
7 Must-know Techniques For Encoding Categorical Feature
...summarized in a single frame.


Almost all real-world datasets come with multiple types of features.
These primarily include:
Categorical
Numerical
While numerical features can be directly used in most ML models without any additional preprocessing, categorical features require encoding to be represented as numerical values.
On a side note, do you know that not all ML models need categorical feature encoding? Read one of my previous guides on this here: Is Categorical Feature Encoding Always Necessary Before Training ML Models?
If categorical features do need some additional processing, being aware of the common techniques to encode them is crucial.
Here are several common methods for encoding categorical features:
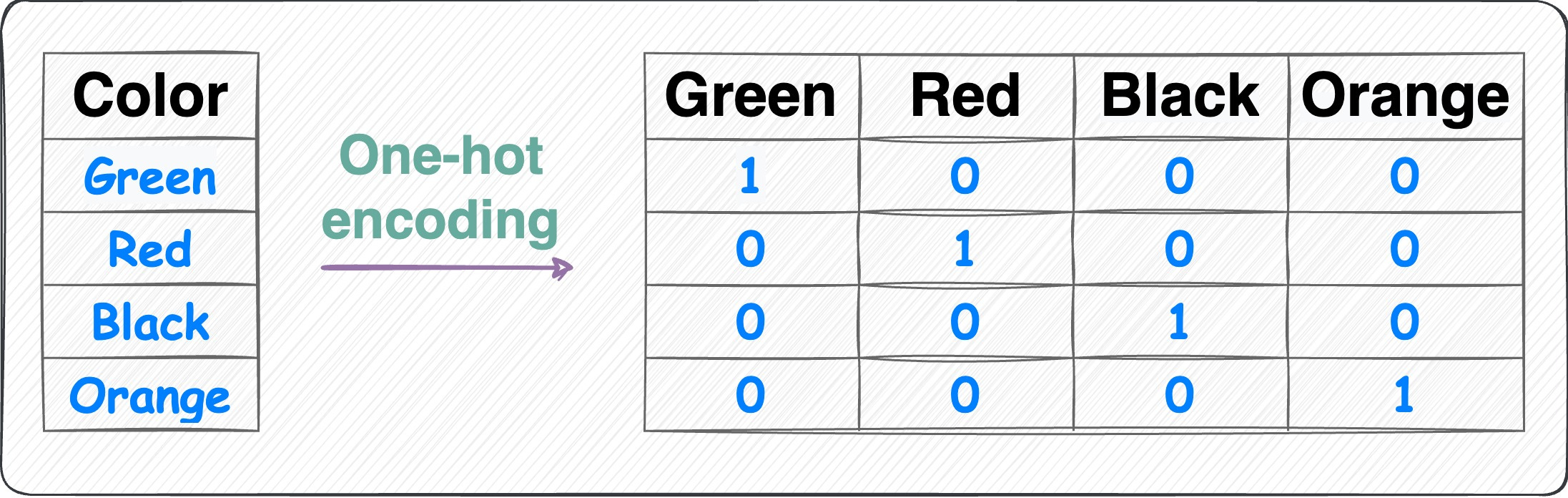
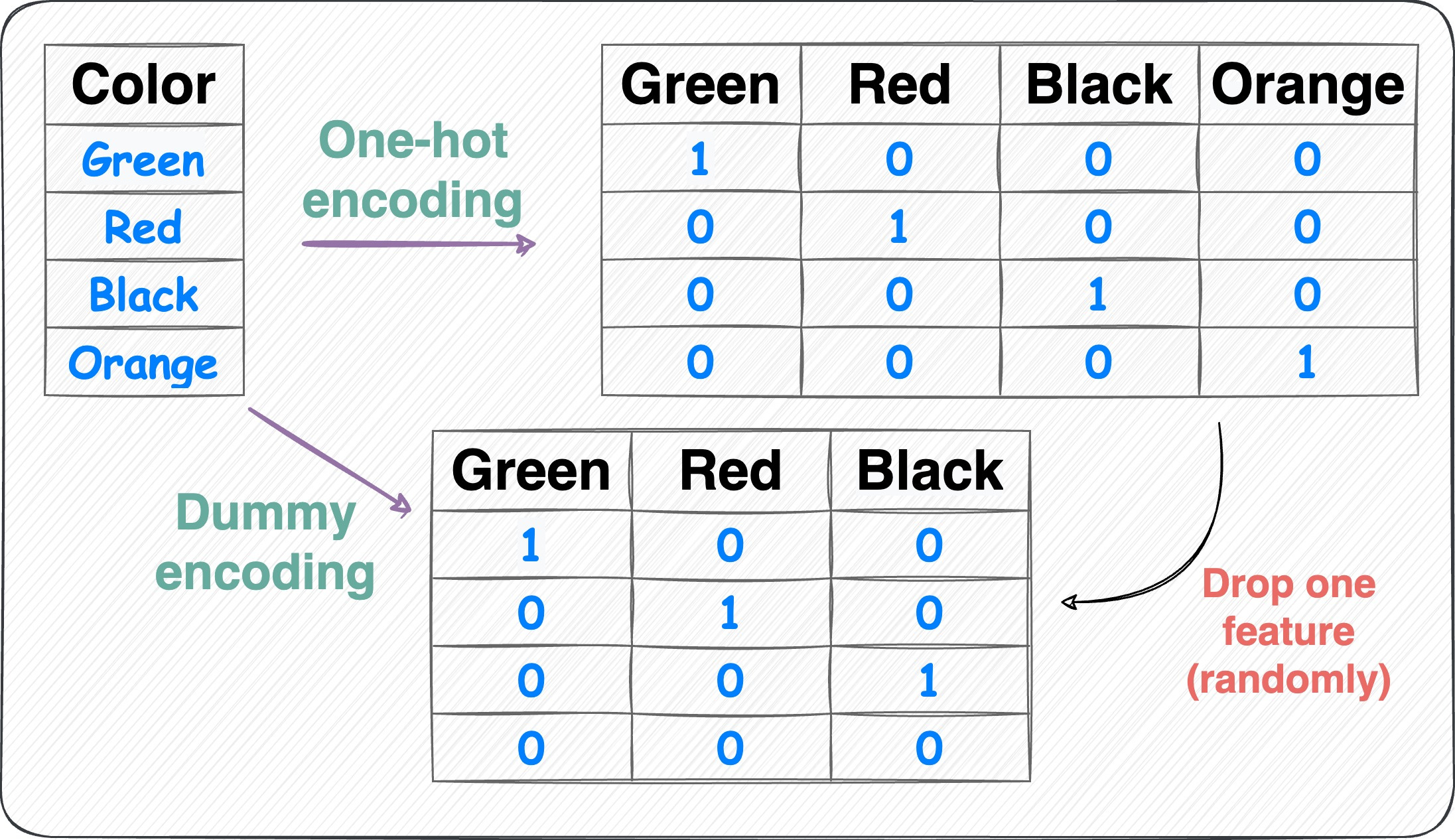
One-hot encoding:
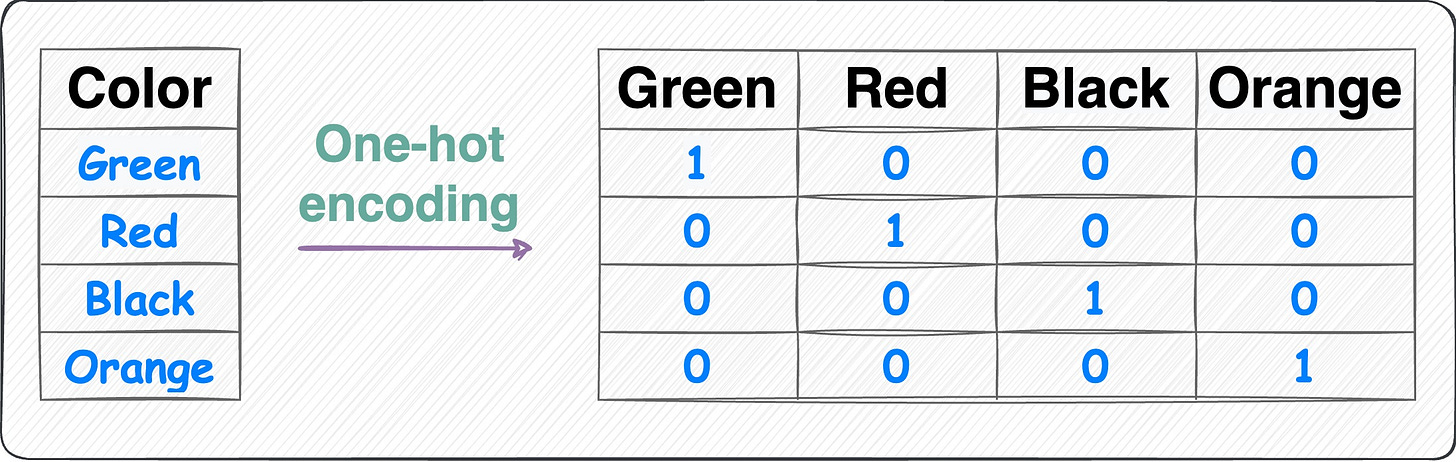
One-hot encoding Each category is represented by a binary vector of 0s and 1s.
Each category gets its own binary feature, and only one of them is "hot" (set to 1) at a time, indicating the presence of that category.
Number of features = Number of unique categorical labels.
Dummy encoding:
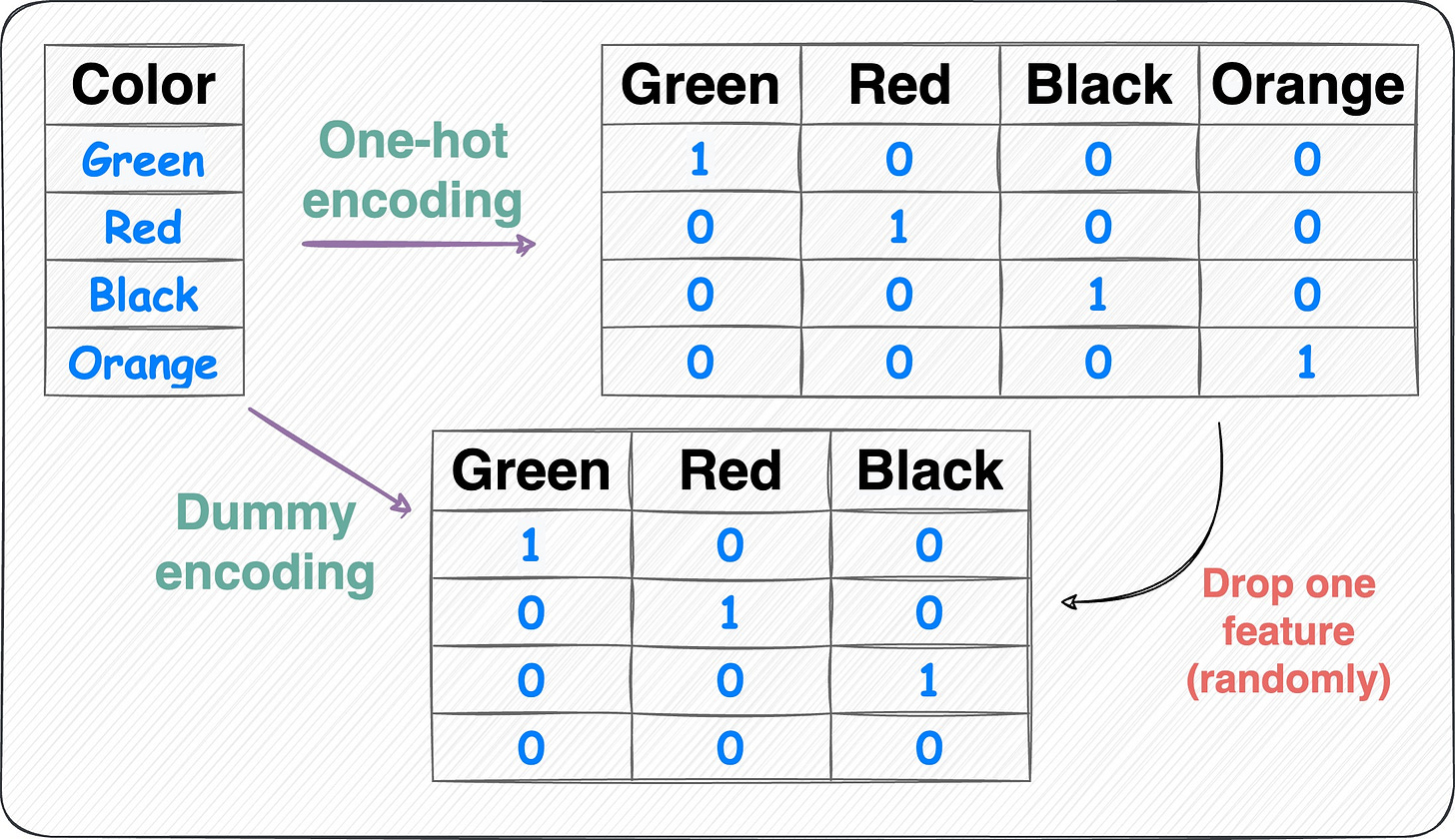
One-hot encoding to dummy encoding Same as one-hot encoding but with one additional step.
