
72 Techniques to Optimize LLMs in Production
...explained with usage.

Cut retrieval tokens by 3X and get better RAG accuracy too
Most RAG cost optimization happens at the model layer, like smaller models, fewer calls, and batching.
The retrieval payload itself rarely gets measured.

A typical setup retrieves 5 chunks per query, each around 300 tokens. That’s 1,500 input tokens before the LLM writes a single word, and at scale, that compounds.
But the bigger problem is accuracy. Enterprise documents repeat the same facts across multiple file versions.
When retrieved chunks say slightly different versions of the same thing, the LLM blends them. The answer sounds confident and is wrong in ways that are hard to catch.
Blockify (GitHub repo) sits between your raw docs and vector store.
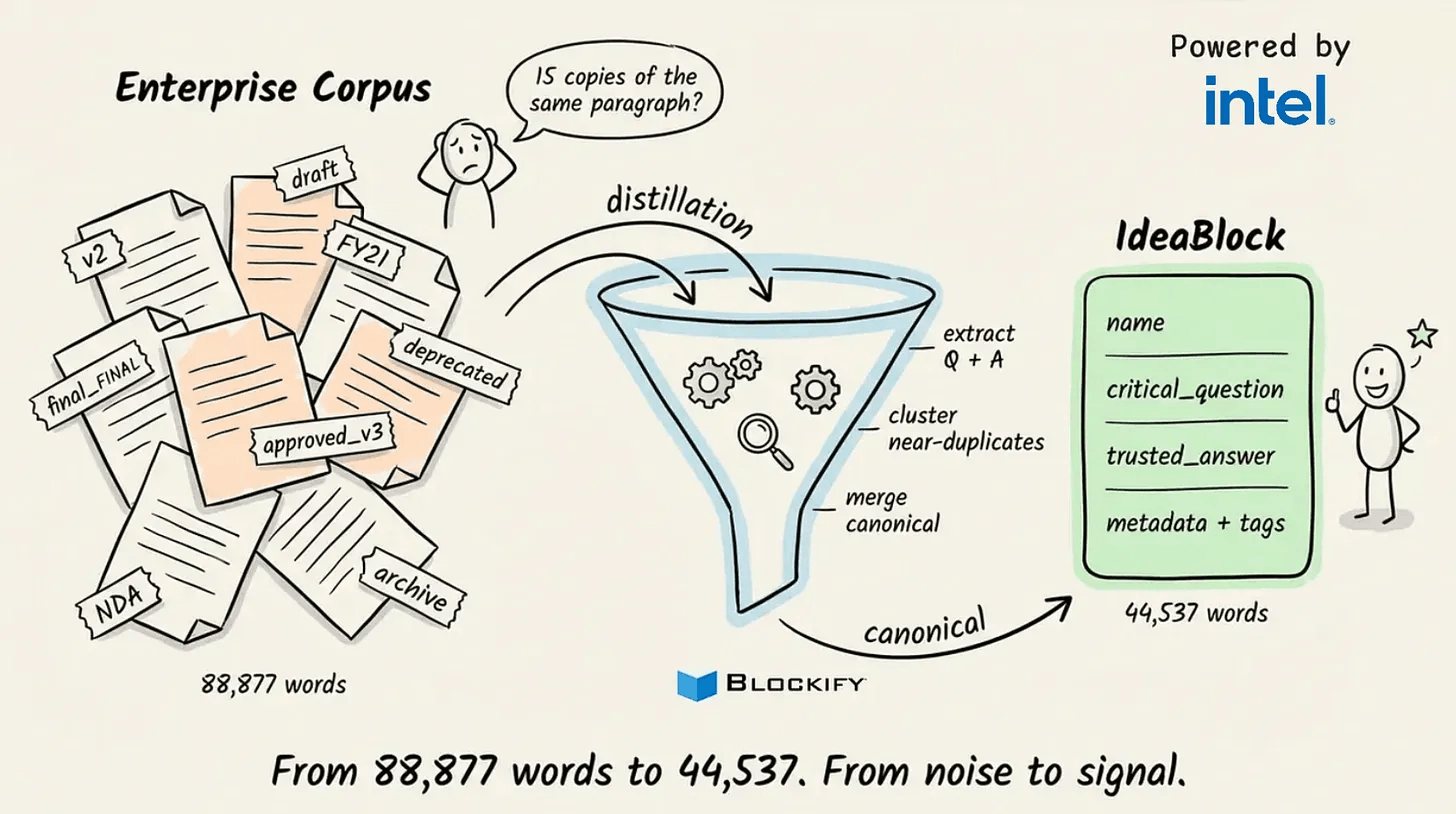
Instead of splitting text into raw chunks, it uses a fine-tuned LLM to generate small, structured knowledge units called IdeaBlocks, where each one is built around one question and one validated answer. Average size: 98 tokens.
