
7 Categorical Data Encoding Techniques
...summarized in a single frame.

Power AI Agents with Seamless, Real-Time Web Interaction

AI agents need more than just data—they need unrestricted, scalable access to the web to retrieve, process, and act on real-time information.
Without the right infrastructure, bot detection, CAPTCHAs, and IP restrictions can block automation and slow down AI-driven workflows.
Bright Data gives you:
Global access across geos to ensure AI agents retrieve localized, real-time data.
Automated handling of cookies, headers, and user agents for seamless web interaction.
Mimic browser fingerprints & user behavior to prevent detection and blocking.
Auto-retry, IP rotation, and CAPTCHA solving to keep AI workflows running smoothly.
JavaScript rendering to extract data from dynamic, modern web pages.
If your AI agents are hitting roadblocks, it’s time to upgrade.
Bright Data provides the infrastructure to scale AI automation, bypass restrictions, and ensure real-time decision-making.
Thanks to Bright Data for partnering today.
7 Categorical Data Encoding Techniques
Here are 7 ways to encode categorical features:
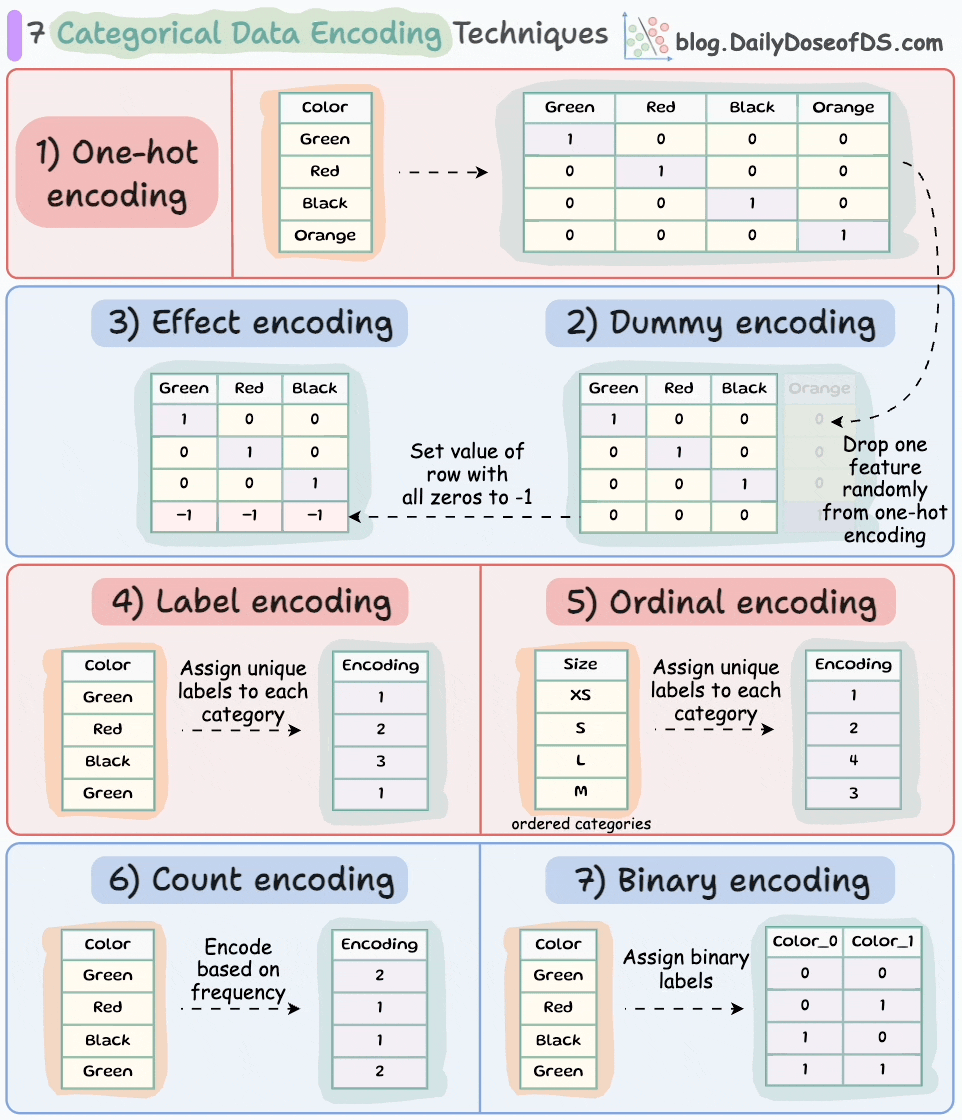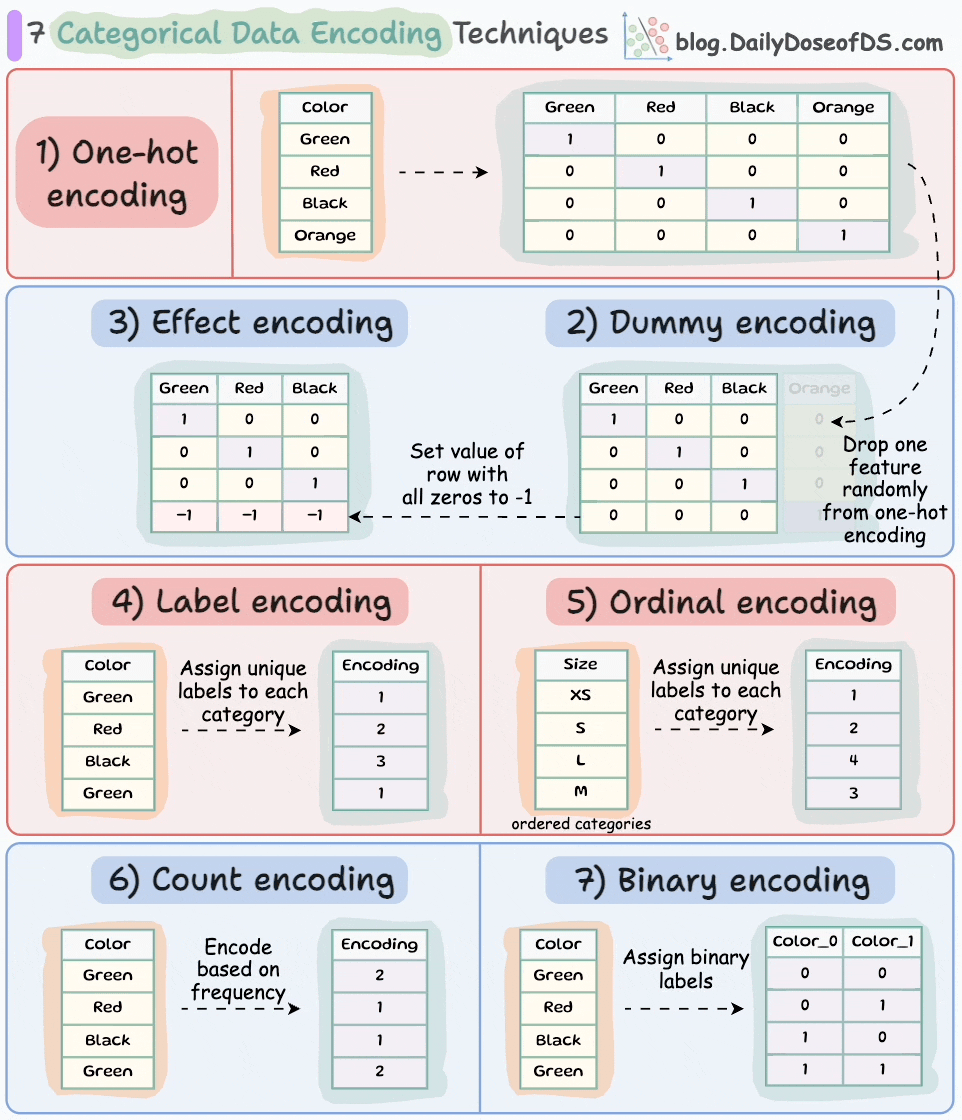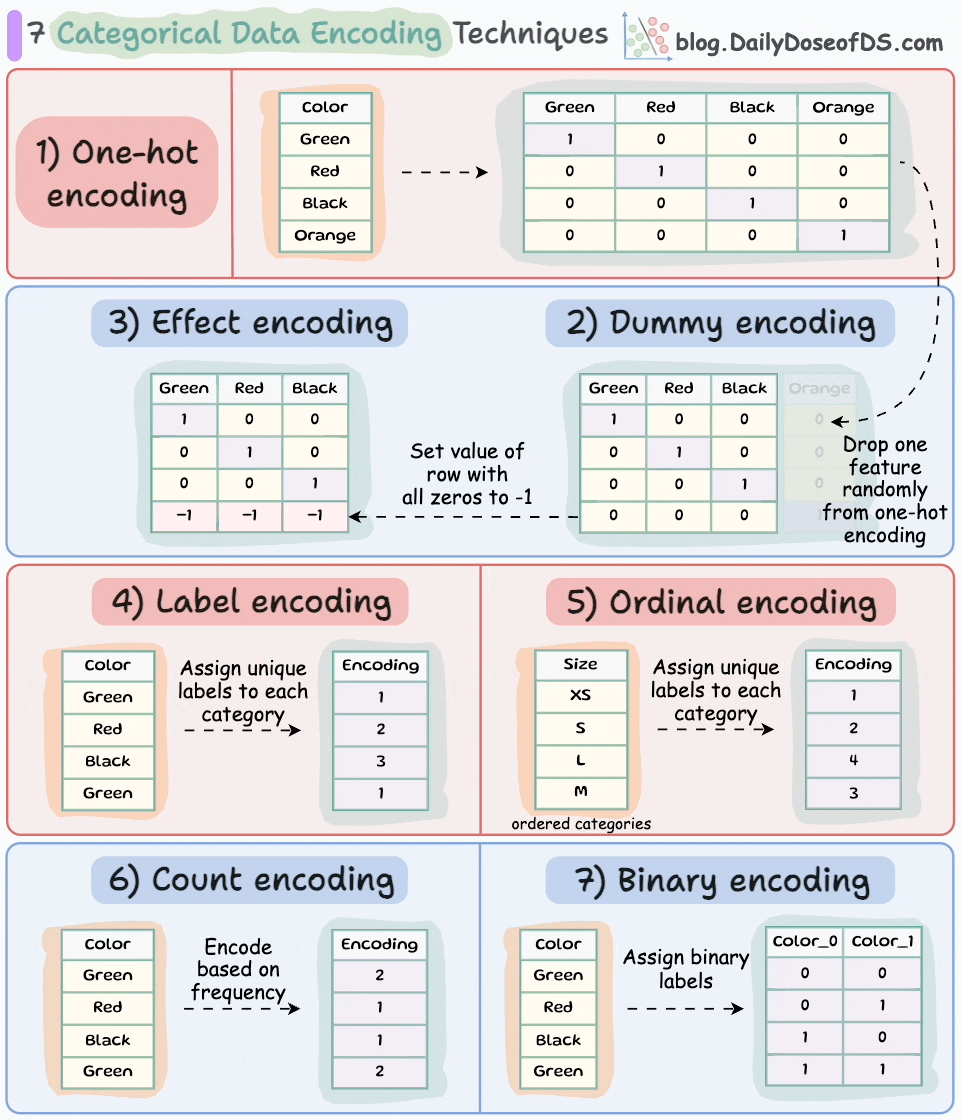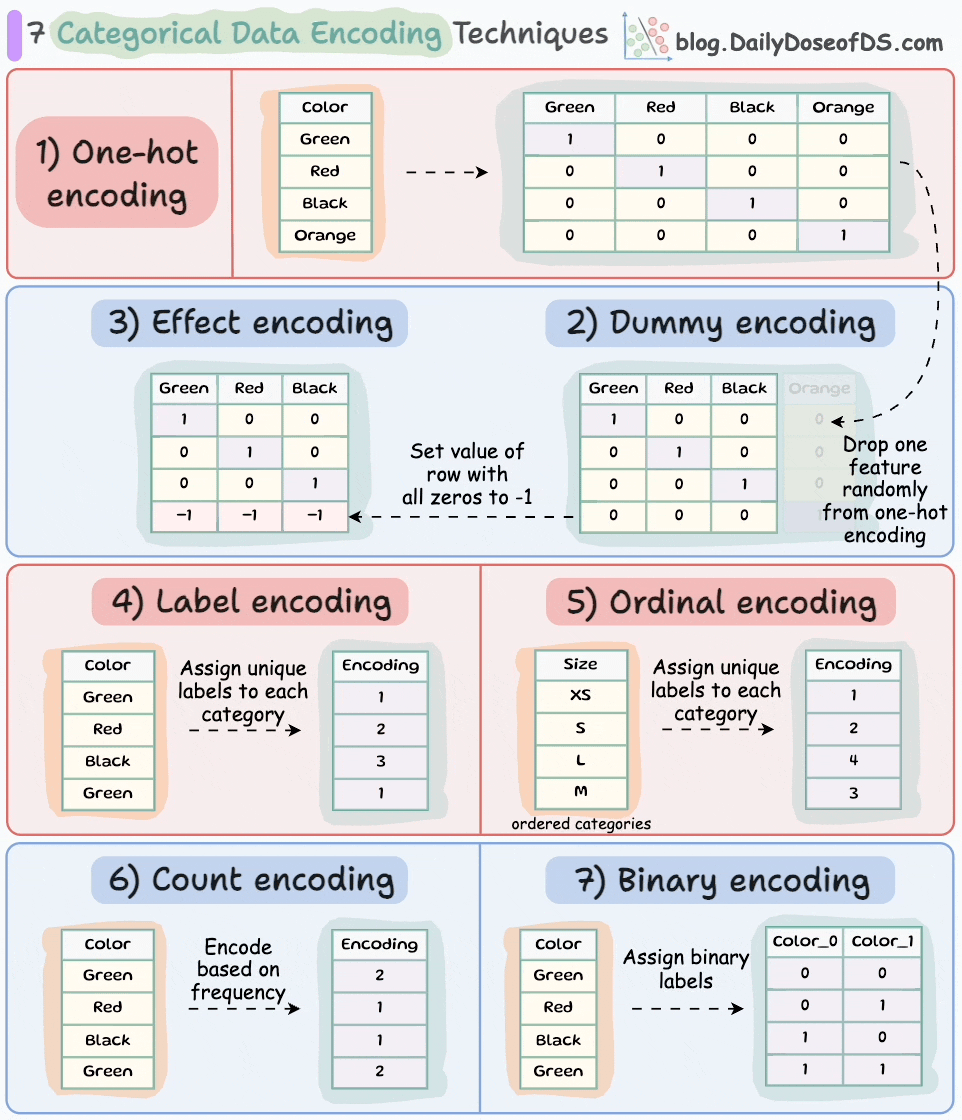
One-hot encoding:

