
48 Most Popular Open ML Datasets
...summarized in a single frame.

Super Accurate Speech-to-Text for Voice Agents!
Accuracy and speed are everything in real-time voice Agents! AssemblyAI’s latest Universal-Streaming is specifically built for that.
Here’s how to use it:

Super accurate with latency as low as ~300 ms.
Provides unlimited concurrency.
Robust to background noise with ~73% fewer false outputs compared to Deepgram Nova-2 and 28% improvement over Deepgram Nova-3.
Start building with Universal-Streaming here →
Thanks to AssemblyAI for partnering today!
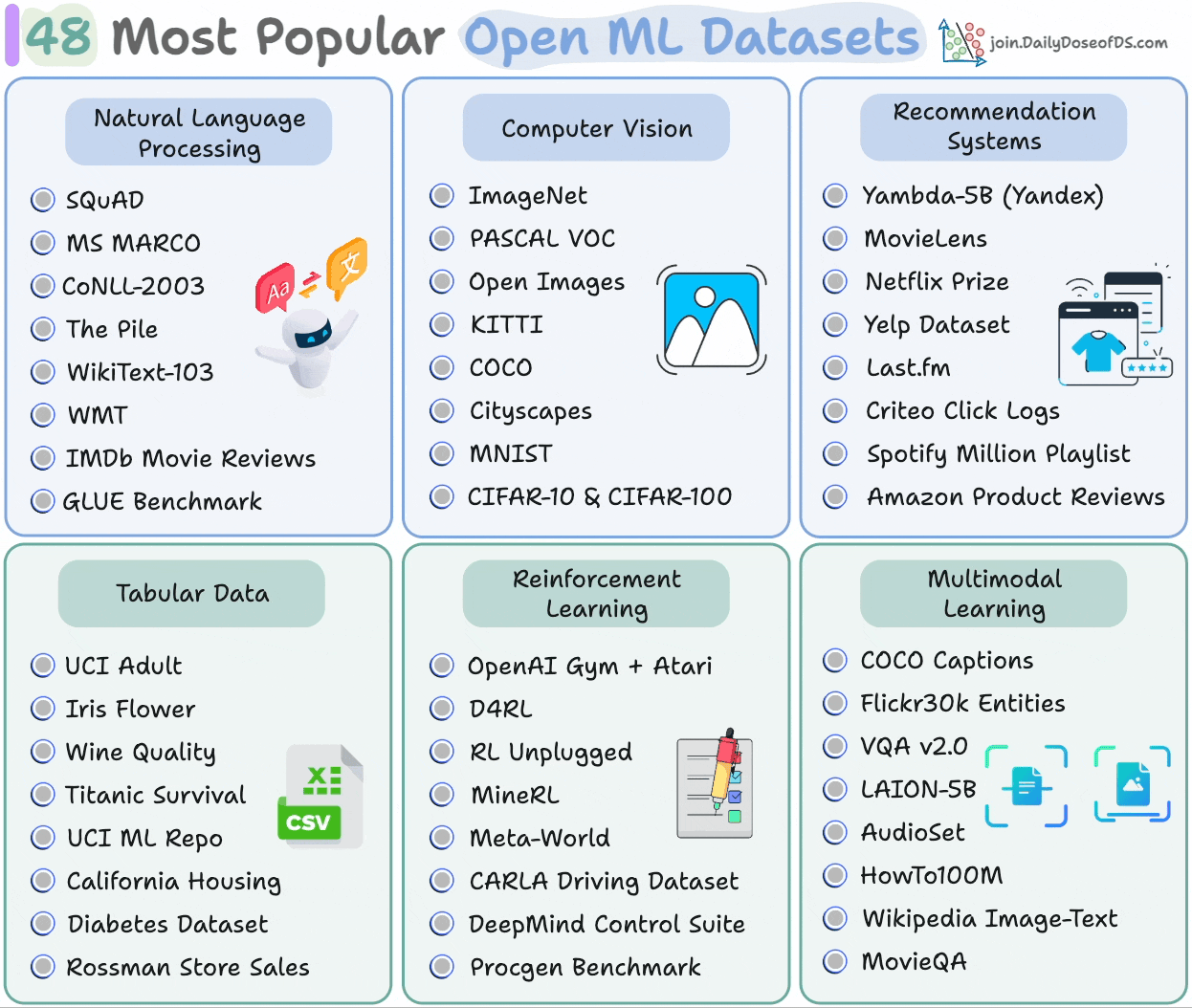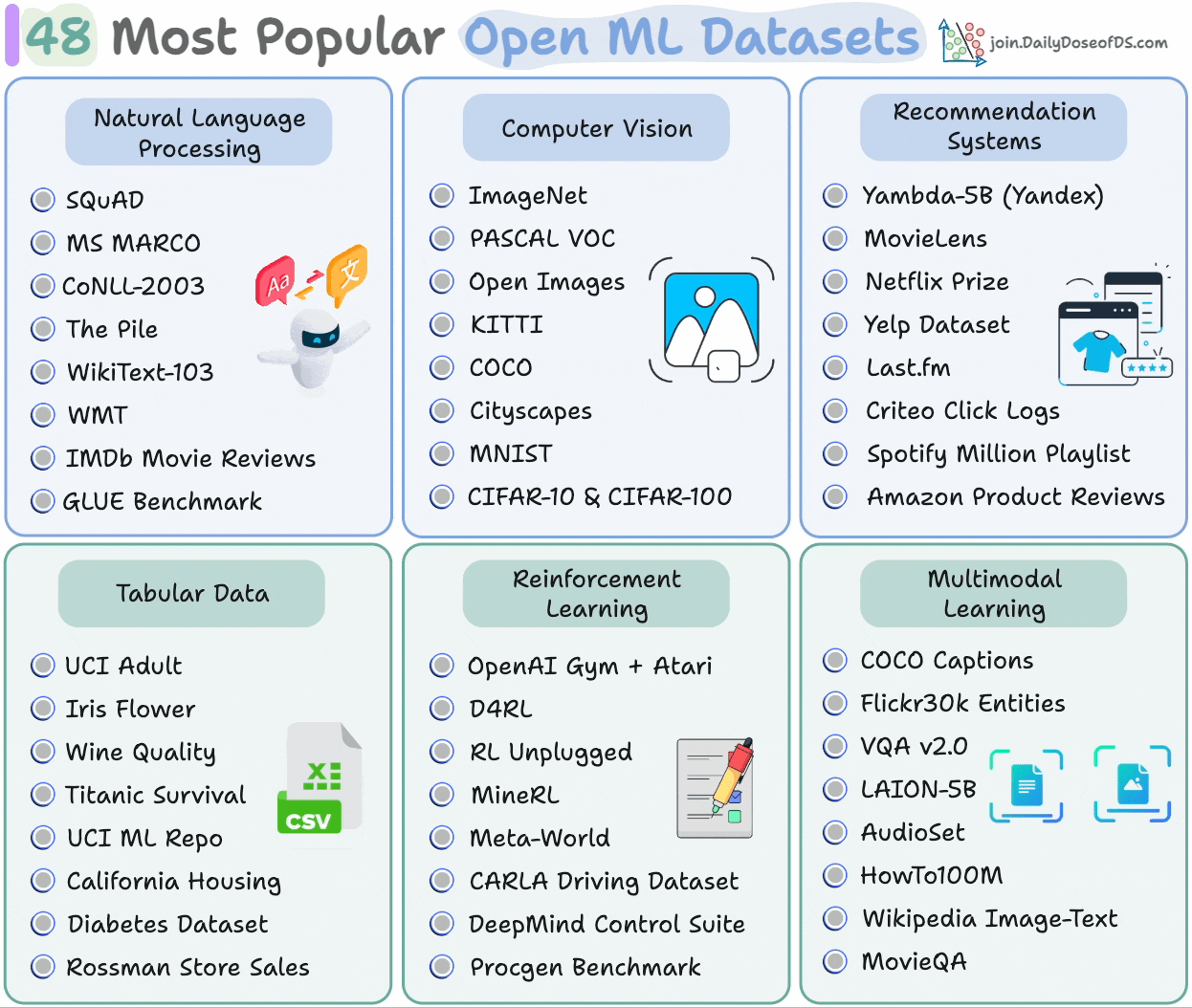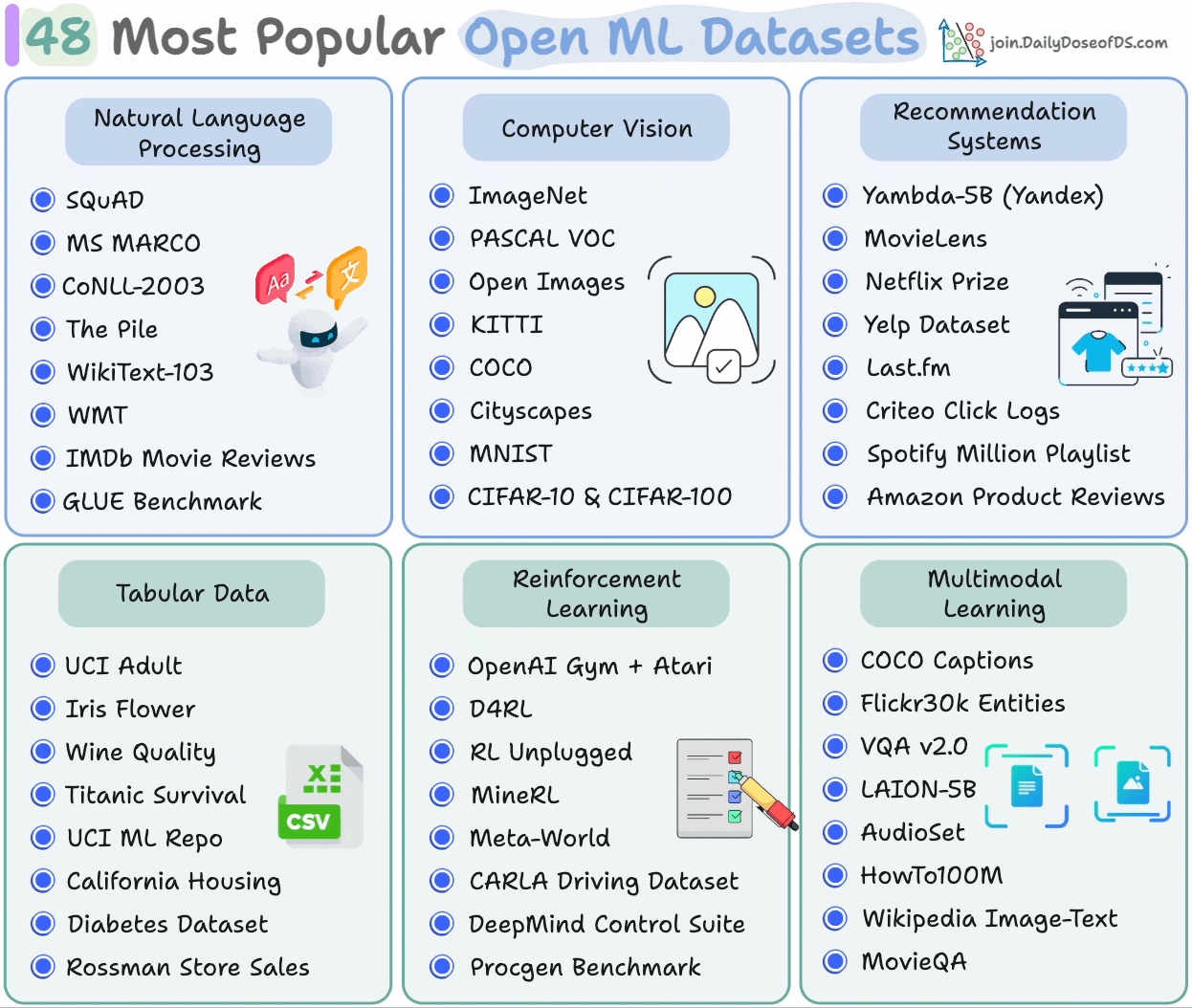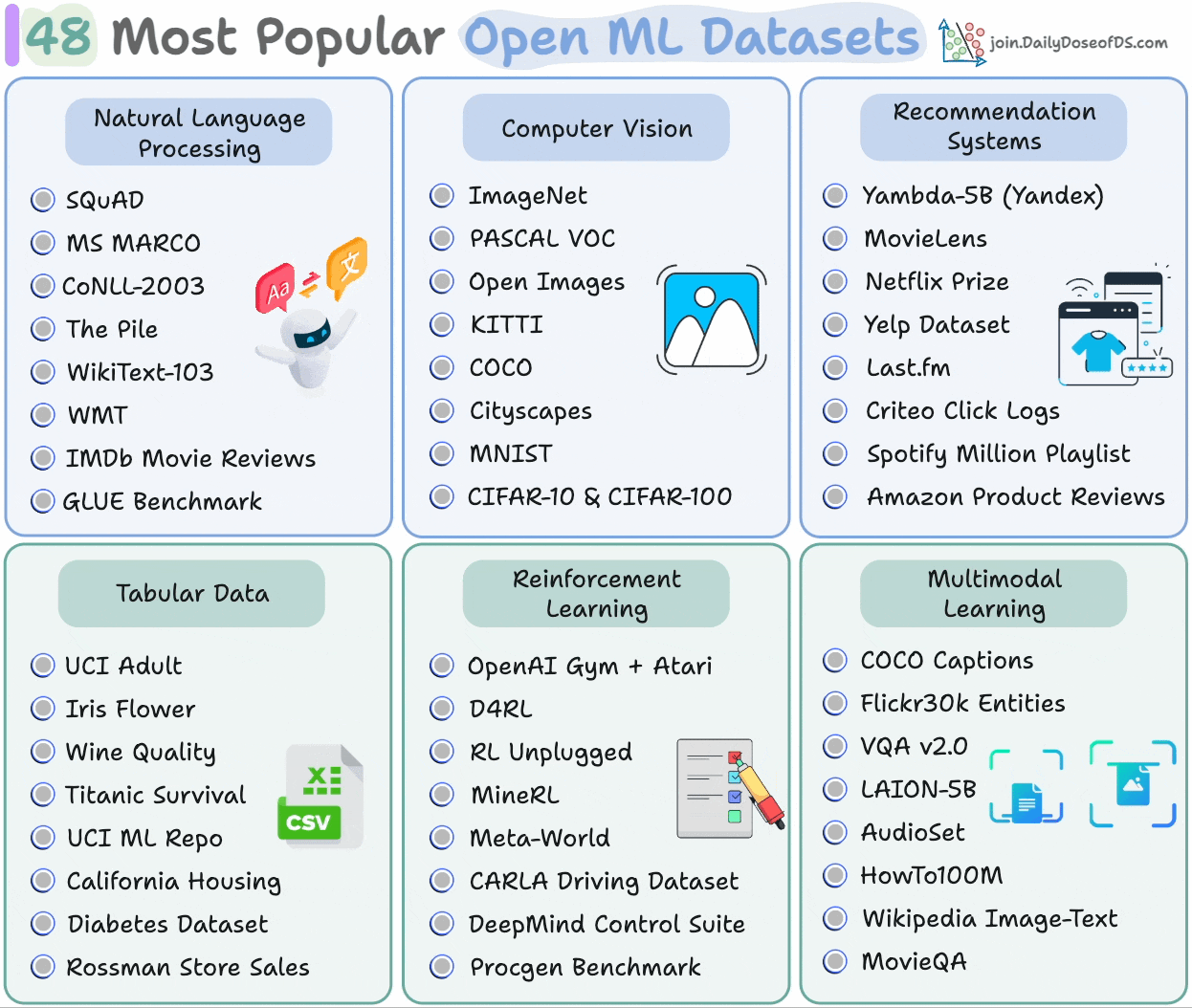
48 most popular open ML datasets
We created a visual that showcases 48 of the most widely used open ML datasets, neatly grouped by domain—covering vision, NLP, recommendation systems, reinforcement learning, and more.
