
8 Key LLM Development Skills for AI Engineers
...covered with resources and explained visually.

Opik: Open-source LLM evaluation platform

Opik is a 100% open-source production monitoring platform for LLM apps that gives real-time insights, feedback tracking, and trace analytics at daily/hourly granularity for enterprise-scale apps.
Real-time dashboard with scores & token metrics
Automated LLM-as-a-Judge evaluation scoring
Python SDK + UI feedback logging
Advanced trace search & update APIs
Complete trace content management
High-volume production-ready
8 key LLM development skills for AI engineers
Working with LLMs isn’t just about prompting.
Production-grade systems demand a deep understanding of how LLMs are engineered, deployed, and optimized.
Here are the eight pillars that define serious LLM development:
Let’s understand each of them:
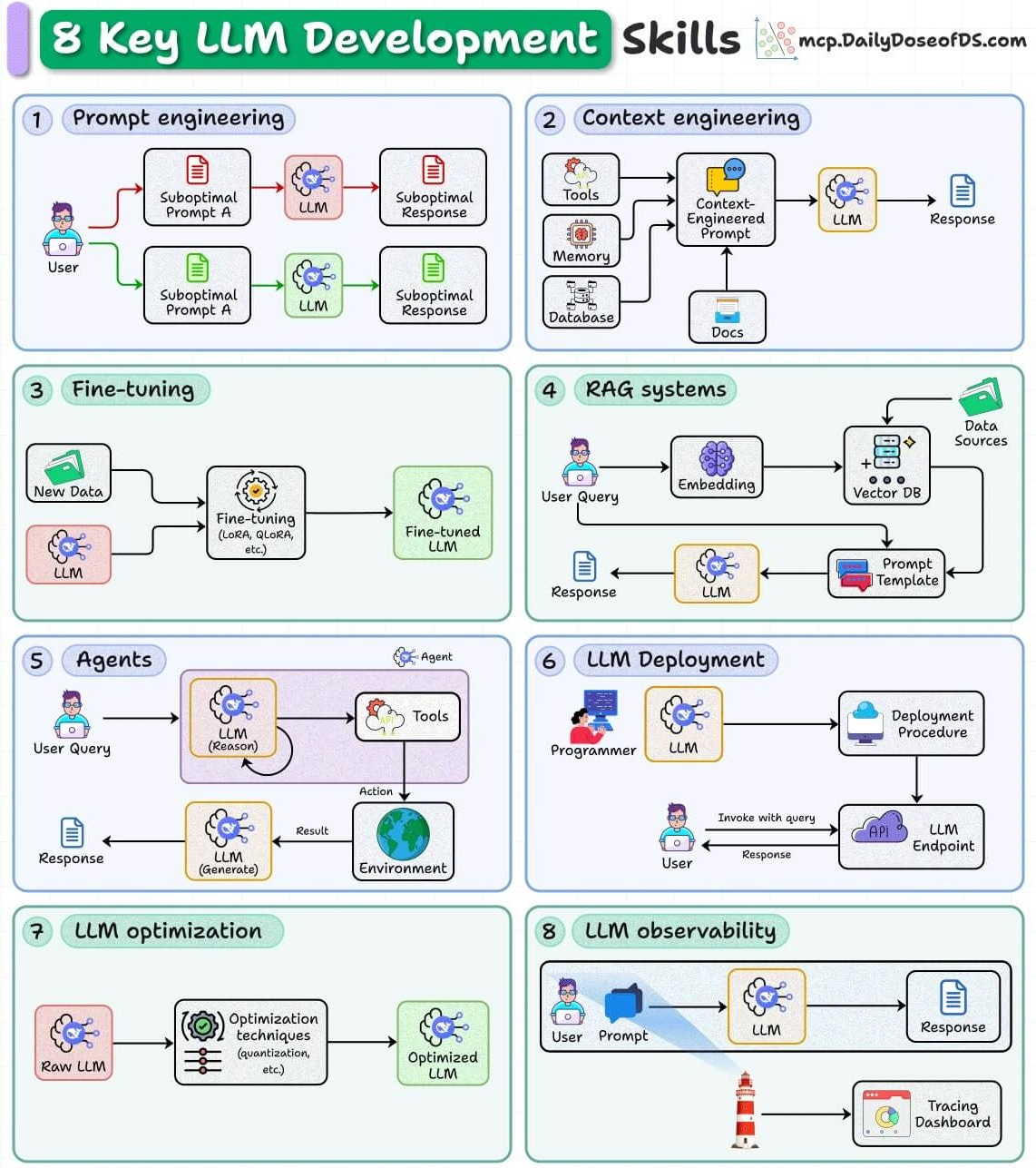
1. Prompt engineering
