
8 Techniques to Generate Better LLM Outputs
...explained visually with usage.

Run DeepSeek V4 Pro model on Lightning AI

DeepSeek just released V4-Pro, a 1.6T total parameter MoE model with only 49B active parameters, open-sourced under MIT.
It’s the strongest open-weight model for agentic coding right now, hitting 80.6% on SWE-Bench Verified.
DeepSeek’s own engineers reportedly use it as their internal coding agent, rating it above Claude Sonnet 4.5 and close to Opus 4.6 in non-thinking mode.
The model also supports a 1M token context window natively, and V4’s new hybrid attention architecture brings KV cache usage down to 10% of V3.2, which is what makes that context length practical for long-running agent loops.
If you’re looking to try it out, Lightning AI has a hosted endpoint ready to go →
Thanks to Lightning AI for partnering today!
8 prompting techniques to generate better LLM outputs
Zero-shot prompting (just sending a query with no additional structure) is the default for most people using LLMs.
It’s also where most output quality complaints come from: inconsistent formatting, shallow reasoning, missing constraints, and lack of diversity.
Each of these failure modes maps to a specific prompting technique that fixes it.
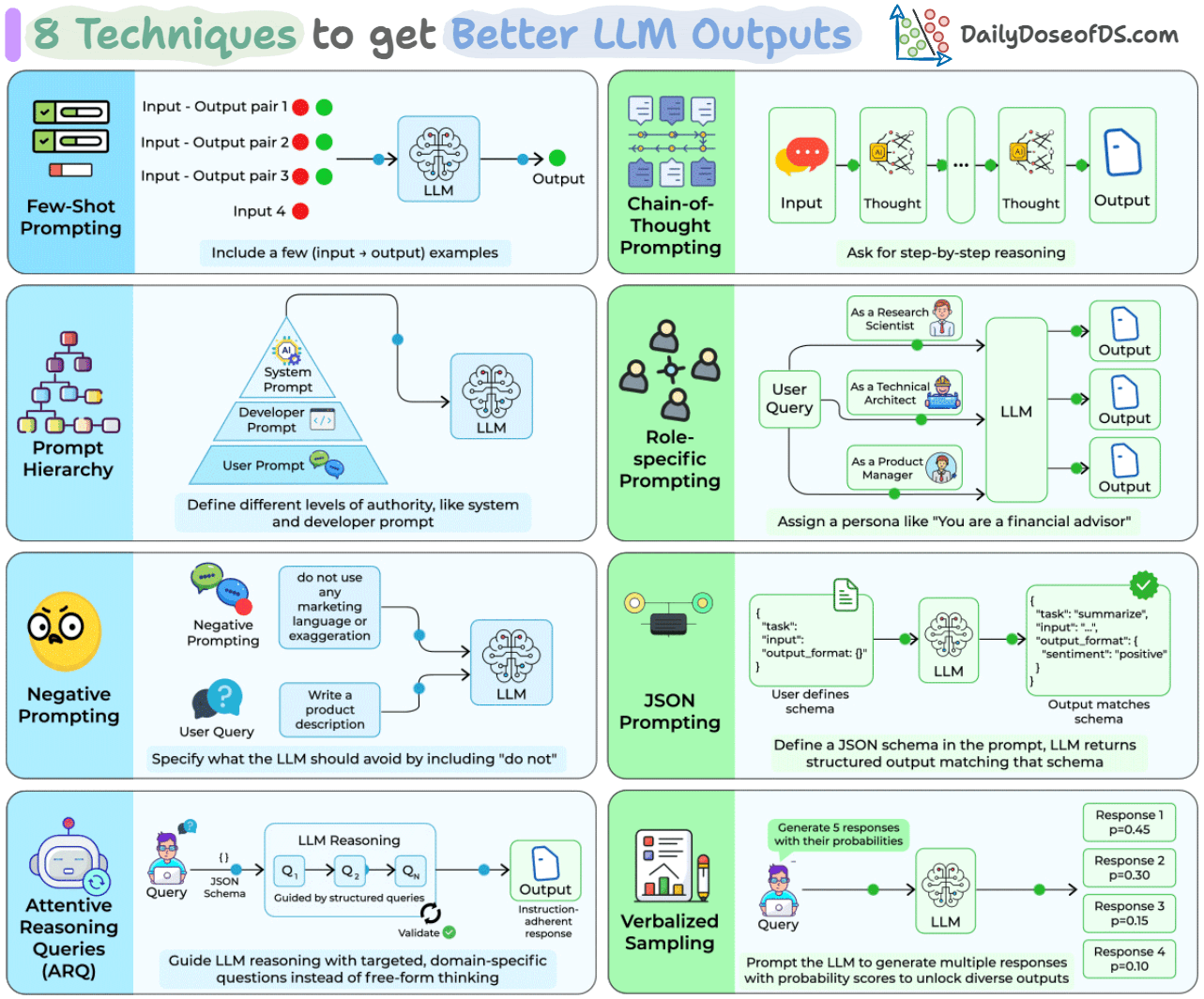
Some have been around for a few years (few-shot, CoT), others are from 2025 research (ARQ hit 90.2% instruction adherence vs. 81.5% for direct prompting; Verbalized Sampling improved output diversity by 1.6-2.1x).
