
6 Graph Feature Engineering Techniques
Must-know for building GNNs.

Building front-end Agentic apps just got 10x easier
If you're building apps where Agents are part of the interface, not just running in the background, AG-UI protocol has become the standard.
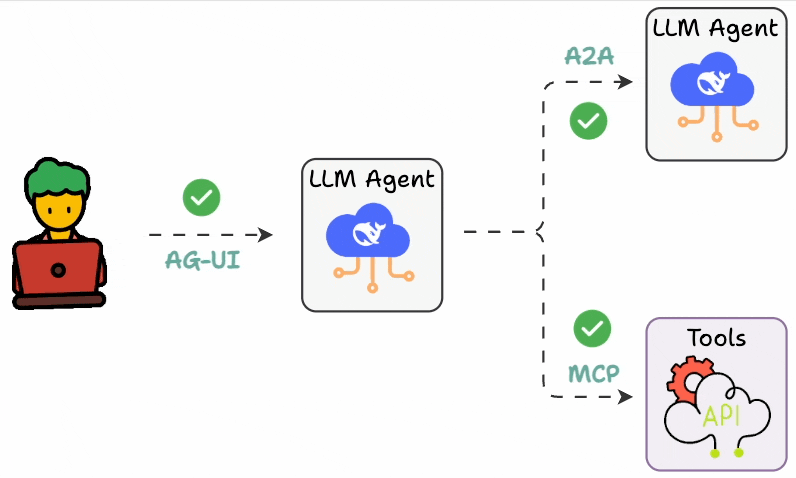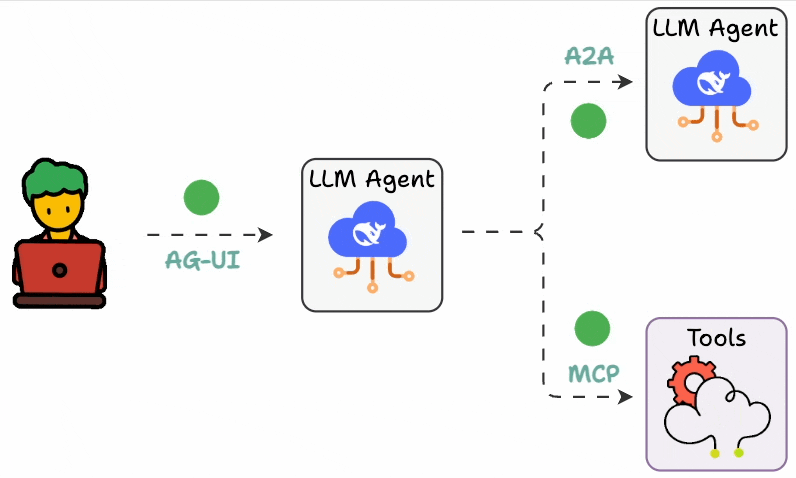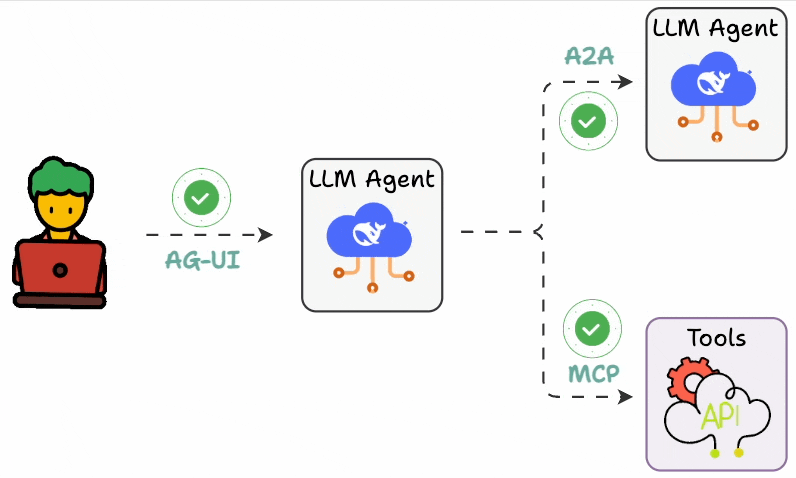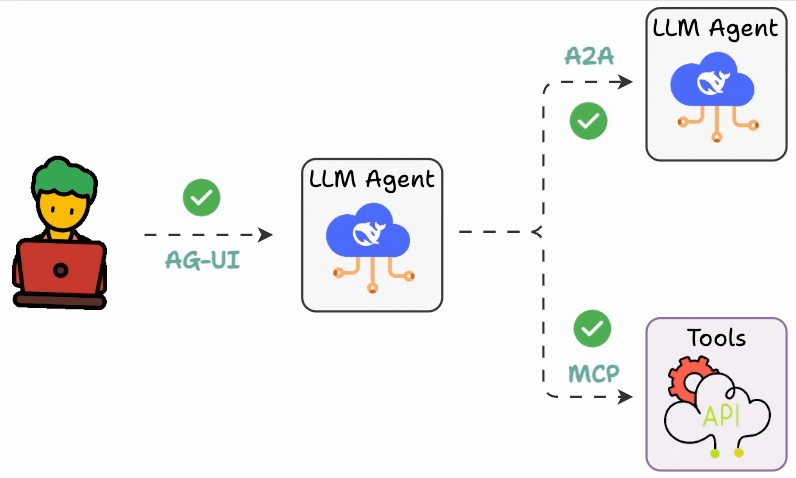
For context:
MCP connects agents to tools
A2A connects agents to other agents
AG-UI connects agents to users
It defines a common interface between Agents and the UI layer.
