
5 Chunking Strategies For RAG
...explained in a single frame.

Linkup Achieves SOTA Performance on SimpleQA

Linkup search achieved 91% F-Score on OpenAI's SimpleQA benchmark, outperforming Perplexity.
This establishes Linkup as the best search API for AI:
Delivers more accurate, relevant results.
Surfaces the latest information at lightning speed.
Integrate natively with high-quality data sources.
Start building with Linkup web search today →
Thanks to Linkup for partnering with us today!
5 Chunking Strategies For RAG
Here’s the typical workflow of RAG:
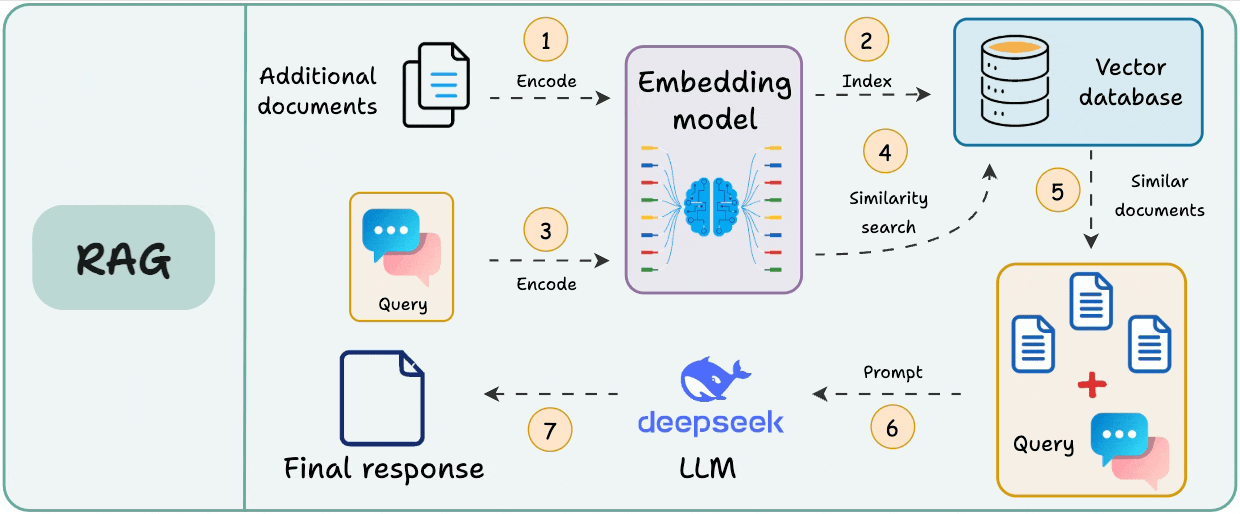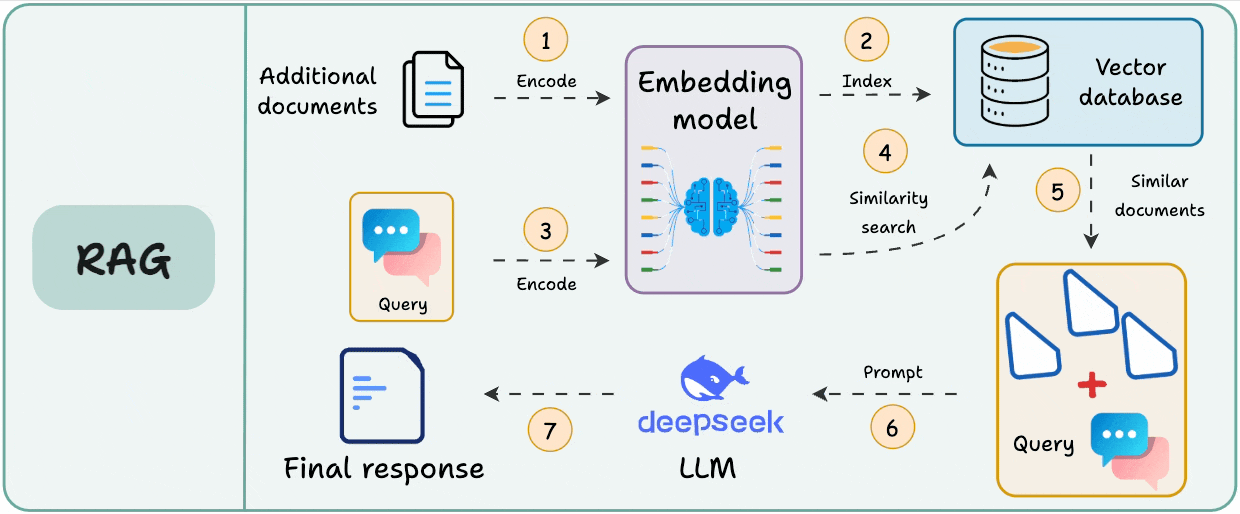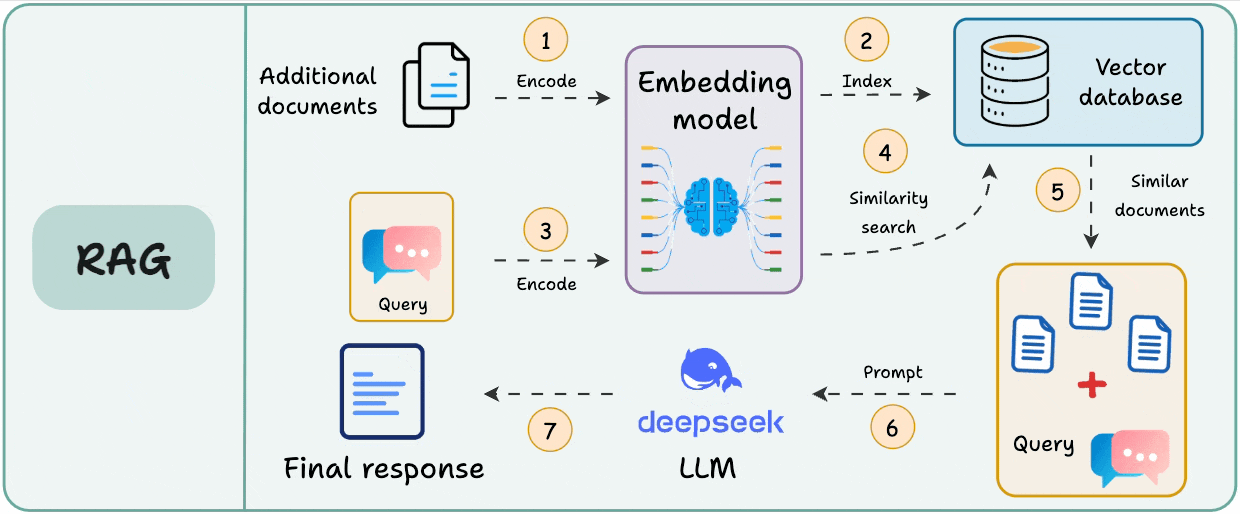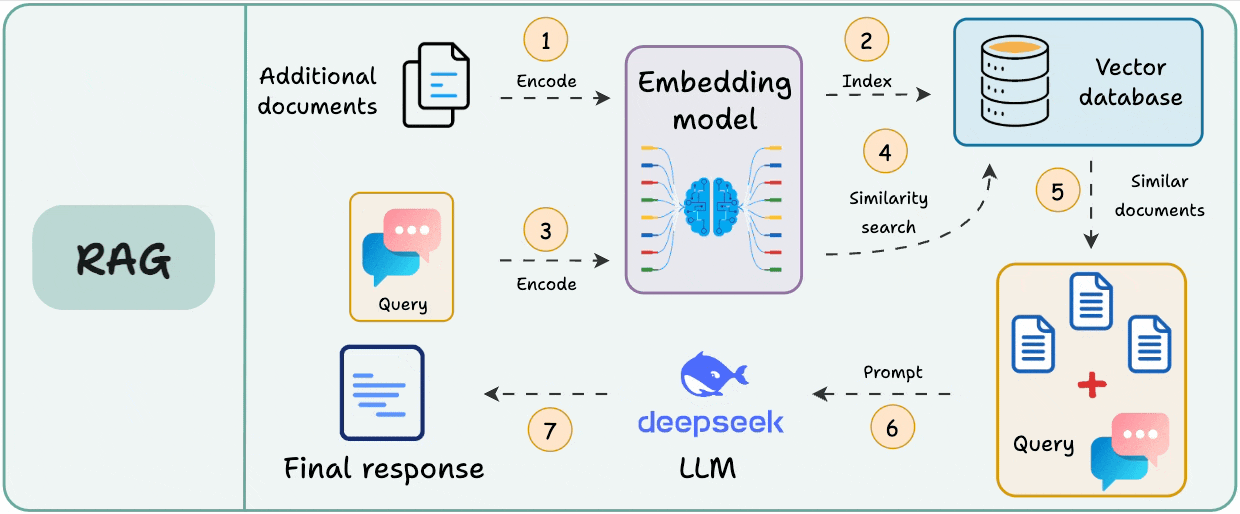
Since the additional document(s) can be large, step 1 also involves chunking, wherein a large document is divided into smaller/manageable pieces.
This step is crucial since it ensures the text fits the input size of the embedding model.
