
4 Ways to Test ML Models in Production
...explained visually

We have discussed before in this newsletter that…
…despite rigorously testing an ML model locally (on validation and test sets), it could be a terrible idea to instantly replace the previous model with the new model.

A more reliable strategy is to test the model in production (yes, on real-world incoming data).
While this might sound risky, ML teams do it all the time, and it isn’t that complicated.
The following visual depicts 4 common strategies to do so:
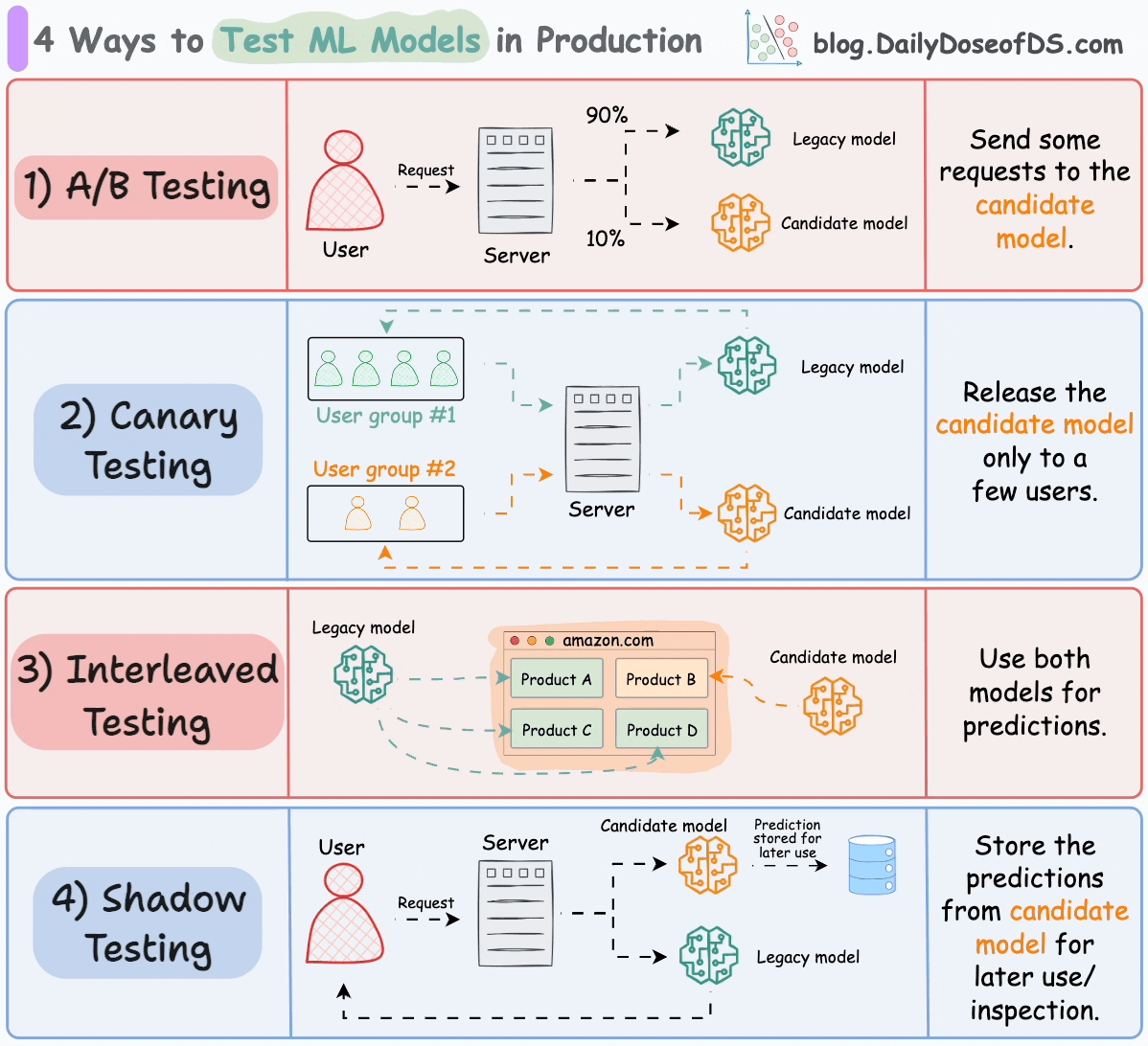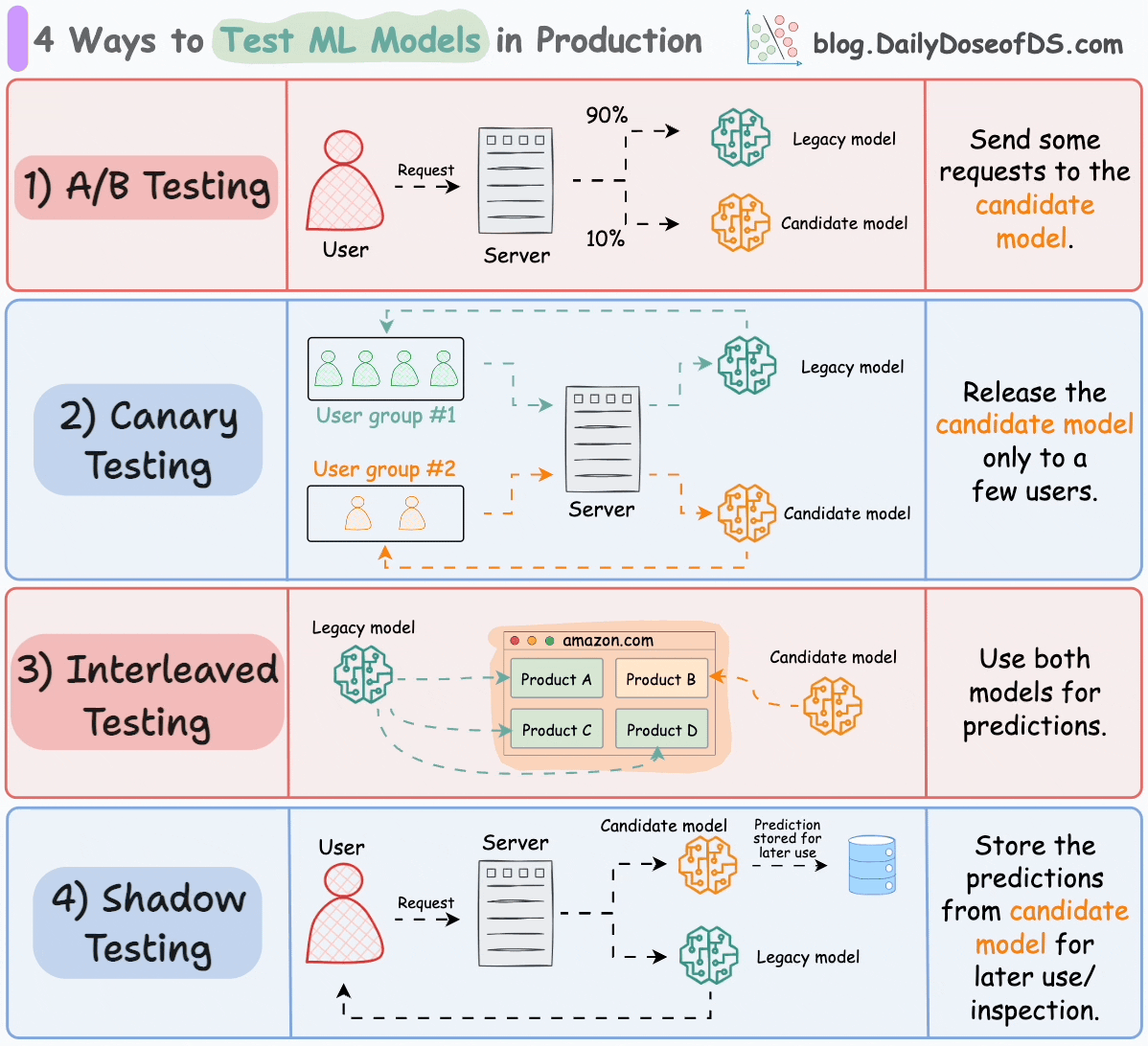