After one-hot encoding, we drop a feature randomly.
This is done to avoid the dummy variable trap. Here’s why we do it: The Most Overlooked Problem With One-Hot Encoding.
Number of features = Number of unique categorical labels - 1.
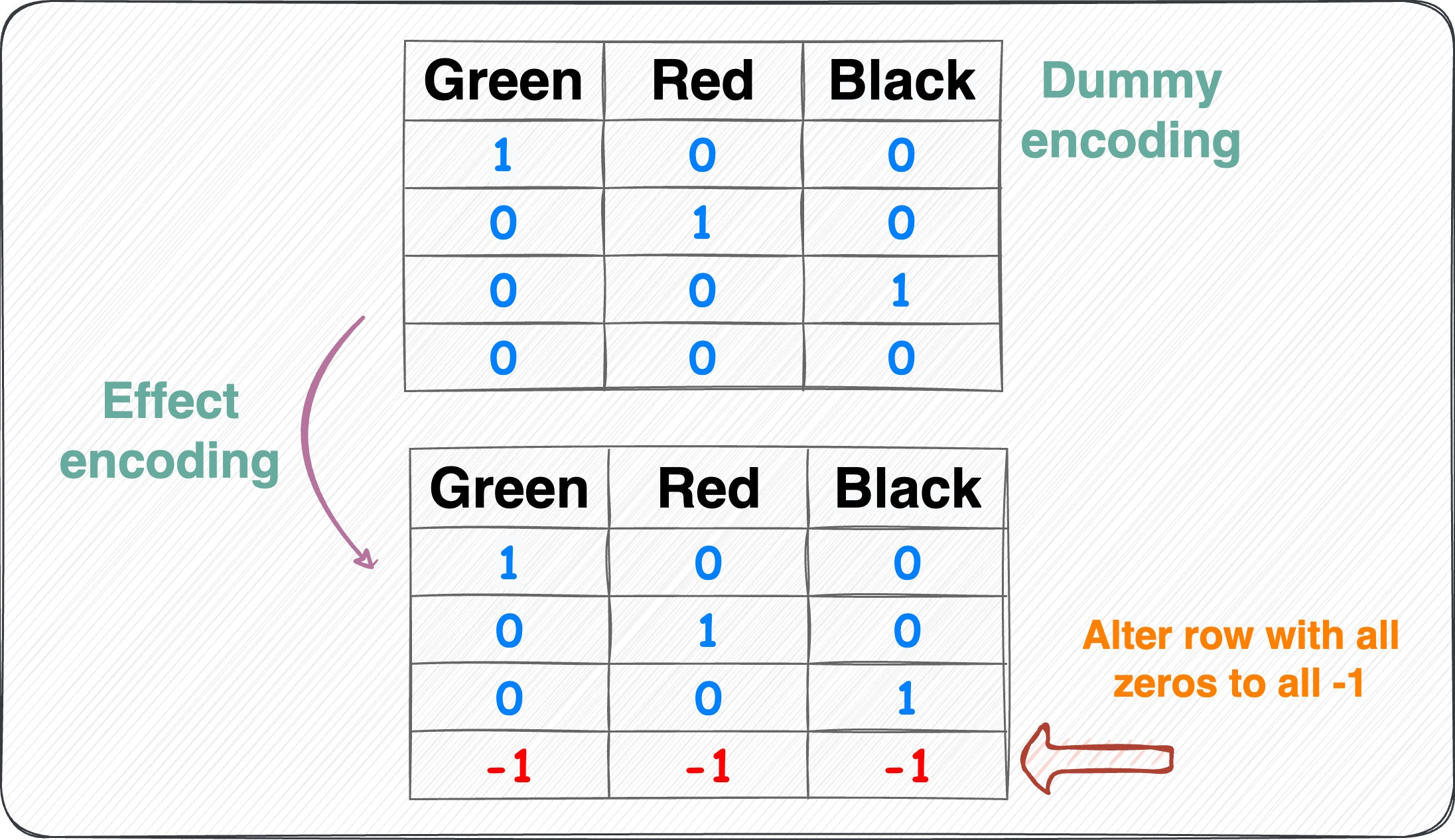
Effect encoding:
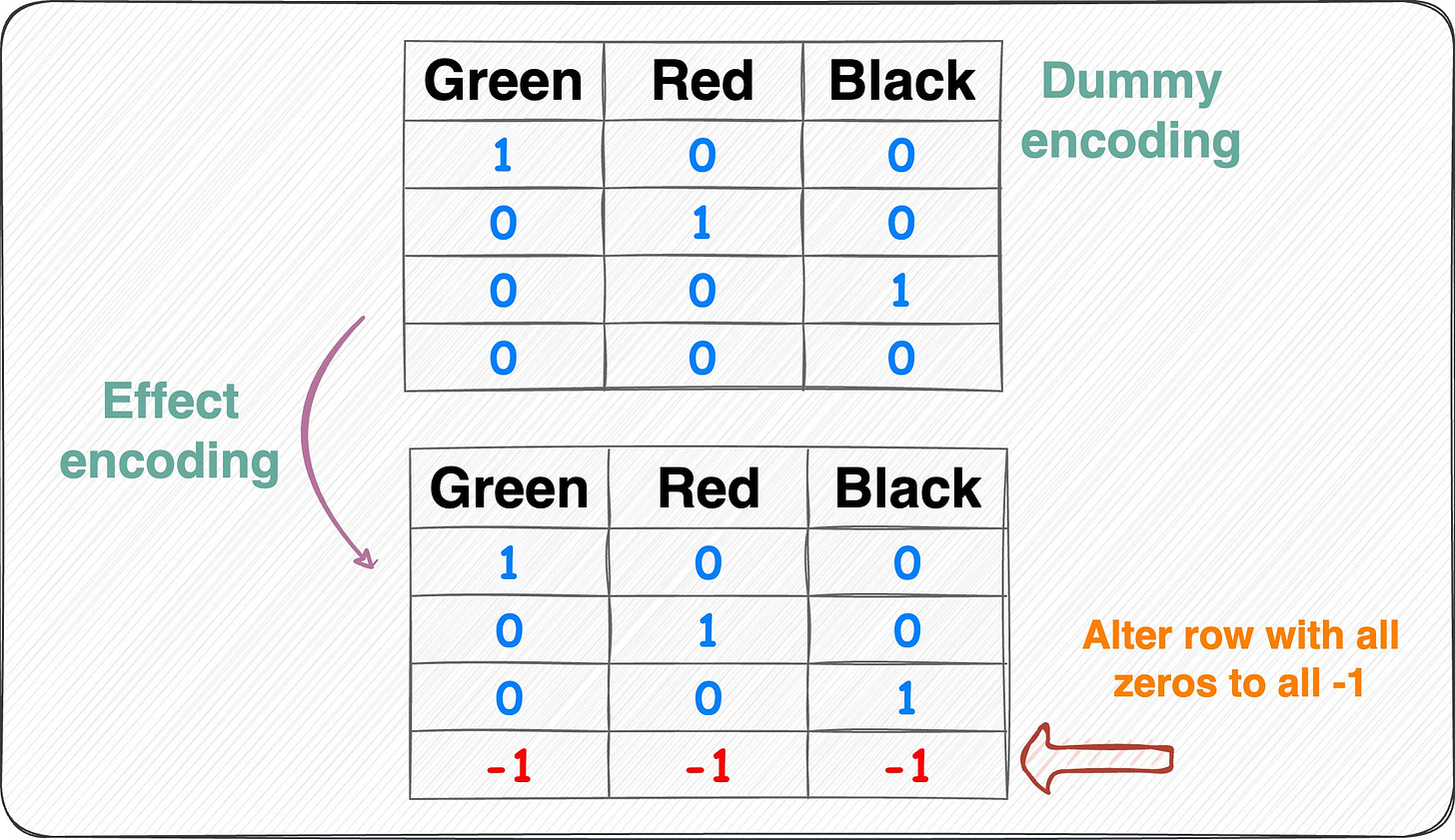