It runs on Intel Xeon CPUs, so no GPU server is needed to get started.
On a published benchmark, the IdeaBlock index outperformed raw chunked indexing by 13.55% on vector accuracy, using the same source documents and embedding model.
The token count dropped 3.09X as a direct result of the smaller unit size.
The cost drops because the quality improved, not separately from it.
You can find the Blockify GitHub repo here →
72 techniques to optimize LLMs in production
On an H100 running Llama 70B, a single inference request hits 92% GPU compute utilization during prefill, then drops to 28% during decode on the same hardware a moment later. The workload changed, not the GPU.
For context:
Prefill processes the entire prompt in parallel and saturates tensor cores.
Decode generates one token at a time and reads the full KV cache from HBM at every step, which makes it memory-bandwidth bound.
This asymmetry is why a single optimization never gets you very far, and why LLM inference prices have still fallen roughly 10x per year, with GPT-4-level performance going from $20 per million tokens in late 2022 to around $0.40 today.
Most of that drop came from the serving stack, and we put together this visual, which lists the techniques that go into optimizing LLMs in production.

Every technique in the grid above is a response to one of three bottlenecks: prefill compute, decode memory bandwidth, or the cost of everything that wraps the model.
Stacking enough of these techniques closes the 5-8x cost-efficiency gap between optimized vLLM or TensorRT-LLM deployments and naive FP16 inference.
Today, let’s walk through the nine layers, what each one actually solves, and how they stack up in a real production deployment.
We covered a lot more in the LLMOps course with implementations and engineering logic.
1. Model compression

Model weights live in GPU memory all the time.
A 70B model in FP16 is 140GB before you load a single token of context. Compression attacks this usage directly.
INT8 halves the memory vs FP16.
INT4 cuts it 4x.
FP8 gives you native tensor core support on Hopper and Blackwell, which means compression plus speedup.
GPTQ, AWQ, and SmoothQuant are the three main algorithms here.
GPTQ uses Hessian-based second-order information
AWQ preserves salient weights based on activation magnitudes,
SmoothQuant handles both weights and activations at W8A8.
Distillation and pruning attack the parameter count itself rather than the bits per parameter.
Multi-LoRA serving is the escape hatch for multi-tenant deployments, where you keep one base model in memory and hot-swap small adapter weights per request.
We covered this specific pillar in
2. Attention and architecture
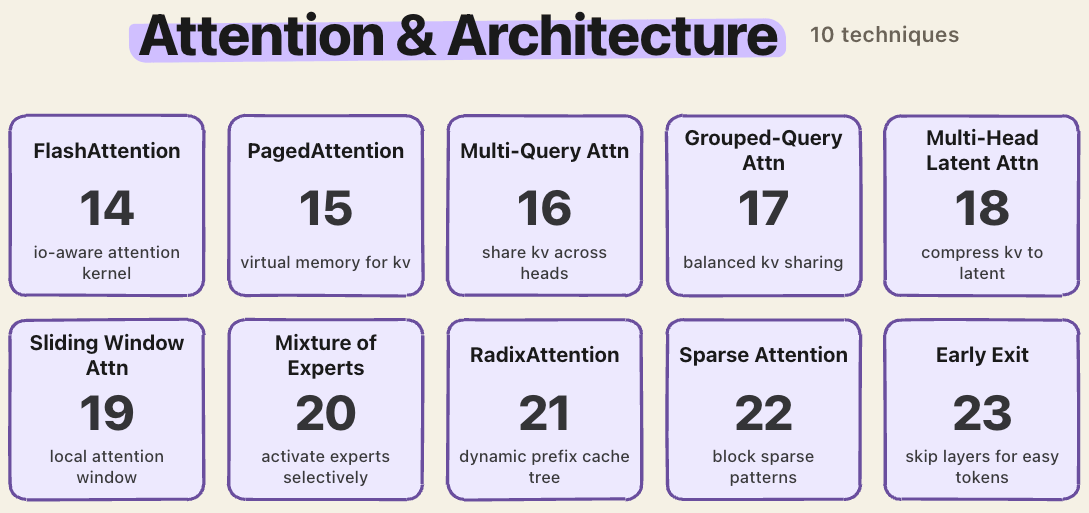
Standard attention is O(N²). At 128K context, this will have 16 billion computations, which is why naive attention is infeasible at long context even on H100-class hardware.
FlashAttention reorders the attention math to be IO-aware, avoiding materializing the full N×N matrix.
