
4 Ways to Test ML Models in Production
...explained visually.

Simulate, evaluate, and observe your AI agents!

Most AI agents never make it to production—not because they aren’t useful, but because real-world testing is hard.
Maxim makes it effortless.
With Maxim’s AI-powered simulations and evaluations, you can:
Define realistic scenarios that simulate different user personas.
Run multi-turn conversations where your AI agent responds dynamically in real-world settings.
Evaluate performance at scale by automatically testing agents across multiple scenarios to get detailed evaluation scores on trajectory, step completion, and task success.
This way, you can reliably test your AI’s performance before deployment.
Thanks to Maxim for showing us their powerful evaluation and observability platform and partnering with us on today’s newsletter.
4 Ways to Test ML Models in Production
Continuing the discussion from agent testing…
…the following visual depicts 4 strategies to test ML models in production:
We covered one more technique (Multi-armed bandits deployments) and the implementation of all five techniques here: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Despite rigorously testing an ML model locally (on validation and test sets), it could be a terrible idea to instantly replace the previous model with the new model.

A more reliable strategy is to test the model in production (yes, on real-world incoming data).
While this might sound risky, ML teams do it all the time, and it isn’t that complicated.
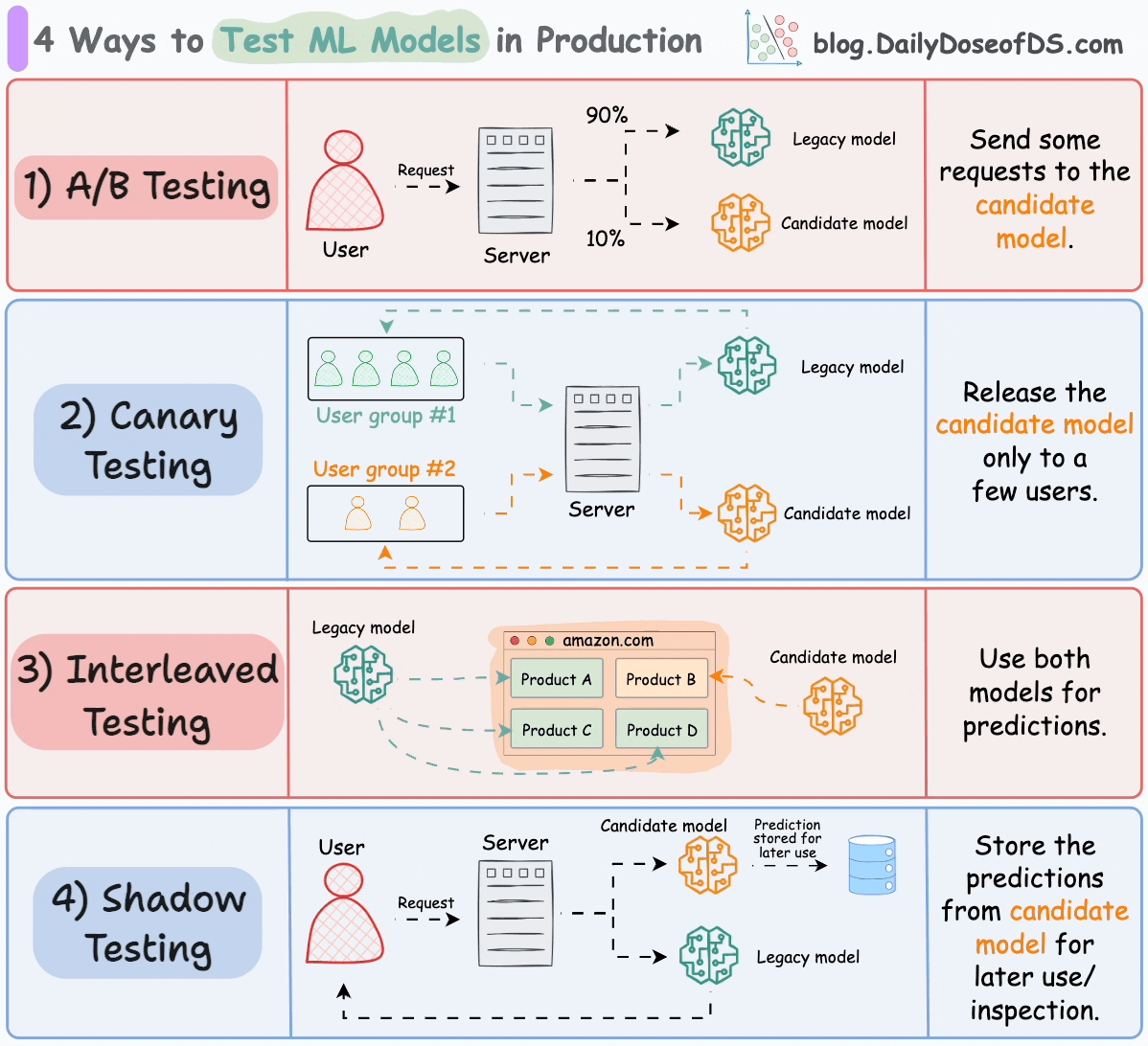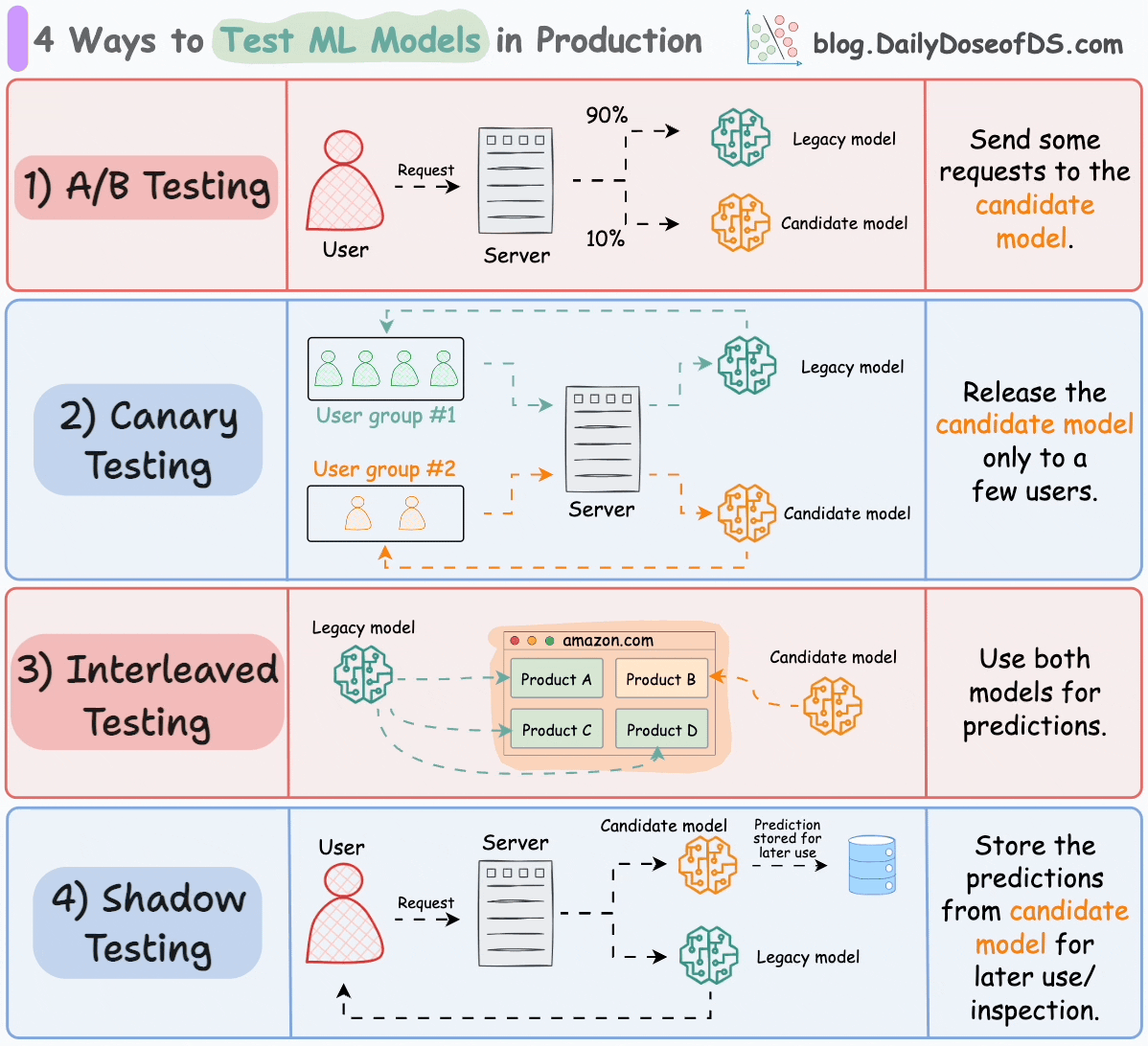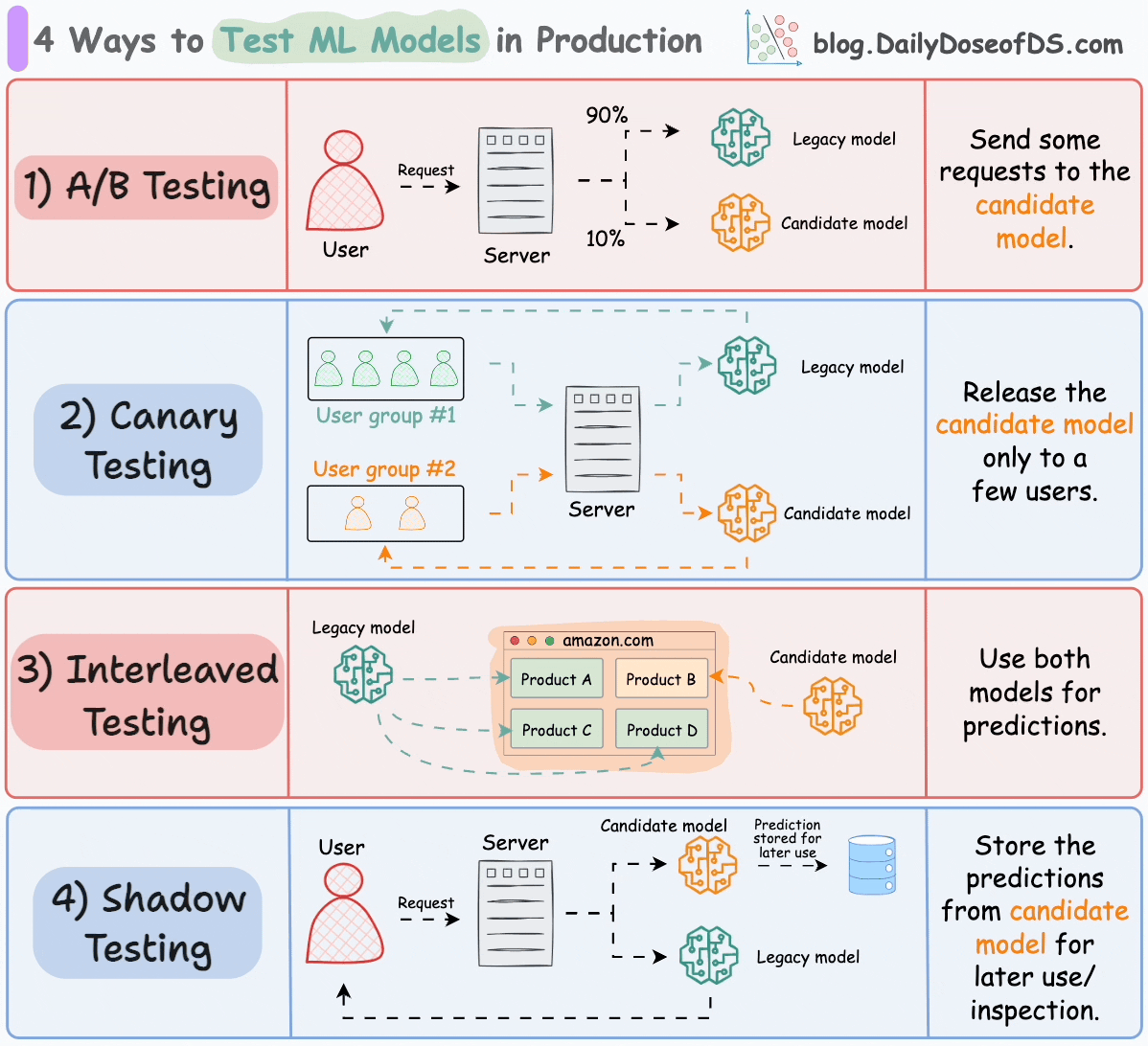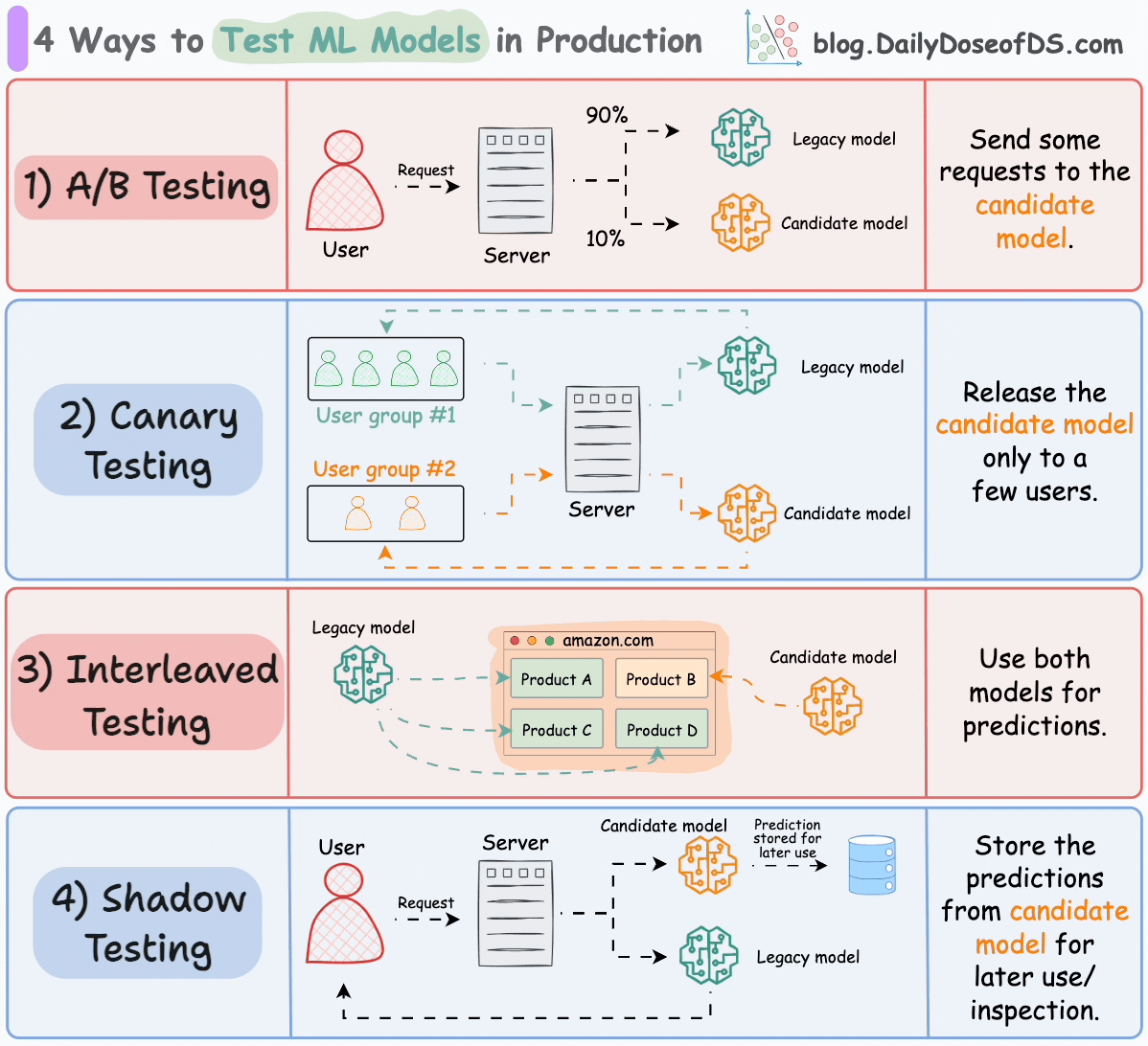