Dummy encoding to effect encoding Similar to dummy encoding but with one additional step.
Alter the row with all zeros to -1.
This ensures that the resulting binary features represent not only the presence or absence of specific categories but also the contrast between the reference category and the absence of any category.
Number of features = Number of unique categorical labels - 1.
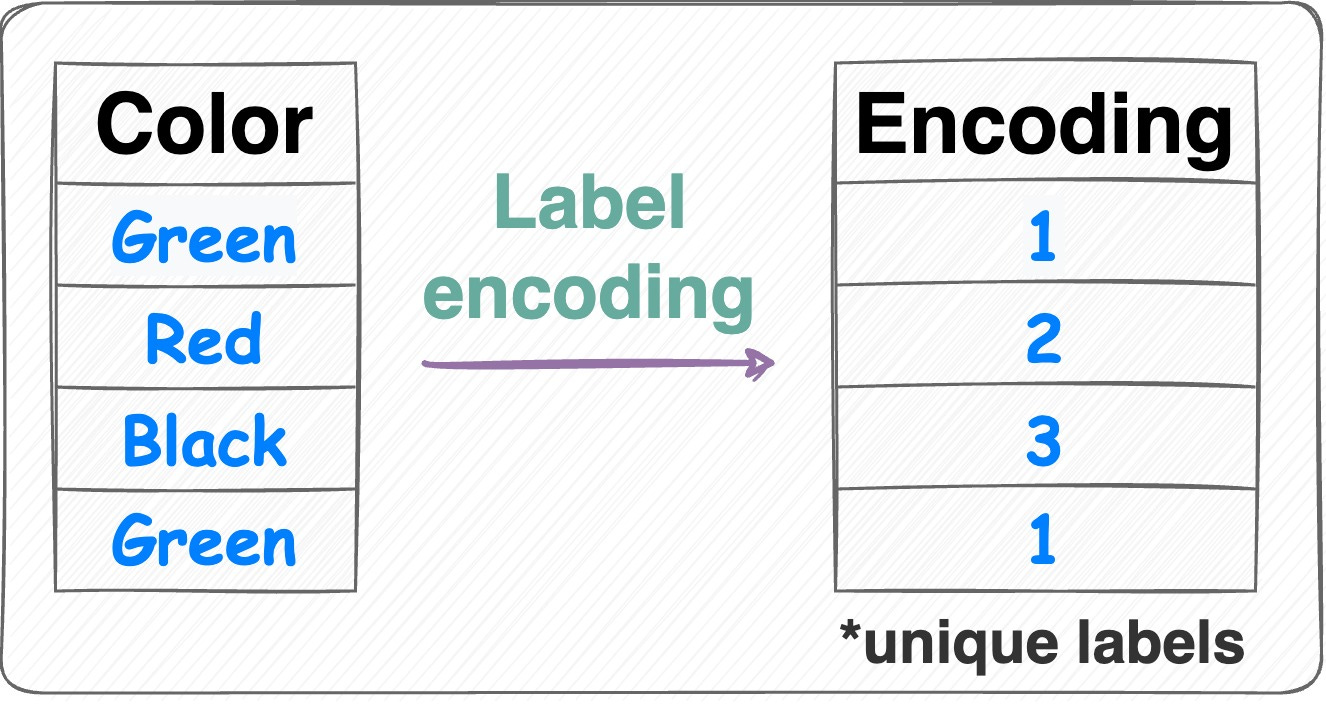
Label encoding:
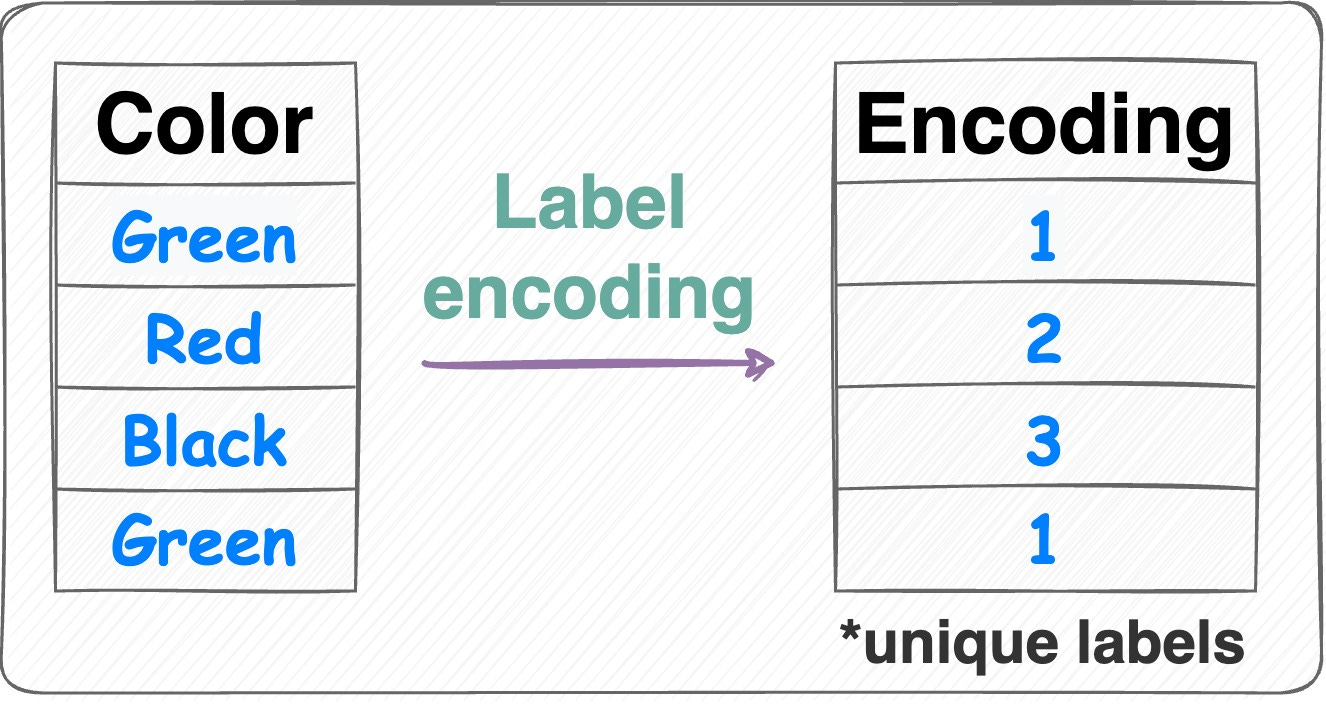
Label encoding Assign each category a unique label.
Label encoding introduces an inherent ordering between categories, which may not be the case.
Number of features = 1.
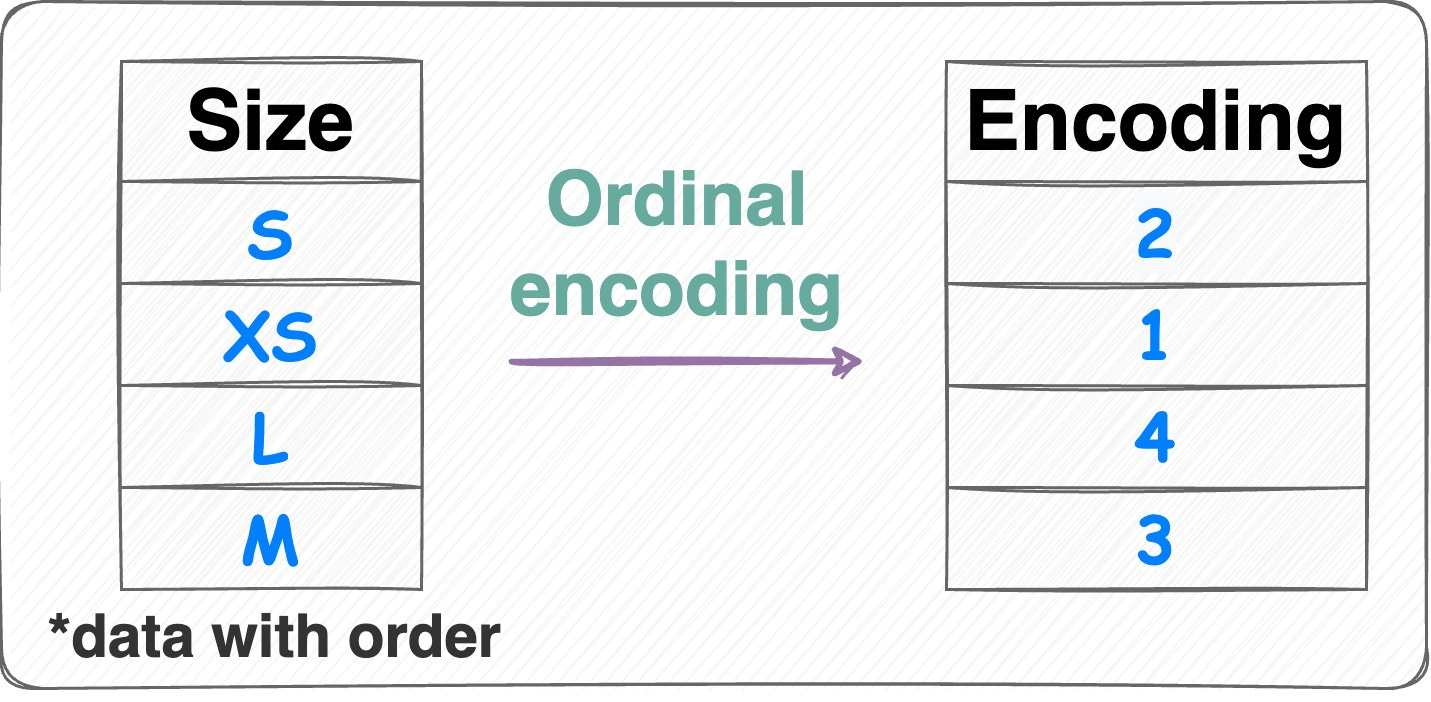
