
6 Coolest Jupyter Hacks That 90% Users Are Consistently Ignoring
Jupyter is cool. Let's make it super cool.

Despite the widespread usage of Jupyter notebooks, I think many users do not use them to their full potential.
They tend to use Jupyter using its default interface/capabilities, which, in my opinion, can be largely improved to provide a richer experience.
Today, let me share some of the coolest things I have learned about Jupyter after using it for so many years.
Let’s begin!
#1) Retrieve a cell’s output in Jupyter
Many Jupyter users often forget to assign the results of a Jupyter cell to a variable.
So they have to (unwillingly) rerun the cell and assign it to a variable.
But very few know that IPython provides a dictionary Out, which you can use to retrieve a cell’s output.

Just specify the cell number as the dictionary’s key. This will return the corresponding output.
#2) Enrich the default preview of a DataFrame
Often when we load a DataFrame in Jupyter, we preview it by printing, as shown below:
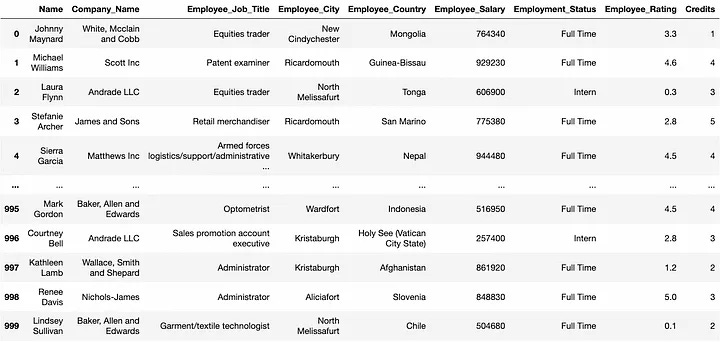
However, it hardly tells anything about what’s inside this data.
Instead, use Jupyter-DataTables.

It supercharges the default preview of a DataFrame with many useful features, as depicted above.
This richer preview provides sorting, filtering, exporting, and pagination operations along with column distribution and data types.
#3) Generate helpful hints as you write Pandas code
Pandas has many unoptimized methods.
They can significantly slow down data analysis if you use them.
Dovpanda is a pretty cool tool that gives suggestions/warnings about your data manipulation steps.

Whenever we use any unoptimized methods, it automatically prompts a warning and a suggestion.
#4) Improve rendering of DataFrames
In a recent issue on Sparklines, we learned that whenever we display a DataFrame in Jupyter, it is rendered using HTML and CSS.

This means that we can format its output just like web pages.
One thing that many Jupyter users do is that they preview raw DataFrames for data analysis tasks.
But unknown to them, styling can make data analysis much easier and faster, as depicted below:

The above styling provides so much clarity over a raw DataFrame.
To style Pandas DataFrames, use its Styling API (𝗱𝗳.𝘀𝘁𝘆𝗹𝗲). As a result, the DataFrame is rendered with the specified styling.
#5) Restart the Jupyter kernel without losing variables
While working in a Jupyter Notebook, you may want to restart the kernel due to several reasons.
If there are any active data/model objects, most users dump them to disk, restart the kernel, and then load them back.
But this is never needed.
Use the %store magic command.

It allows you to store and retrieve a variable back even if you restart the kernel.
This way, you can avoid the hassle of dumping an object to disk.
#6) Search code in all Jupyter Notebooks from the terminal
Context: I have published over 400 newsletter issues so far.
So my local directory is filled with Jupyter notebooks (342 as of today), which accompany the code for most of the issues published here.

