
5 LLM Fine-tuning Techniques
...explained visually.

Build Full-stack AI Agents with CopilotKit [open-source]

Today, we have several reliable tools to create decent agentic workflows. Yet, the main challenge is transitioning them from local setups to user-facing apps.
Here are some key factors to consider:
How do you embed a seamless UI?
How do you enable user control when necessary?
How do you unify the agent’s state and actions with the app?
CoAgents by CopilotKit is solving this by providing all the essential building blocks for full-stack agentic apps.
The latest updates to CoAgents include:
Human-in-the-loop: Real-time human approvals.
LangGraph integration: Supports LG Studio, Platform, and self-hosted.
Agentic UI: Agents generate UI components dynamically.
Predictive state updates: Preview upcoming changes.
Enhanced documentation: Clear, step-by-step guidance.
Thanks to CopilotKit for partnering on today's post and showing what's possible with their powerful Agent-integration framework.
Fine-tuning LLMs
Traditional fine-tuning (depicted below) is infeasible with LLMs because these models have billions of parameters and are hundreds of GBs in size, and not everyone has access to such computing infrastructure.

Thankfully, today, we have many optimal ways to fine-tune LLMs, and five such popular techniques are depicted below:
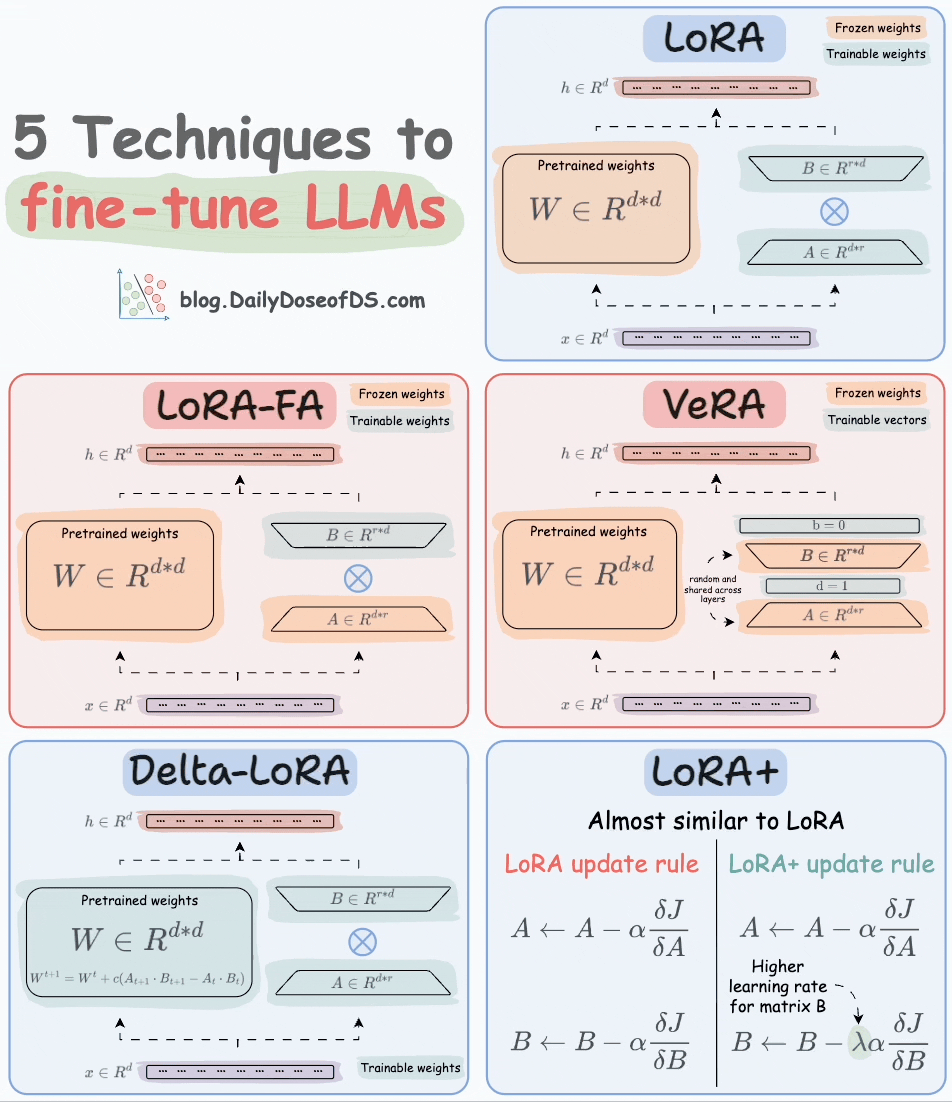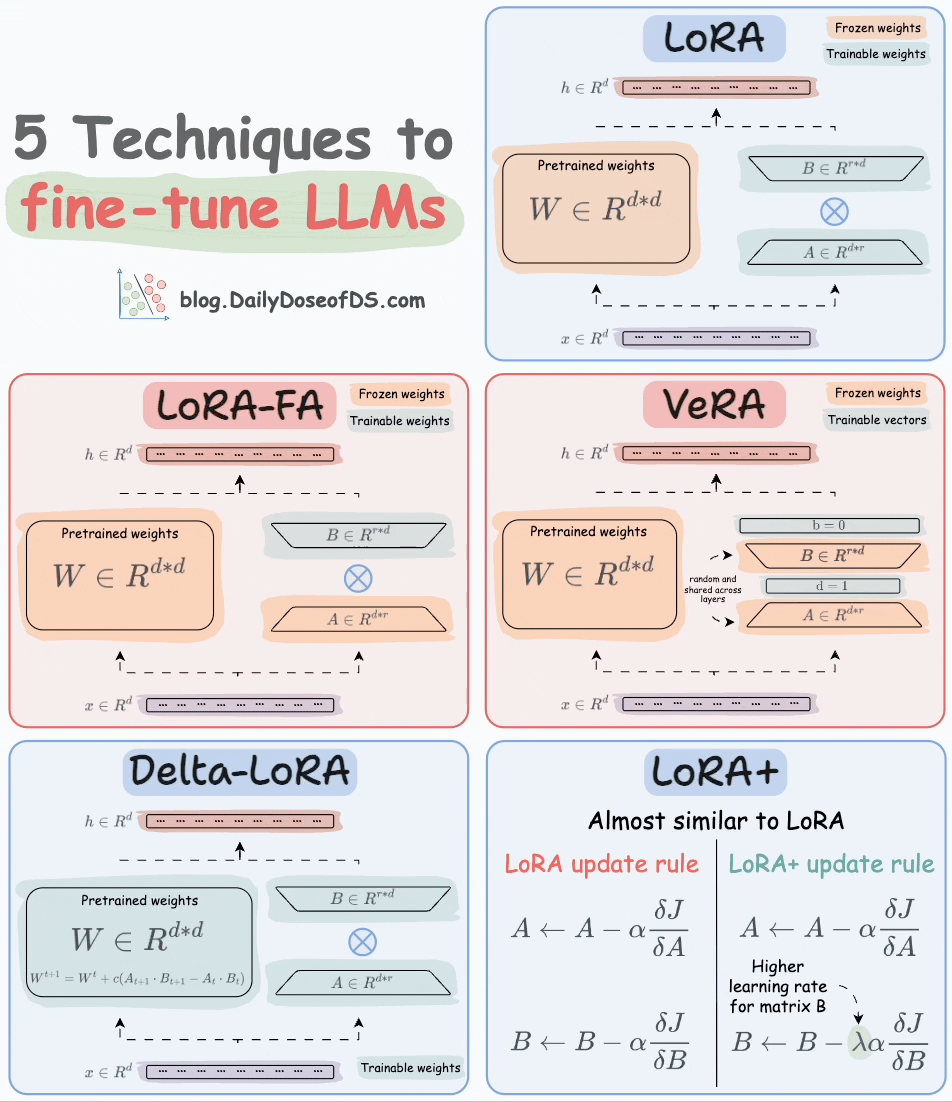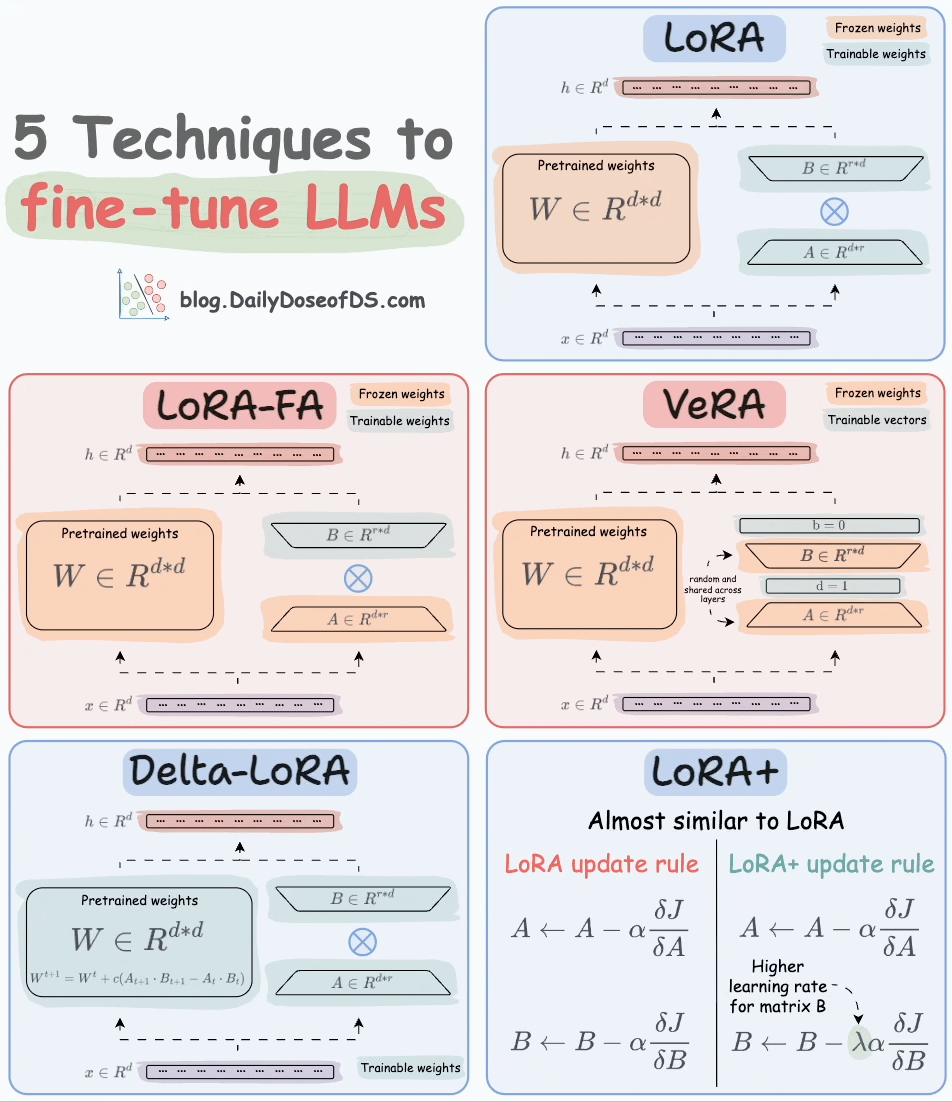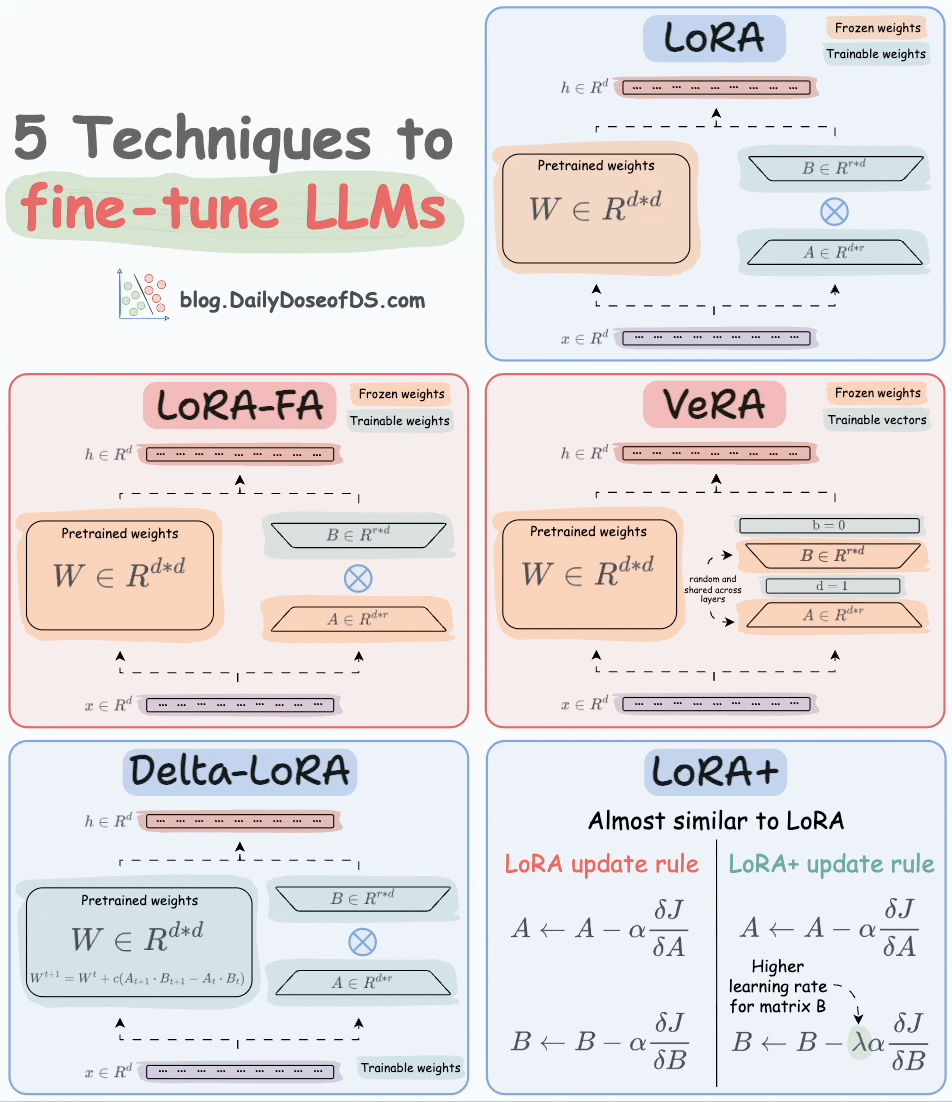
We covered them in detail here:
Here’s a brief explanation:
LoRA: Add two low-rank matrices
AandBalongside weight matrices, which contain the trainable parameters. Instead of fine-tuningW, adjust the updates in these low-rank matrices.

LoRA-FA: While LoRA considerably decreases the total trainable parameters, it still requires substantial activation memory to update the low-rank weights. LoRA-FA (FA stands for Frozen-A) freezes the matrix
Aand only updates matrixB.