Let’s walk through all eight, how they work, and when each one is the right tool.
Few-shot prompting
Instead of describing what you want, you show the LLM a few input-output examples directly in the prompt. The model picks up the pattern and applies it to your new input.
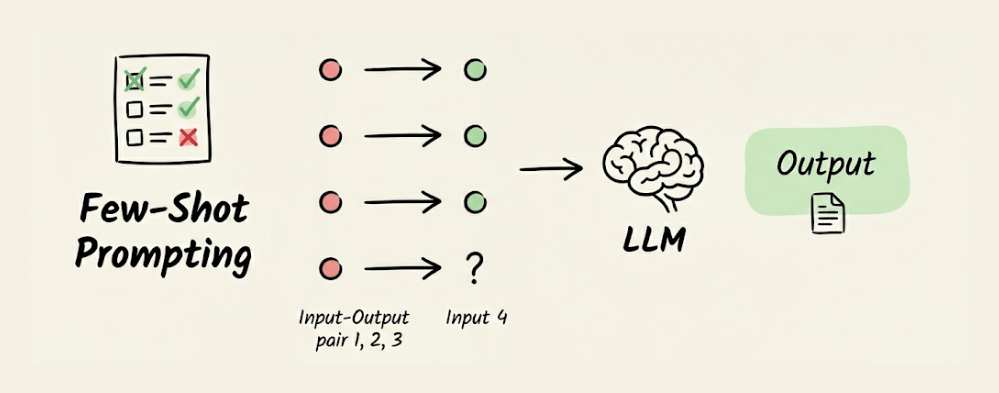
Three to five examples are typically enough. Use this when the task has a specific format: natural language to SQL, text classification into custom categories, or any conversion where showing is easier than telling.
Chain-of-Thought (CoT) prompting
CoT asks the model to reason step by step before producing a final answer. Adding “Let’s think step by step” to prompts improved accuracy on GSM8K math benchmarks from 17.7% to 78.7% with PaLM 540B.
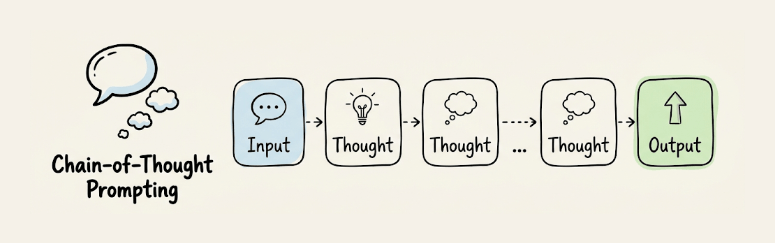
It works because it breaks complex reasoning into smaller, verifiable steps rather than forcing a single-pass answer. Most useful for math, logic, code debugging, or any task that depends on a chain of intermediate conclusions.
We covered it in detail here, along with the Self-consistency technique and the Tree of Thought technique →
Prompt hierarchy
LLM APIs expose multiple levels of instruction: system prompts, developer prompts, and user prompts. System prompts set behavioral constraints, developer prompts define task-specific logic, and user prompts carry the actual query.