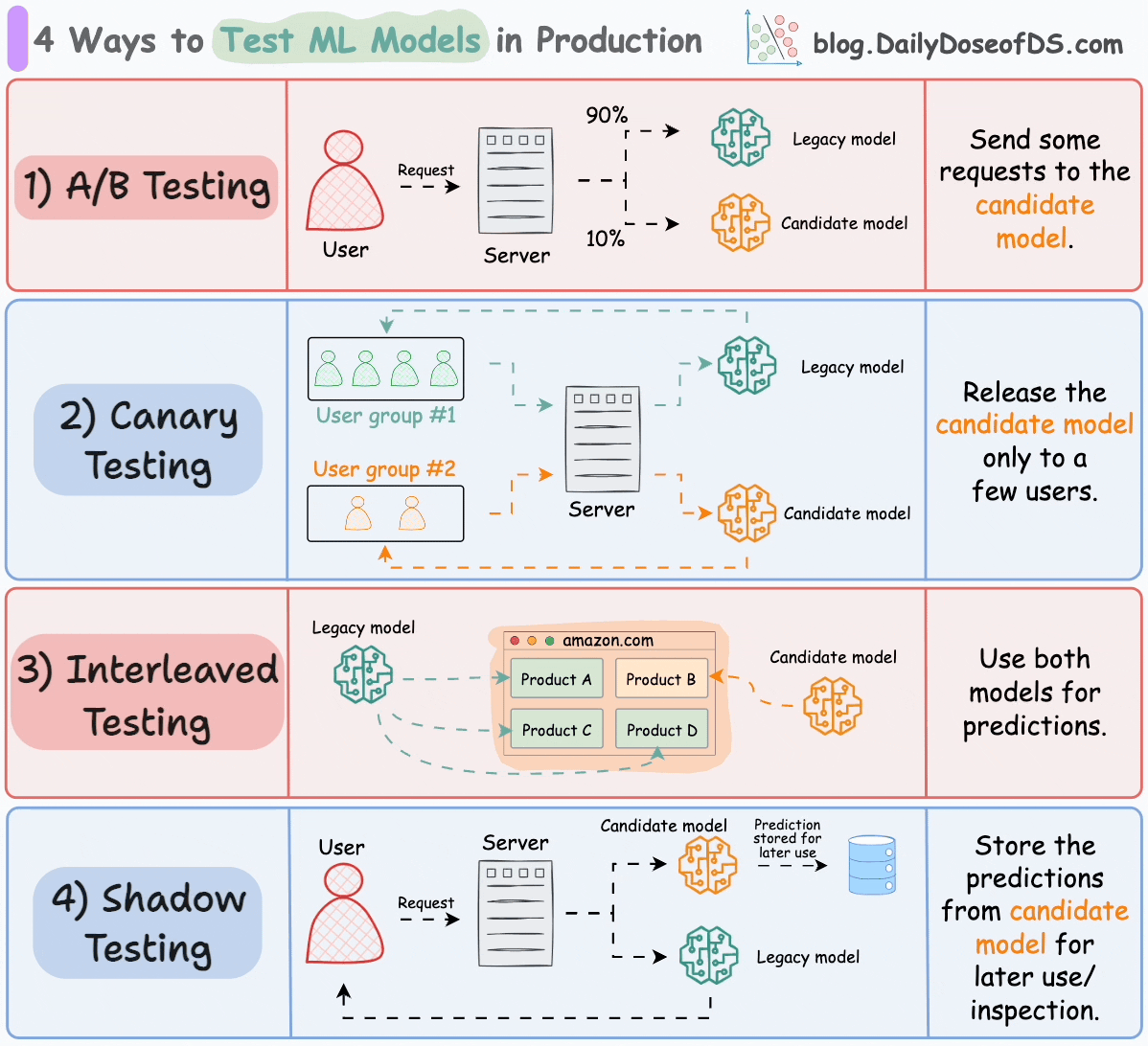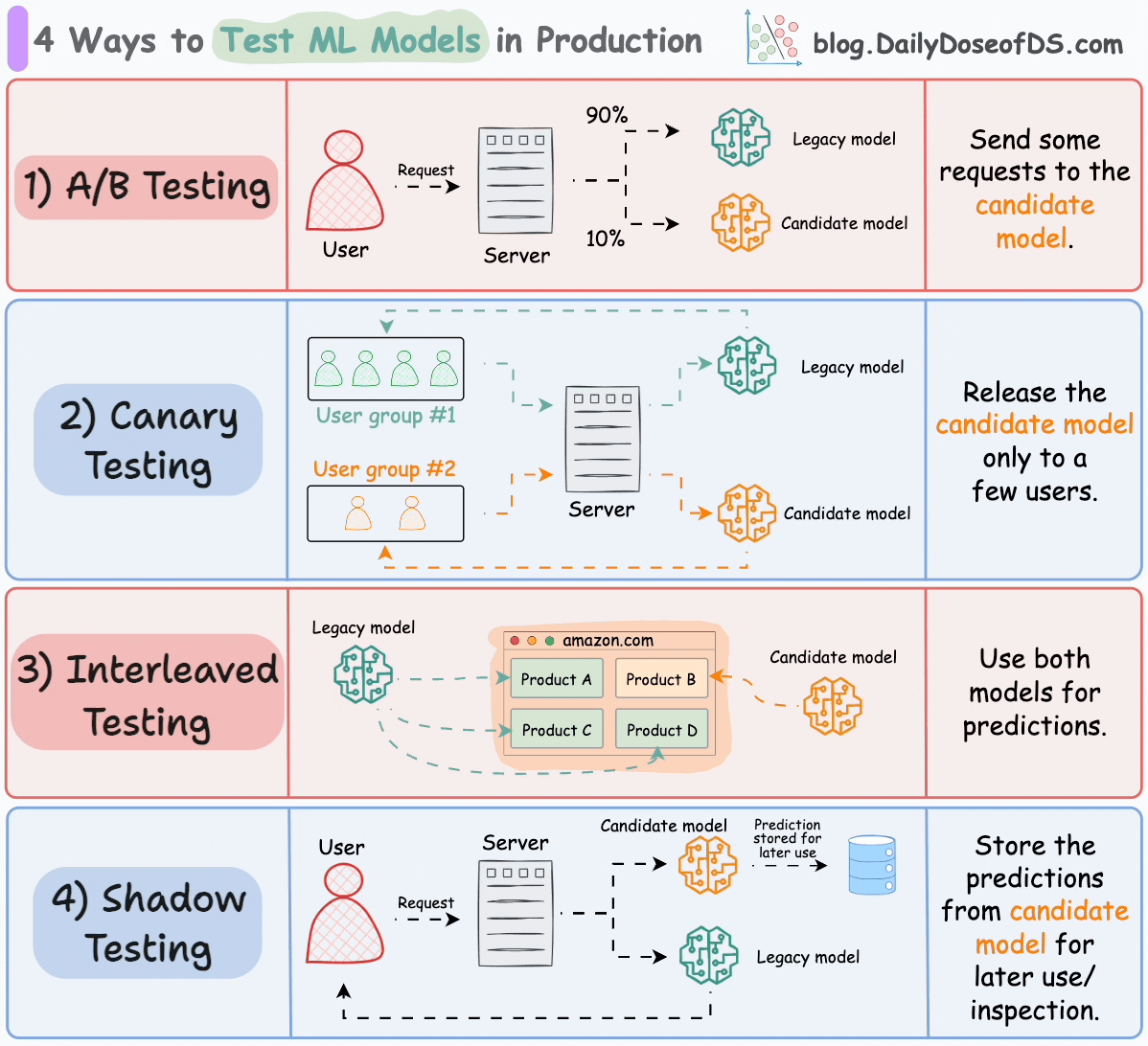
We covered their implementation here: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
The current model is called the legacy model.