PagedAttention applies OS-style virtual memory to the KV cache, eliminating fragmentation.
MQA, GQA, and MLA attack the number of KV heads.
MQA shares one KV head across all queries, GQA groups them, MLA compresses keys and values into a low-rank latent. DeepSeek-V2 reported a 93.3% KV cache reduction from MLA alone.
Sliding window attention restricts each token to a local window. MoE activates only a subset of experts per token. These are architectural choices driven entirely by serving economics.
We covered this specific pillar in:
3. Decoding

Decode is memory-bound because every new token requires a full pass over the weights and KV cache.
Speculative decoding sidesteps this by generating a draft with a cheap model, then verifying in parallel with the main model.
Medusa attaches extra prediction heads to the model itself, so the same model can draft its own candidate tokens without needing a separate smaller model.
EAGLE improves on this by predicting at the hidden-state level rather than the token level, which gives higher draft accuracy and better speedups.
Lookahead decoding skips the draft model entirely. It generates and verifies multiple tokens in parallel from the main model alone.
Prompt lookup decoding copies spans directly from the input prompt, which is surprisingly effective for tasks with heavy prompt-output overlap like summarization or code edits.
Constrained decoding enforces grammars at the token level, which is how providers guarantee valid JSON.
Multi-token prediction trains the model to emit several tokens per forward pass.
We covered this specific pillar in:
4. KV cache

The KV cache grows linearly with context length, and for long conversations, it dominates memory (learn KV caching here)
A 70B model with 4K context per request already consumes several gigabytes of KV just for a modest batch size.
Prefix caching reuses KV across requests sharing the same prefix, which is why system prompts and few-shot examples are effectively free after the first request.
