
5 LLM Fine-tuning Techniques
...explained visually.

A 100% local and better alternative to Jupyter!
The .ipynb format is stuck in 2014. It was built for a different era with no cloud collaboration, no AI agents, and no team workflows.
Change one cell, and you get 50+ lines of JSON metadata in your git diff. Code reviews become a nightmare.
Want to share a database connection across notebooks? Configure it separately in each one. And there’s no flexibility for comments.
Jupyter works for solo analysis but breaks for teams building production AI systems.
Deepnote just open-sourced the solution (Apache 2.0 license).
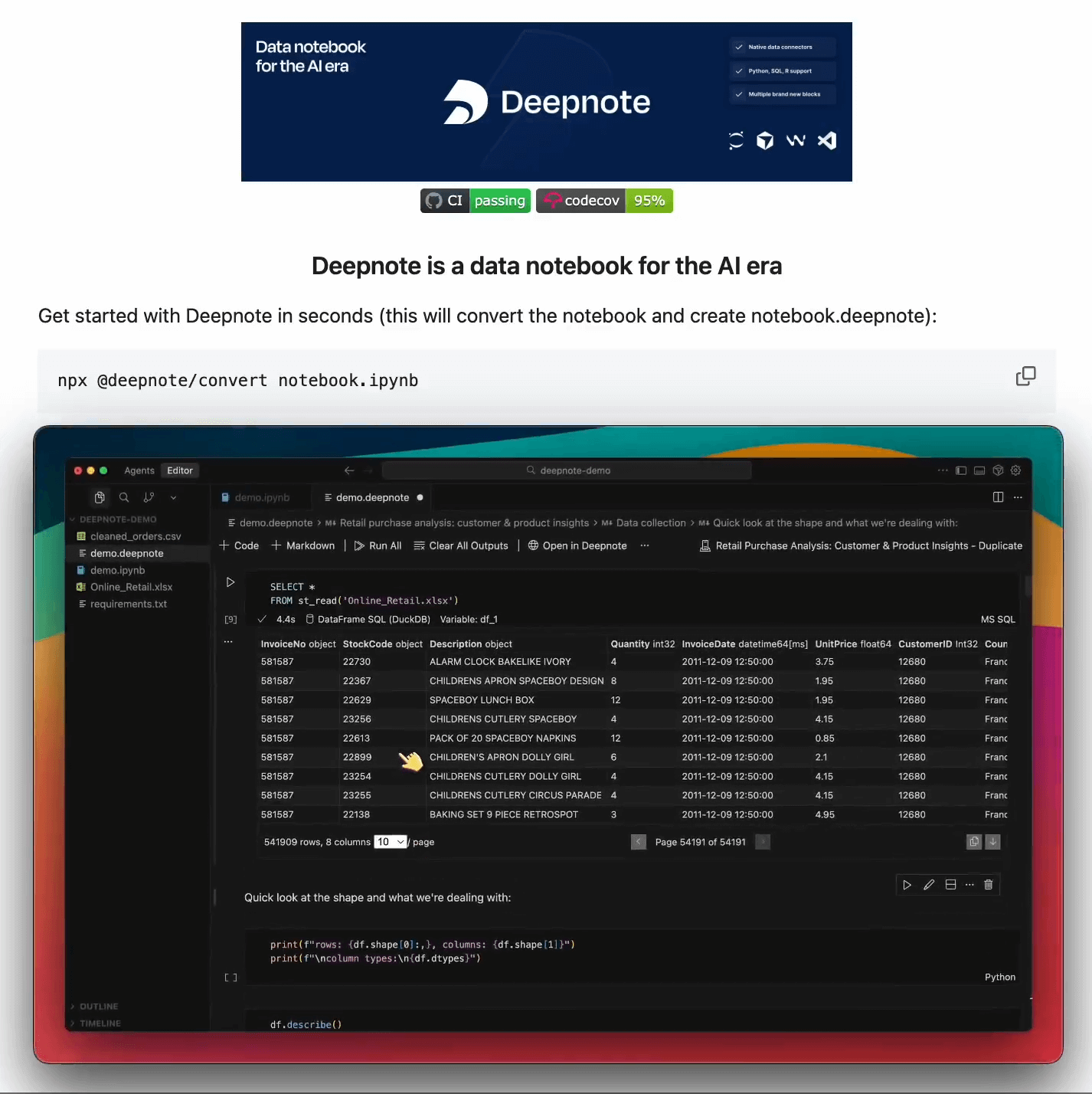
It’s a new notebook standard that actually fits modern workflows:
Human-readable YAML: Git diffs show actual code changes, not JSON noise. Code reviews finally work.
