
8 AI Model Architectures, Visually Explained!
must-know for AI engineers!

Get RAG-ready data from any unstructured doc!
Real-world documents are complex for LLMs to process directly.
Tensorlake transforms unstructured docs into LLM-ready data in just a few lines of code, as shown below:
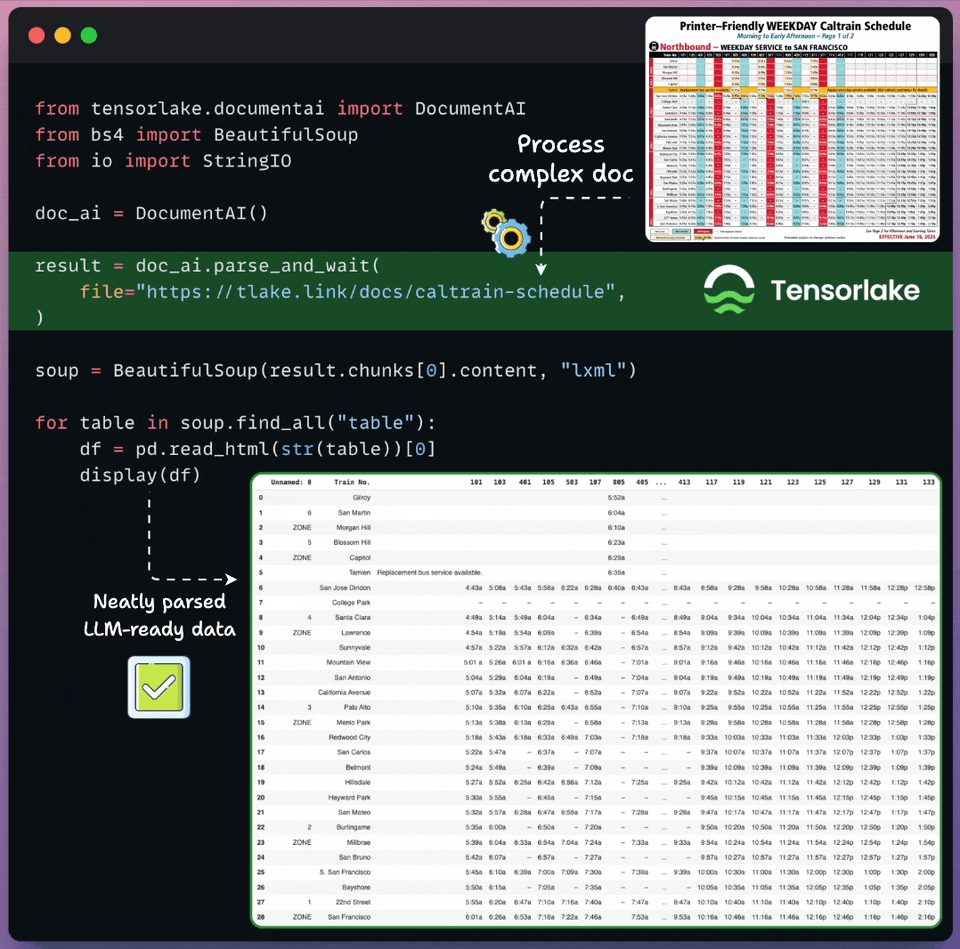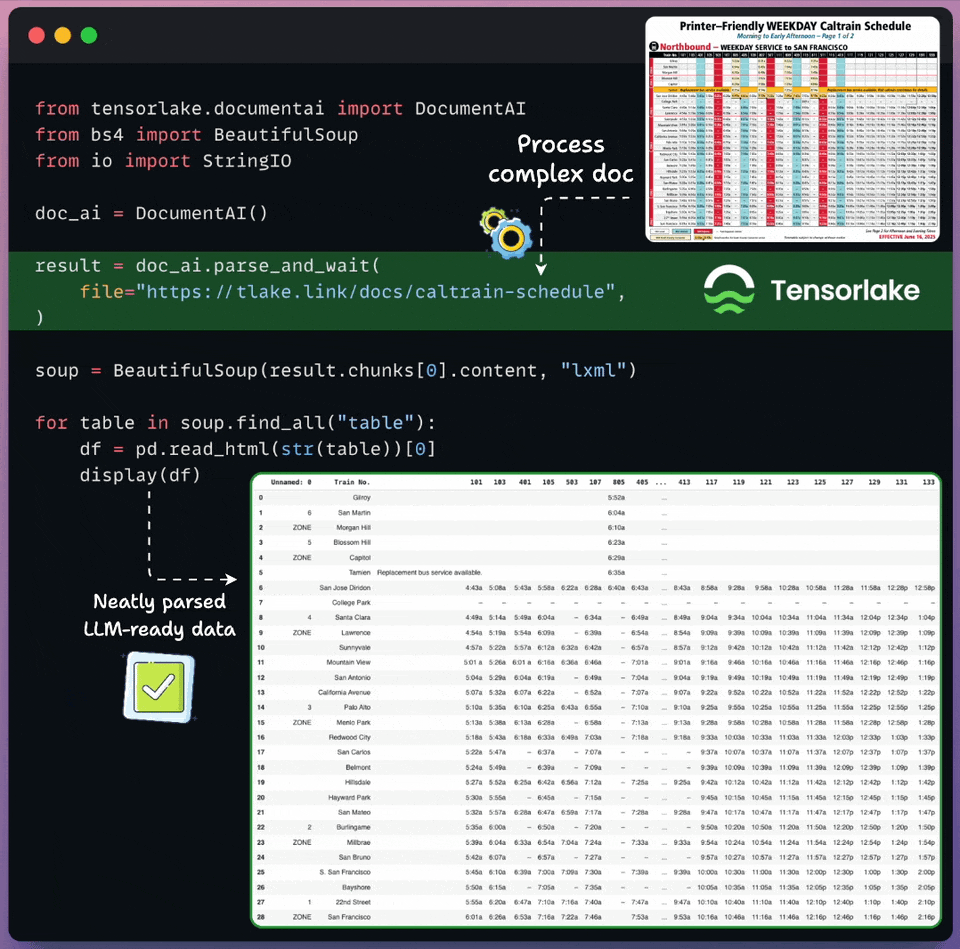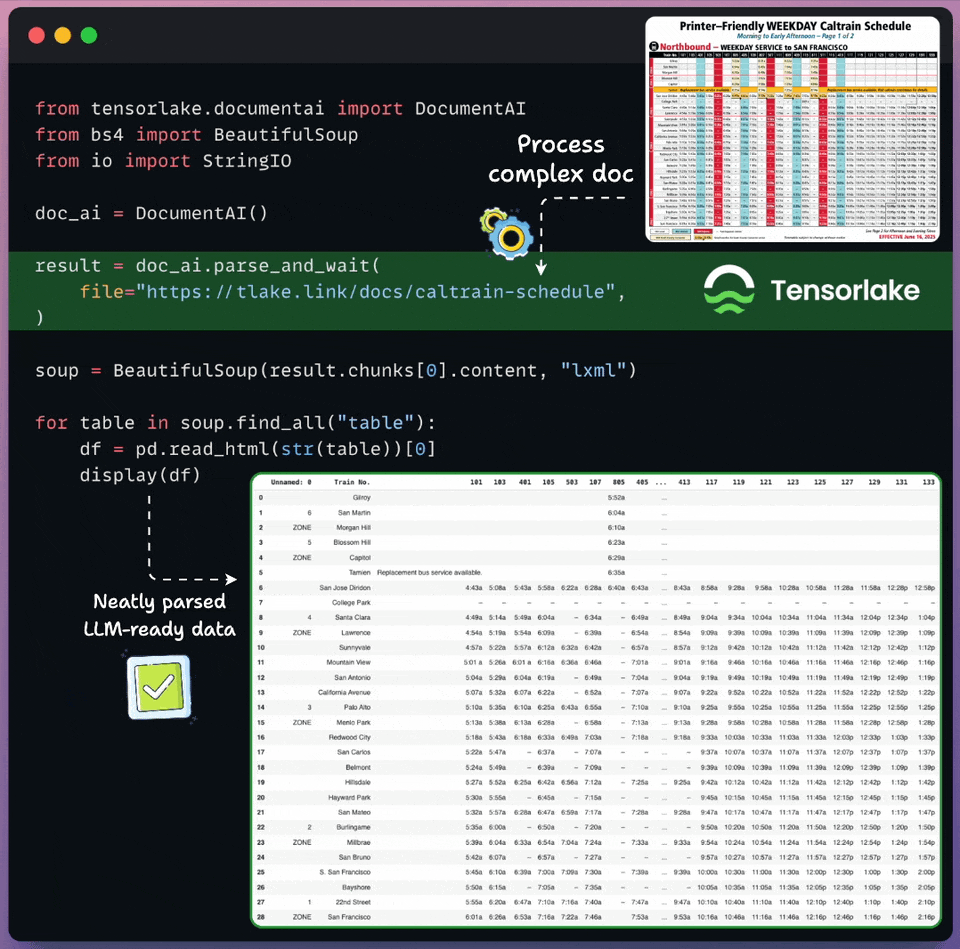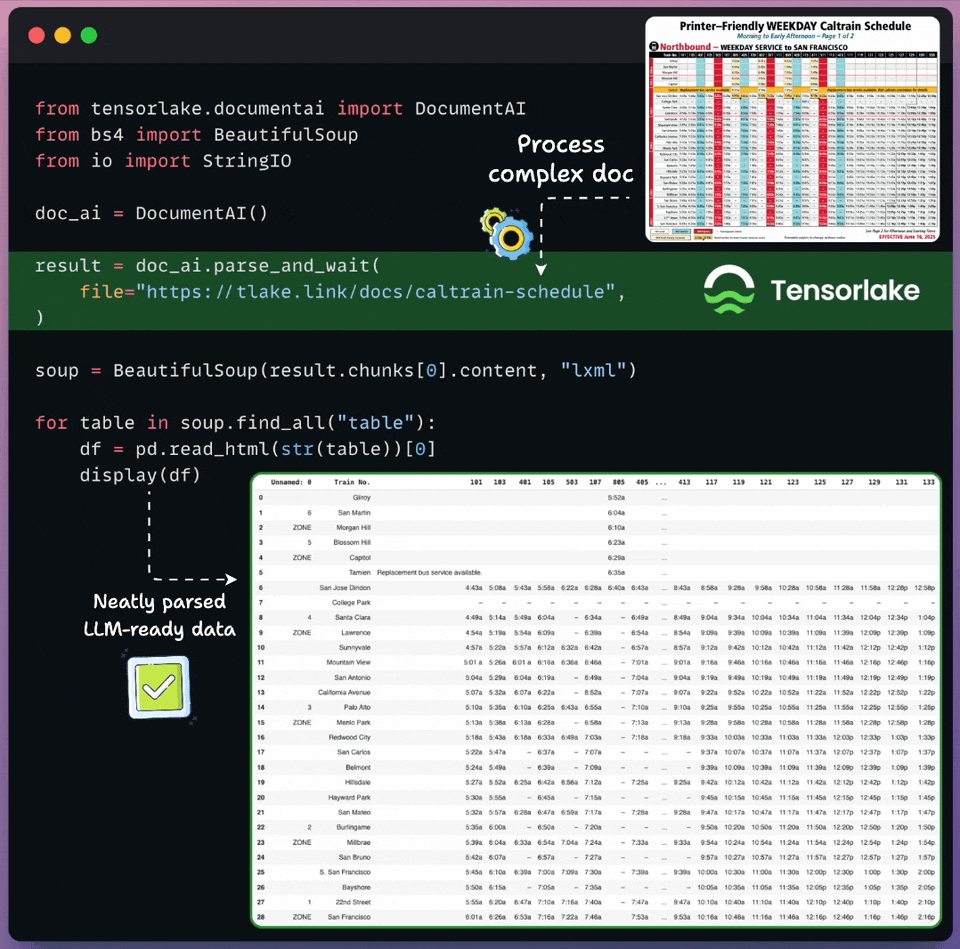
Supports images, documents, CSVs, slides, etc.
Works on any complex layout, handwritten notes, multilingual data, etc.
Returns document layout, structured extraction, page classification, and bounding boxes.
And much more.
Here’s the GitHub repo → (don’t forget to star)
We’ll cover more in a hands-on demo soon.
8 AI model architectures, visually explained
Everyone talks about LLMs, but there’s a whole family of specialized models doing incredible things.