#1) A/B testing
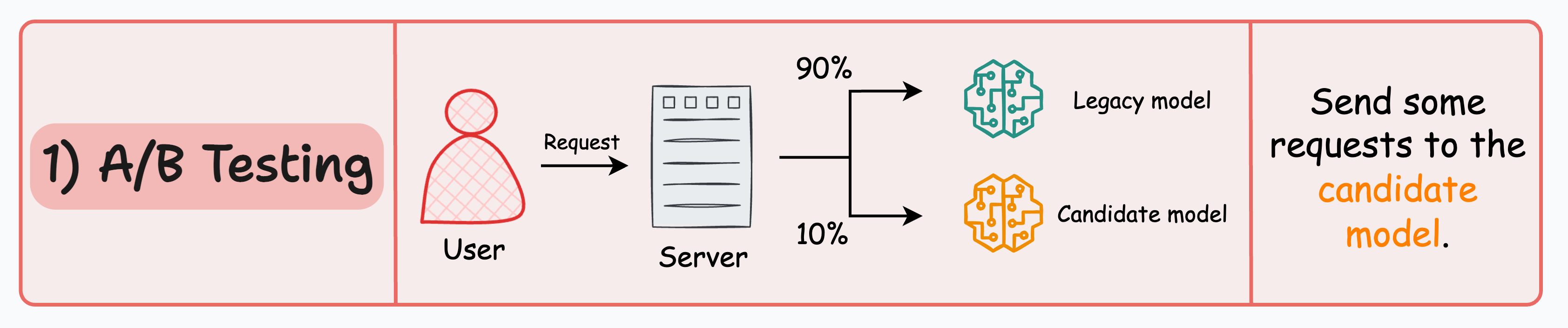
Distribute the incoming requests non-uniformly between the legacy model and the candidate model.
Limit the exposure of the candidate model to avoid any potential risks.
#2) Canary testing
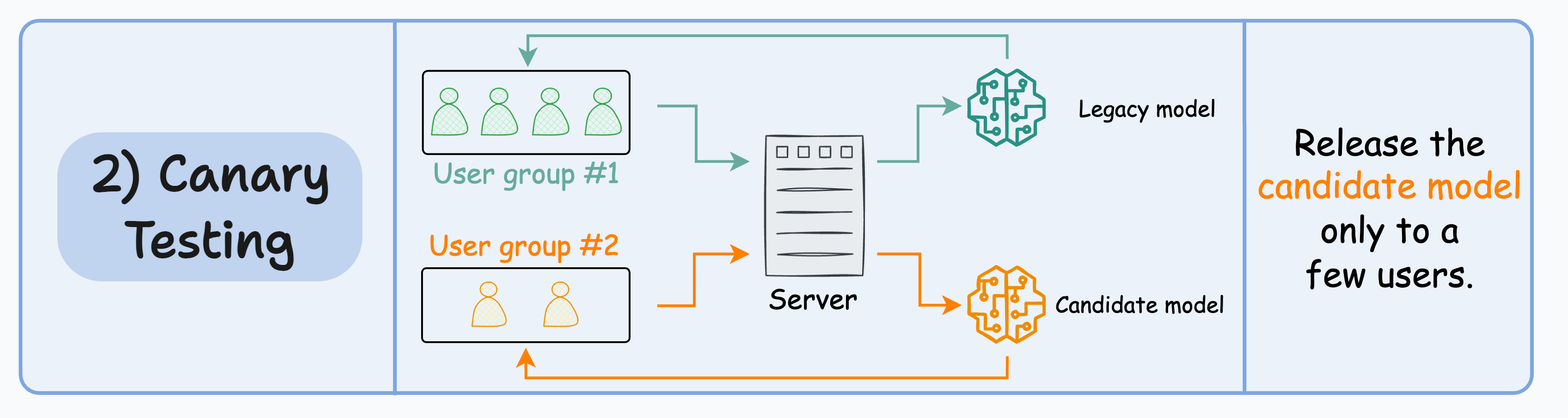
A/B testing may affect all users since it randomly distributes “traffic” to either model (irrespective of the user).