Thus, if I ever wanted to refer to some code I wrote previously in a Jupyter notebook, it became tough to find that specific notebook.
This involved plenty of manual effort.
But later, I discovered an open-source tool — nbcommands.
Using this, we can search for code in Jupyter Notebook right from the terminal:
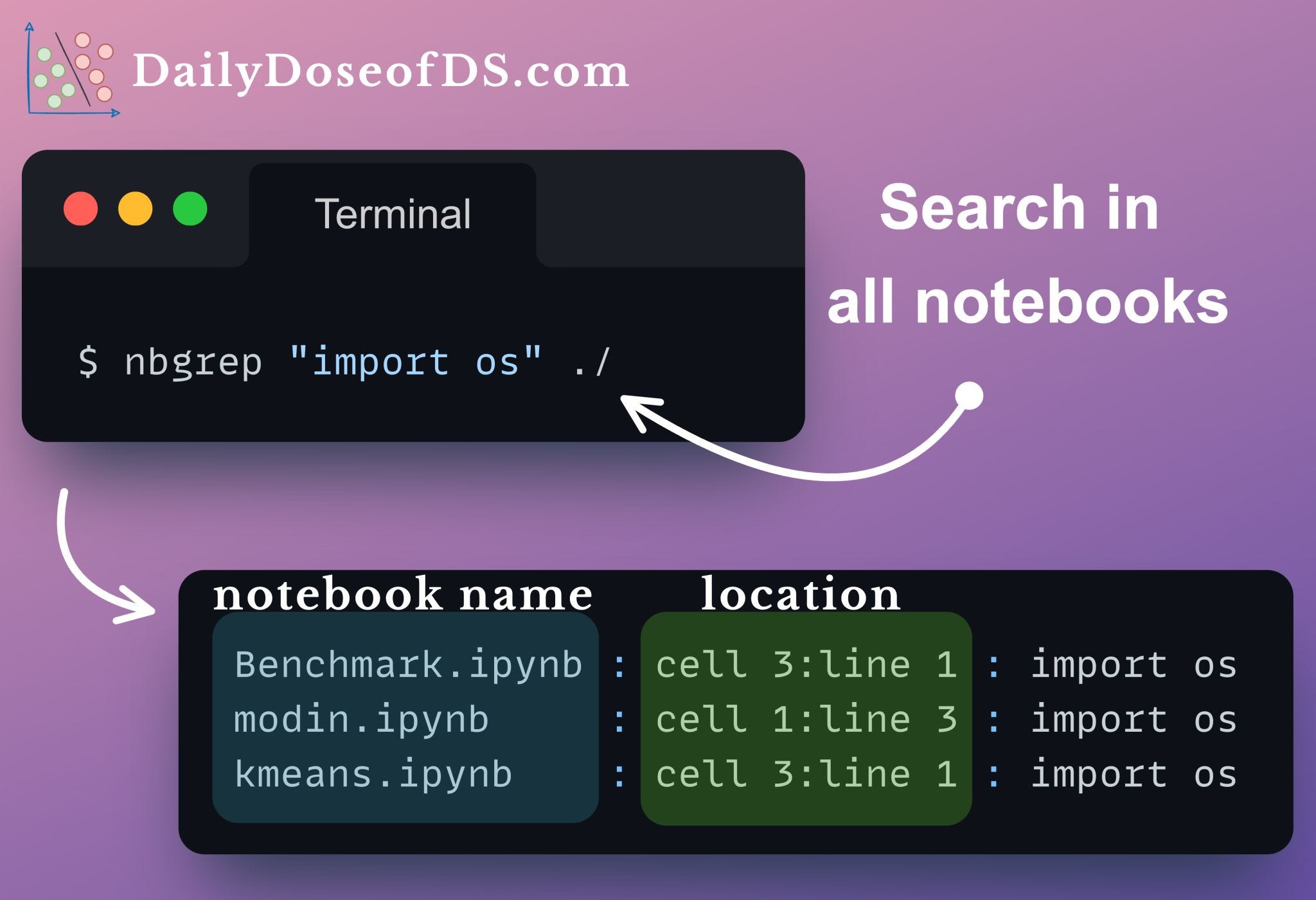
A task that often used to take me 5-10 minutes now takes me only a couple of seconds.
Pretty cool, isn’t it?
That’s it for today.
Hope you learned something new :)
👉 Over to you: What are some other cool Jupyter hacks that you are aware of?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Love you posts! Thanks for sharing
Great tips, as always!