Here are five chunking strategies for RAG:
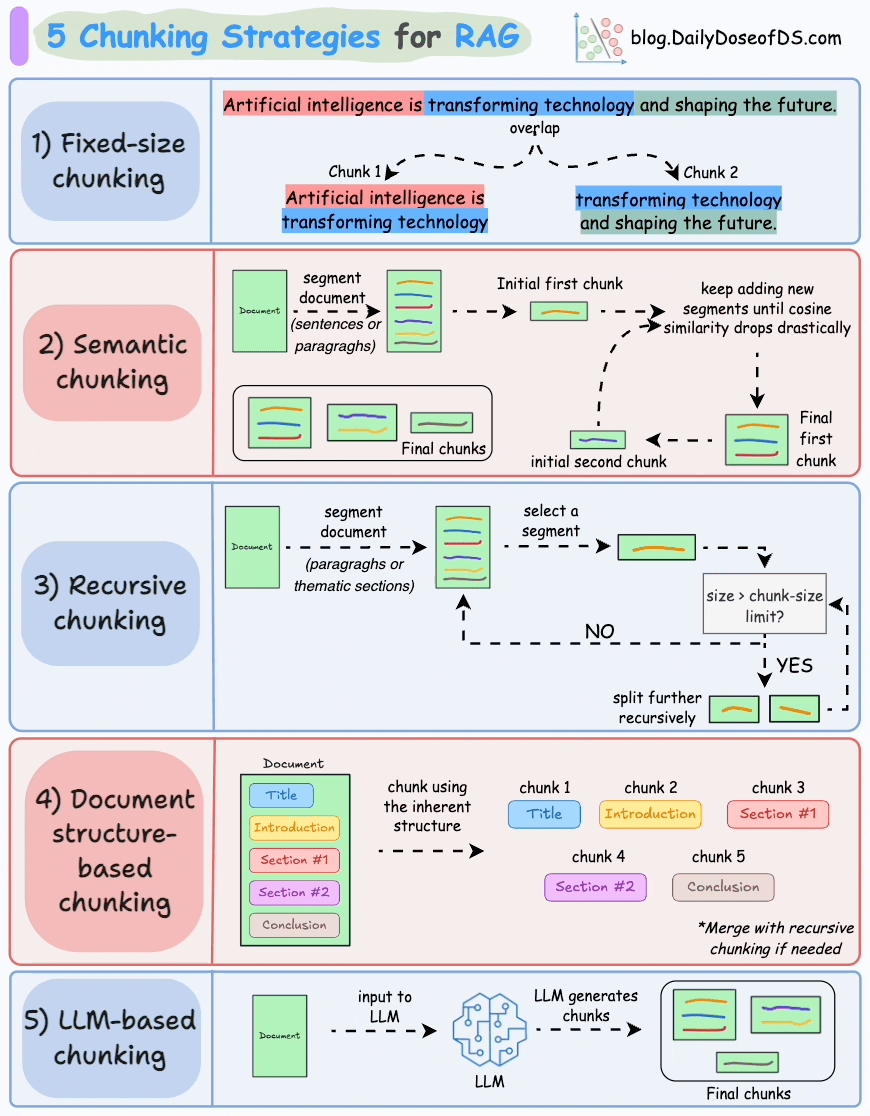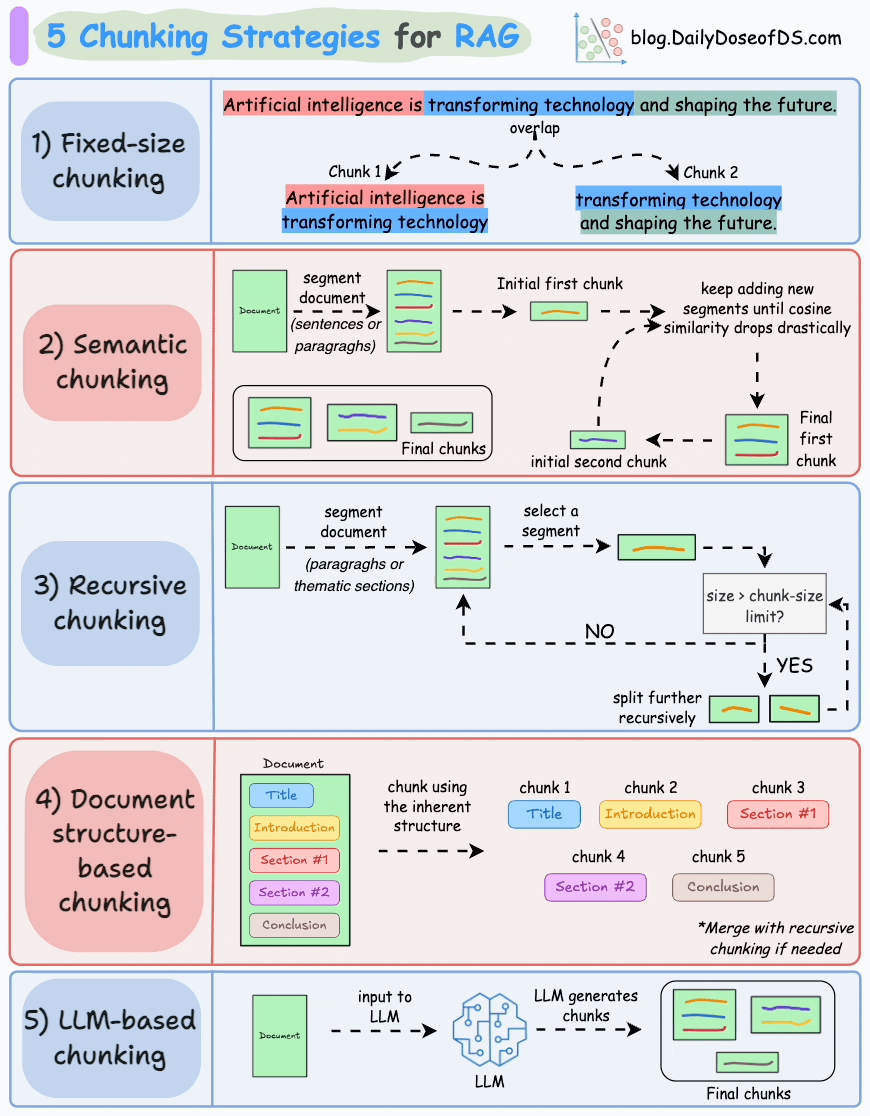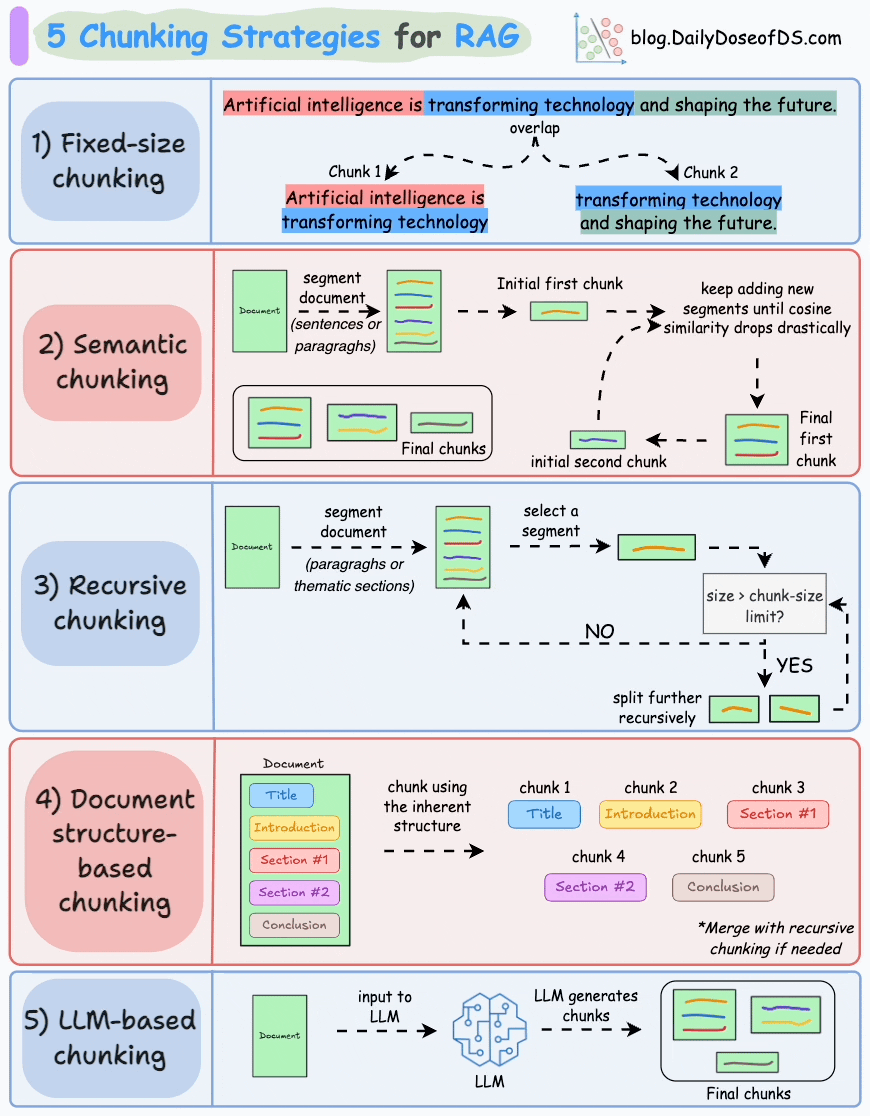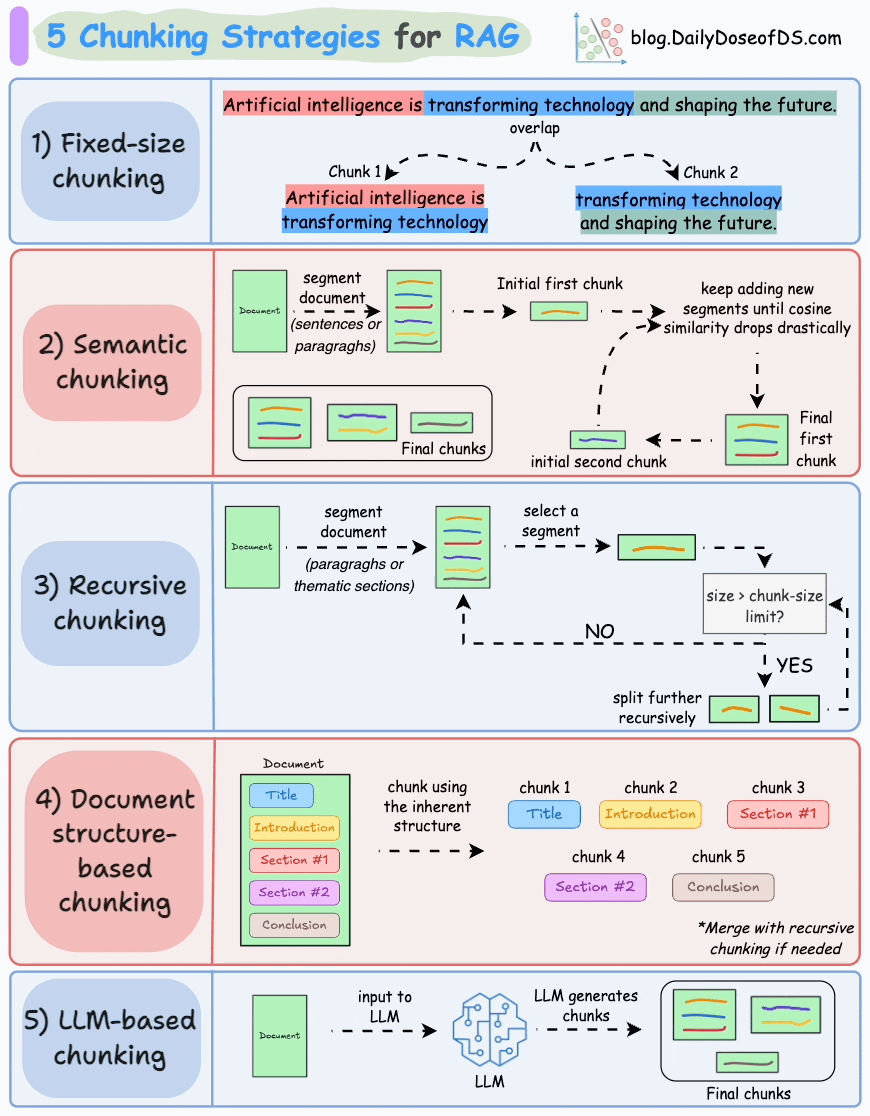
Let’s understand them today!
If you want to dive into building LLM apps, our full RAG crash course discusses RAG from basics to beyond:
1) Fixed-size chunking
Split the text into uniform segments based on a pre-defined number of characters, words, or tokens.
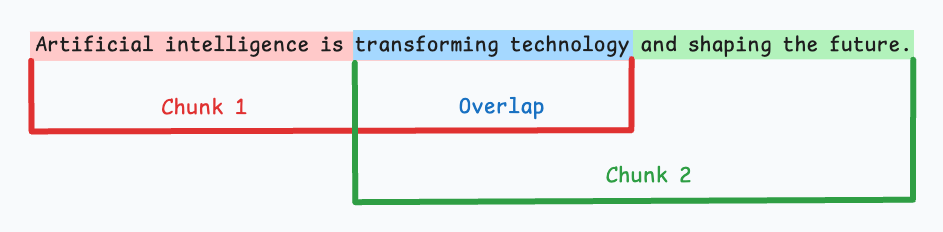
Since a direct split can disrupt the semantic flow, it is recommended to maintain some overlap between two consecutive chunks (the blue part above).
This is simple to implement. Also, since all chunks are of equal size, it simplifies batch processing.
But this usually breaks sentences (or ideas) in between. Thus, important information will likely get distributed between chunks.