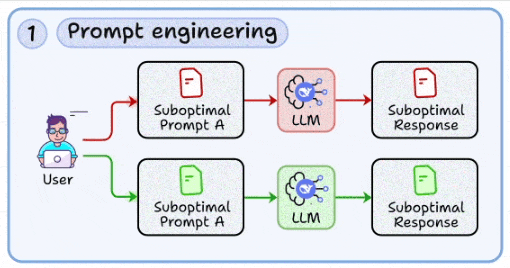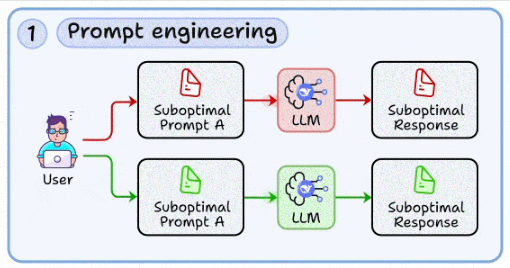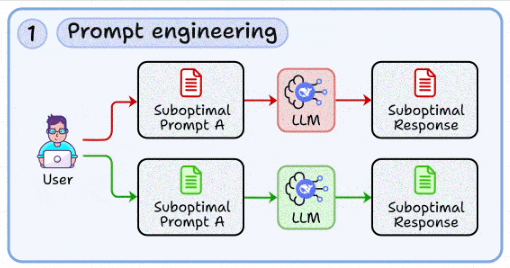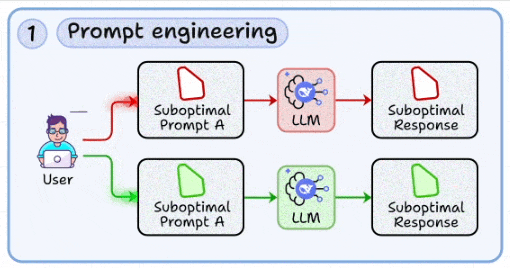
The most basic skill is to craft structured prompts that reduce ambiguity and guide model behavior toward deterministic outputs.
This involves iterating quickly with variations, using patterns like chain-of-thought, and a few-shot examples to stabilize responses (covered here).
Treating prompt design as a reproducible engineering task, not trial-and-error copywriting.
2. Context engineering
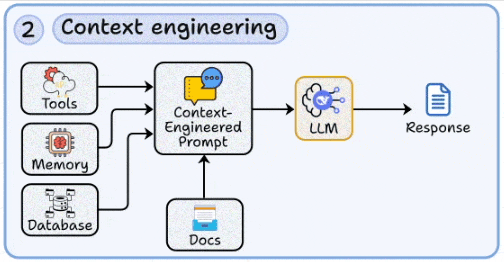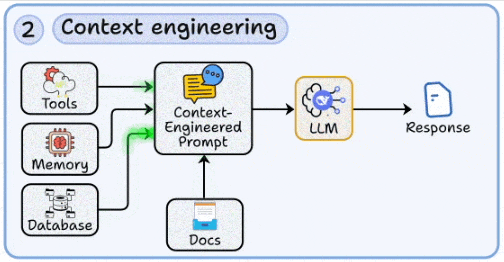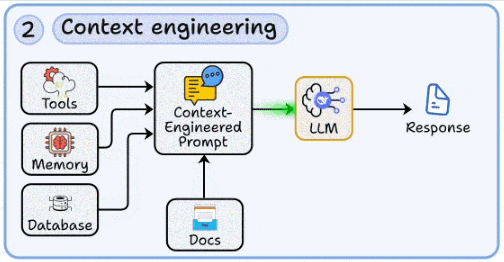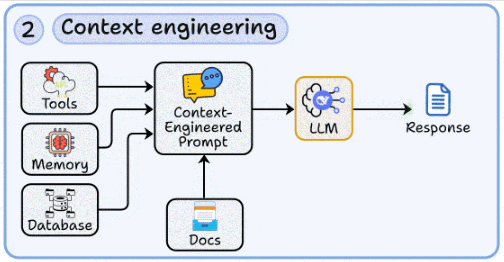
Dynamically injecting relevant external data (databases, memory, tool outputs, documents) into prompts.
Designing context windows that balance completeness with token efficiency.
Handling retrieval noise and context collapse, critical in long-context scenarios.
We’ll be doing a demo on context engineering pretty soon to make this more concrete.