Project-based structure: Multiple notebooks share integrations, secrets, and environment settings. Configure once, use everywhere.
23 new block: SQL, interactive inputs, charts, and KPIs as first-class citizens. Build data apps, not just analytics notebooks.
Multi-language support - Python and SQL in one notebook. Modern data work isn’t single-language anymore.
Full backward and forward compatibility: convert any Jupyter notebook to Deepnote and vice versa with one command below:
npx @ deepnote/convert notebook.ipynb
Then open it in VS Code, Cursor, WindSurf, or Antigravity. Your existing notebooks migrate instantly.
Their cloud version adds real-time collaboration with comments, permissions, and live editing.
You can find the GitHub repo here → (don’t forget to star it)
Fine-tuning Techniques for LLMs
Traditional fine-tuning (depicted below) is infeasible with LLMs because these models have billions of parameters and are hundreds of GBs in size, and not everyone has access to such computing infrastructure.

Thankfully, today, we have many optimal ways to fine-tune LLMs, and five such popular techniques are depicted below:
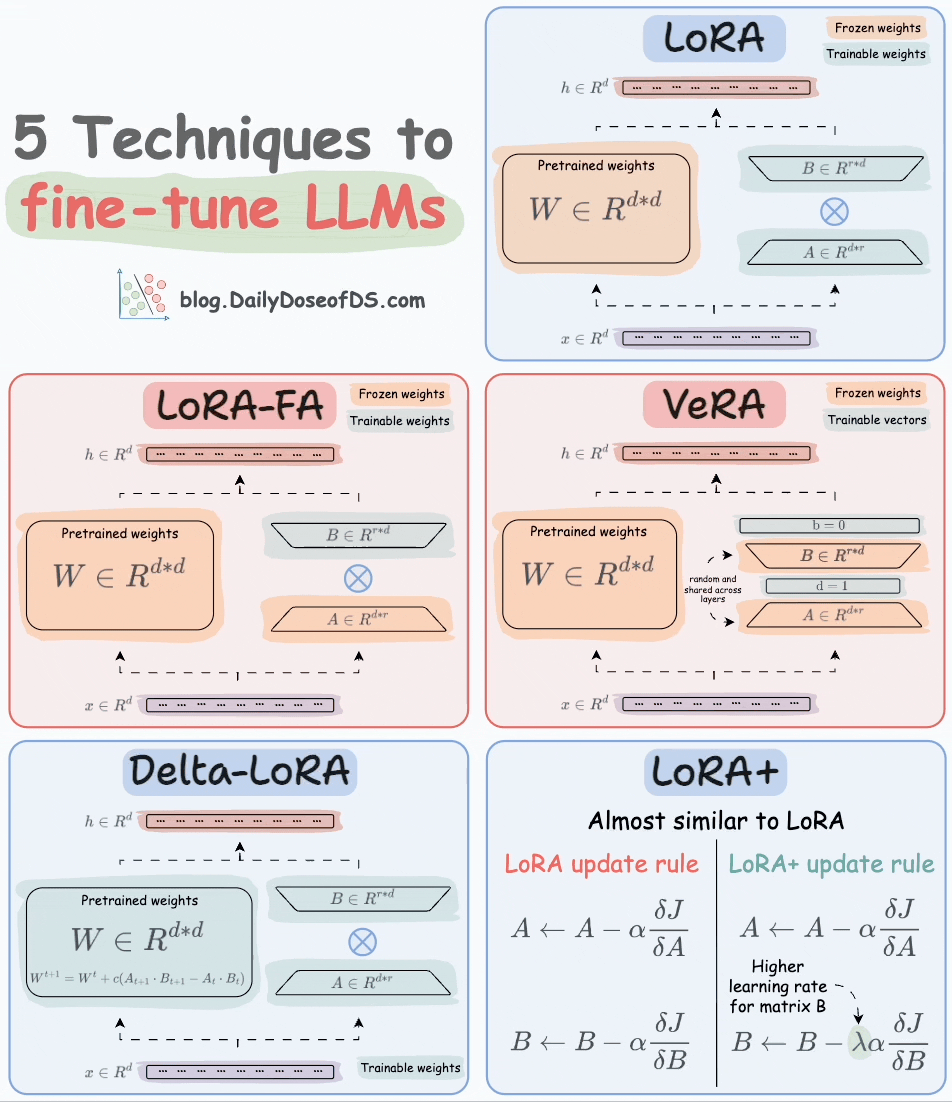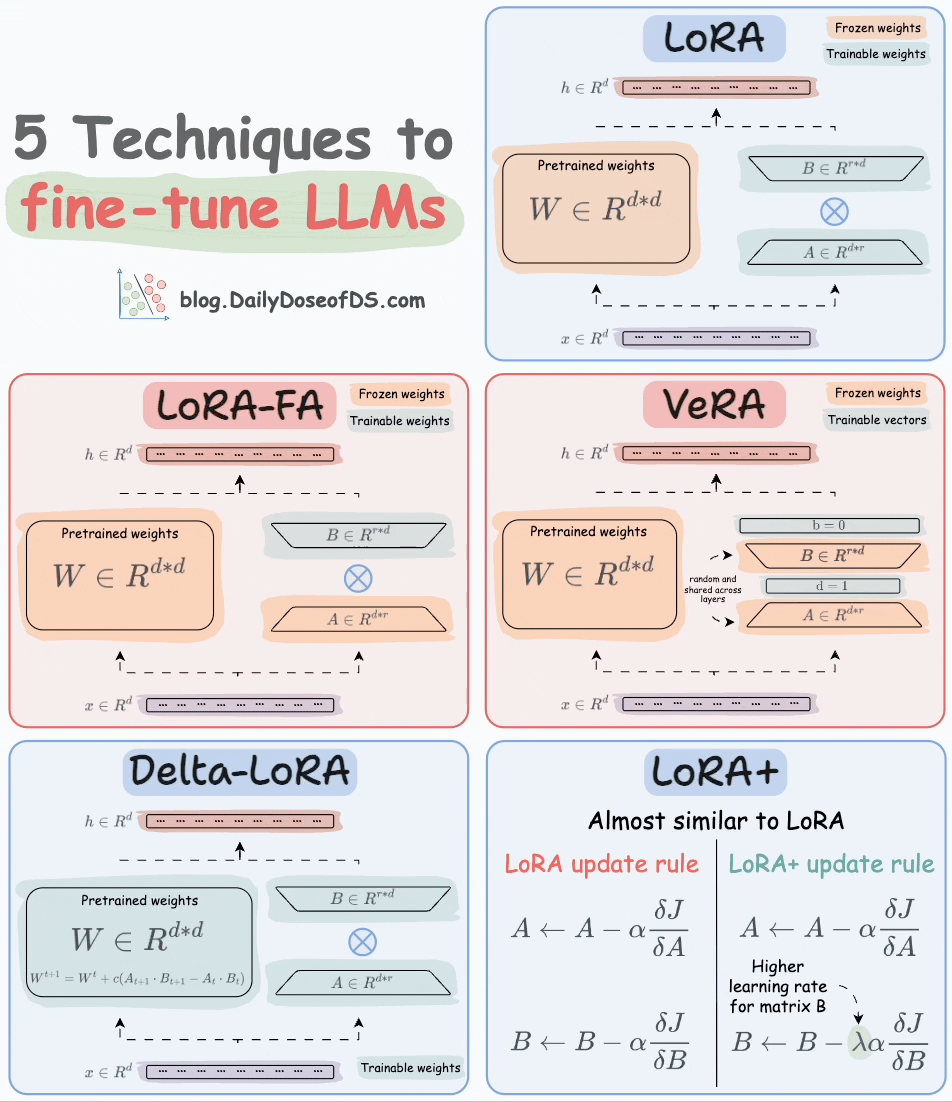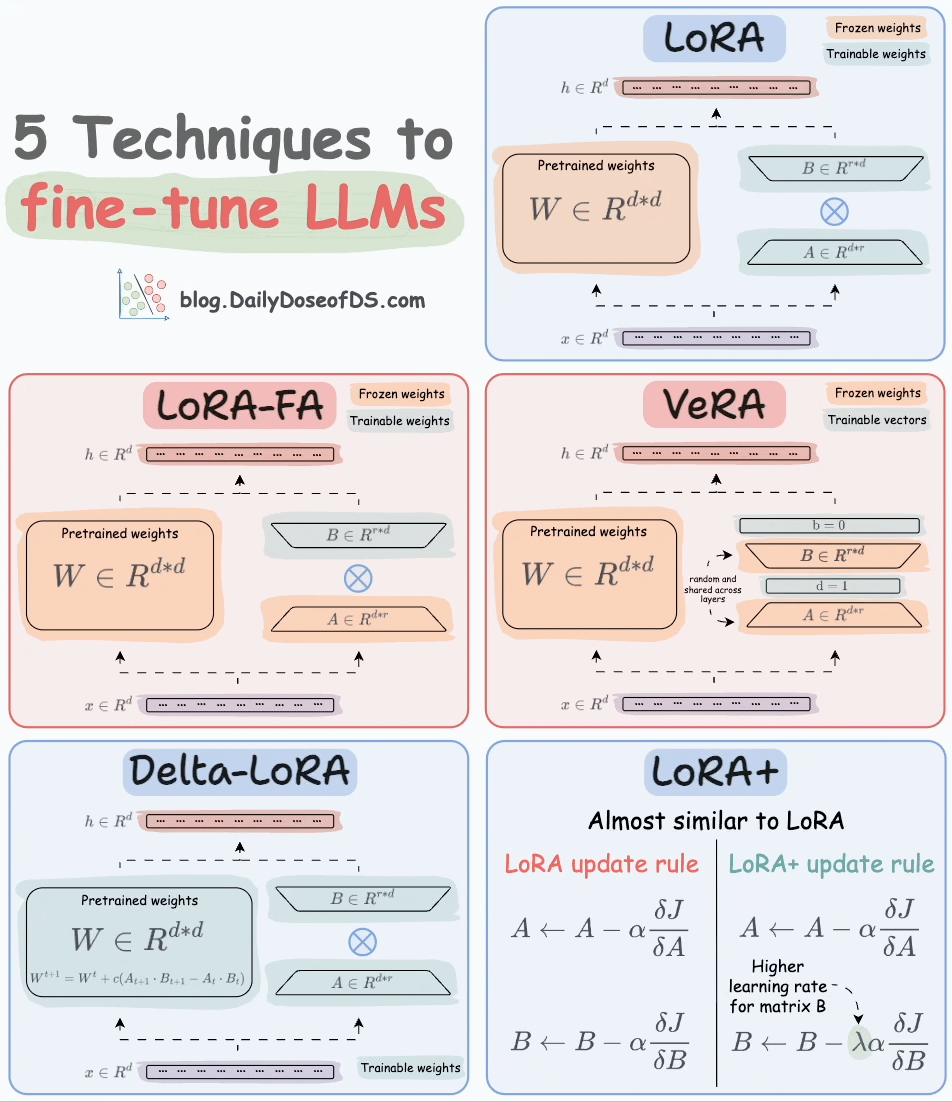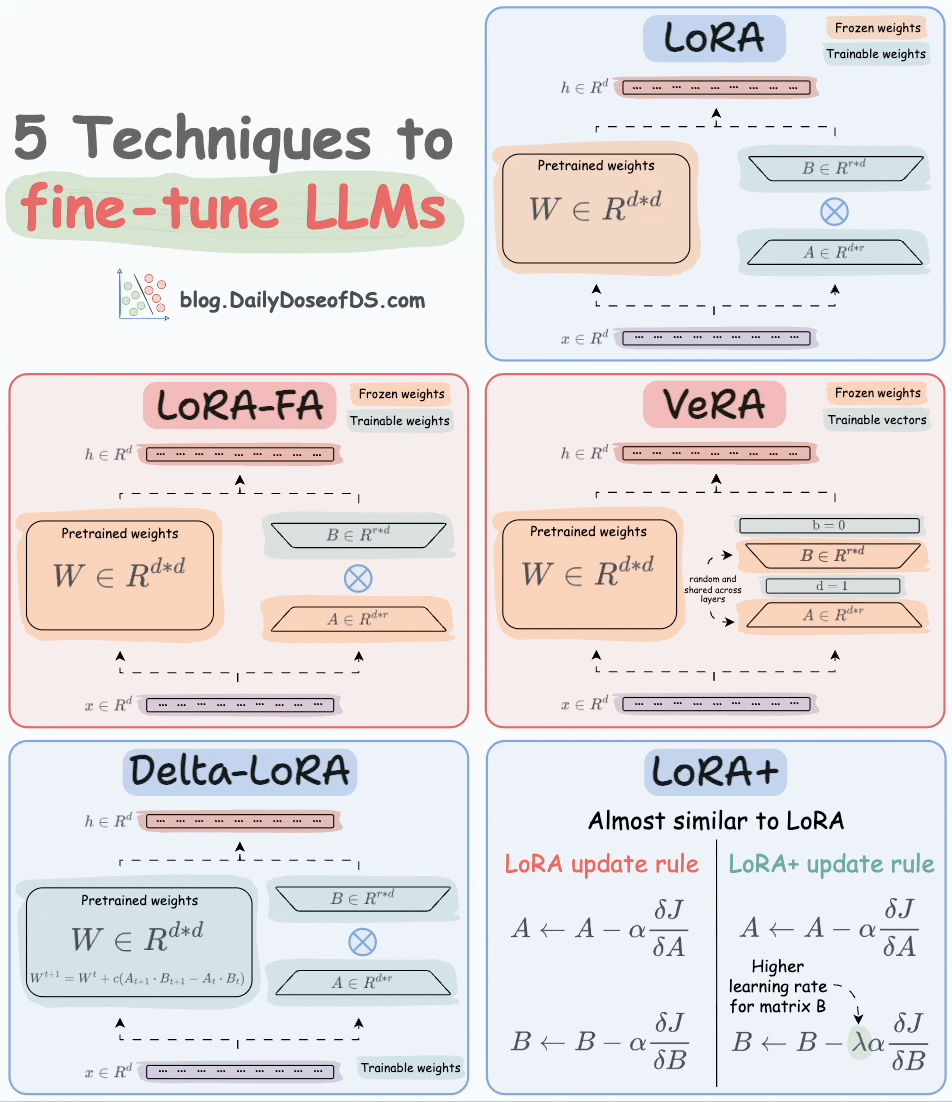
We covered them in detail here:
Here’s a brief explanation:
LoRA: Add two low-rank matrices
AandBalongside weight matrices, which contain the trainable parameters. Instead of fine-tuningW, adjust the updates in these low-rank matrices.

LoRA-FA: While LoRA considerably decreases the total trainable parameters, it still requires substantial activation memory to update the low-rank weights. LoRA-FA (FA stands for Frozen-A) freezes the matrix
Aand only updates matrixB.

