
A 100% Open-source Alternative to n8n!
+ a common misconception about RAG indexing!

A 100% open-source alternative to n8n!
Sim is a drag-and-drop open-source platform to build and deploy Agentic workflows.
Runs 100% locally
Works with any local LLM
We used it to build a finance assistance app & connected it to Telegram in minutes.
The workflow is simple:
You ask a finance question through Telegram
An Intent Classifier figures out if it’s finance-related
If not, you get a polite redirect
If yes, the Finance Agent kicks in
Here’s what’s happening under the hood:
The Finance Agent uses Firecrawl for web searches and accesses stock data via Alpha Vantage’s API through MCP servers.
A Response Agent compiles the info and delivers it.
In Sim, every tool or agent you need is available as a block. Just drag them onto the canvas and connect them.
Sim agents also support integration with MCP, which is exactly what we did to connect our agent with Alpha Vantage’s API.
And it’s simple to extend. If you want to track crypto or need portfolio analysis, you can just add another Agent. Sim allows easy feature additions without disrupting existing functionality.
Find Sim’s open-source GitHub repo here →
A common misconception about RAG indexing
When we talk about RAG, it’s usually thought: index the doc → retrieve the same doc.
But indexing ≠ retrieval.
So the data you index doesn’t have to be the data you feed the LLM during generation.
Here are 4 smart ways to index data:
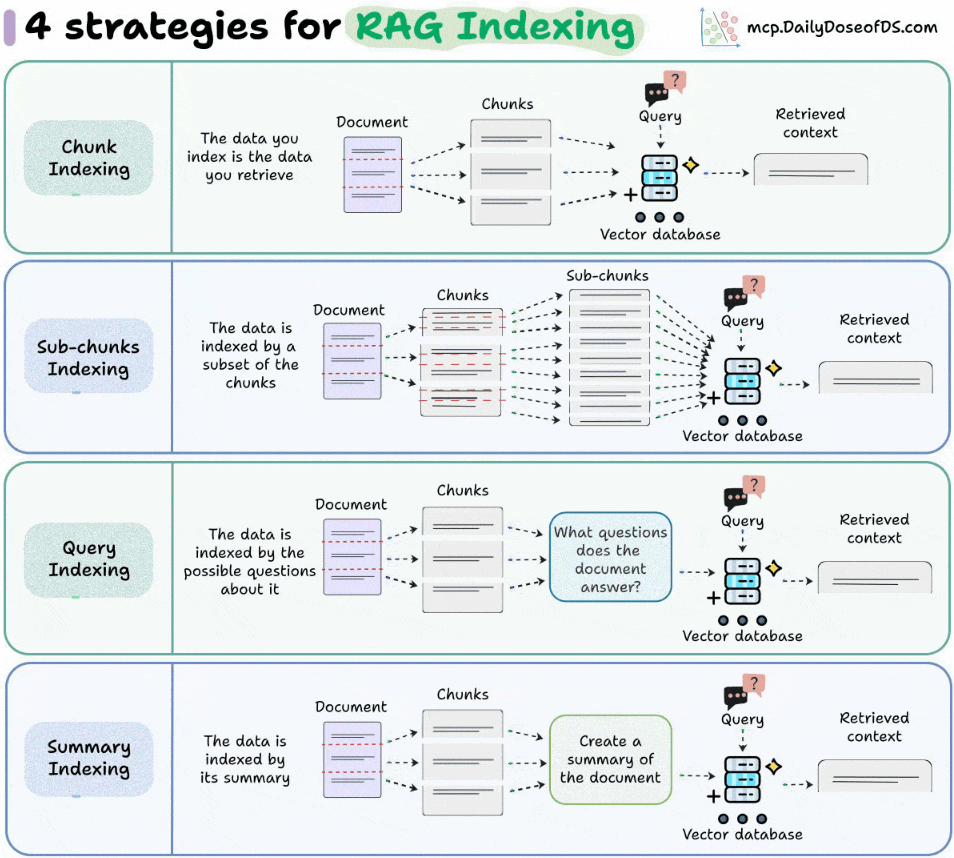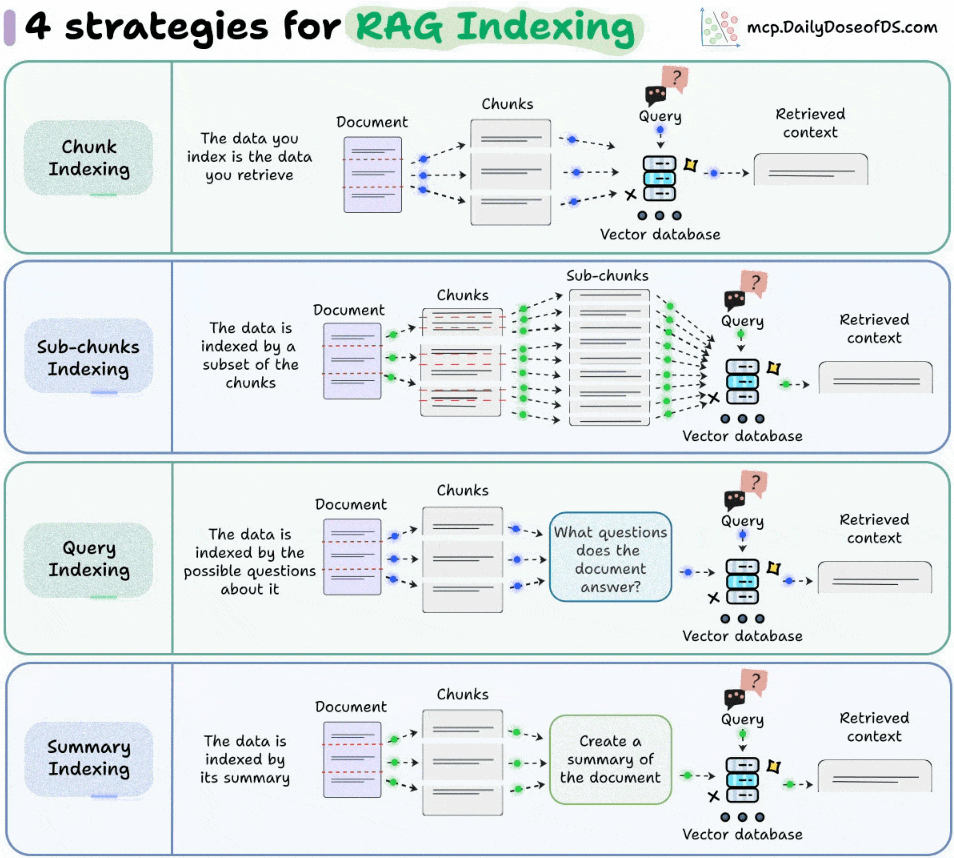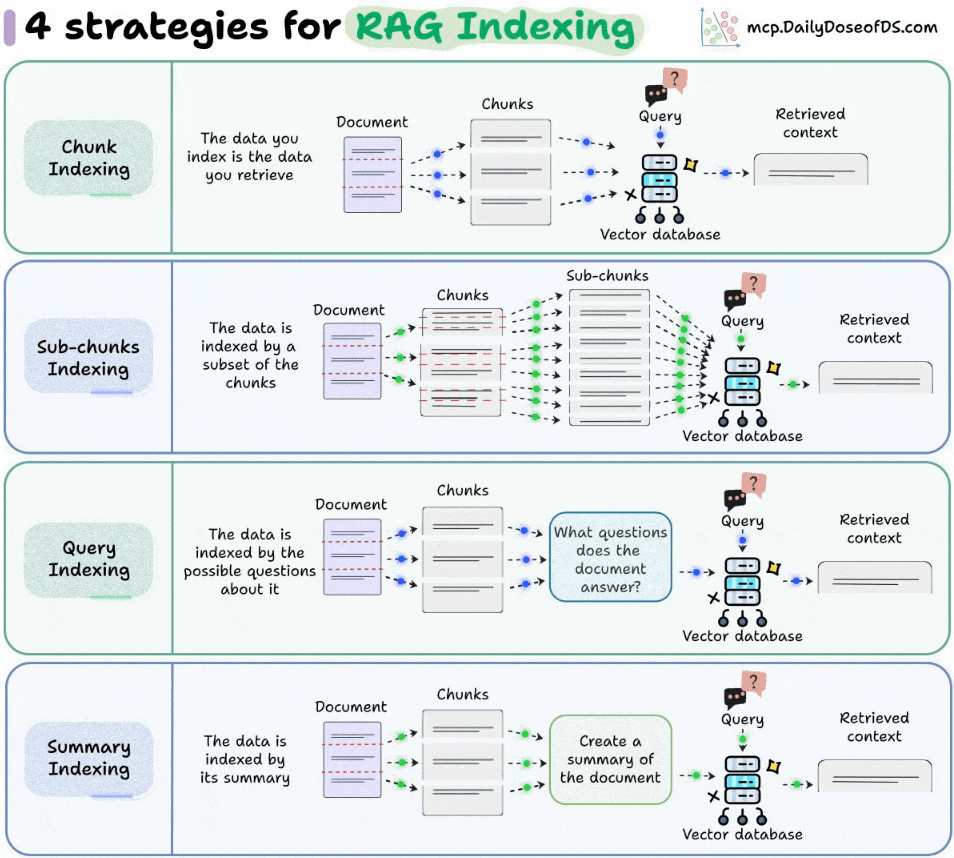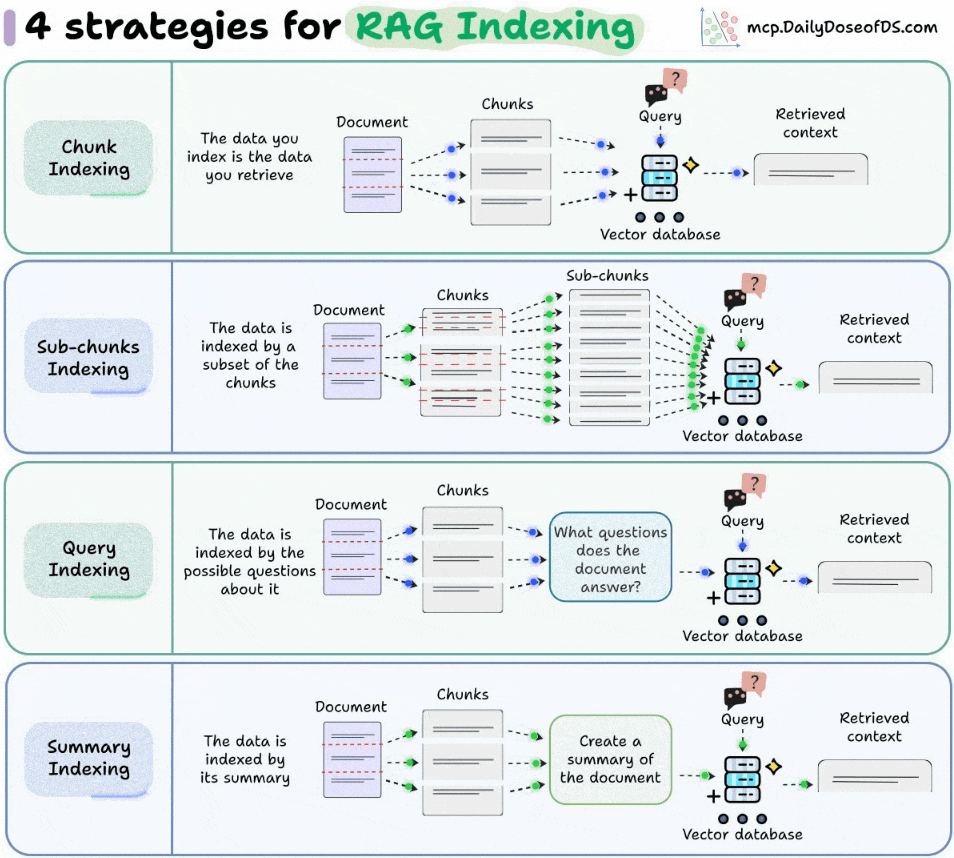
1) Chunk Indexing
The most common approach.
Split the doc into chunks, embed, and store them in a vector DB.
At query time, the closest chunks are retrieved directly.
This is simple and effective, but large or noisy chunks can reduce precision.
2) Sub-chunk Indexing
Take the original chunks and break them down further into sub-chunks.