Each category is represented by a binary vector of 0s and 1s.
Each category gets its own binary feature, and only one of them is "hot" (set to 1) at a time, indicating the presence of that category.
Number of features = Number of unique categorical labels

Dummy encoding:

Same as one-hot encoding but with one additional step.
After one-hot encoding, we drop a feature randomly.
This is done to avoid the dummy variable trap. We covered it here along with 8 more lesser-known pitfalls and cautionary measures that you will likely run into in your DS projects: 8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science.
Number of features = Number of unique categorical labels - 1.
Effect encoding:

Similar to dummy encoding but with one additional step.
Alter the row with all zeros to -1.
This ensures that the resulting binary features represent not only the presence or absence of specific categories but also the contrast between the reference category and the absence of any category.
Number of features = Number of unique categorical labels - 1.
Label encoding:

Assign each category a unique label.
Label encoding introduces an inherent ordering between categories, which may not be the case.
Number of features = 1.
Ordinal encoding:
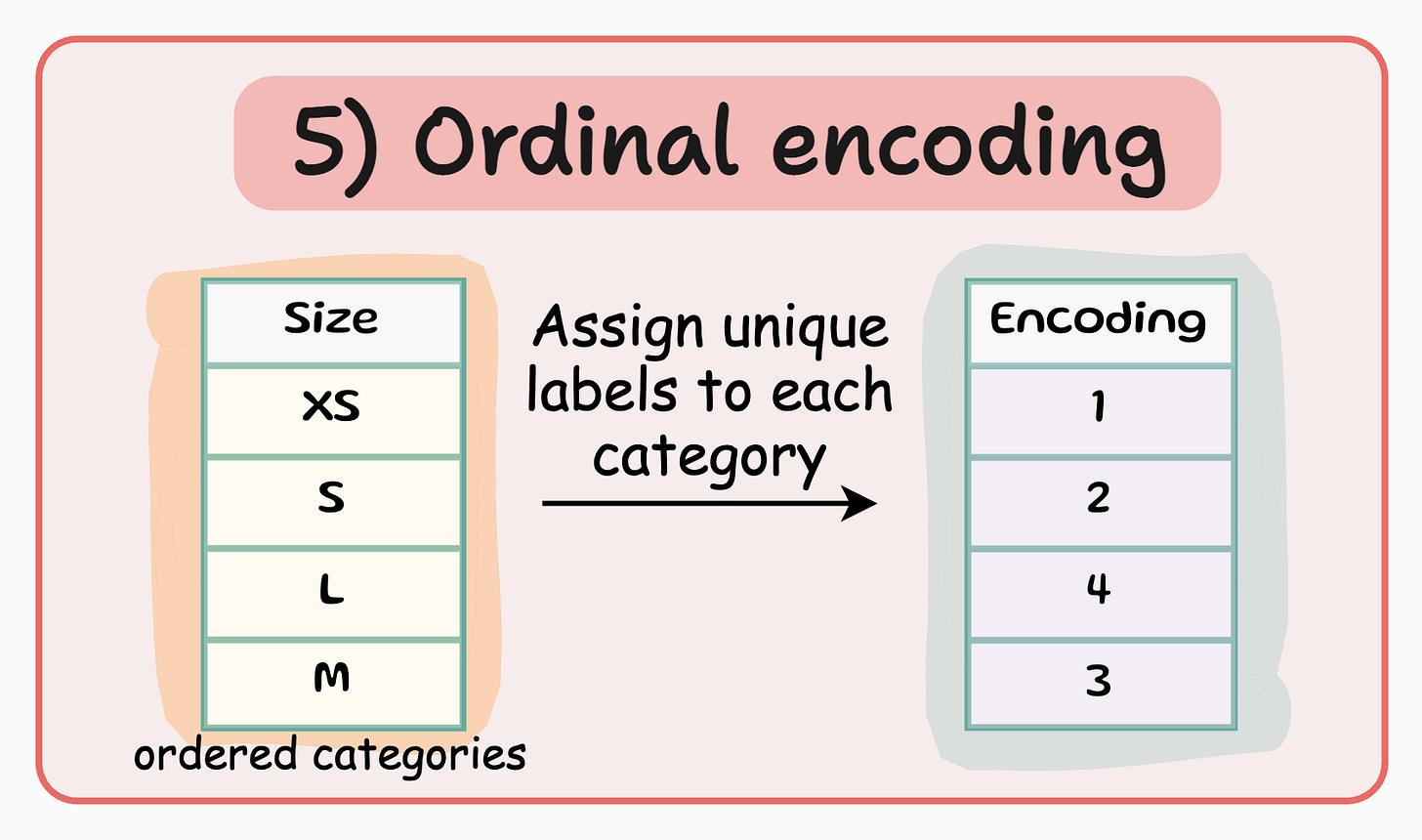
Similar to label encoding — assign a unique integer value to each category.
The assigned values have an inherent order, meaning that one category is considered greater or smaller than another.
Number of features = 1.
Count encoding:

Also known as frequency encoding.
Encodes categorical features based on the frequency of each category.
Thus, instead of replacing the categories with numerical values or binary representations, count encoding directly assigns each category with its corresponding count.
Number of features = 1.
Binary encoding:

Combination of one-hot encoding and ordinal encoding.
It represents categories as binary code.
Each category is first assigned an ordinal value, and then that value is converted to binary code.
The binary code is then split into separate binary features.
Useful when dealing with high-cardinality categorical features (or a high number of features) as it reduces the dimensionality compared to one-hot encoding.
Number of features = log(n) (in base 2).






While these are some of the most popular techniques, do note that these are not the only techniques for encoding categorical data.
You can try plenty of techniques with the category-encoders library.
👉 Over to you: What other common categorical data encoding techniques have I missed?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
Hi, first off, all thanks for your daily posts, but this post is the same as https://datasciencedojo.com/blog/categorical-data-encoding/ (this post is older than your post). if you cite the source. It will be useful for you. Good luck