2) Semantic chunking
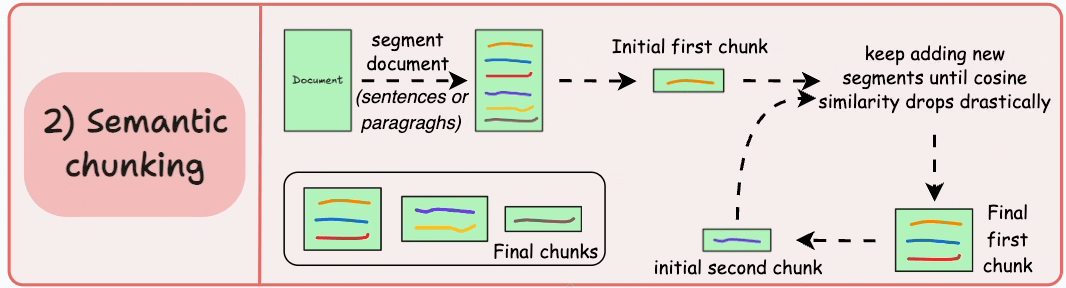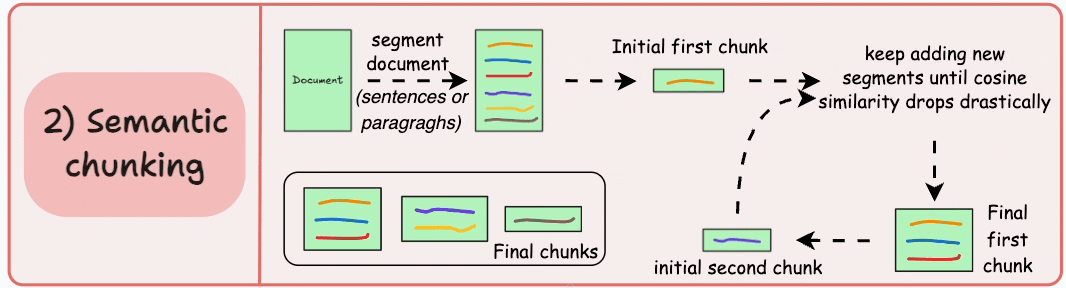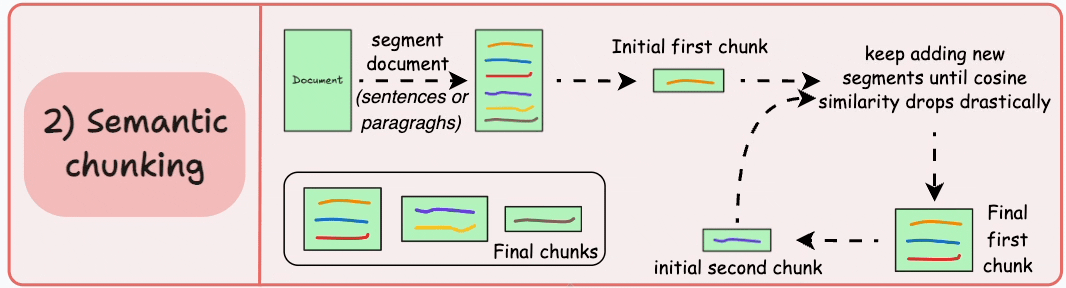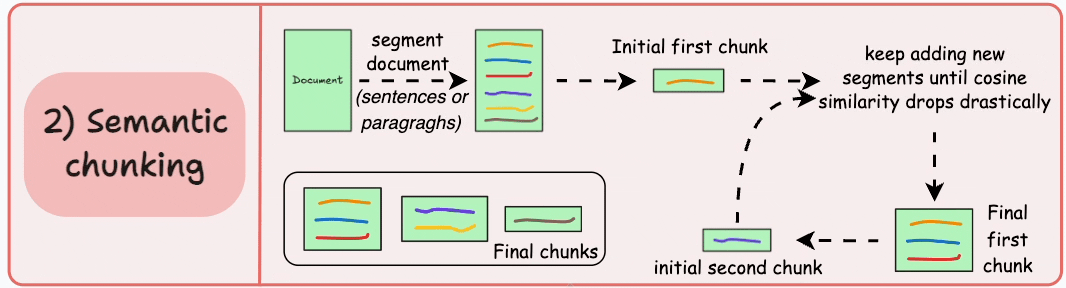
Segment the document based on meaningful units like sentences, paragraphs, or thematic sections.
Next, create embeddings for each segment.
Let’s say we start with the first segment and its embedding.
If the first segment’s embedding has a high cosine similarity with that of the second segment, both segments form a chunk.
This continues until cosine similarity drops significantly.
The moment it does, we start a new chunk and repeat.
Here’s what the output could look like:

Unlike fixed-size chunks, this maintains the natural flow of language and preserves complete ideas.
Since each chunk is richer, it improves the retrieval accuracy, which, in turn, produces more coherent and relevant responses by the LLM.
A minor problem is that it depends on a threshold to determine if cosine similarity has dropped significantly, which can vary from document to document.