Ordinal encoding:
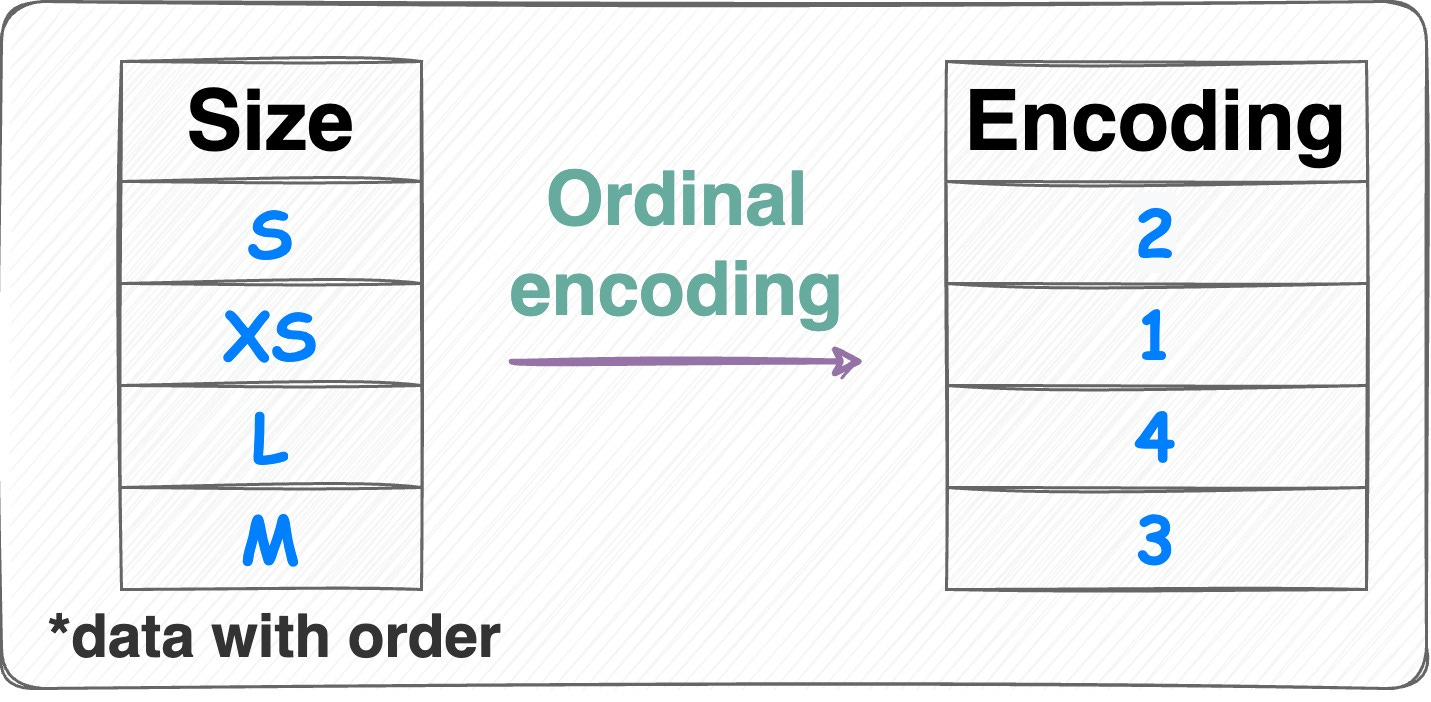
Ordinal encoding Similar to label encoding — assign a unique integer value to each category.
The assigned values have an inherent order, meaning that one category is considered greater or smaller than another.
Number of features = 1.
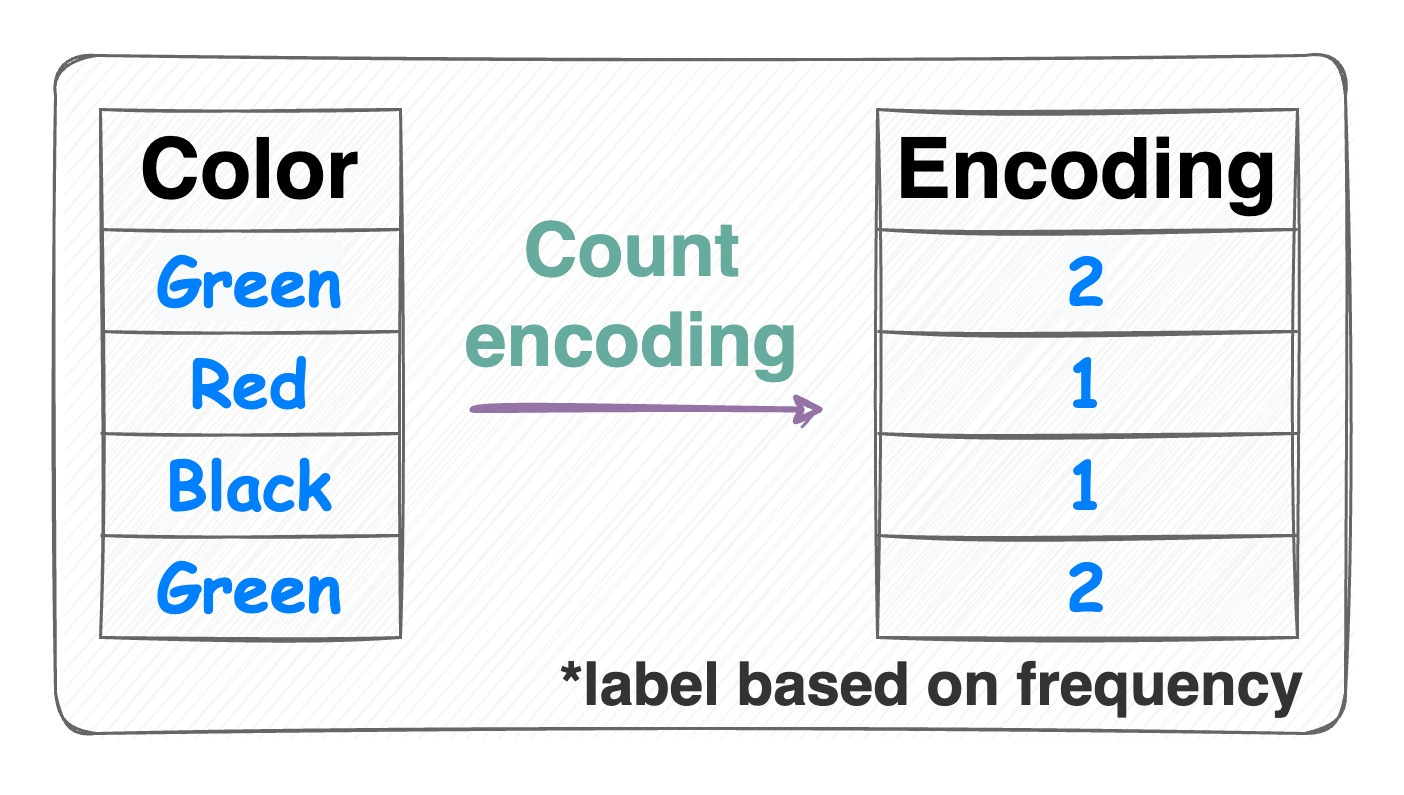
Count encoding:
