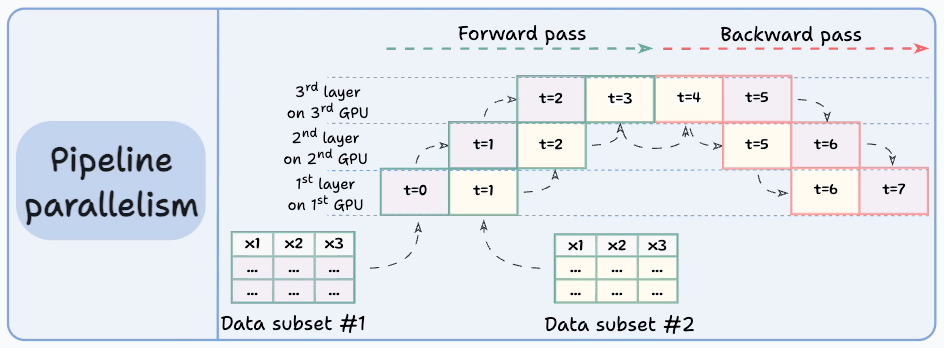
This is often considered a combination of data parallelism and model parallelism.
So the issue with standard model parallelism is that 1st GPU remains idle when data is being propagated through layers available in 2nd GPU:
Pipeline parallelism addresses this by loading the next micro-batch of data once the 1st GPU has finished the computations on the 1st micro-batch and transferred activations to layers available in the 2nd GPU. The process looks like this:
1st micro-batch passes through the layers on 1st GPU.
2nd GPU receives activations on 1st micro-batch from 1st GPU.
While the 2nd GPU passes the data through the layers, another micro-batch is loaded on the 1st GPU.
And the process continues.
GPU utilization drastically improves this way. This is evident from the animation below where multi-GPUs are being utilized at the same timestamp (look at t=1, t=2, t=5, and t=6):
Those were four common strategies for multi-GPU training.
To get into more details about multi-GPU training and implementation, read this article: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, we covered 15 ways to optimize neural network training here (with implementation).
👉 Over to you: What are some other strategies for multi-GPU training?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.