3) Recursive chunking
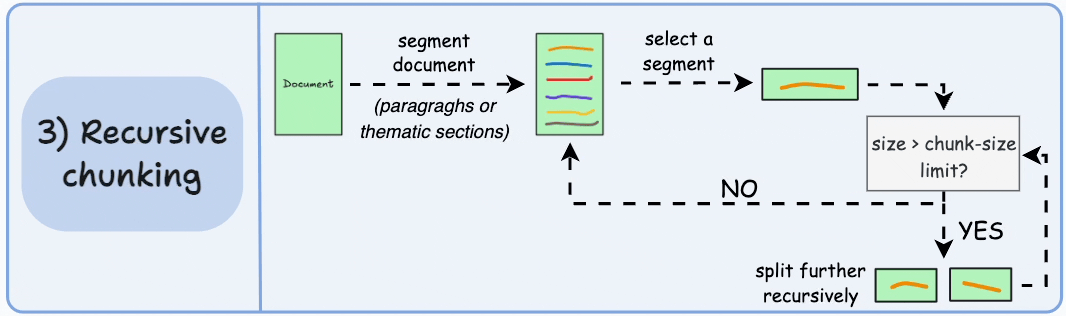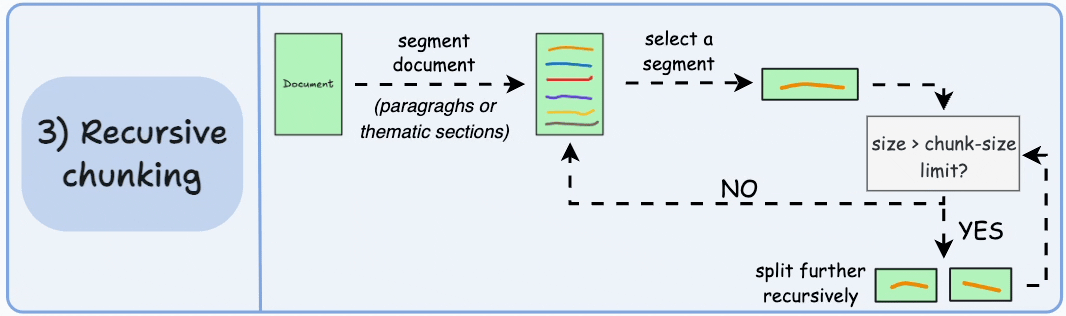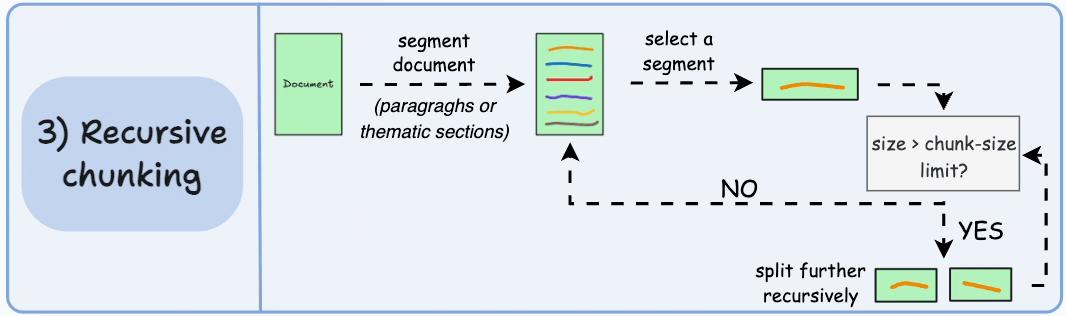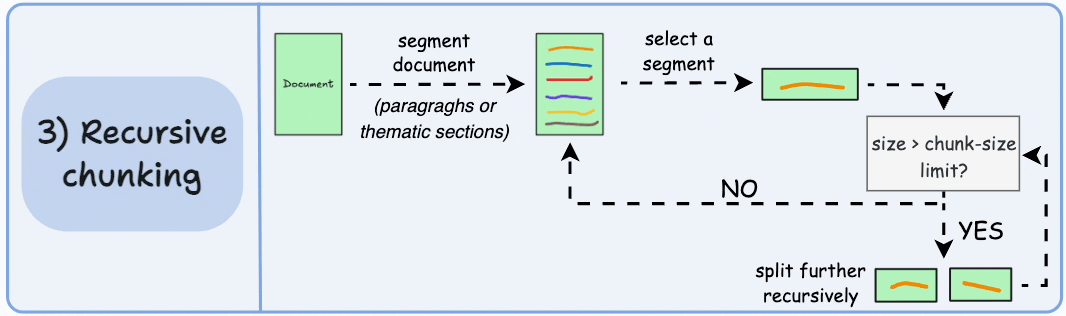
First, chunk based on inherent separators like paragraphs, or sections.
Next, split each chunk into smaller chunks if the size exceeds a pre-defined chunk size limit. If, however, the chunk fits the chunk-size limit, no further splitting is done.
Here’s what the output could look like:

As shown above:
First, we define two chunks (the two paragraphs in purple).
Next, paragraph 1 is further split into smaller chunks.
Unlike fixed-size chunks, this approach also maintains the natural flow of language and preserves complete ideas.
However, there is some extra overhead in terms of implementation and computational complexity.