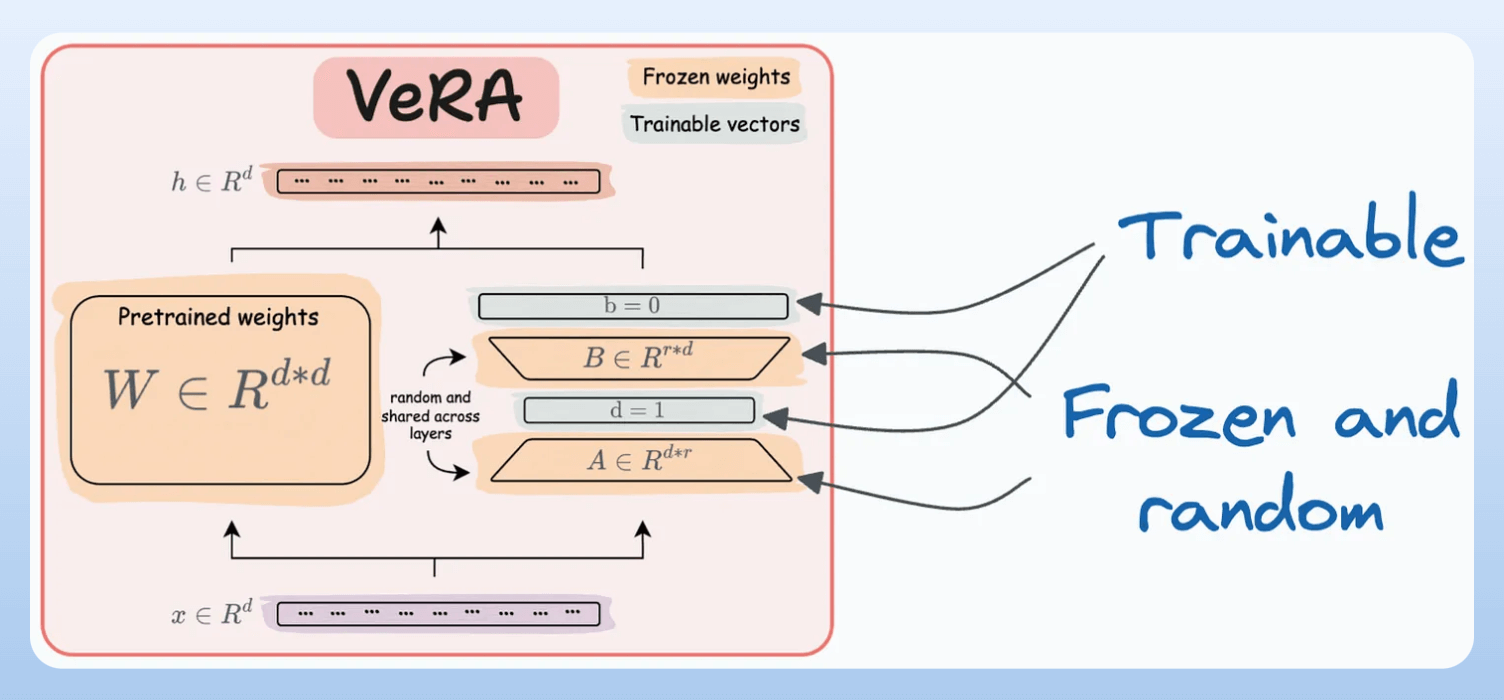
VeRA: In LoRA, every layer has a different pair of low-rank matrices
AandB, and both matrices are trained. In VeRA, however, matricesAandBare frozen, random, and shared across all model layers. VeRA focuses on learning small, layer-specific scaling vectors, denoted asbandd, which are the only trainable parameters in this setup.
Delta-LoRA: Here, in addition to training low-rank matrices, the matrix
Wis also adjusted but not in the traditional way. Instead, the difference (or delta) between the product of the low-rank matricesAandBin two consecutive training steps is added toW:

LoRA+: In LoRA, both matrices
AandBare updated with the same learning rate. Authors found that setting a higher learning rate for matrixBresults in more optimal convergence.

To get into more detail about the precise steps, intuition, and results, read these articles:
That said, these are not the only LLM fine-tuning techniques. The following visual depicts a timeline of popular approaches:

👉 Over to you: What are some ways to reduce the computational complexity of fine-tuning LLMs?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
Fine-tuning LLMs is an exciting topic that we want to explore further. Thank you for the great overview.