
4 Ways to Run LLMs Locally
Llama-3, DeepSeek, Phi, and many many more.

Access DeepSeek on the fastest inference engine
Below, DeepSeek-R1 (distilled Llama-70B) is generating 330 tokens per second—most likely the fastest you will find anywhere.
Optimized inference engines are as important as having good LLMs.
But GPUs weren’t built for AI.
SambaNova Systems built the world’s fastest AI inference using its specialized hardware stack (RDUs)—a 10x faster alternative to GPU.
SambaNova Cloud delivers:
10x faster inference than GPUs
Support for trillion-parameter models
Optimized performance for most open-source models.
Thanks to SambaNova Systems for partnering on today’s issue.
4 Ways to Run LLMs Locally
Continuing the discussion from SambaNova…
Being able to run LLMs also has many upsides:
Privacy since your data never leaves your machine.
Testing things locally before moving to the cloud and more.
Here are four ways to run LLMs locally.
#1) Ollama
Running a model through Ollama is as simple as executing this command:

To get started, install Ollama with a single command:
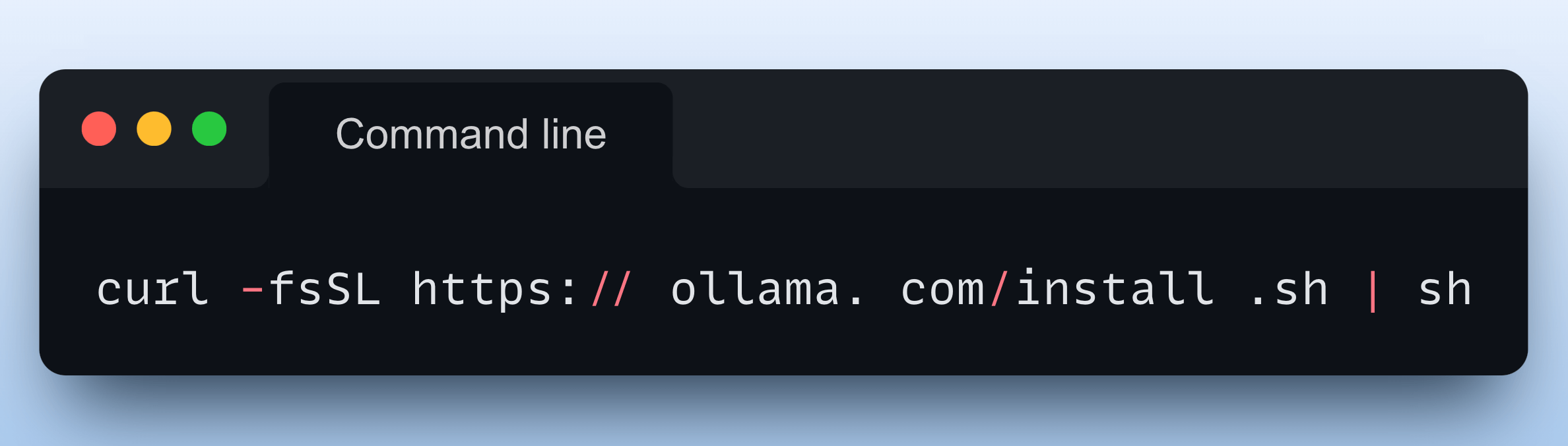
Done!
Now, you can download any of the supported models using these commands:

For programmatic usage, you can also install the Python package of Ollama or its integration with orchestration frameworks like Llama Index or CrewAI:

We heavily used Ollama in our RAG crash course if you want to dive deeper.
The video below shows the usage of ollama run deepseek-r1 command:
#2) LMStudio
LMStudio can be installed as an app on your computer.
The app does not collect data or monitor your actions. Your data stays local on your machine. It’s free for personal use.
It offers a ChatGPT-like interface, allowing you to load and eject models as you chat. This video shows its usage:
Just like Ollama, LMStudio supports several LLMs as well.
#3) vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving.
With just a few lines of code, you can locally run LLMs (like DeepSeek) in an OpenAI-compatible format:

#4) LlamaCPP
LlamaCPP enables LLM inference with minimal setup and good performance.

Here’s DeepSeek-R1 running on a Mac Studio:
And these were four ways to run LLMs locally on your computer.
If you don’t want to get into the hassle of local setups, SambaNova’s fastest inference can be integrated into your existing LLM apps in just three lines of code:

Also, if you want to dive into building LLM apps, our full RAG crash course discusses RAG from basics to beyond:
👉 Over to you: Which method do you find the most useful?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.