4) Document structure-based chunking
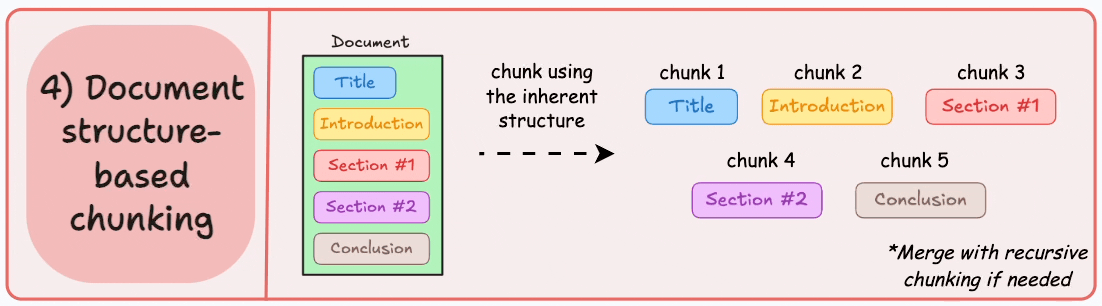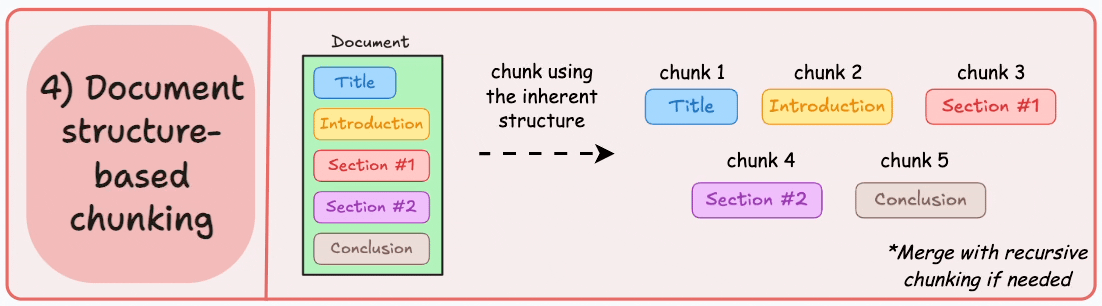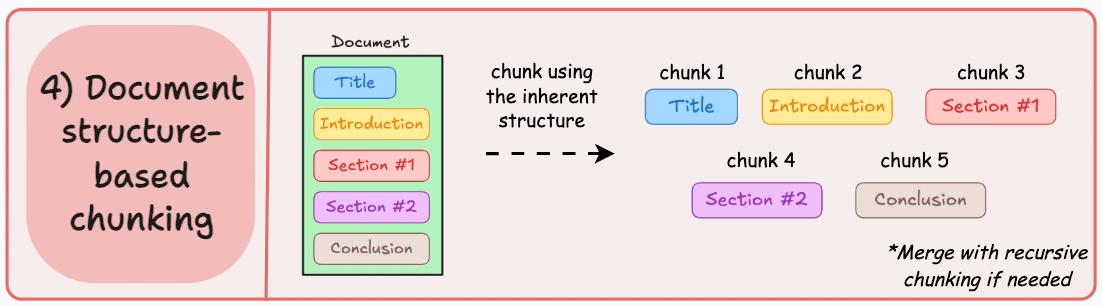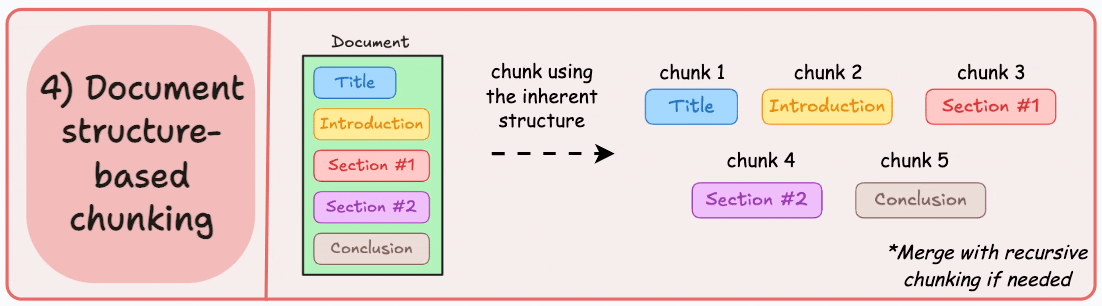
It utilizes the inherent structure of documents, like headings, sections, or paragraphs, to define chunk boundaries. This way, it maintains structural integrity by aligning with the document’s logical sections.
Here’s what the output could look like:

That said, this approach assumes that the document has a clear structure, which may not be true.
Also, chunks may vary in length, possibly exceeding model token limits. You can try merging it with recursive splitting.
5) LLM-based chunking

Prompt the LLM to generate semantically isolated and meaningful chunks.
This method ensures high semantic accuracy since the LLM can understand context and meaning beyond simple heuristics (used in the above four approaches).
But this is the most computationally demanding chunking technique of all five techniques discussed here.
Also, since LLMs typically have a limited context window, that is something to be taken care of.
Each technique has its own advantages and trade-offs.
We have observed that semantic chunking works pretty well in many cases, but again, you need to test.
The choice will depend on the nature of your content, the capabilities of the embedding model, computational resources, etc.
If you want to dive into building LLM apps, our full RAG crash course discusses RAG from basics to beyond:
👉 Over to you: What other chunking strategies do you know?
Thanks for reading!