3. Fine-tuning
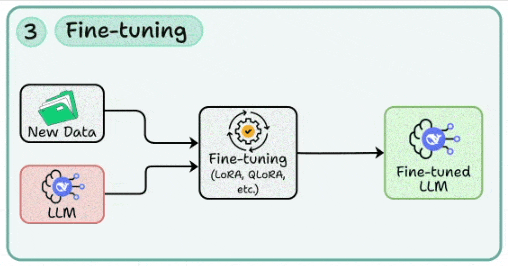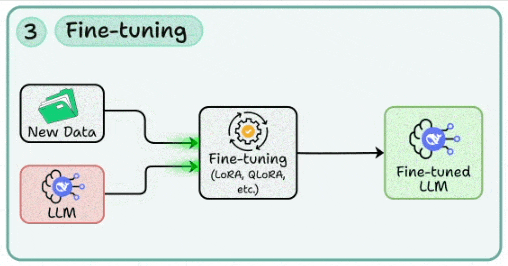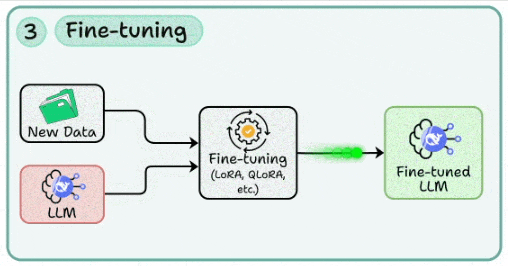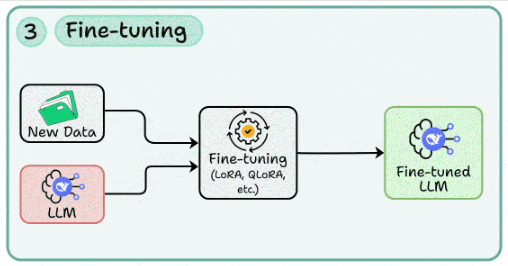
In many cases, you may need to tweak the LLM’s behaviour to your use cases. This skill involves applying methods like LoRA/QLoRA to adapt a base model with domain-specific data while keeping compute costs low.
Managing data curation pipelines (deduplication, instruction formatting, quality filtering).
Monitoring overfitting vs. generalization when extending the model beyond zero/few-shot capabilities.
We implemented LoRA here and DoRA here and covered 5 more techniques for fine-tuning LLMs here.
4. RAG systems
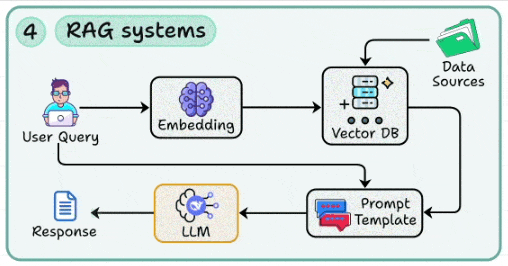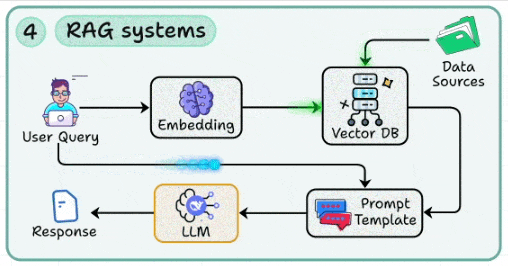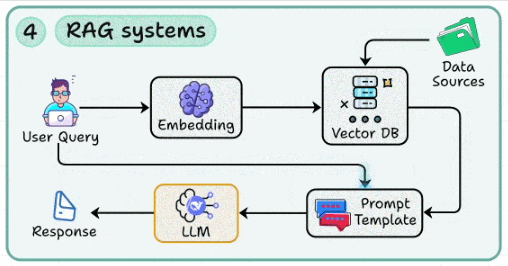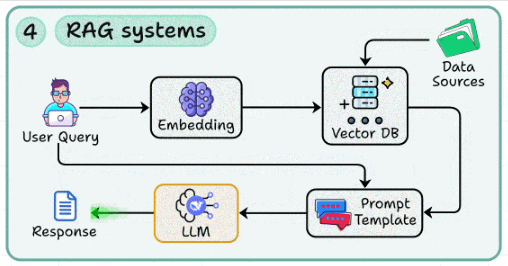
This skill lets you build systems that can augment LLMs with external knowledge via embeddings + vector DBs to reduce hallucinations.
Engineering retrieval pipelines (indexing, chunking, query rewriting) for high recall and precision.
Using prompt templates that fuse retrieved context with user queries in a structured way.
