
5 Cross Validation Techniques Explained Visually
A 2-min visual guide to popular cross validation techniques.

Tuning and validating machine learning models on a single validation set can be misleading and sometimes yield overly optimistic results.
This can occur due to a lucky random split of data, which results in a model that performs exceptionally well on the validation set but poorly on new, unseen data.

That is why we often use cross validation instead of simple single-set validation.
Cross validation involves repeatedly partitioning the available data into subsets, training the model on a few subsets, and validating on the remaining subsets.
The main advantage of cross validation is that it provides a more robust and unbiased estimate of model performance compared to the traditional validation method.
Below are five of the most commonly used and must-know cross validation techniques.
Leave-One-Out Cross Validation

Leave one data point for validation.
Train the model on the remaining data points.
Repeat for all points.
Of course, as you may have guessed, this is practically infeasible when you have many data points. This is because number of models is equal to number of data points.
We can extend this to Leave-p-Out Cross Validation, where, in each iteration,
pobservations are reserved for validation, and the rest are used for training.
K-Fold Cross Validation
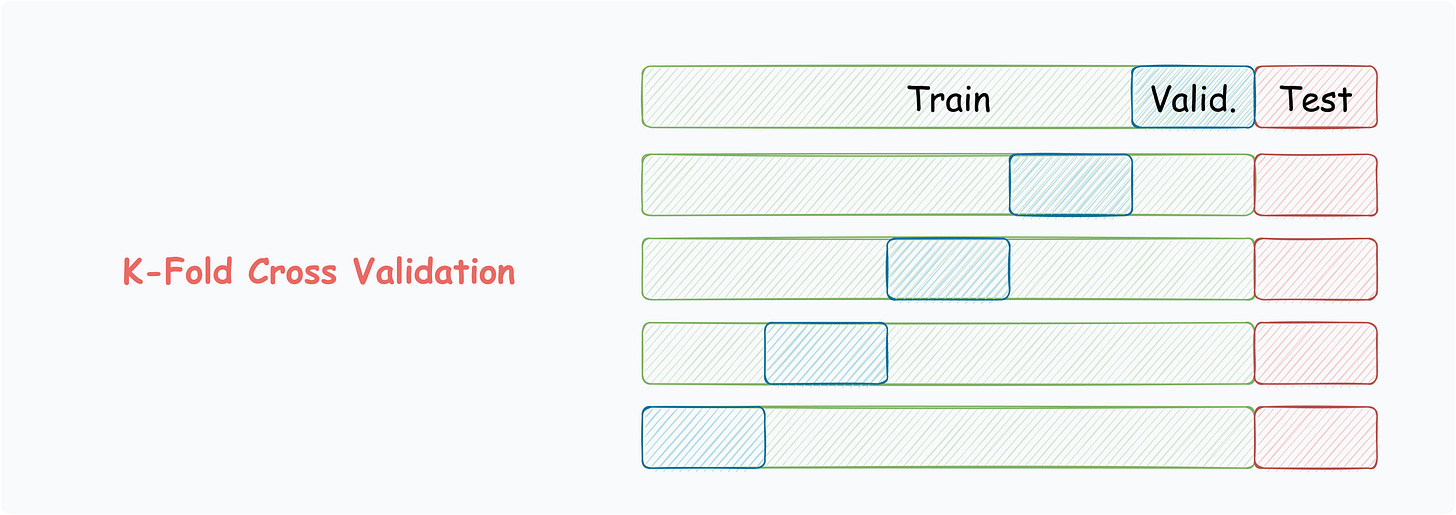
Split data into k equally-sized subsets.
Select one subset for validation.
Train the model on the remaining subsets.
Repeat for all subsets.
Rolling Cross Validation
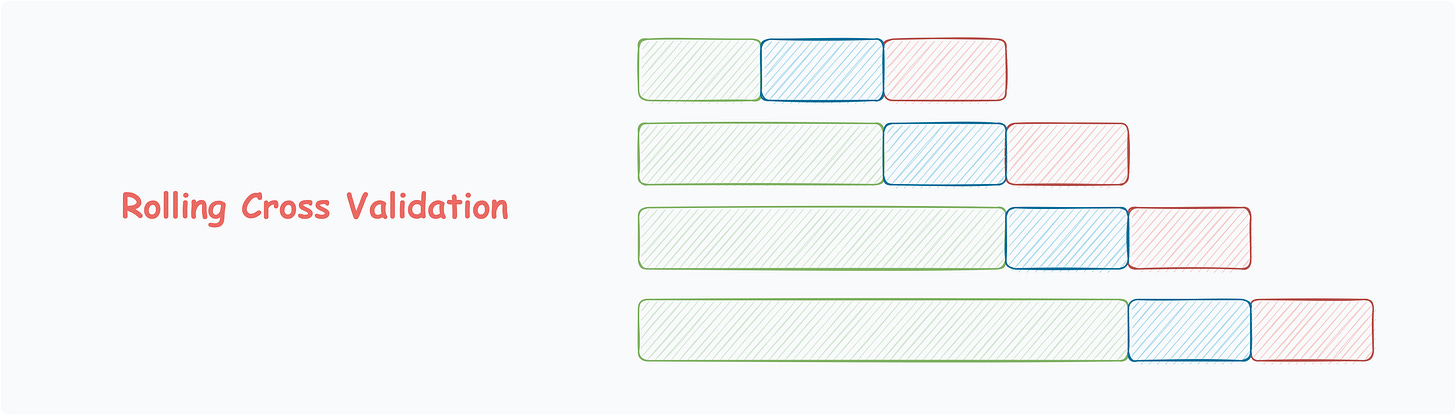
Mostly used for data with temporal structure.
Data splitting respects the temporal order, using a fixed-size training window.
The model is evaluated on the subsequent window.
Blocked Cross Validation
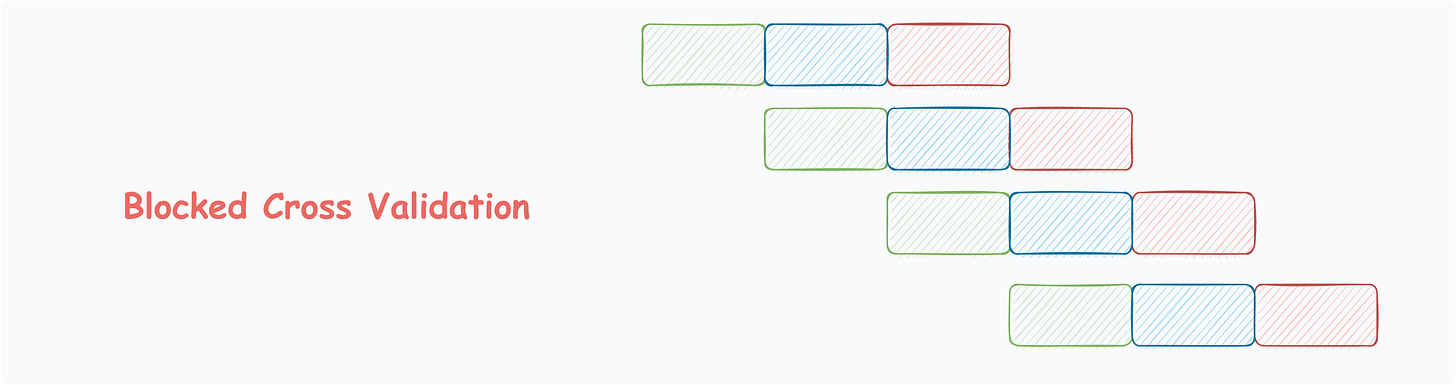
Another common technique for time-series data.
In contrast to rolling cross validation, the slice of data is intentionally kept short if the variance does not change appreciably from one window to the next.
This also saves computation over rolling cross validation.
Stratified Cross Validation
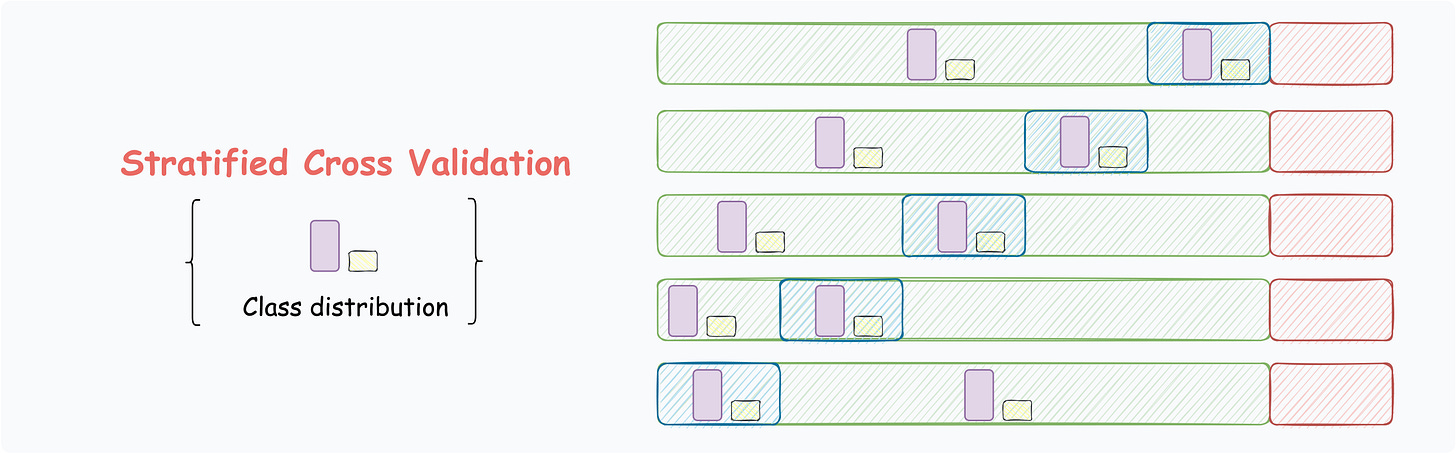
The above-discussed techniques may not work for imbalanced datasets. Stratified cross validation is mainly used for preserving the class distribution.
The partitioning ensures that the class distribution is preserved.

👉 Over to you: What other cross validation techniques have I missed?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 80,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Hi Avi, can you cover nested cross validation in one of your deep dives or articles? Thanks..