AG-UI itself is Agent framework agnostic, and it lets you:
stream token-level updates
show tool progress in real time
share mutable state
and pause for human input
The visual below summarizes the latest updates:
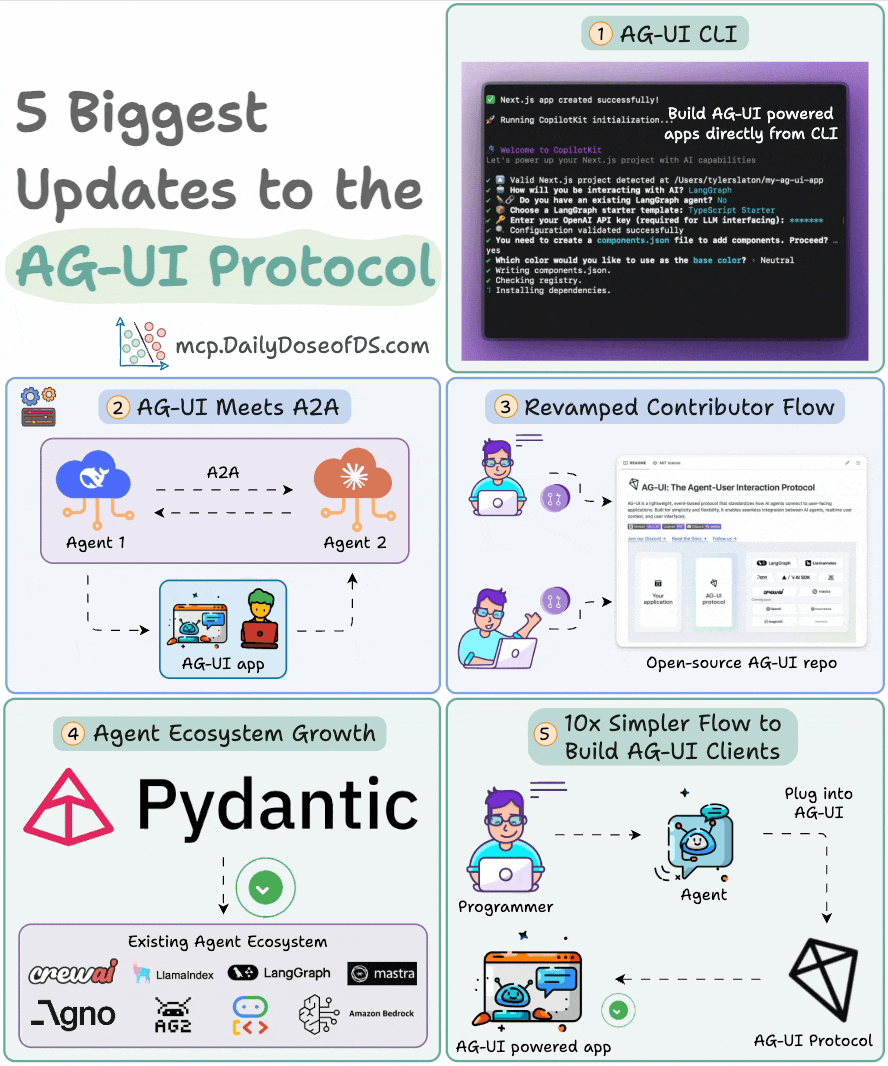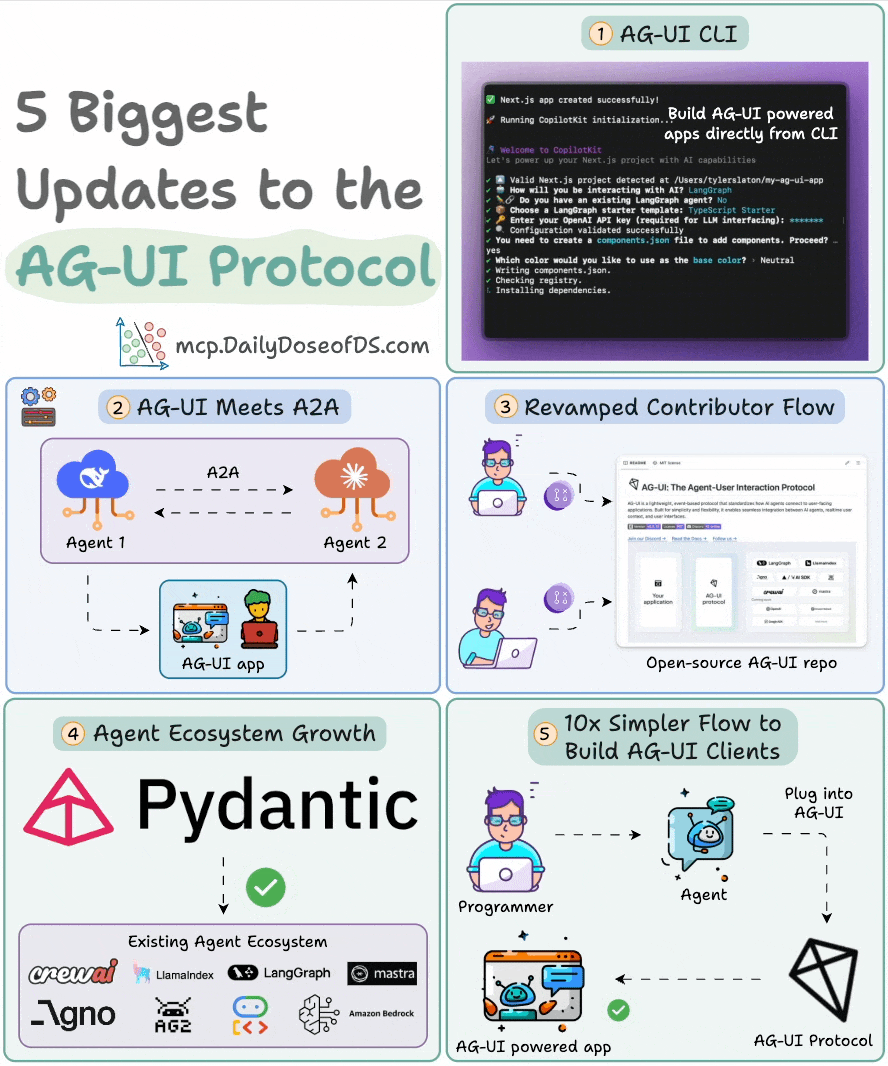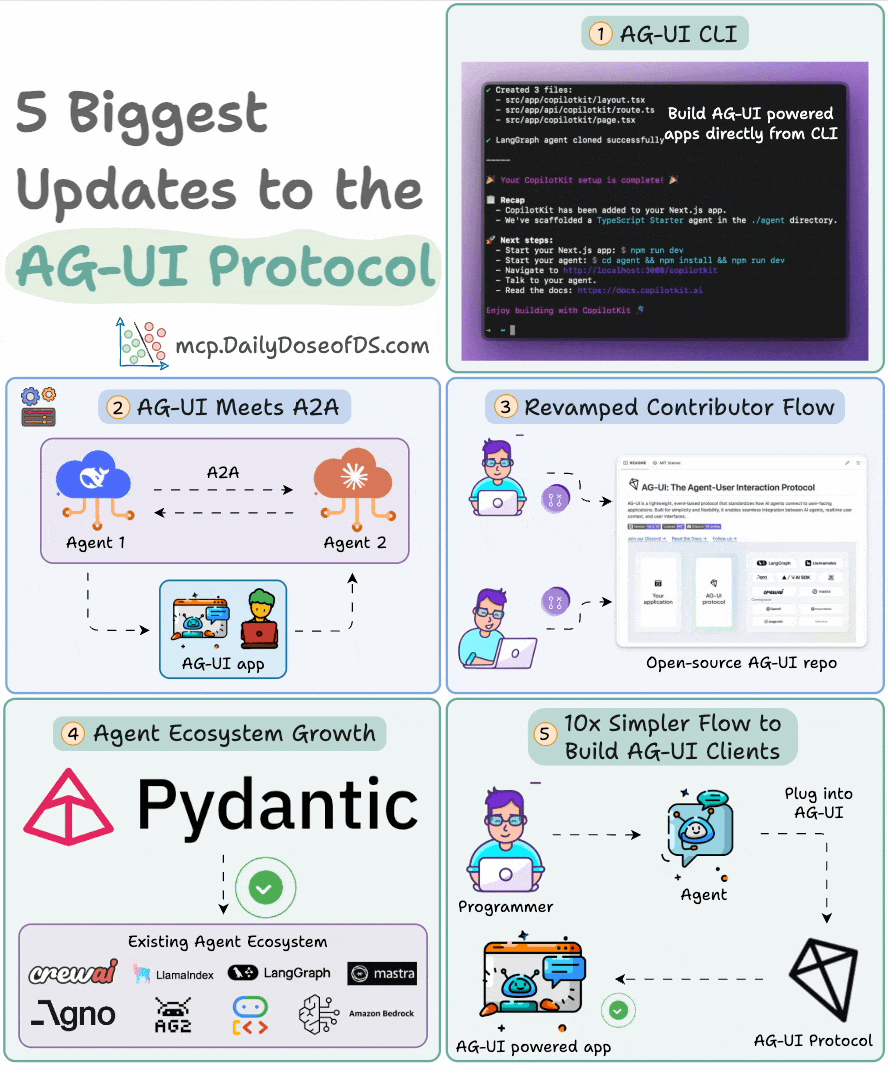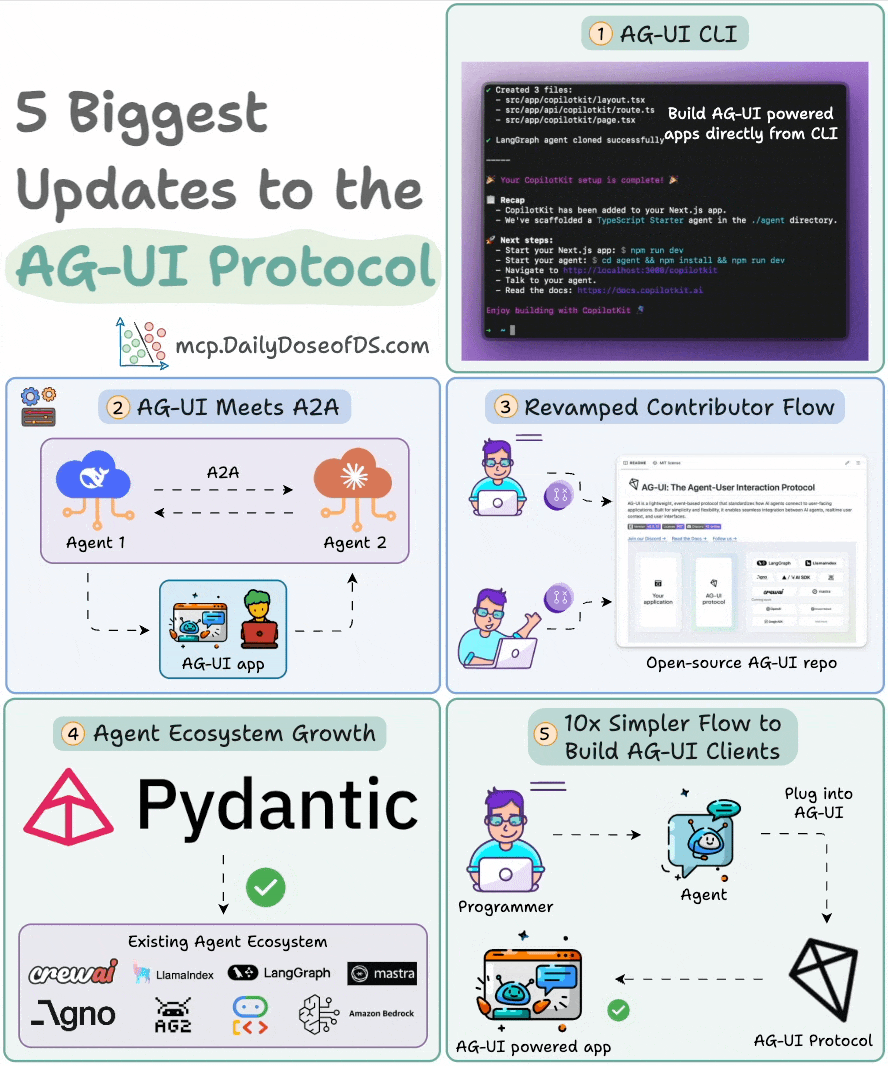
Spin up a full-stack AG-UI app directly from CLI.
Visualize A2A interactions, and allow them to reach out to the user.