In canary testing, the candidate model is exposed to a small subset of users in production and gradually rolled out to more users.
#3) Interleaved testing

This involves mixing the predictions of multiple models in the response.
Consider Amazon’s recommendation engine. In interleaved deployments, some product recommendations displayed on their homepage can come from the legacy model, while some can be produced by the candidate model.
#4) Shadow testing
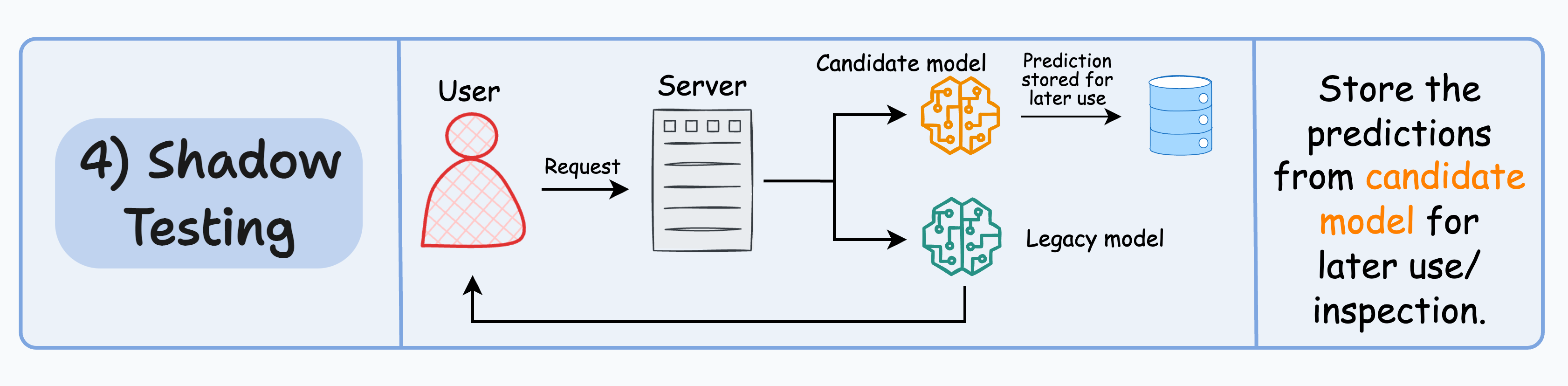
All of the above techniques affect some (or all) users.
Shadow testing (or dark launches) lets us test a new model in a production environment without affecting the user experience.
The candidate model is deployed alongside the existing legacy model and serves requests like the legacy model. However, the output is not sent back to the user. Instead, the output is logged for later use to benchmark its performance against the legacy model.
We explicitly deploy the candidate model instead of testing offline because the exact production environment can be difficult to replicate offline.
Shadow testing offers risk-free testing of the candidate model in a production environment.
That said, don't forget to check out Maxim for Agent testing.
Maxim provides an end-to-end evaluation and observability platform that will help you ship AI agents reliably and >5x faster!
👉 Over to you: What are some ways to test models in production?
Thanks for reading!