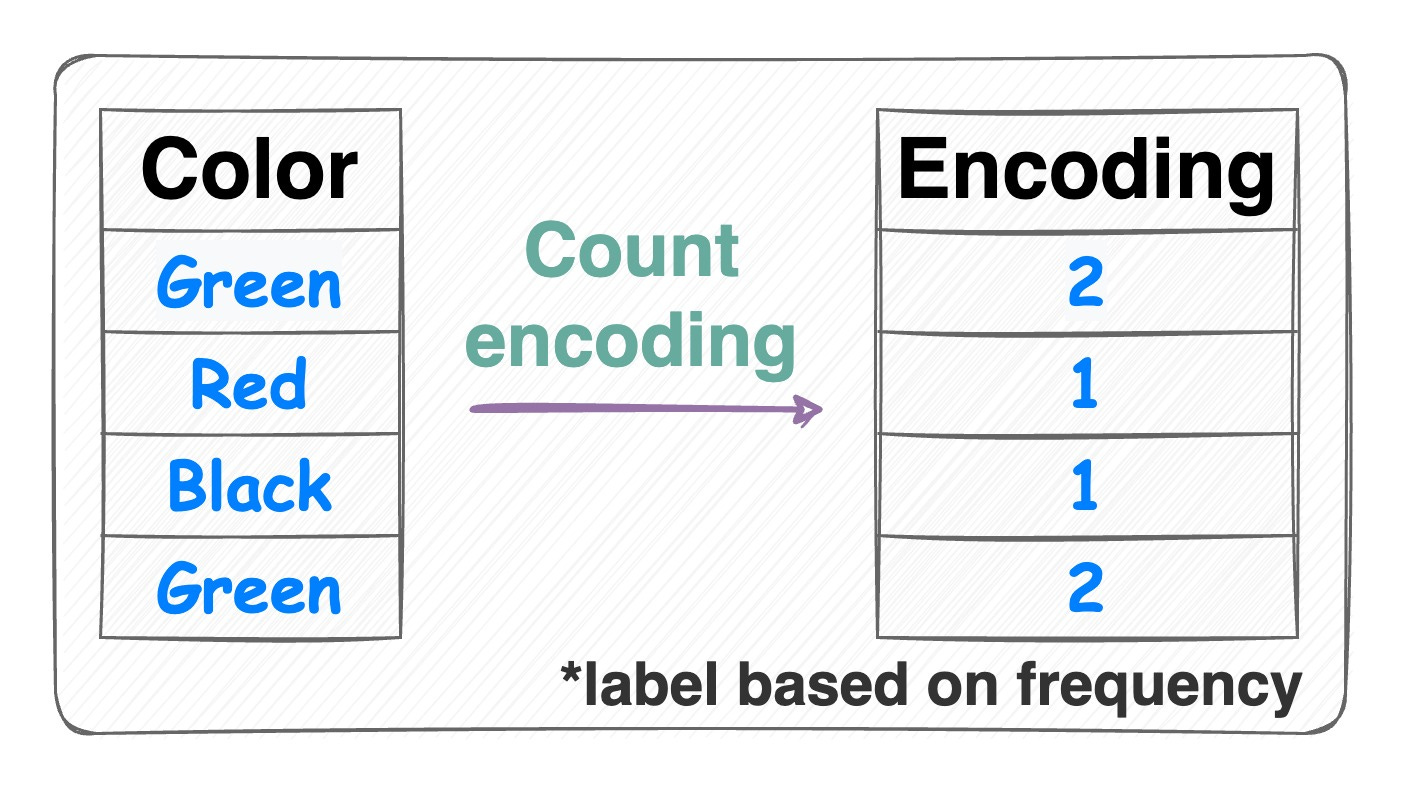
Count encoding Also known as frequency encoding.
Encodes categorical features based on the frequency of each category.
Thus, instead of replacing the categories with numerical values or binary representations, count encoding directly assigns each category with its corresponding count.
Number of features = 1.