A fully revamped contributor flow for developers.
Pydantic AI is now AG-UI compatible.
Build AG-UI frontends 10x faster with a plug-and-play interface.
Build your own AG-UI client: npx create-ag-ui-app my-agent-app.
GitHub repo → (don’t forget to star)
6 graph feature engineering techniques
Like images, text, and tabular datasets have features, so do graph datasets.
This means when building models on graph datasets, we can engineer these features to achieve better performance.
Today, let us learn 6 must-know techniques to do so.
Let’s begin!
Note: In case you missed it, we have already done an extensive and beginner-friendly crash course on graph neural networks (with implementations):
Part 1: A Crash Course on GNNs – Part 1
Part 2: A Crash Course on GNNs – Part 2
Part 3: A Crash Course on GNNs – Part 3
Dummy dataset
Let’s create a dummy social networking graph dataset with accounts and followers:
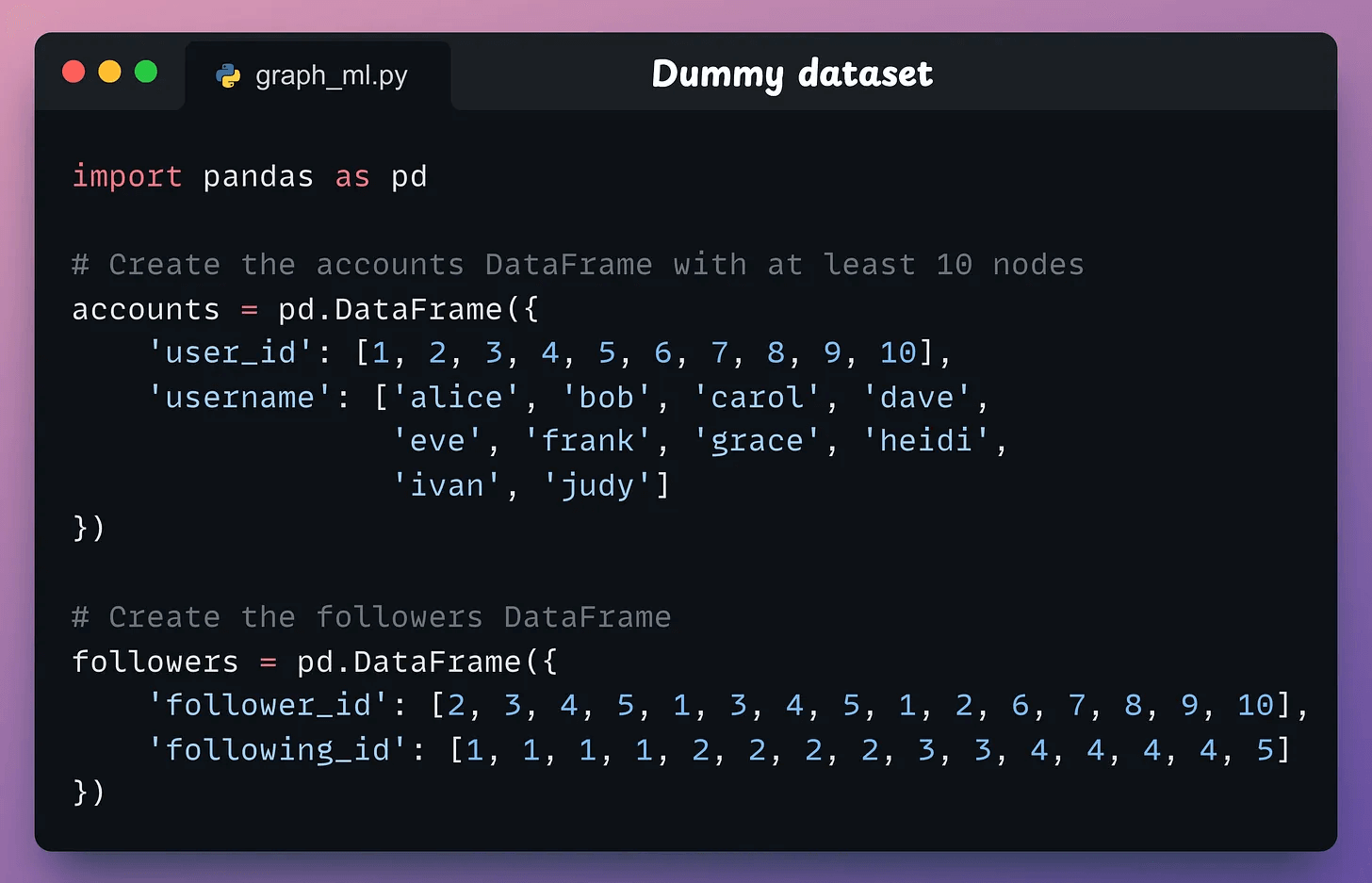
This is tabular, but we need to convert this into a graph format. To do this, we use networkx as follows:
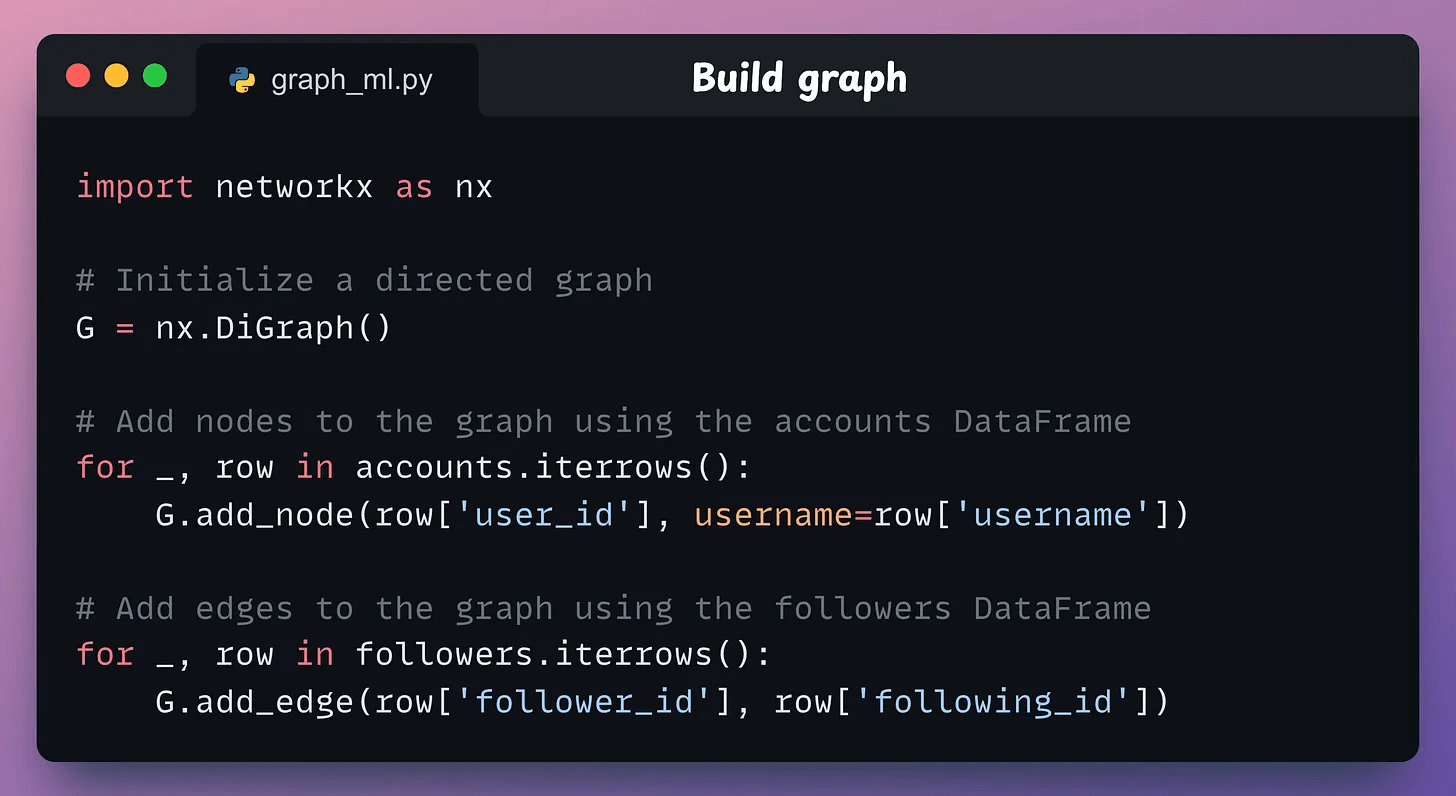
We initialize a directed graph
G.Next, we add nodes to the graph using the
accountsDataFrame.Finally, we added edges between the nodes using the
followersDataFrame. These are directed edges from the follower to the user they are following.
