
8 RAG Architectures for AI Engineers
...explained with visuals.

Convert any unstructured data to AI-ready data
Real-world documents are complex for LLMs to process directly.
Tensorlake transforms unstructured docs into LLM-ready data in just a few lines of code, as shown below:
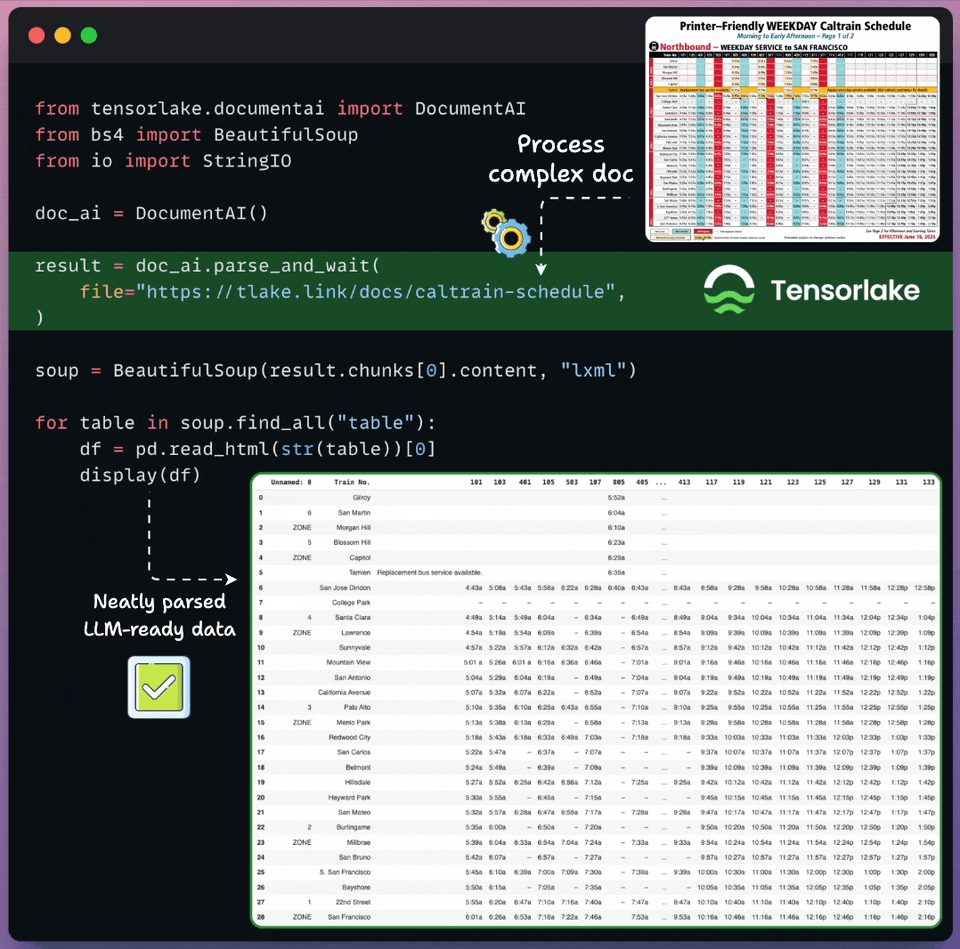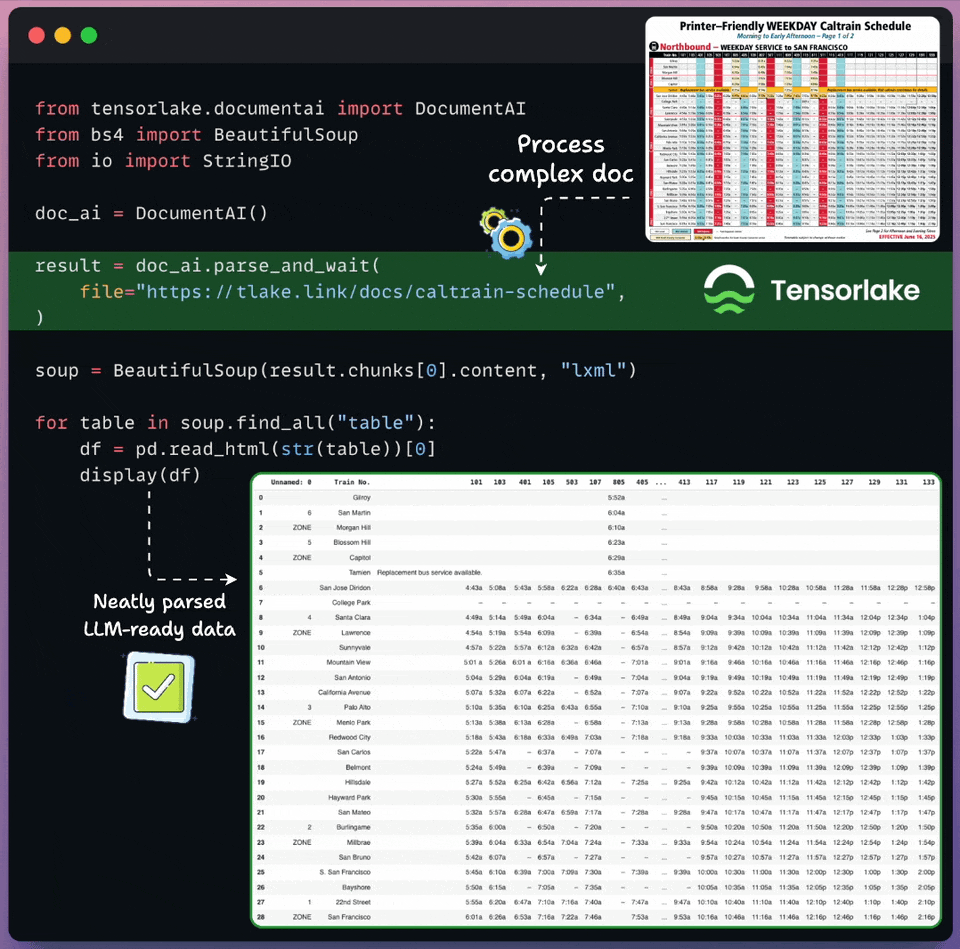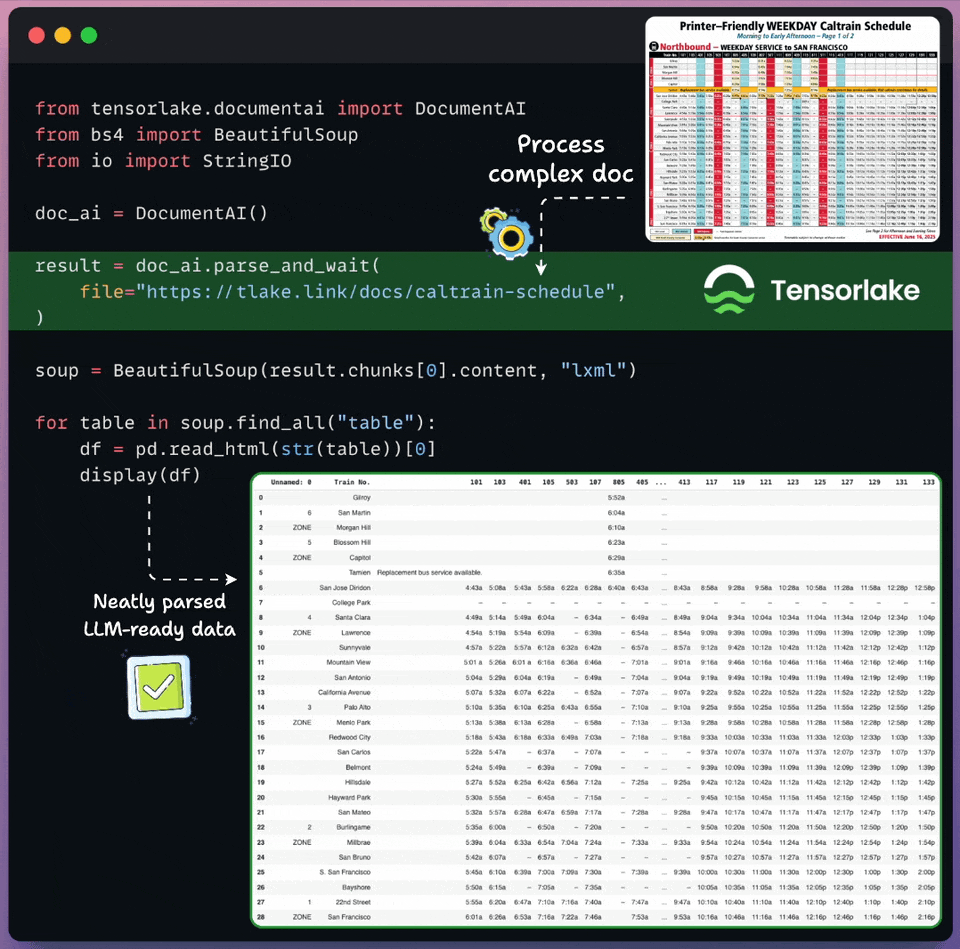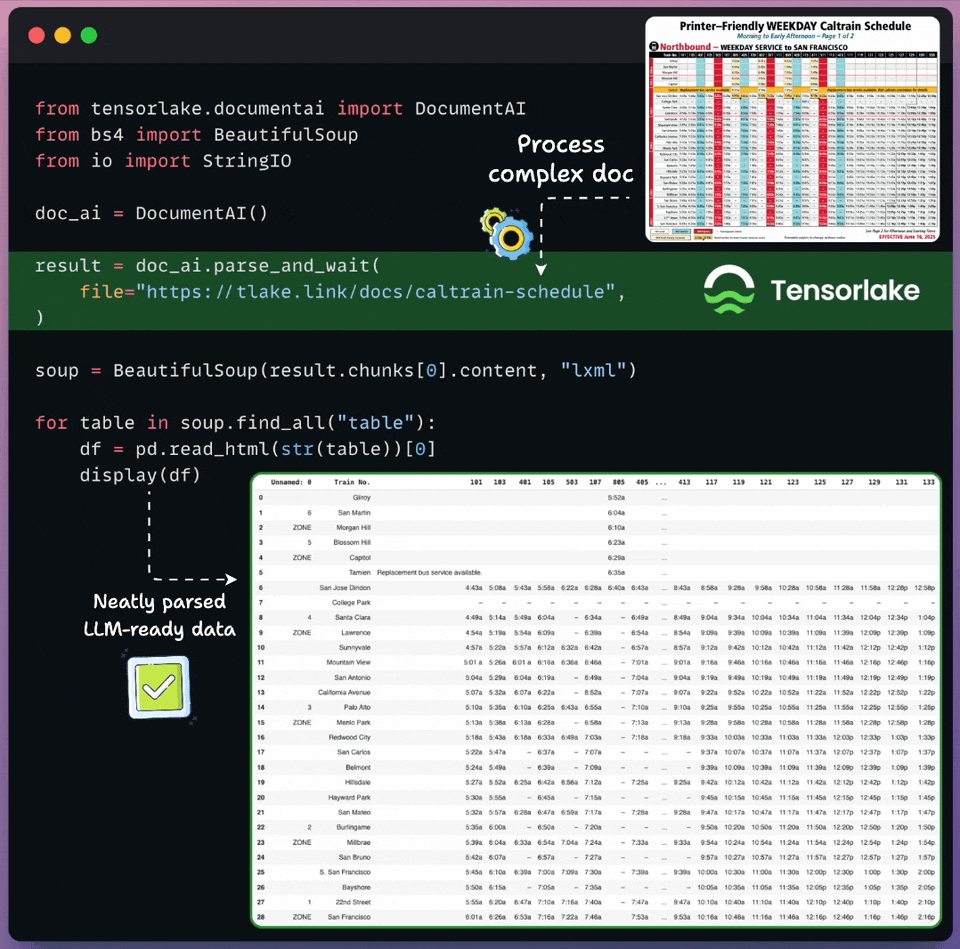
Supports images, documents, CSVs, slides, etc.
Works on any complex layout, handwritten notes, multilingual data, etc.
Returns document layout, structured extraction, page classification, and bounding boxes.
And much more.
Here’s the GitHub repo → (don’t forget to star)
We’ll cover more in a hands-on demo soon.