This 9-part rag crash course covers everything with implementation →
5. Agents
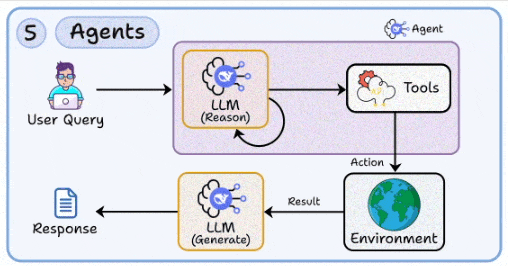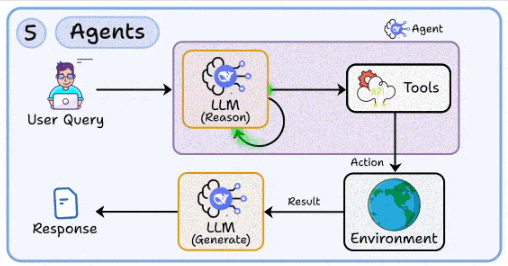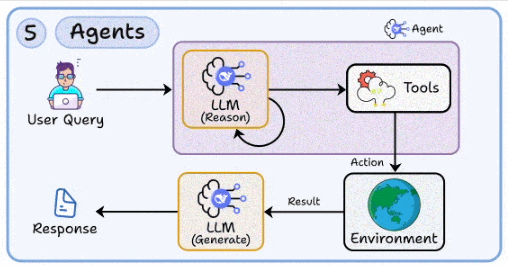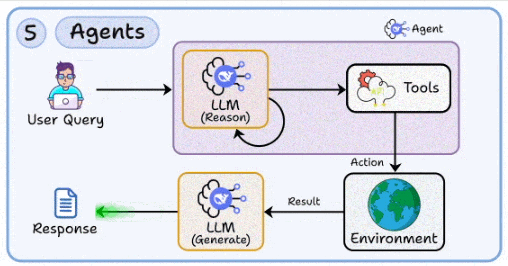
With this skill, you learn to move beyond static Q&A by orchestrating multi-step reasoning loops with tool use.
Handling environment interactions, state management, and error recovery in autonomous workflows.
Designing fallbacks for when reasoning paths fail or external APIs return incomplete results.
This 14-part Agents crash course covers everything with implementation →
This mini crash course is also a good starting point that covers:
What is an AI Agent
Connecting Agents to tools
Overview of MCP
Replacing tools with MCP servers
Setting up observability and tracing
6. LLM deployment
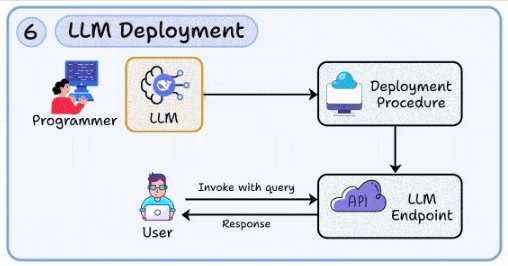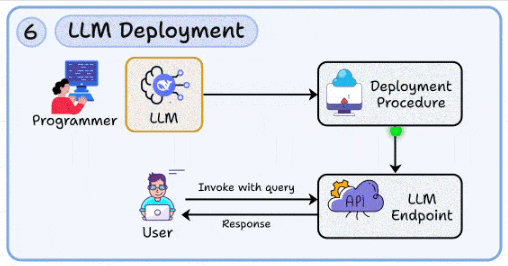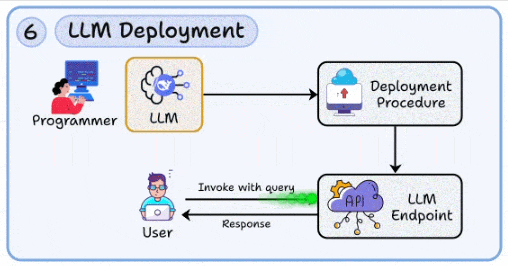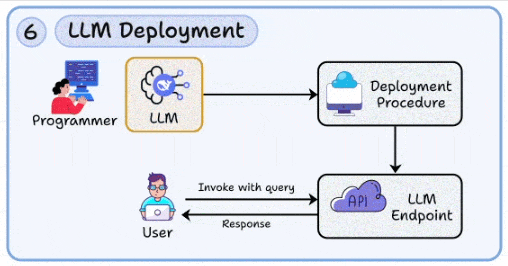
At this stage, you have likely built your LLM app. This skill lets you package models into production-grade APIs with scalable deployment pipelines.
Managing latency, concurrency, and failure isolation (think: autoscaling + container orchestration).
Building guardrails around access, monitoring cost per request, and controlling misuse.