The new model is called the candidate model.
#1) A/B testing
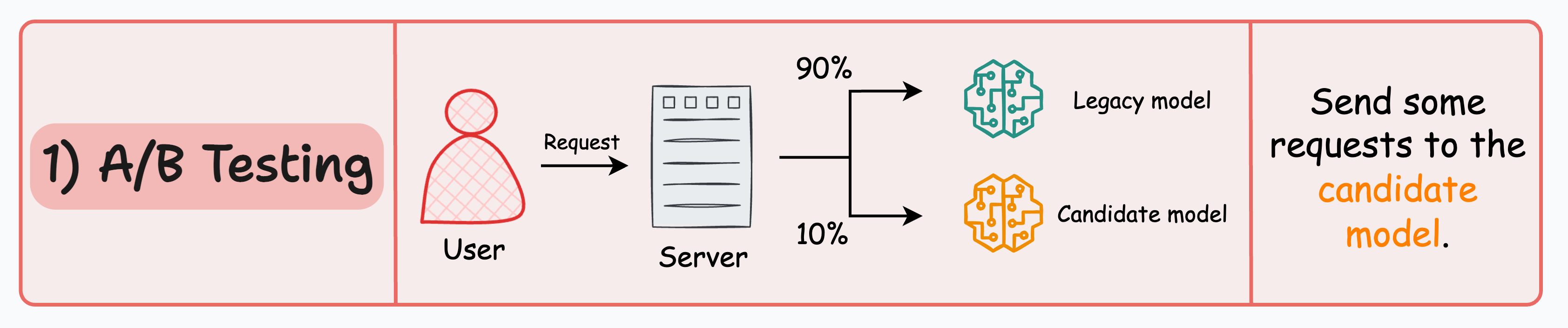
Distribute the incoming requests non-uniformly between the legacy model and the candidate model.
Intentionally limit the exposure of the candidate model to avoid any potential risks. Thus, the number of requests sent to the candidate model must be low.
#2) Canary testing
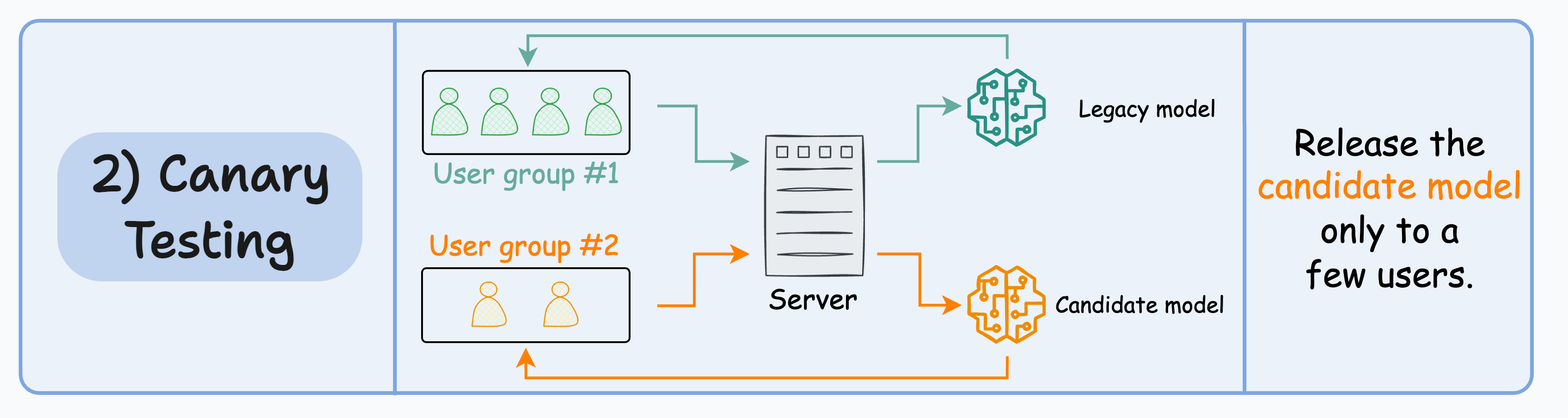
In A/B testing, since traffic is randomly redirected to either model irrespective of the user, it can potentially affect all users.