This produces the following graph:
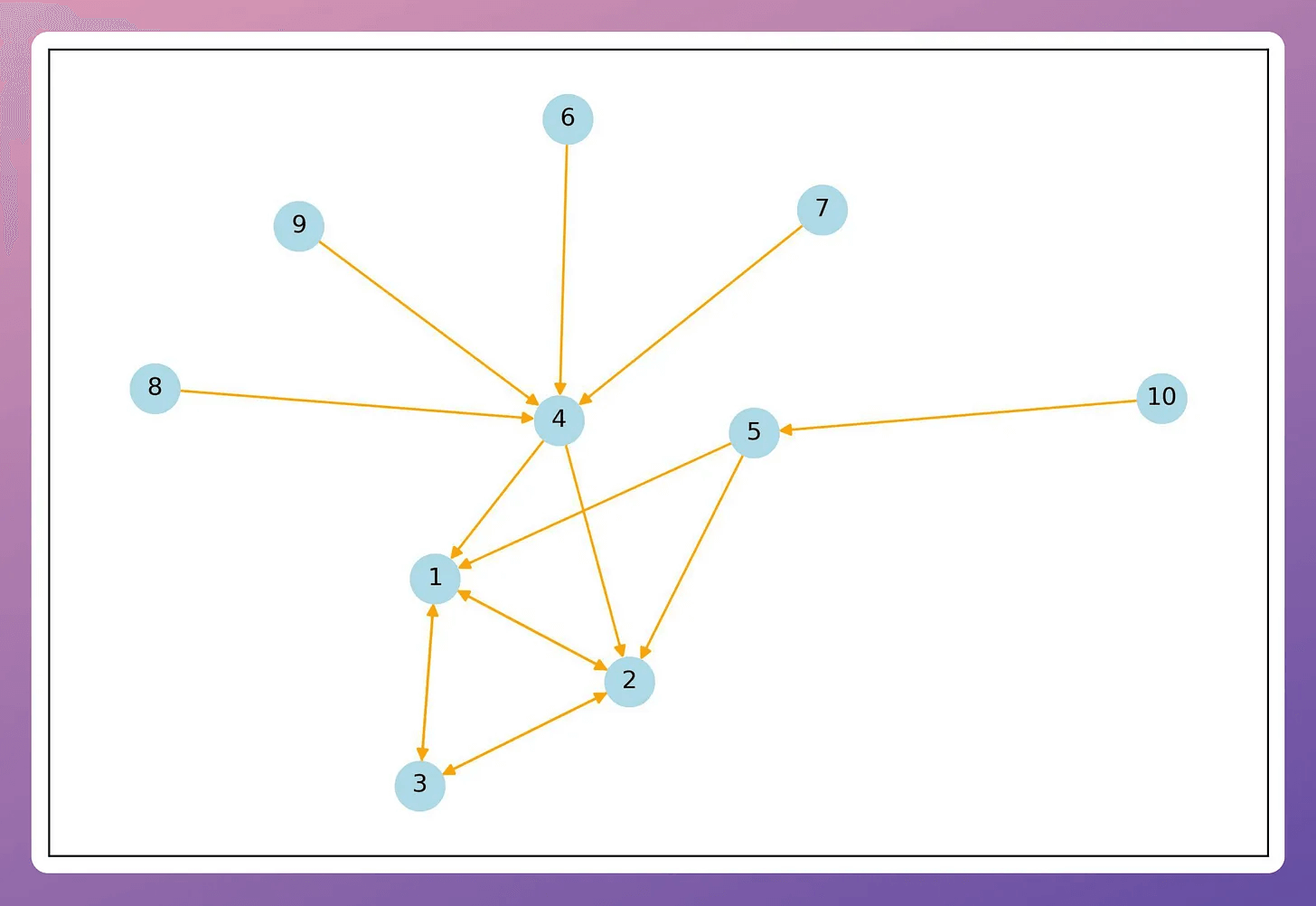
With that, we are now ready for feature engineering.