While open-source models and frameworks are getting a lot of attention, it's easy to forget that most progress in ML still starts with data.
For instance, there haven’t been truly large-scale, public datasets for recommendations, despite several platforms generating billions of interactions daily. Most of this data remains locked behind proprietary systems.
Just last week, Yambda-5B solved this by releasing the largest open dataset for recommendation systems, containing 4.79 billion user–item interactions across 1 million users and 9.39 million tracks.
Here's a quick look at some of the most popular datasets:
Natural Language Processing:

SQuAD: QA dataset built from Wikipedia with span-based answers.
MS MARCO: Real-world search queries paired with passages.
CoNLL-2003: NER dataset with newswire articles.
The Pile: A massive 825GB open-source text corpus from EleutherAI.
WikiText-103: Long-form Wikipedia articles for language modeling.
WMT: Standard for machine translation benchmarks.
IMDb Reviews: Sentiment classification dataset of 50k reviews.
GLUE Benchmark: Evaluation benchmark across 9 NLU tasks.
Computer vision:

ImageNet: The dataset that sparked the deep learning boom in vision.
PASCAL VOC: Detection, segmentation, and classification.
Open Images: 9M images with bounding boxes and labels.
KITTI: Self-driving car dataset with stereo, LiDAR, and detection tasks.
COCO: Rich object segmentation and captioning dataset.
Cityscapes: Pixel-level segmentation for urban scenes.
MNIST: Classic handwritten digits dataset.
CIFAR-10 & CIFAR-100: Tiny image classification datasets.
Recommendation systems:

Yambda-5B (Yandex): A 4.79B multimodal interactions with audio embeddings and organic vs recommended flags. The dataset uses a global temporal split for evaluation, which, unlike Leave-One-Out, does not break temporal dependencies. This mimics a realistic model testing.
MovieLens: Ratings and tags across multiple sizes (100k to 25M).
Netflix Prize: The iconic 100M rating dataset from Netflix’s public competition.
Yelp Dataset: Local business reviews with metadata and social network features.
Last.fm (LFM-1B): 1B music listening events with timestamps and track metadata.
Criteo 1TB: Massive click-through dataset for ads.
Spotify Million Playlist: User-generated music playlists for sequential recommendation.
Amazon Reviews: 200M+ product reviews across multiple years and domains.
Tabular data:

UCI Adult: Census income classification task.
Iris Flower: The classic 3-class flower dataset.
Wine Quality: Red/white wine data for regression and classification.
Titanic: Predict passenger survival.
UCI ML Repo: Classic collection of 500+ datasets.
California Housing: Predict median house prices.
Diabetes Dataset: Medical regression benchmark.
Rossmann Sales: Time series forecasting with store and promotion metadata.
Reinforcement learning:

OpenAI Gym + Atari: RL environments with discrete and continuous action spaces.
D4RL: Offline RL benchmarks with logged trajectories from MuJoCo, AntMaze, and others.
RL Unplugged: DeepMind’s offline RL datasets from Control Suite and Atari.
MineRL: Minecraft demonstration dataset for sample-efficient RL.
Meta-World: 50+ robot manipulation tasks.
CARLA: Autonomous driving simulator.
DeepMind Control Suite: Continuous control physics tasks.
Procgen Benchmark: Procedurally generated RL games for generalization.
Multimodal learning:

COCO Captions: 1.5M human-written captions for 300k images.
Flickr30k Entities: Phrase-region mappings in image captions.
VQA v2.0: Visual question answering over images.
LAION-5B: Web-scale image–text pairs used to train models like CLIP and Stable Diffusion.
AudioSet: Audio clips labeled with events (e.g. dog barking, piano).
HowTo100M: Video-text pairs from instructional YouTube videos.
Wikipedia Image-Text (WIT): 37M image–text pairs scraped from Wikipedia.
MovieQA: QA based on video subtitles, plots, and visual content.
That’s a wrap!
We hope this landscape gives you a clearer picture of what’s available.
If there’s a dataset you use and love that didn’t make the list, reply and let us know—we’d love to feature it in a follow-up.
Thanks for reading!