Index using these finer-grained pieces.
Retrieval still gives you the larger chunk for context.
This helps when documents contain multiple concepts in one section, increasing the chances of matching queries accurately.
3) Query Indexing
Instead of indexing the raw text, generate hypothetical questions that an LLM thinks the chunk can answer.
Embed those questions and store them.
During retrieval, real user queries naturally align better with these generated questions.
A similar idea is also used in HyDE, but there, we match a hypothetical answer to the actual chunks.
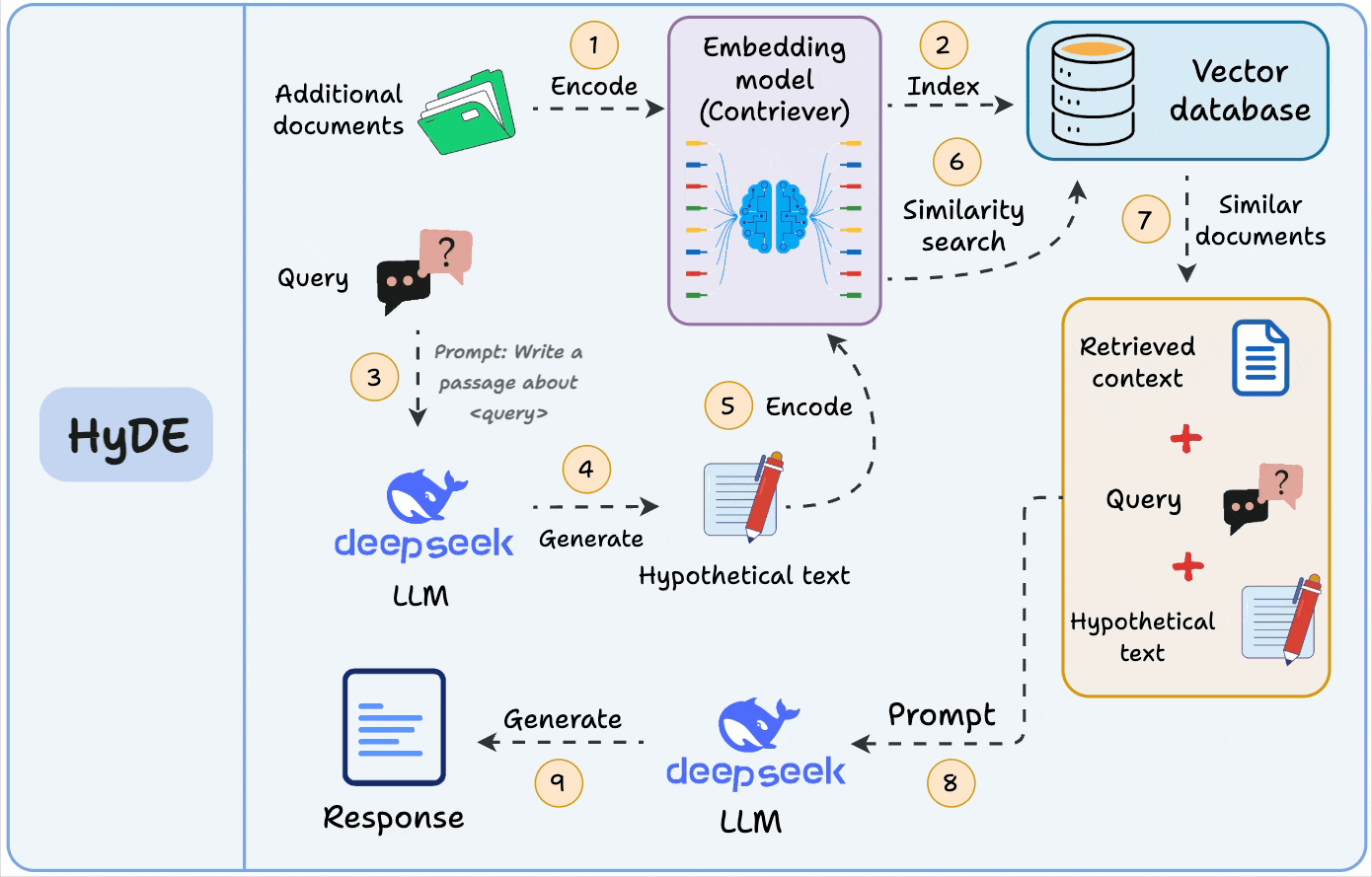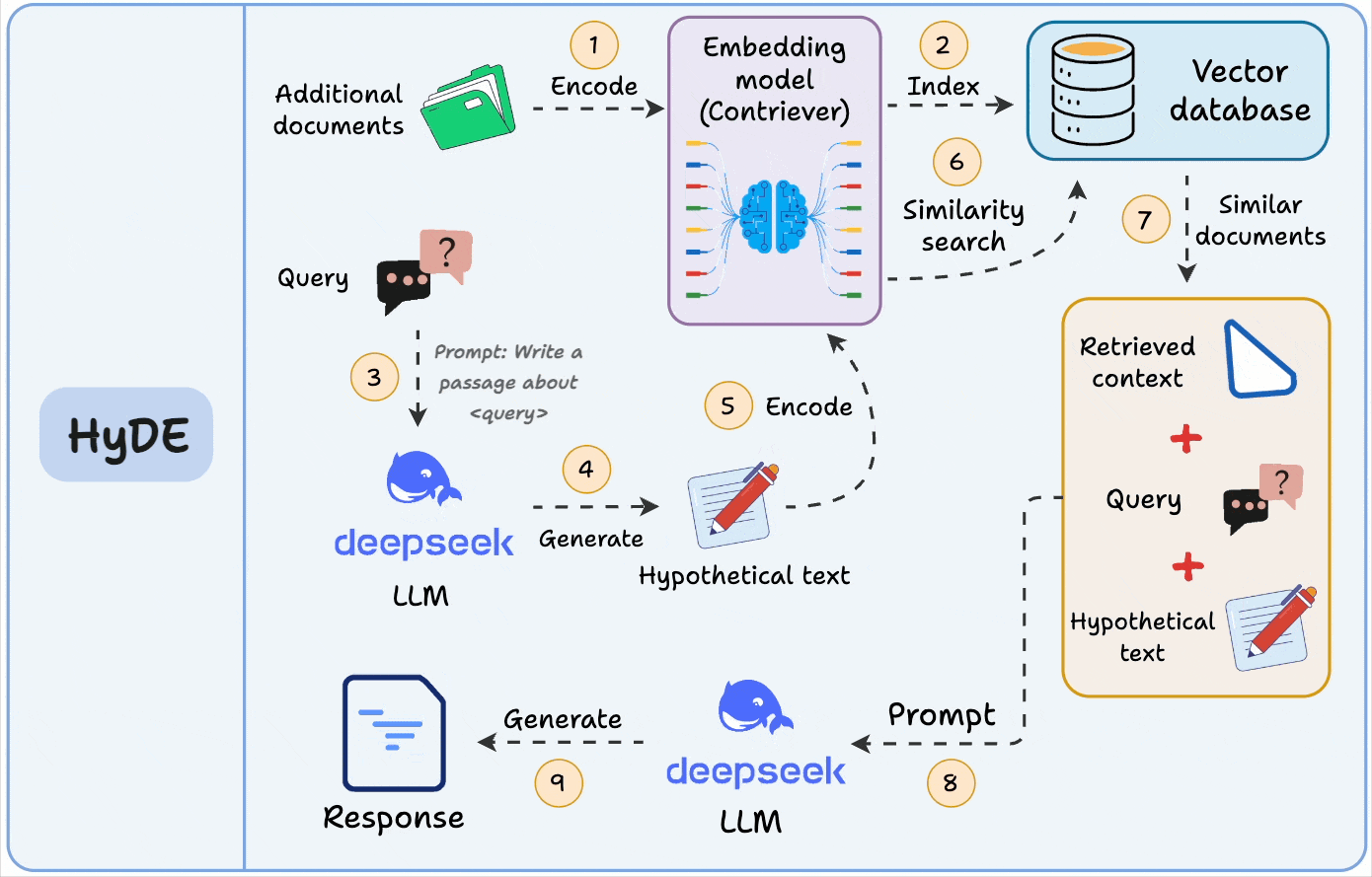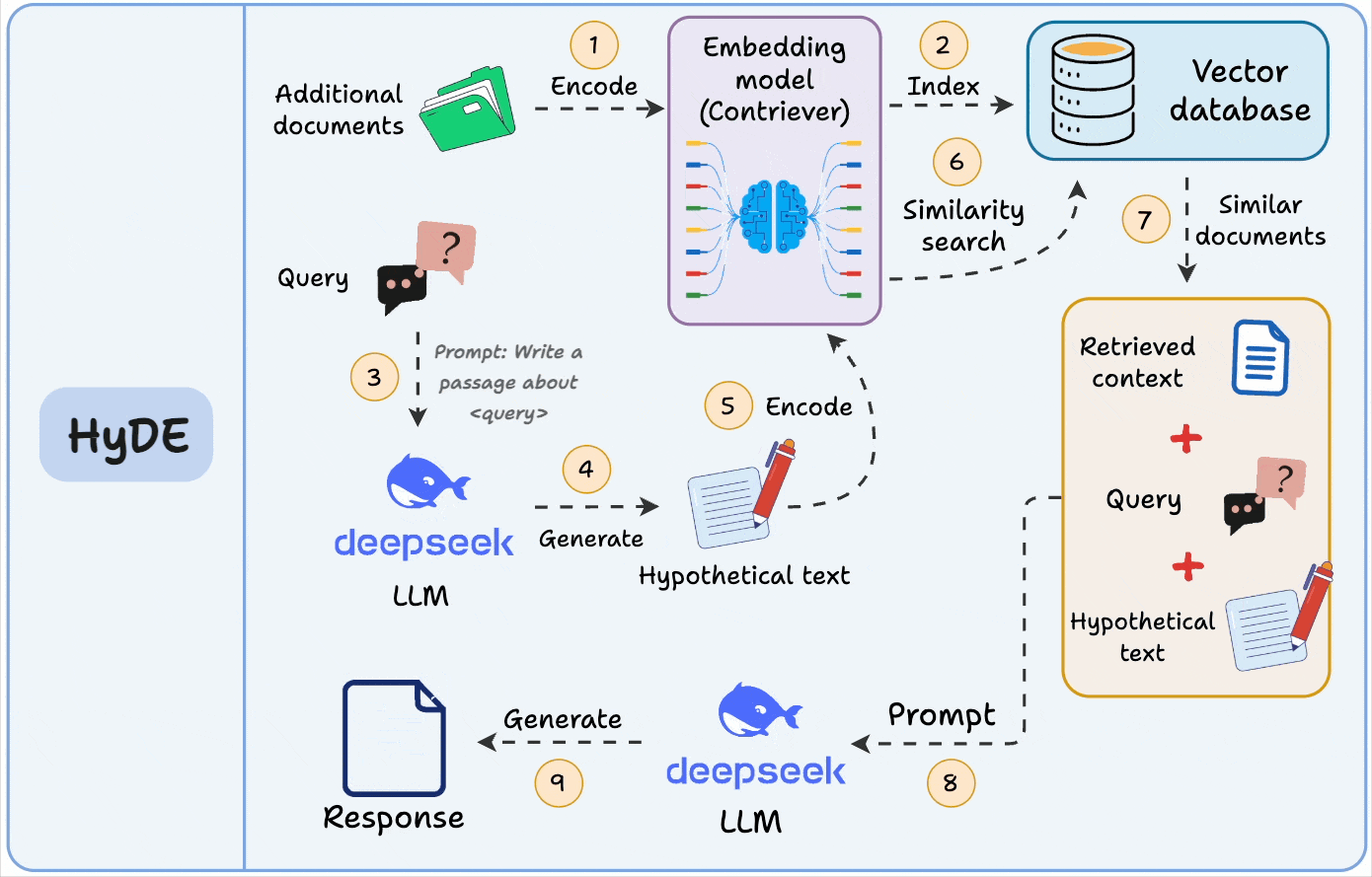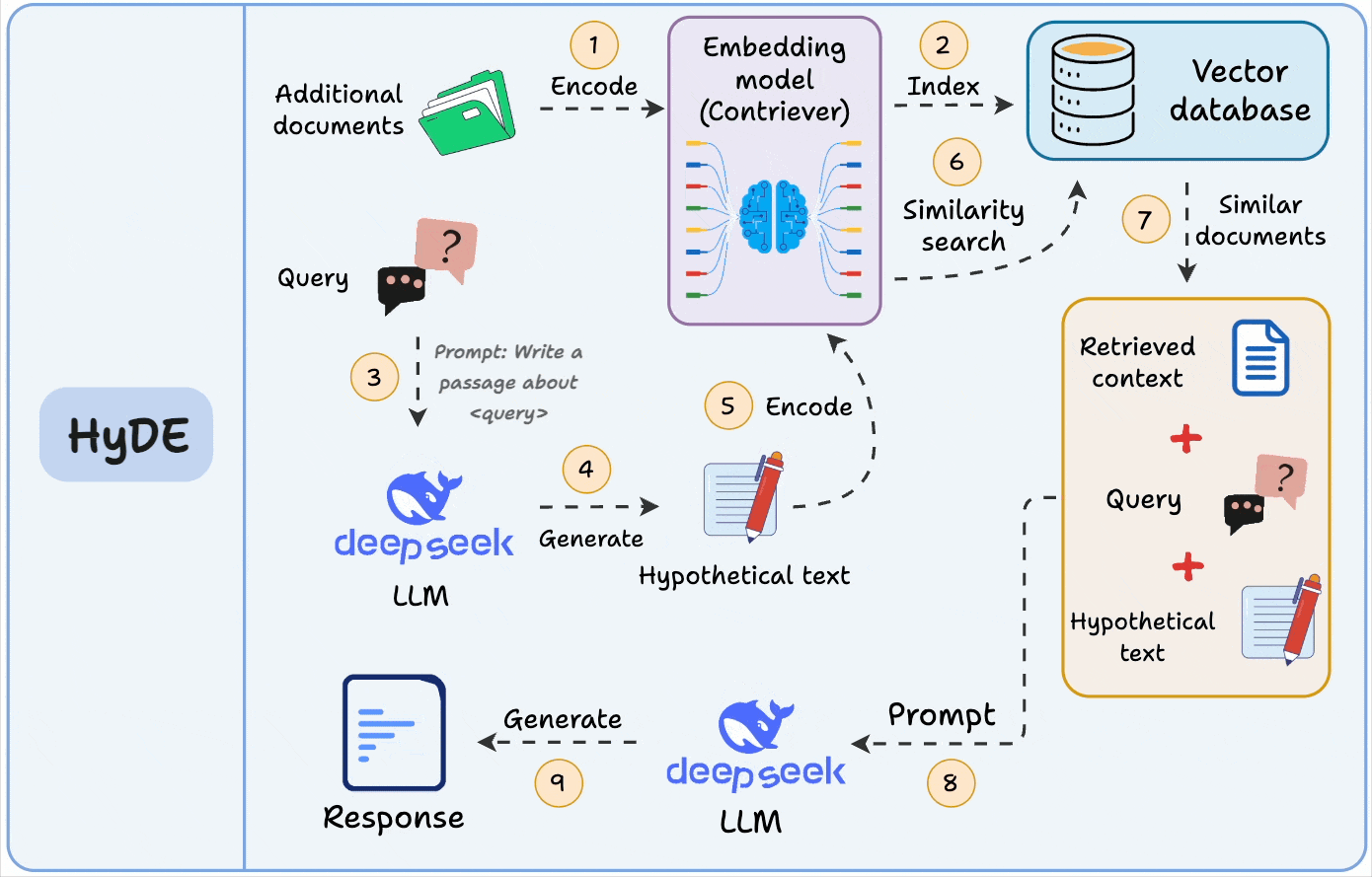
This is great for QA-style systems, since it narrows the semantic gap between user queries and stored data.
4) Summary Indexing
Use an LLM to summarize each chunk into a concise semantic representation.
Index the summary instead of the raw text.
Retrieval still returns the full chunk for context.
This is particularly effective for dense or structured data (like CSVs/tables) where embeddings of raw text aren’t meaningful.
👉 Over to you: What are some strategies that you commonly use for RAG indexing?
On a side note, we did a beginner-friendly crash course on RAGs recently with implementations, which covers:
Thanks for reading!