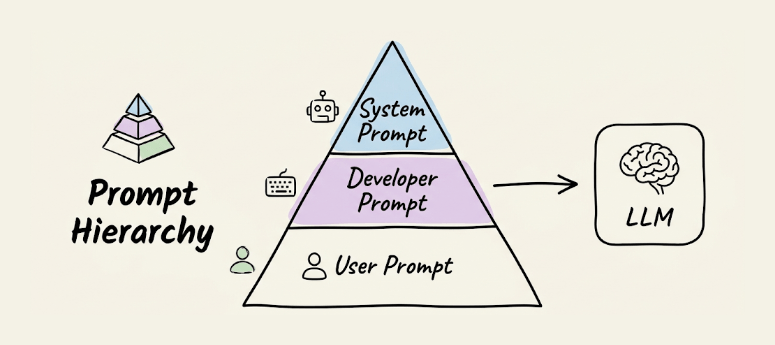
When instructions conflict across levels, the model prioritizes higher levels. This separation of concerns lets you put immutable rules in the system prompt so user inputs can’t override your core constraints.
Role-specific prompting
Assigning a persona (”You are a financial advisor” vs. “You are a security researcher”) shifts the model’s responses toward a specific expertise profile. The model conditions on different subsets of its training data, producing different vocabulary, framing, and decision criteria.
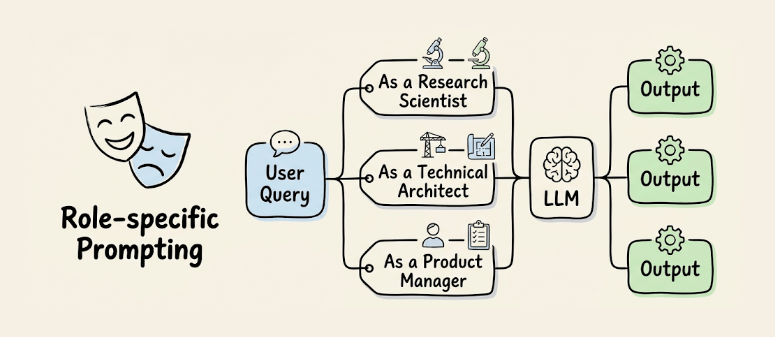
You can also run the same query through multiple personas and compare outputs for diverse perspectives on the same problem.
Negative prompting
Instead of only telling the LLM what to do, you specify what to avoid: “do not use marketing language,” “avoid bullet points,” “do not mention pricing unless asked.” The model treats these as hard constraints during generation.
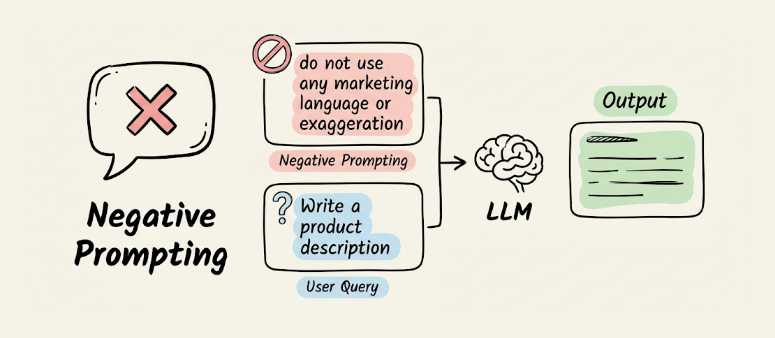
Most useful for content generation where you need to prevent specific failure modes like jargon, hallucinated references, or unnecessary caveats.
JSON prompting
You define a JSON schema in the prompt and instruct the LLM to return its output matching that structure.
Include something like {"task": "summarize", "input": "...", "output_format": {"sentiment": "", "summary": ""}} and the model responds with values filled in.