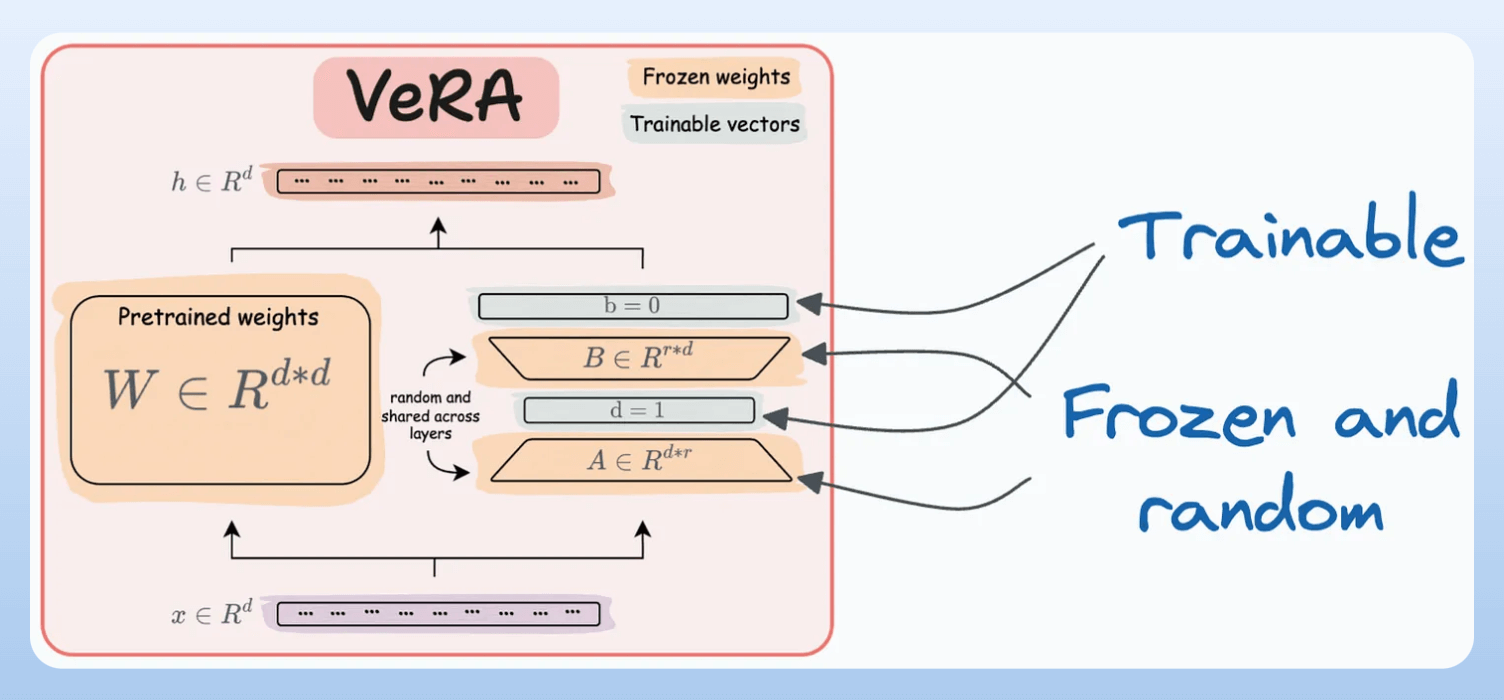
VeRA: In LoRA, every layer has a different pair of low-rank matrices
AandB, and both matrices are trained. In VeRA, however, matricesAandBare frozen, random, and shared across all model layers. VeRA focuses on learning small, layer-specific scaling vectors, denoted asbandd, which are the only trainable parameters in this setup.
Delta-LoRA: Here, in addition to training low-rank matrices, the matrix
Wis also adjusted but not in the traditional way. Instead, the difference (or delta) between the product of the low-rank matricesAandBin two consecutive training steps is added toW:

LoRA+: In LoRA, both matrices
AandBare updated with the same learning rate. Authors found that setting a higher learning rate for matrixBresults in more optimal convergence.

To get into more detail about the precise steps, intuition, and results, read these articles:
👉 Over to you: What are some ways to reduce the computational complexity of fine-tuning LLMs?
Thanks for reading!