8 RAG architectures, explained visually
We prepared the following visual that details 8 types of RAG architectures used in AI systems:
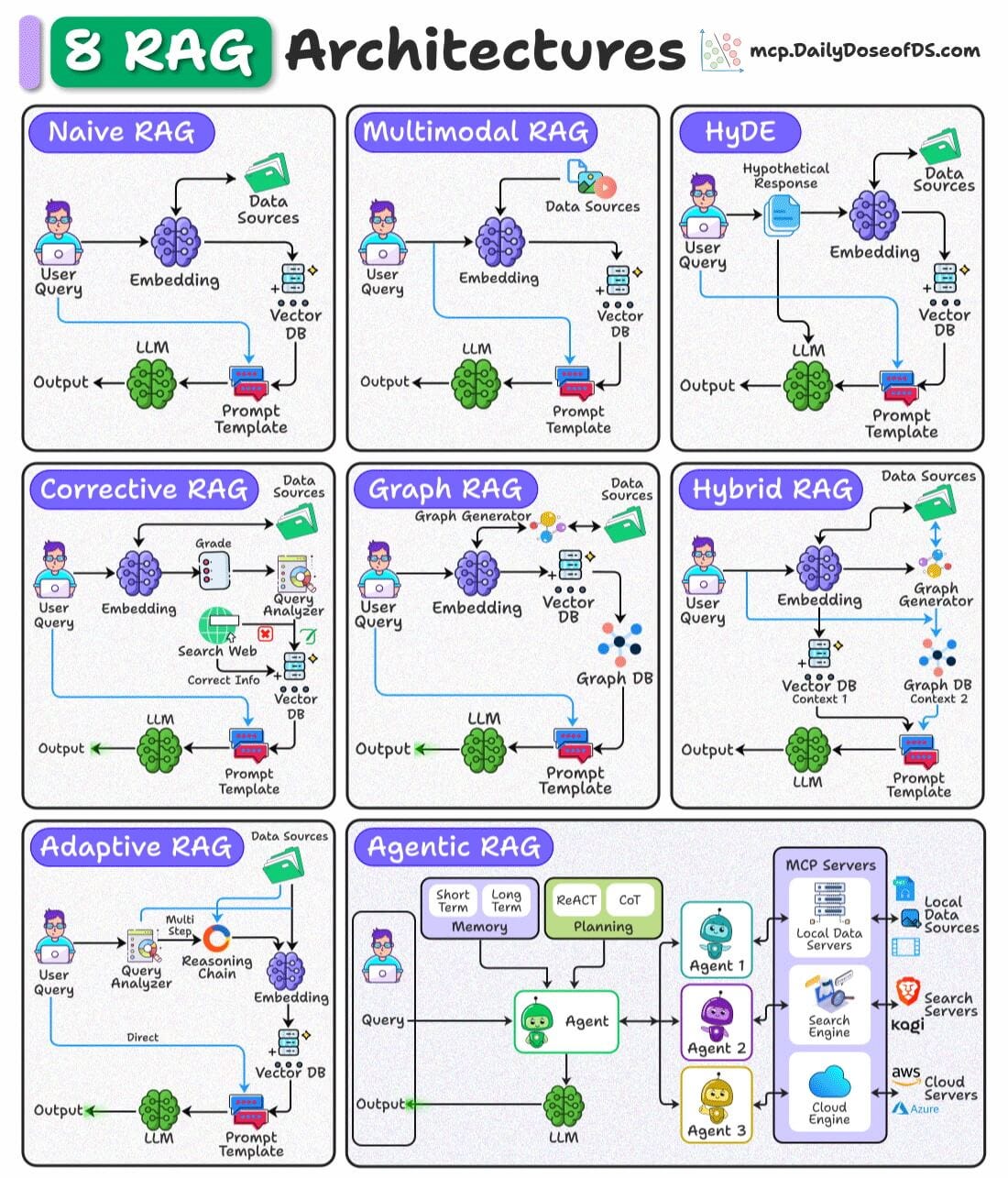
Let’s discuss them briefly:
Retrieves documents purely based on vector similarity between the query embedding and stored embeddings.
Works best for simple, fact-based queries where direct semantic matching suffices.
Handles multiple data types (text, images, audio, etc.) by embedding and retrieving across modalities.
Ideal for cross-modal retrieval tasks like answering a text query with both text and image context.
Queries are not semantically similar to documents.
This technique generates a hypothetical answer document from the query before retrieval.
Uses this generated document’s embedding to find more relevant real documents.
Validates retrieved results by comparing them against trusted sources (e.g., web search).
Ensures up-to-date and accurate information, filtering or correcting retrieved content before passing to the LLM.
Converts retrieved content into a knowledge graph to capture relationships and entities.
Enhances reasoning by providing structured context alongside raw text to the LLM.
6) Hybrid RAG
Combines dense vector retrieval with graph-based retrieval in a single pipeline.
Useful when the task requires both unstructured text and structured relational data for richer answers.
7) Adaptive RAG
Dynamically decides if a query requires a simple direct retrieval or a multi-step reasoning chain.
Breaks complex queries into smaller sub-queries for better coverage and accuracy.
Uses AI agents with planning, reasoning (ReAct, CoT), and memory to orchestrate retrieval from multiple sources.
Best suited for complex workflows that require tool use, external APIs, or combining multiple RAG techniques.
We have covered several of these architectures with implementations in our RAG series to fully prepare you for building production-grade RAG systems:
👉 Over to you: Which RAG architecture do you use the most?
Thanks for reading!