
6 Steps to Build an ML Model
...explained visually!

Online hackathon for Agent Builders ($30k in prizes)!

Encode Club is running an AI Agents Hackathon starting January 13th, and the theme is interesting: Build AI Agents that help people actually stick to their New Year’s resolutions.
$30,000 in prizes across six categories: productivity, health, financial wellness, personal growth, and social impact.
Moreover, the “Best Use of Comet Opik” track ($5,000) rewards teams that implement proper evaluation and observability in their AI systems. This is because most AI agent projects fail in production due to no systematic way to track experiments, measure performance, or improve quality with data.
You also get workshops from Comet’s team on agent optimization, plus credits from Google and Vercel.
It’s completely online and free to participate.
Thanks to Comet for partnering today!
6 Steps to build an ML model
Building an ML model isn’t just about picking an algorithm and hitting train.
Getting it to production requires 6 steps, and the algorithm selection is just one of them.
Here’s the full breakdown:
On a side note, we have already covered MLOps from a fully beginner-friendly perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, Spark, model compression, Deployment phase, Kubernetes, cloud infra, virtualisation, deep dive into AWS, and monitoring in production.
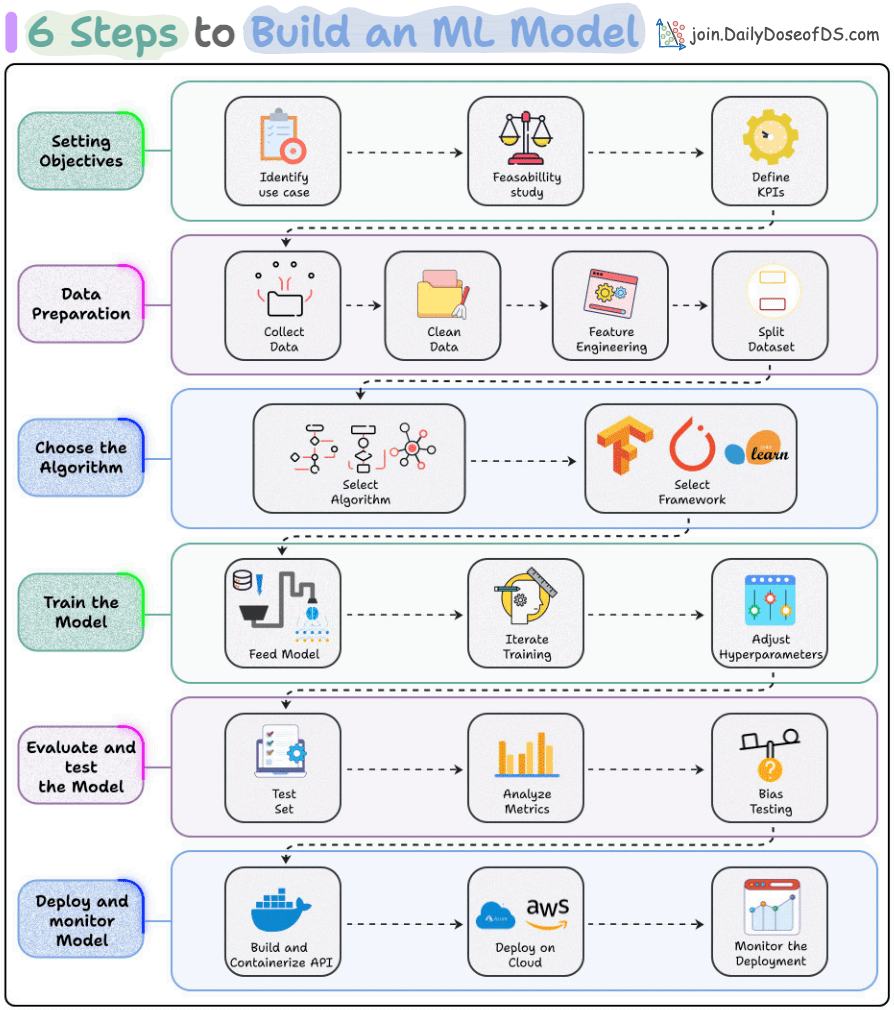
Step 1: Setting objectives
Before writing a single line of code, you need clarity.
What problem are you solving? Is ML even the right approach? What does success look like?

This means identifying the use case, running a feasibility study, and defining your KPIs upfront.
Step 2: Data preparation
This is where you’ll spend most of your time since no fancy algorithm fixes bad data.

Here, you collect your data, clean it (handle missing values, outliers, inconsistencies), engineer meaningful features, and split it properly into train/validation/test sets.
Step 3: Choose the algorithm
Now you pick your approach, like Random Forest, XGBoost, Neural network, etc.

The choice depends on your problem type, data size, interpretability needs, and latency requirements.
Also, decide on your framework: scikit-learn for classical ML, TensorFlow, or PyTorch for deep learning.
Step 4: Train the model
Feed your prepared data to the model and let it learn.

But training isn’t a one-shot thing. Here, you iterate, adjust hyperparameters and experiment with different configurations.
This loop continues until performance plateaus.
Step 5: Evaluate and test
Now, you test how good your model really is.
Run it on your held-out test set. Analyze metrics relevant to your problem (accuracy, precision, recall, F1, AUC).

And don’t forget bias testing. Your model should work fairly across different segments.
Step 6: Deploy and monitor

Finally, you containerize it, deploy it to the cloud (AWS, GCP, Azure), and set up monitoring.
Moreover, since models degrade over time, you need to catch data drifts and other issues before your users do.
That’s the full picture.
The algorithm typically gets all the attention, but it’s maybe 15% of the work. The rest is Engineering, infra, and careful thinking.
If you want to see this in practice, we have already covered MLOps from a fully beginner-friendly perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, Spark, model compression, Deployment phase, Kubernetes, cloud infra, virtualisation, deep dive into AWS, and monitoring in production.
Start with MLOps Part 1 here →
We also started the LLMOps crash course recently:
👉 Over to you: Have we missed any step in the model-building process?
Thanks for reading!