KV offload tiers cold cache entries to CPU RAM or NVMe.
KV cache quantization compresses the cache itself, separate from the weights.
Token eviction methods like H2O and SnapKV drop low-attention tokens from the cache. SnapKV reports 92% KV compression at a 1024-token budget with a 3.6x decode speedup.
Attention sinks, from the StreamingLLM paper, keep the first few tokens permanently in the cache to prevent long-context generation from going incoherent past the cache limit.
Chunked prefill splits long prompts into smaller pieces so decode steps can interleave with prefill work.
We covered this specific pillar in:
5. Batching and scheduling

LLM inference is memory-bandwidth bound during decode, which means the GPU is usually starved. Batching more requests together amortizes memory reads across more useful work.
Continuous batching does this at the iteration level. As soon as one request finishes generating, a new one takes its slot mid-flight.
Dynamic batching waits for a short window to group arriving requests. Batching 32 requests together cuts per-token cost roughly 85% with minor latency impact.
Prefill-decode disaggregation splits the two phases onto separate GPU pools. Perplexity, Meta, and Mistral run this in production because co-locating prefill and decode on the same GPU means decode requests freeze every time a new prefill enters the batch.
SLO-aware scheduling prioritizes interactive traffic over background jobs.
Spot GPU scheduling runs preemptible workloads on cheap capacity.
Request deduplication merges identical in-flight queries.
We covered this specific pillar in:
6. Parallelism and kernels

Tensor parallelism splits weight matrices across GPUs.
Pipeline parallelism splits layers.
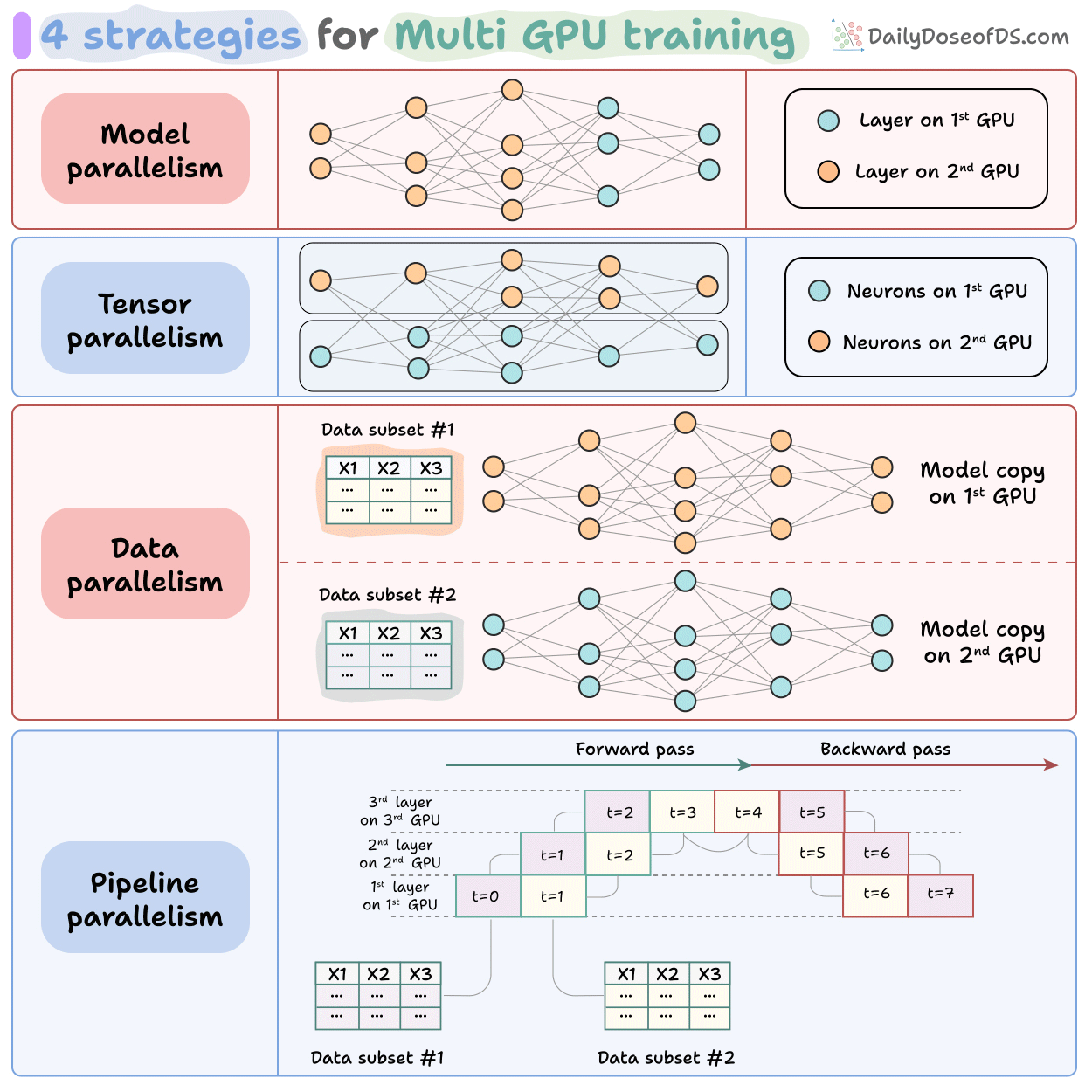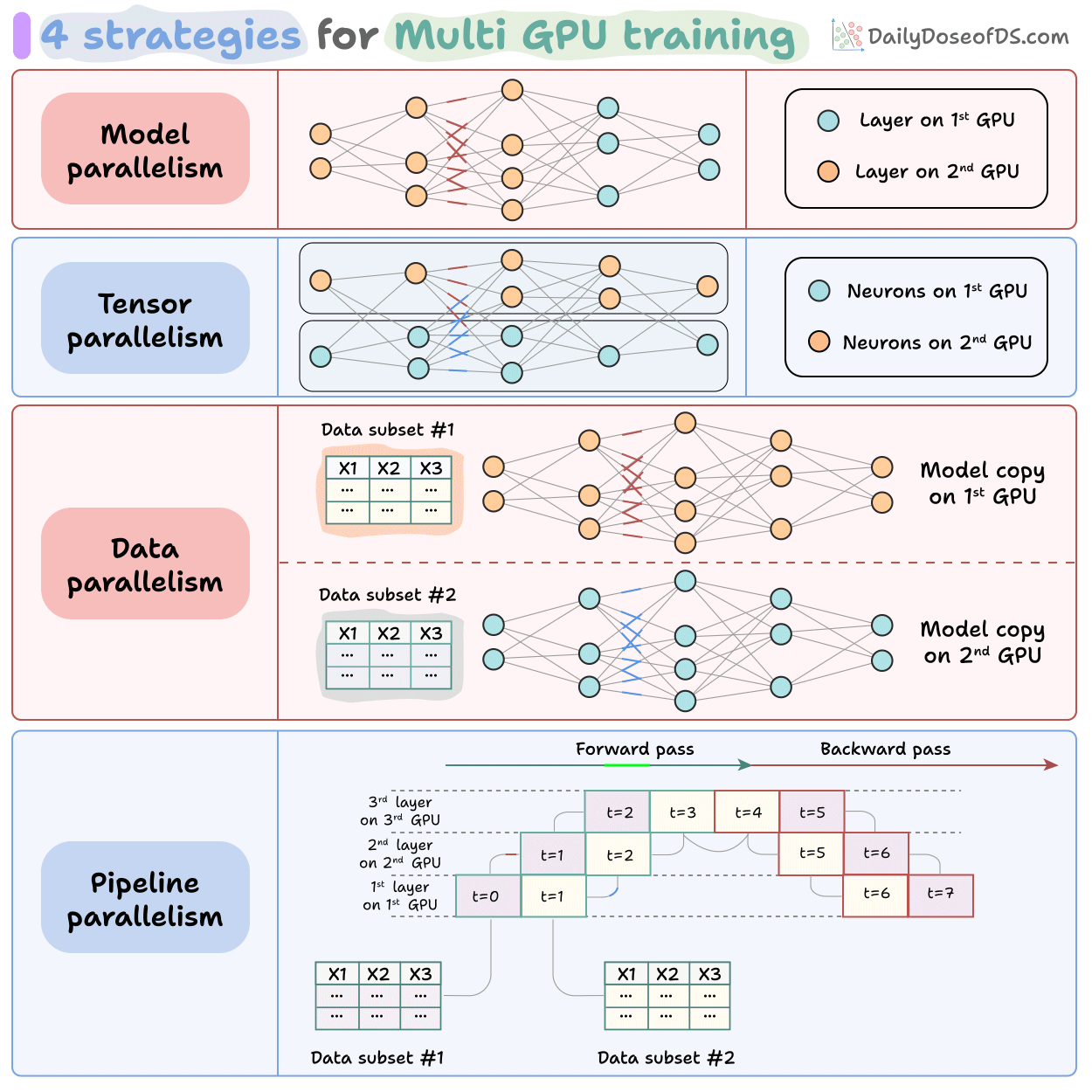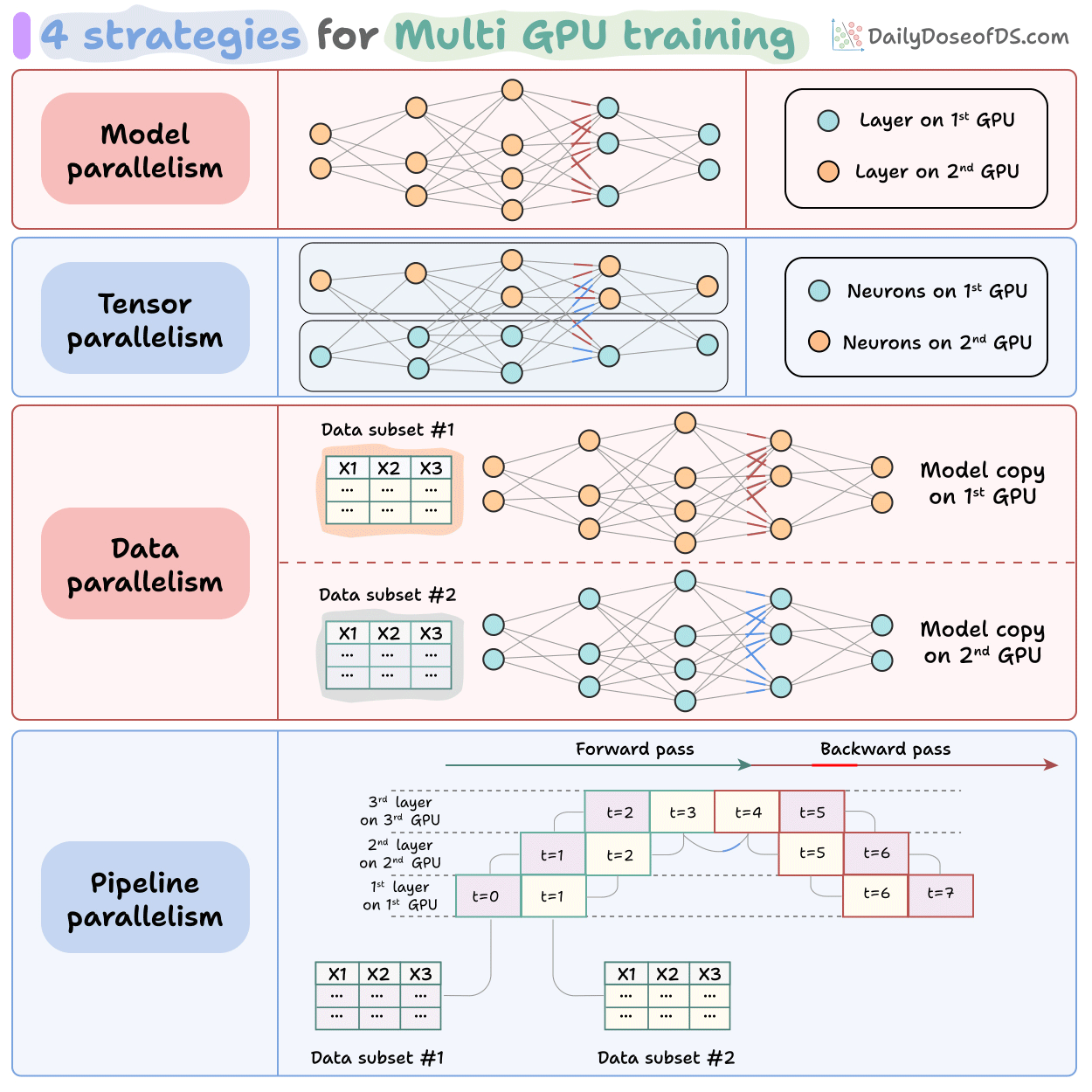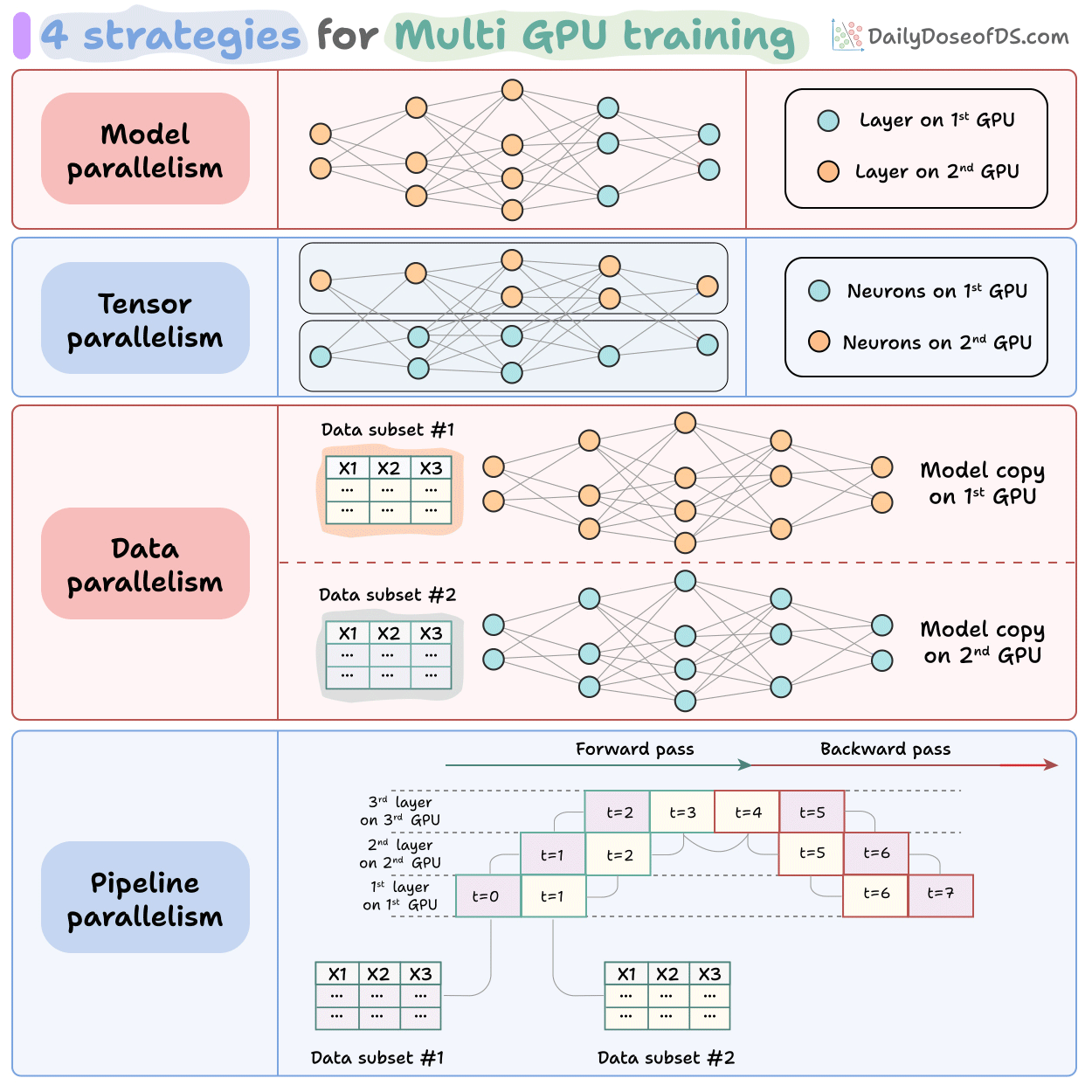
Expert parallelism shards MoE experts across devices.