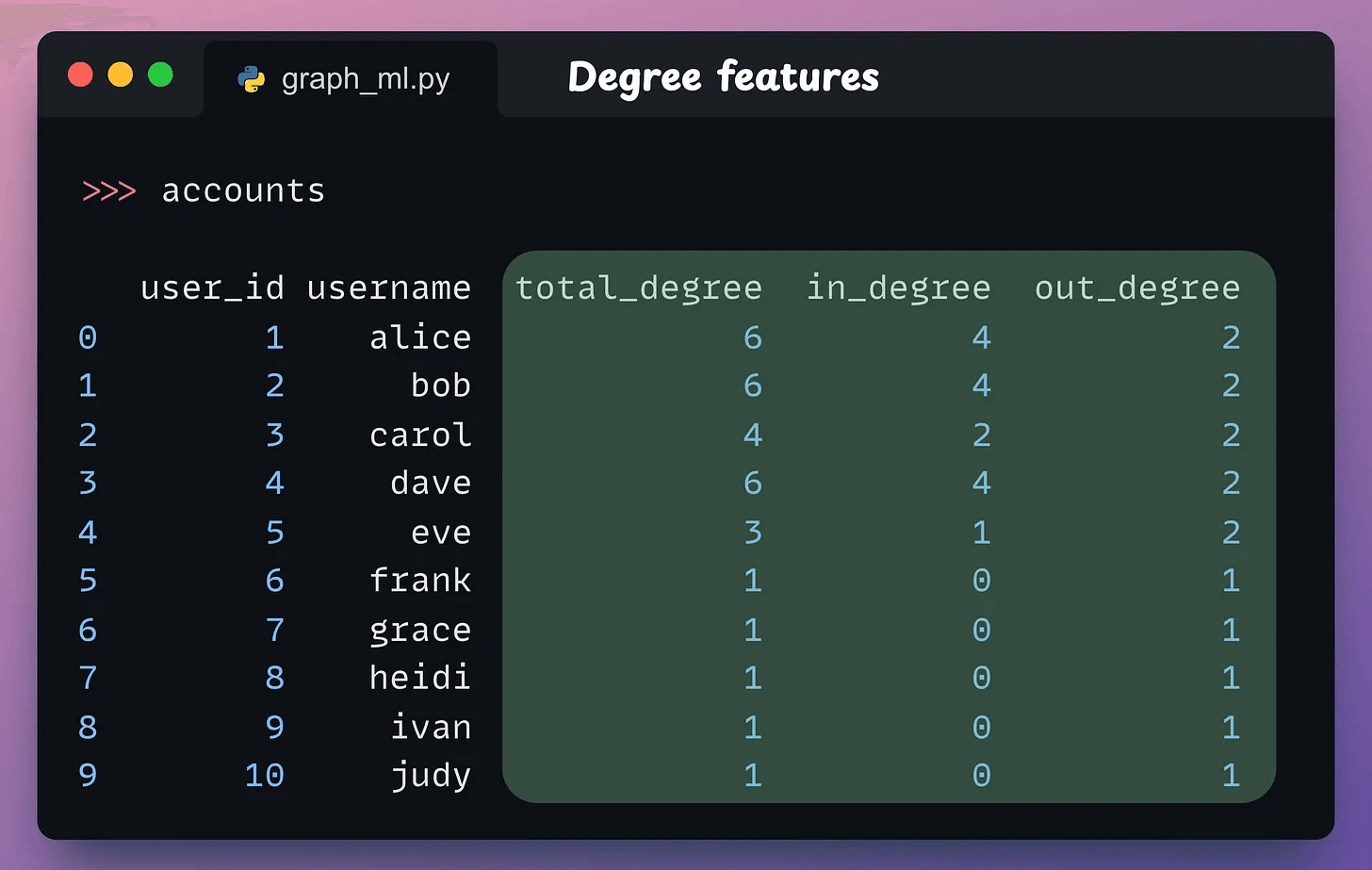
1-3) Node degree
In a directed graph (like above), there are two types of degrees:
In-Degree: The number of incoming edges (followers) a node has. A high in-degree can indicate that a user is influential.
Out-Degree: The number of outgoing edges (followings) a node has. A high out-degree can indicate that a user is very active.
Here’s how we can compute them using NetworkX:
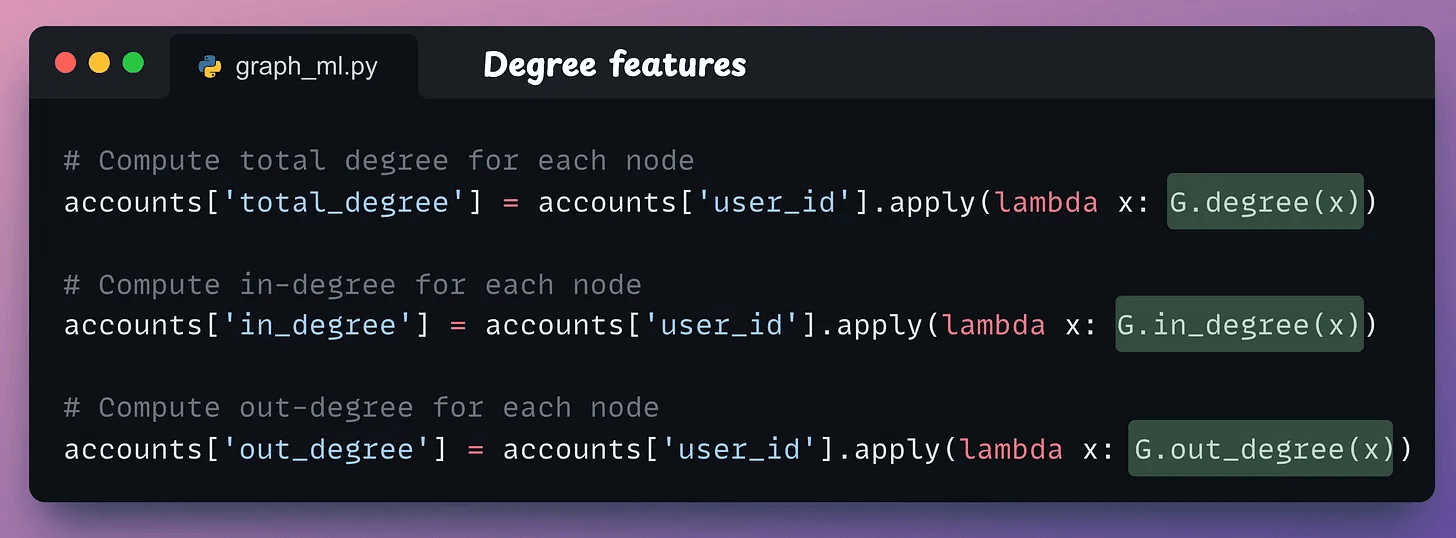
G.in_degree(x)counts edges directed toward the nodex.G.out_degree(x)counts edges directed away from the nodex.G.degree(x)is the sum of the in-degree and out-degree of the nodex.