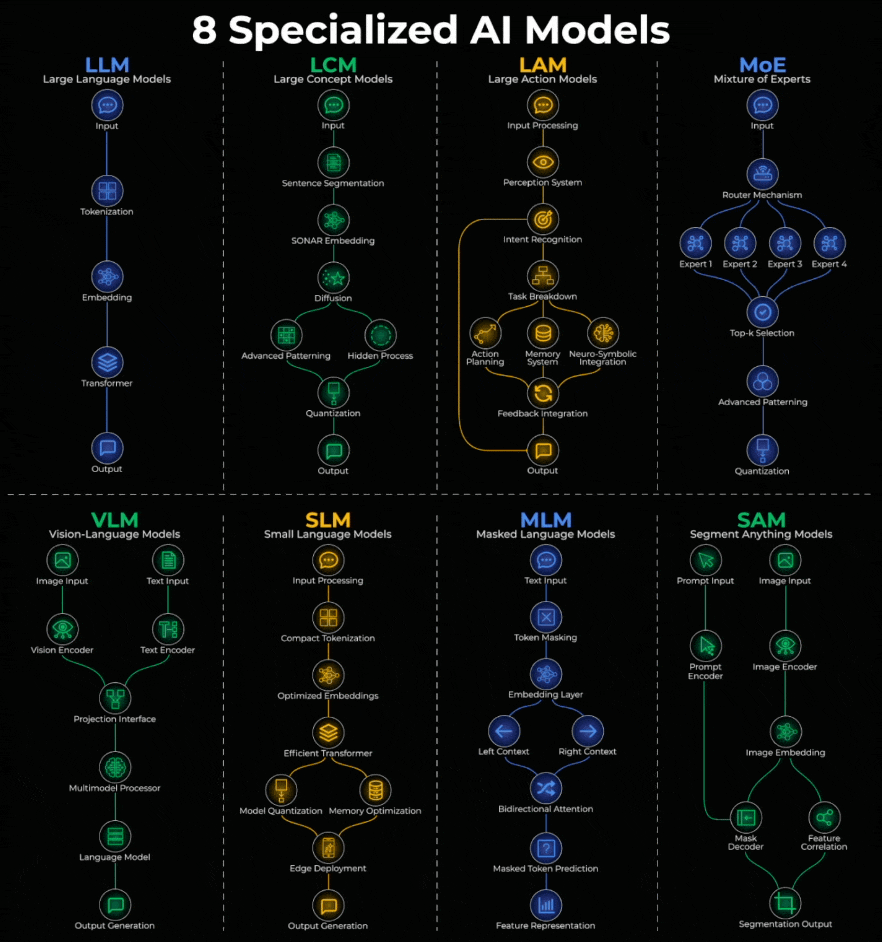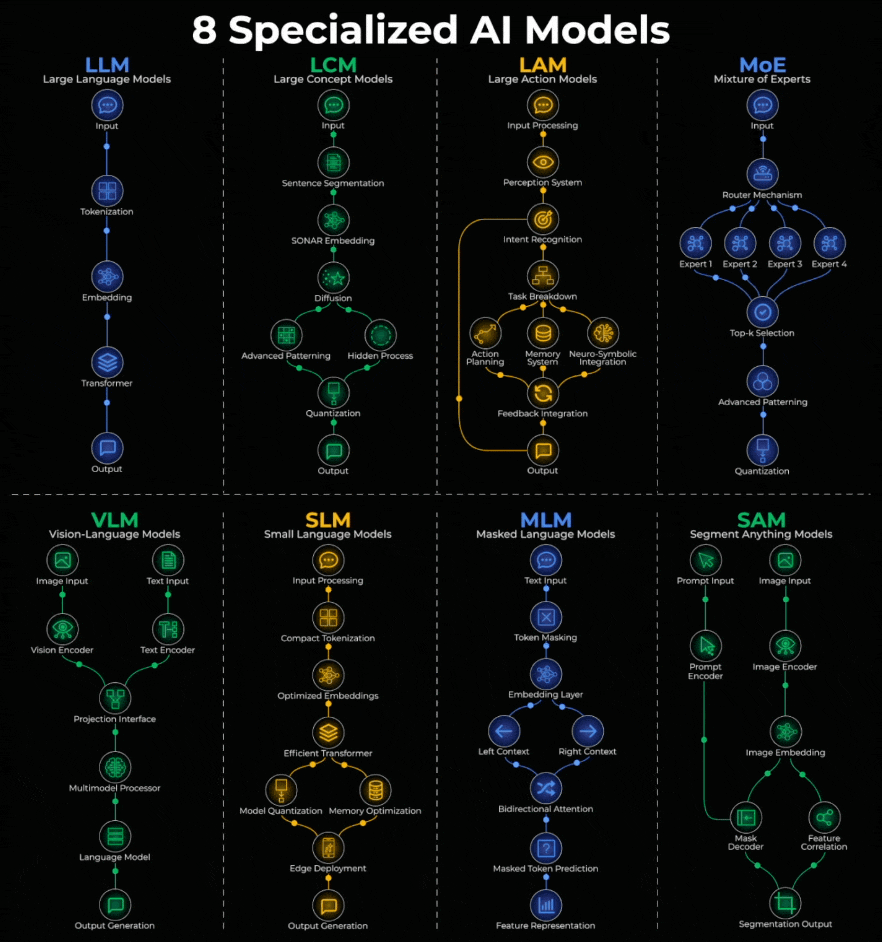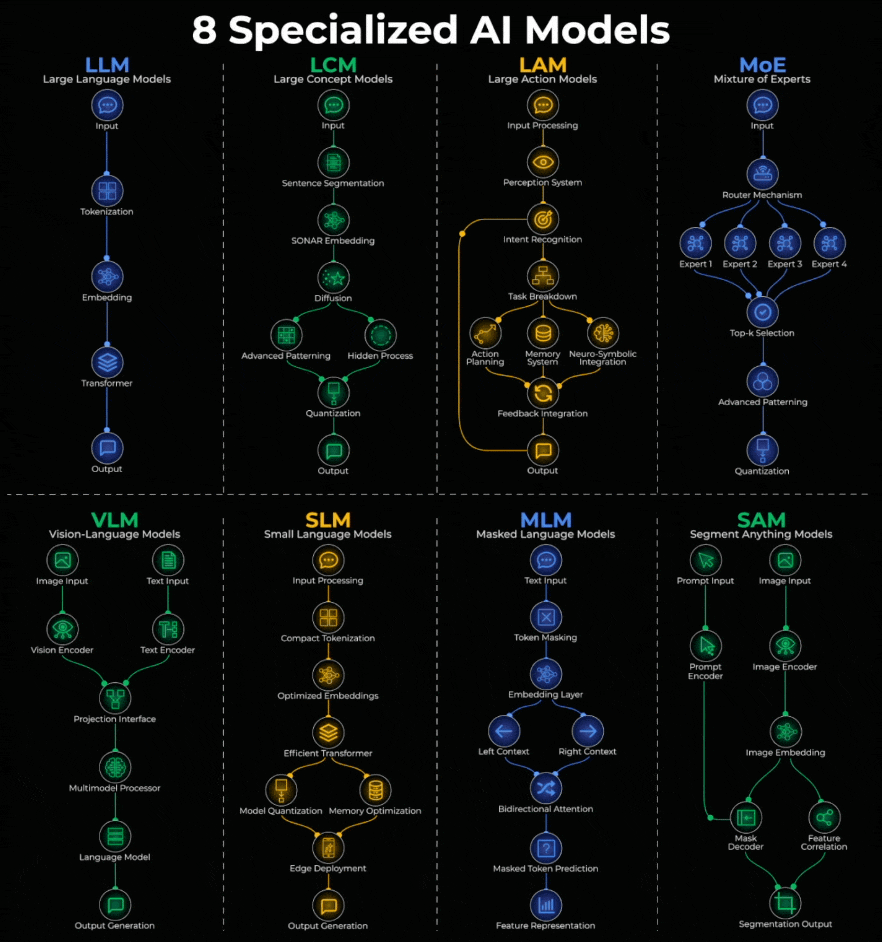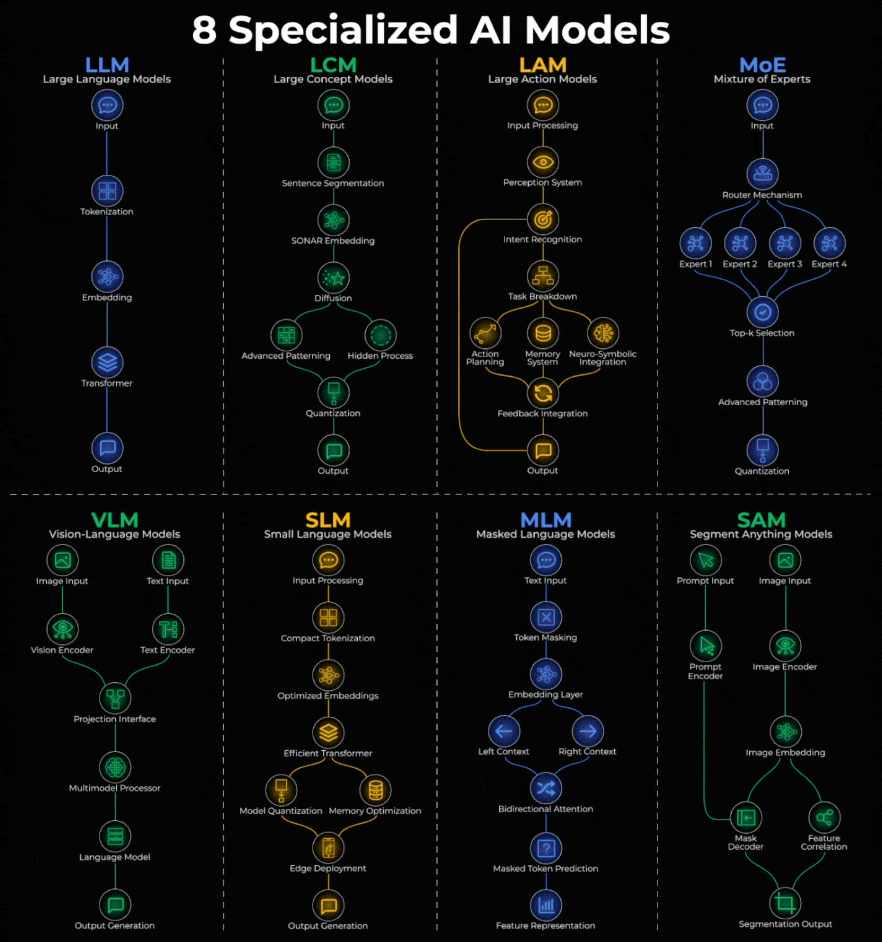
Here’s a quick breakdown:
LLM (Large Language Models):
Text goes in, gets tokenized into embeddings, processed through transformers, and text comes out.
ChatGPT, Claude, Gemini, Llama.
LCM (Large Concept Models)
Works at concept level, not tokens. Input is segmented into sentences, passed through SONAR embeddings, then uses diffusion before output.
Meta’s LCM is the pioneer.
LAM (Large Action Models)
Turns intent into action. Input flows through perception, intent recognition, task breakdown, then action planning with memory before executing.
Rabbit R1, Microsoft UFO, Claude Computer Use.
MoE (Mixture of Experts)
A router decides which specialized “experts” handle your query. Only relevant experts activate, results go through selection and processing.
Mixtral, GPT-4, DeepSeek.
VLM (Vision-Language Models)
Images pass through a vision encoder, text through a text encoder. Both fuse in a multimodal processor, then a language model generates output.
GPT-4V, Gemini Pro Vision, LLaVA.
SLM (Small Language Models)
LLMs optimized for edge devices. Compact tokenization, efficient transformers, and quantization for local deployment.
Phi-3, Gemma, Mistral 7B, Llama 3.2 1B.
MLM (Masked Language Models)
Tokens get masked, converted to embeddings, then processed bidirectionally to predict hidden words.
BERT, RoBERTa, DeBERTa power search and sentiment analysis.
SAM (Segment Anything Models)
Prompts and images go through separate encoders, feed into a mask decoder to produce pixel-perfect segmentation.
Meta’s SAM powers photo editing, medical imaging, and autonomous vehicles.
What else would you add?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.