Open-source frameworks like Beam can help. GitHub repo →
7. LLM optimization
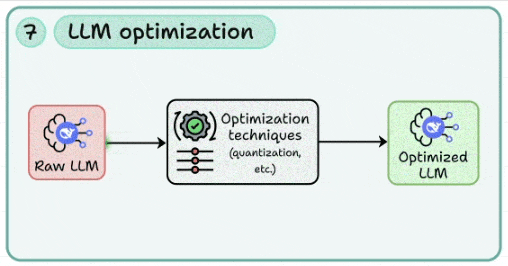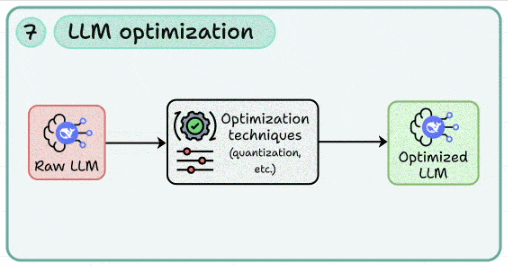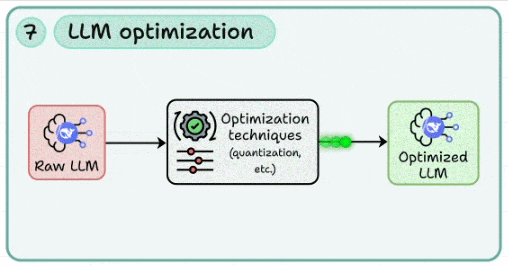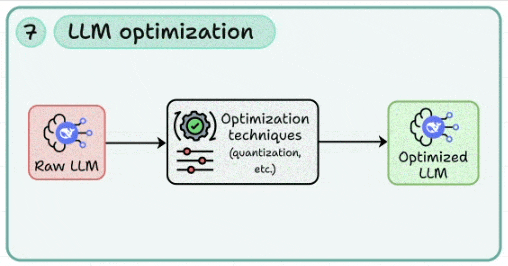
To reduce costs, you need to learn how to apply quantization, pruning, and distillation to reduce memory footprint and inference costs.
This lets you benchmark trade-offs between speed, accuracy, and hardware utilization (GPU/CPU offloading).
Continuously profiling models to ensure optimization doesn’t compromise core functionality.
8. LLM observability
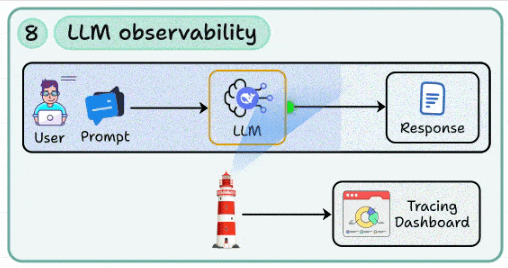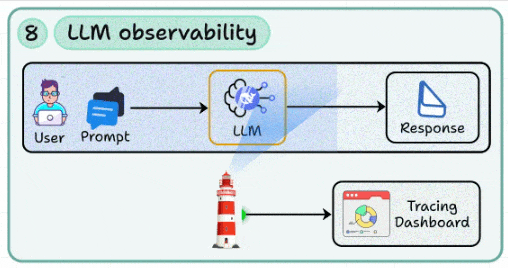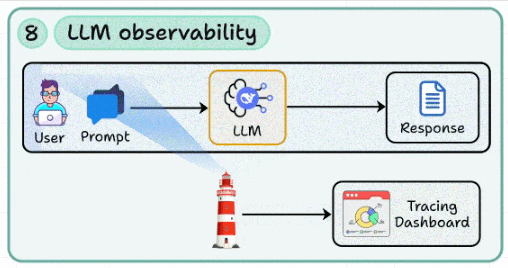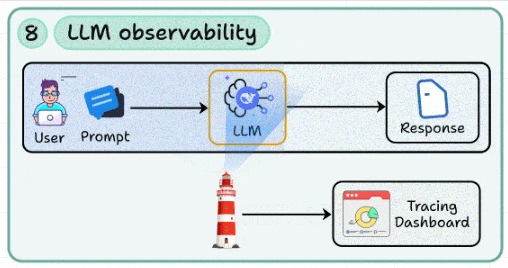
No matter how simple or complex your LLM app is, you must learn how to implement tracing, logging, and dashboards to monitor prompts, responses, and failure cases.
Tracking token usage, latency spikes, and prompt drift in real-world traffic.
Feeding observability data back into iteration cycles for continuous improvement.
This practical guide covers integrating evaluation and observability into LLM apps →
👉 Over to you: What other LLM development skills will you add here?
Thanks for reading!