These features are now part of the accounts DataFrame as depicted below:
4-6) Node centrality
Node degree features discussed above capture connectedness but fail to capture the influence of those connections.
For instance, a user can have many online friends just because they send friend requests to everyone.
Centrality features handle this.
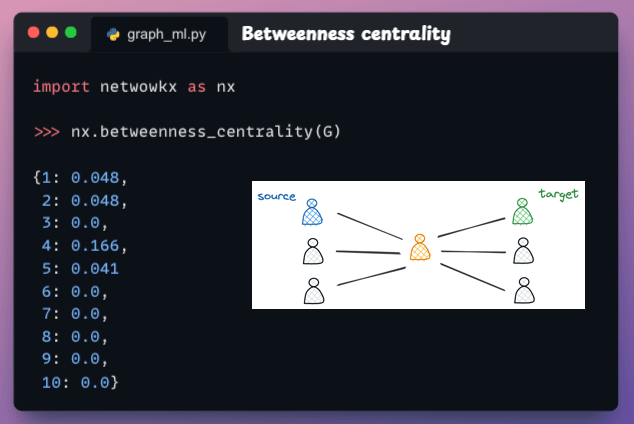
Betweenness centrality
This measures how often a node appears on the shortest paths between other nodes.
If a node often acts as a “bridge” between other nodes, it plays a key role in facilitating information flow.
In the following graph, the yellow node has a high betweenness centrality since it always lies on the shortest path between any two nodes.
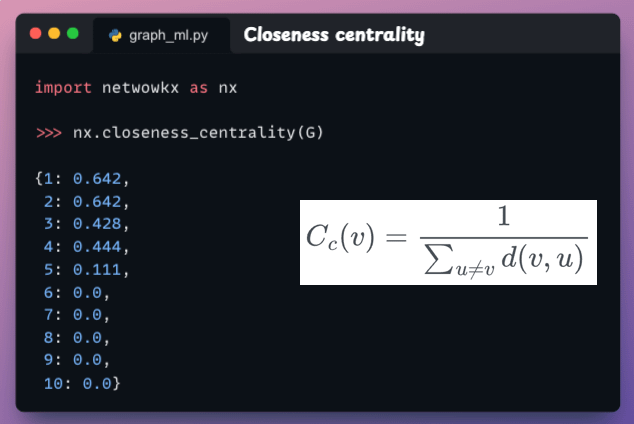
Closeness centrality
This indicates how close a node is to all other nodes in the network based on the shortest paths.
If a node with high closeness centrality can quickly interact with others, it means that it can spread information efficiently across the network.
To compute closeness centrality for a node v, we sum the shortest path length from v to all other nodes and take its reciprocal:
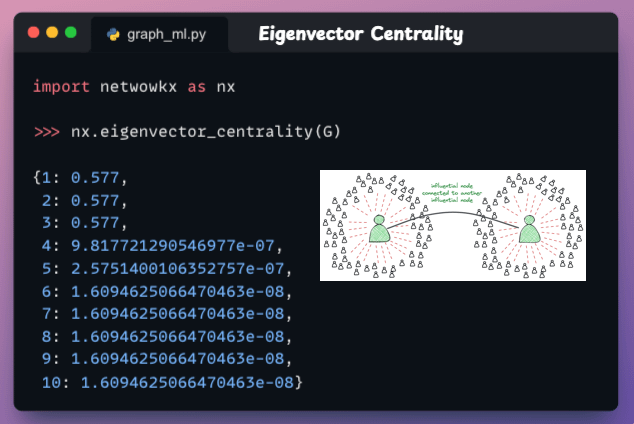
Eigenvector centrality
If a node is connected to other influential nodes, it amplifies its own influence.
So this feature identifies nodes that are influential not only due to their direct ties but also due to their connections with other influential nodes.
Those were the 6 common graph feature engineering techniques!
We covered the implementations of node centrality in the extensive and beginner-friendly crash course on graph neural networks (with implementations):
Part 1: A Crash Course on GNNs – Part 1
Part 2: A Crash Course on GNNs – Part 2.
Part 3: A Crash Course on GNNs – Part 3.
Here’s why you should care about GraphML:
Google Maps uses graph ML for ETA prediction.
Pinterest uses graph ML (PingSage) for recommendations.
Netflix uses graph ML (SemanticGNN) for recommendations.
Spotify uses graph ML (HGNNs) for audiobook recommendations.
Uber Eats uses graph ML (a GraphSAGE variant) to suggest dishes, restaurants, etc.
The list could go on since almost every major tech company employs graph ML.
Becoming proficient in graph ML is now as crucial as traditional DL to differentiate profiles and aim for these positions.
We cover:
Background of GNNs and their benefits.
Type of tasks for GNNs.
Data challenges in GNNs.
Frameworks to build GNNs.
Advanced architectures to build robust GNNs.
Feature engineering methods.
Practical demos.
Insights and some best practices.
Over to you: What are some graph feature engineering methods?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.