Sequence parallelism splits along the token dimension.
CUDA graphs reduce kernel launch overhead, which matters because decode launches thousands of tiny kernels per second.
Kernel fusion combines multiple operations into one launch.
Torch compile produces fused kernels automatically via graph-level compilation.
We covered this specific pillar in:
7. Application caching
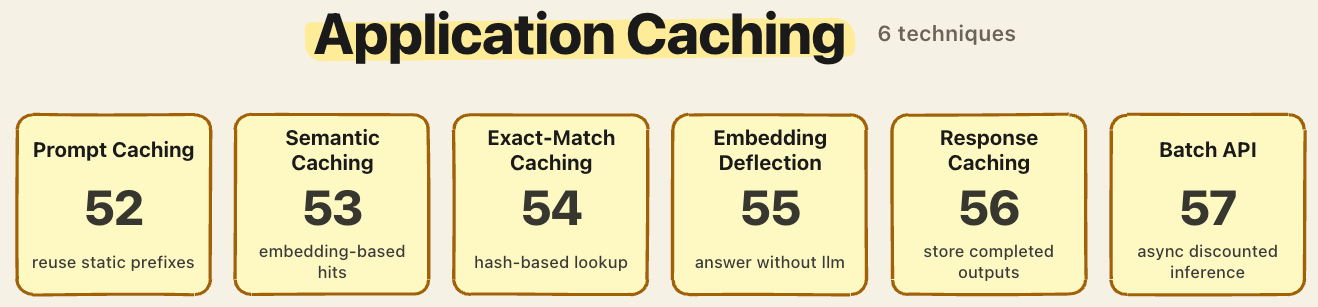
The cheapest inference is the one you skip.
Prompt caching reuses the KV state of static prefixes across calls. Anthropic reports up to 90% cost reduction and 85% latency reduction for long cached prompts.
Semantic caching matches queries by embedding similarity rather than exact string match, which handles paraphrases.
Exact-match caching is the hash-based baseline.
Response caching stores completed outputs.
Embedding deflection routes simple queries to a vector search without ever calling the LLM.
Batch API endpoints run async jobs at roughly half the per-token price for non-realtime workloads
We covered this specific pillar in:
8. Input/output shaping
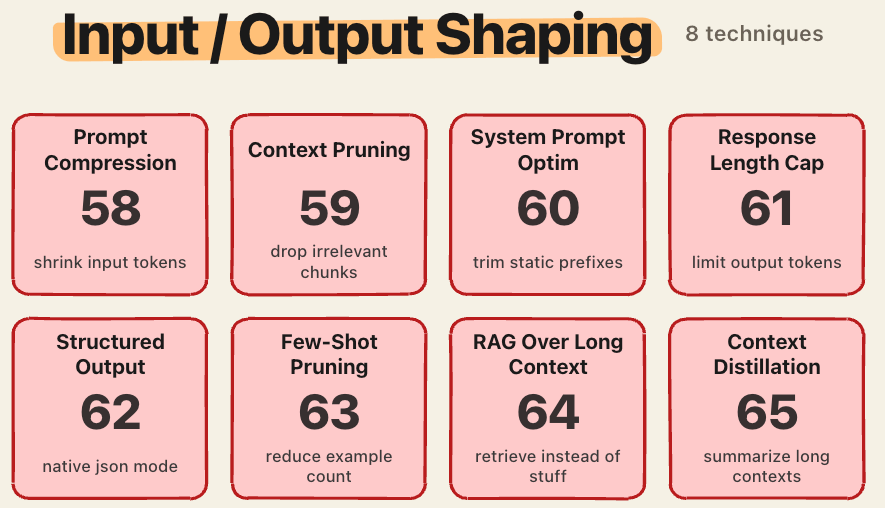
Output tokens cost 3-10x more than input tokens across every major provider.
Claude Sonnet 4 is $3 per million input versus $15 per million output, so trimming either side of the call translates directly into margin.
Prompt compression with tools like LLMLingua achieves up to 20x compression with minimal quality loss.
Context pruning drops irrelevant retrieved chunks before they reach the model.
System prompt optimization trims static prefixes that bloat every request.
Response length caps, structured output modes, and few-shot pruning all attack output volume.
Context distillation summarizes long histories into a shorter state.
RAG over long context is often cheaper than stuffing everything into the window. Retrieval keeps the prefill bill bounded.
We covered this specific pillar in:
9. Routing and cost

Not every query needs a frontier model.
Model routing picks a smaller model when a smaller model suffices.