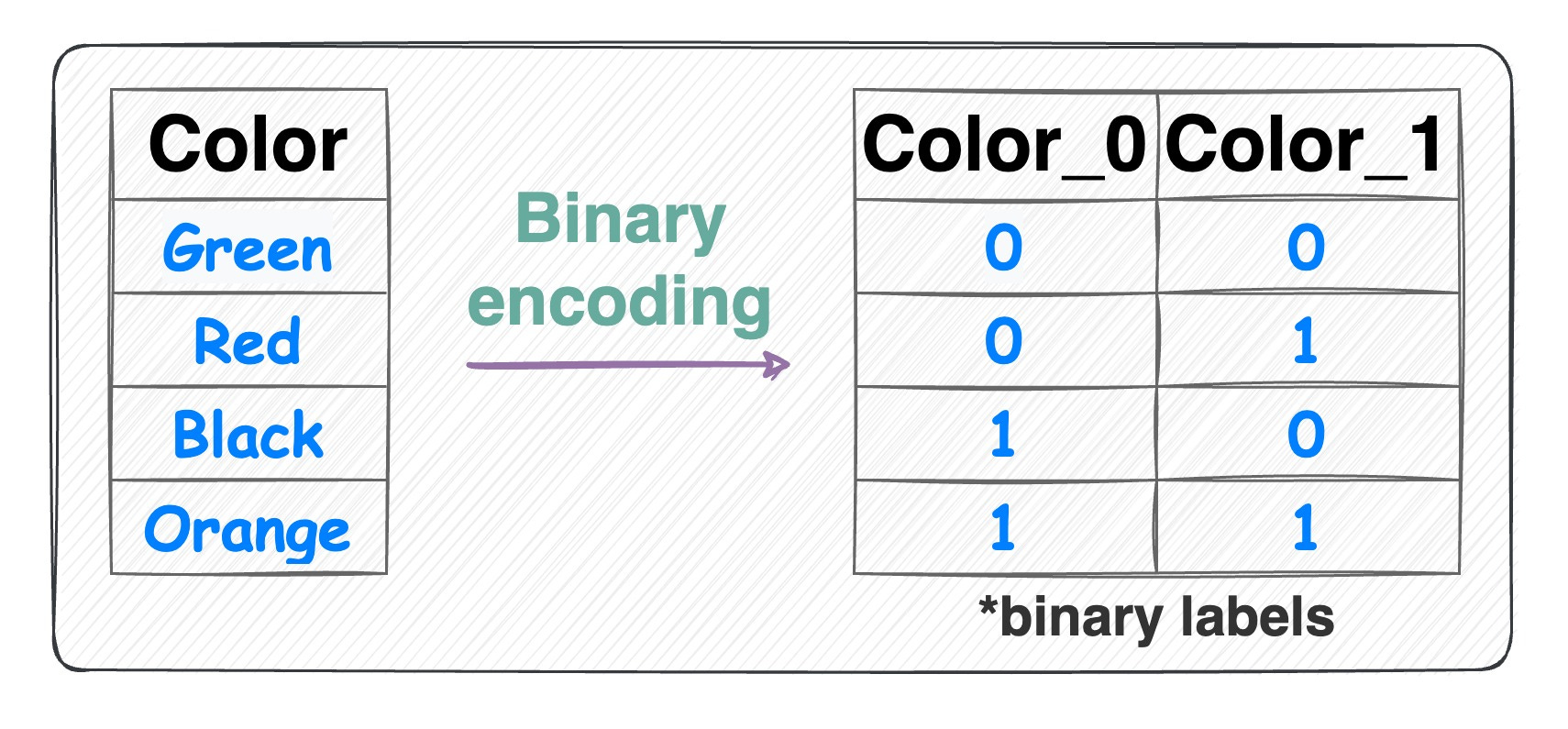
Binary encoding:
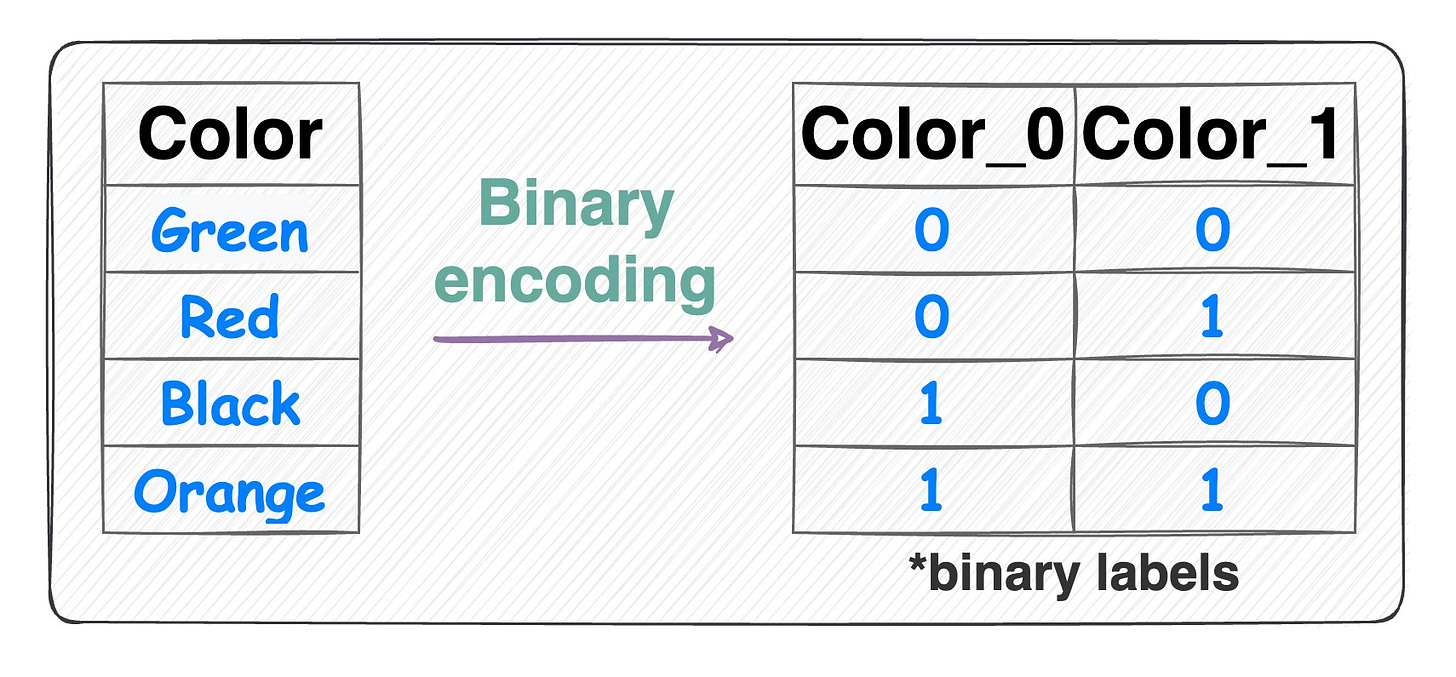
Binary encoding Combination of one-hot encoding and ordinal encoding.
It represents categories as binary code.
Each category is first assigned an ordinal value, and then that value is converted to binary code.
The binary code is then split into separate binary features.
Useful when dealing with high-cardinality categorical features (or a high number of features) as it reduces the dimensionality compared to one-hot encoding.
Number of features = log(n) (in base 2).
While these are some of the most popular techniques, do note that these are not the only techniques for encoding categorical data.
You can try plenty of techniques with the category-encoders library: Category Encoders.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
important techniques, thank you! bookmarked