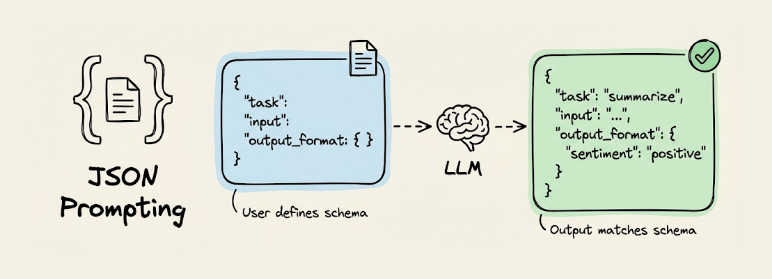
Unlike API-level structured outputs (OpenAI’s response_format, Anthropic’s tool-use), JSON prompting works with any model and any interface because the constraint lives in the prompt itself.
You get ~90%+ schema compliance on capable models without any API-specific setup.
We covered it in detail here →
Attentive reasoning queries (ARQ)
ARQ replaces free-form CoT with targeted, domain-specific questions organized in a predefined JSON schema. Instead of “think step by step,” you give the model a structured checklist it must answer before generating its response.
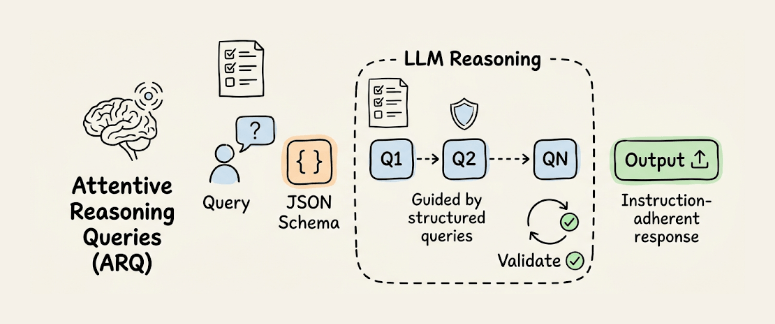
In testing across 87 scenarios within the Parlant framework, ARQ hit 90.2% success rate vs. 86.1% for CoT and 81.5% for direct prompting.
CoT lets the model freely ignore instructions. ARQ reinstates critical constraints at the exact point where reasoning happens, using the recency effect to keep rules in an active context.
We covered it in detail here →
Verbalized sampling
Post-training alignment (RLHF, DPO) causes LLMs to collapse toward a narrow set of “safe” outputs.
Verbalized Sampling fixes this with a single prompt change. Instead of asking for one response, you ask the model to “generate 5 responses with their corresponding probabilities.”
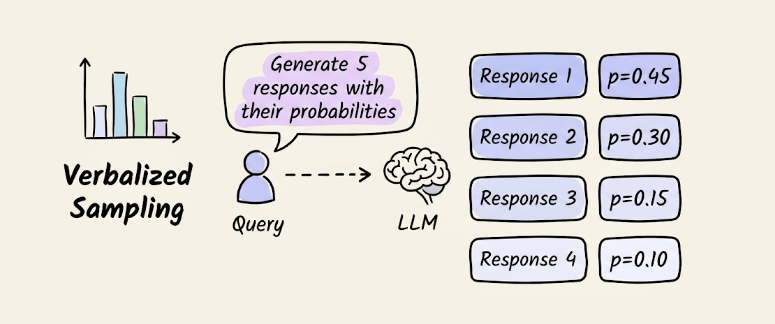
This forces the LLM to verbalize its internal distribution rather than collapsing to the mode.
In experiments mentioned in its research paper, diversity improved by 1.6-2.1x over direct prompting, while human evaluation scores went up by 25.7%. The technique is orthogonal to temperature, so you can stack them.
We covered it in detail here →
These techniques aren’t mutually exclusive. Few-shot + CoT is a common combination. JSON prompting + negative prompting gives you structured outputs with explicit constraints. ARQ is a structured version of CoT designed for multi-turn agent conversations.
The choice depends on the failure mode: inconsistent format (JSON prompting), shallow reasoning (CoT or ARQ), lack of diversity (Verbalized Sampling), unwanted content (Negative prompting), or missing domain expertise (Role-specific prompting).
👉 Over to you: Which of these techniques do you use most in your day-to-day workflows, and have you tried combining any of them?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.