In canary testing, the candidate model is released to a small subset of users in production and gradually rolled out to more users.
#3) Interleaved testing

This involves mixing the predictions of multiple models in the response.
Consider Amazon’s recommendation engine. In interleaved deployments, some product recommendations displayed on their homepage can come from the legacy model, while some can be produced by the candidate model.
#4) Shadow testing
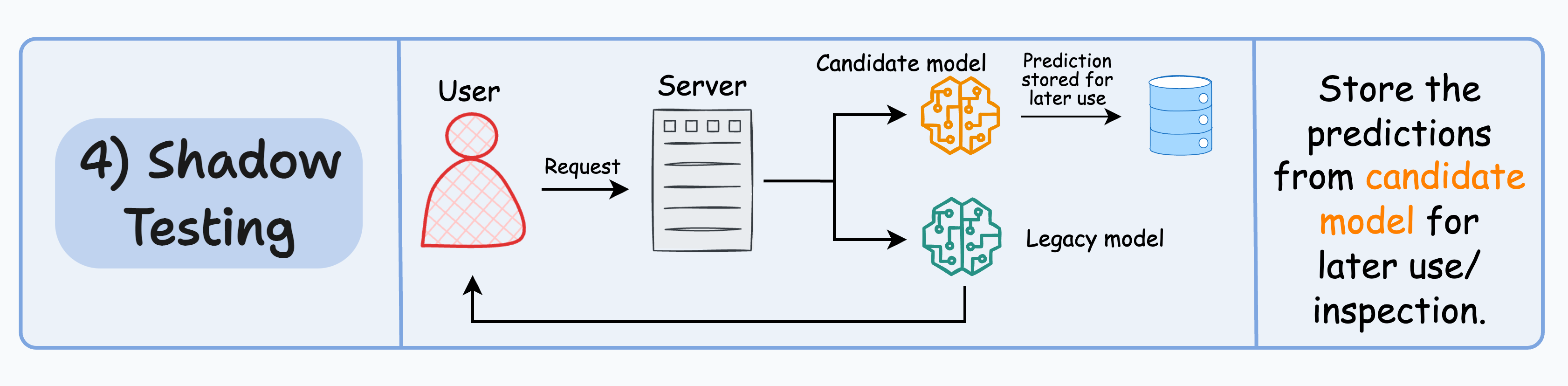
All of the above techniques affect some (or all) users.
Shadow testing (or dark launches) lets us test a new model in a production environment without affecting the user experience.
The candidate model is deployed alongside the existing legacy model and serves requests like the legacy model. However, the output is not sent back to the user. Instead, the output is logged for later use to benchmark its performance against the legacy model.
We explicitly deploy the candidate model instead of testing offline because the production environment is difficult to replicate offline.
Shadow testing offers risk-free testing of the candidate model in a production environment.
That’s it!
In the full article, we covered one more technique (Multi-armed bandits deployments) and the implementation of all five techniques: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
👉 Over to you: What are some ways to test models in production?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 80,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.