Model cascading runs a cheap model first and escalates to a larger one only when confidence is low. Advisor strategy is somewhat similar to this:
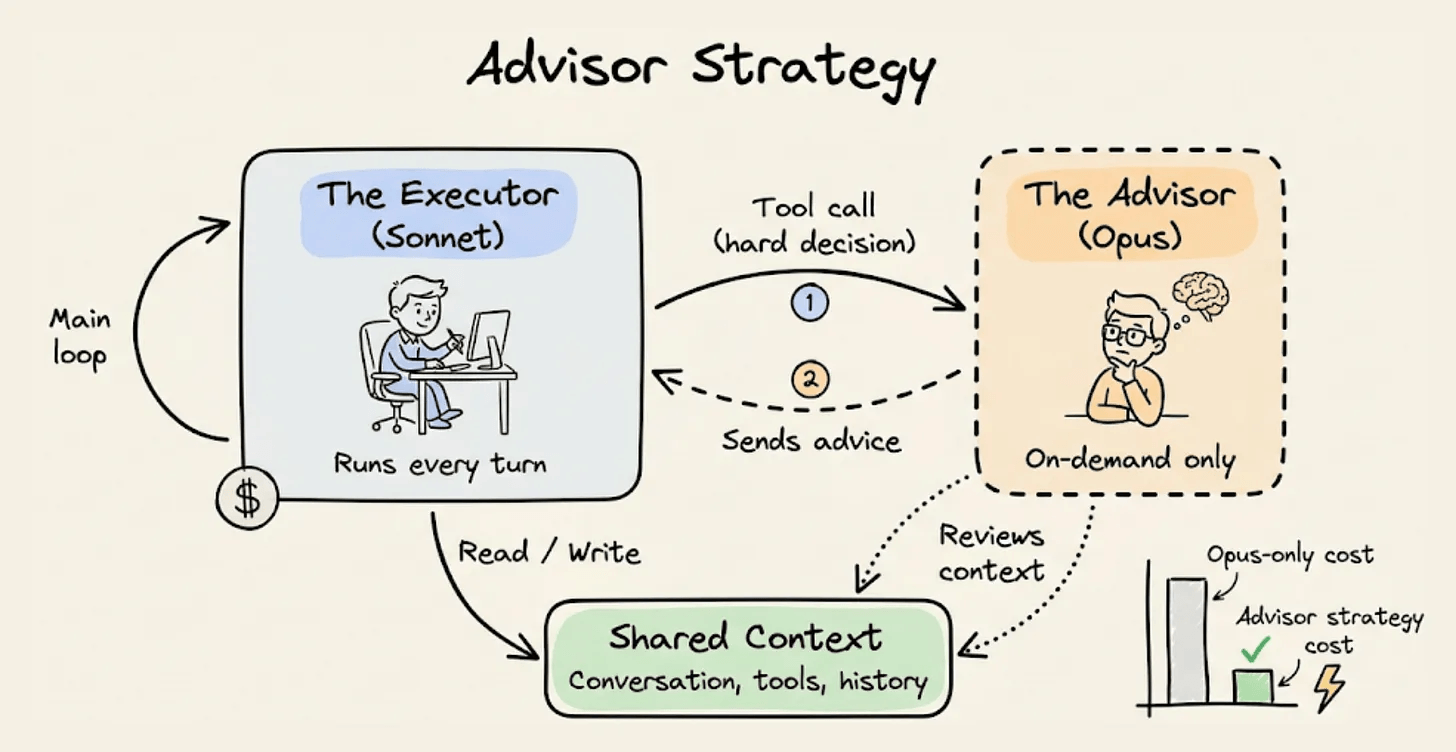
Classifier routing learns which queries go where.
Multi-provider failover routes across APIs for reliability and cost.
QoS tiers separate fast-and-cheap traffic from slow-and-high-quality.
Task-specific fine-tuning lets a 7B model match a 70B model on a narrow domain.
Function calling offloads deterministic logic to tools so the model doesn’t spend tokens computing what code could.
We covered this specific pillar in:
Putting it together
A serious production stack touches most of these.
A reasonable setup for a general-purpose API might run FP8 weights, GQA-based attention with FlashAttention kernels, PagedAttention for KV, continuous batching with prefill-decode disaggregation, prefix caching for system prompts, semantic caching at the application layer, prompt compression for long retrieved contexts, and model routing to send trivial queries to a small model.
The gap between this stack and a naive FP16 deployment with static batching is 5-8x on cost-per-token, and each technique alone moves the number only a small amount, which is exactly why the compounding across all nine layers is what defines a serious production setup.
We covered a lot more in the LLMOps course with implementations and engineering logic.
You can start reading it here →
Thanks for reading!