


A Common Industry Problem: Identify Fuzzy Duplicates in a Data with Million Records
A clever technique to optimize the deduplication algorithm.

Data duplication is a big problem that many organizations face.
This creates problems because:
It wastes storage space.
It can lead to incorrect data analysis.
It can result in reporting errors and more.
As you are reading this, you might be thinking that we can remove duplicates by using common methods like df.drop_duplicates().

But what if the data has fuzzy duplicates?
Fuzzy duplicates are those records that are not exact copies of each other, but somehow, they appear to be the same. This is shown below:

The Pandas method will be ineffective because it will only remove exact duplicates.
So what can we do here?
Let’s imagine that your data has over a million records.
How would you identify fuzzy duplicates in this dataset?
One way could be to naively compare every pair of records, as depicted below:

We can formulate a distance metric for each field and generate a similarity score for each pair of records.
But this approach is infeasible at scale.
For instance, on a dataset with just a million records, comparing every pair of records will result in 10^12 comparisons (n^2).
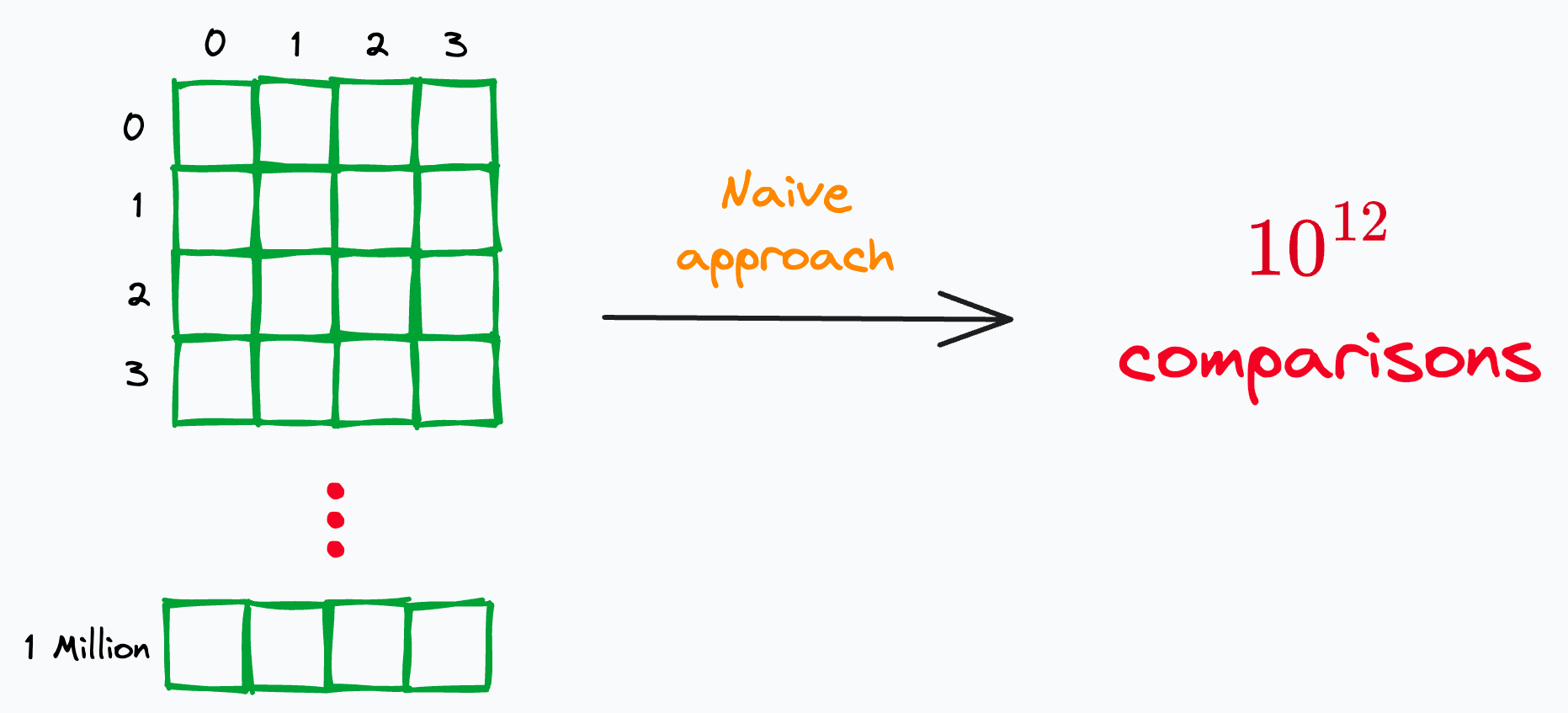
Even if we assume a decent speed of 10,000 comparisons per second, this approach will take ~3 years to complete.
Can we do better?
Of course we can!
But first, we need to understand a special property of fuzzy duplicates.
If two records are duplicates, they will certainly possess some lexical (or textual) overlap.
For instance, consider the below dataset:

Here, comparing the name “Daniel” to “Philip” or “Shannon” to “Julia” makes no sense. There is literally no lexical overlap.
Thus, they are guaranteed to be distinct records.
This makes intuitive sense as well.
If we are calling two records as “duplicates,” there must be some lexical overlap.
Yet, the naive approach will still waste time in comparing them.
We can utilize this “lexical overlap” property of duplicates to cleverly reduce the total comparisons.
More specifically, we segregate the data into smaller buckets by applying some rules.
For instance, consider the above dataset again. One rule could be to create buckets based on the first three letters of the first name.

Thus, we will only compare two records if they are in the same bucket.
If the first three letters are different, the records will fall into different buckets. Thus, they won’t be compared at all.
After segregating the records, we would have eliminated almost 98-99% of unnecessary comparisons that would have happened otherwise.
The figure “98-99%” comes from my practical experience on solving this problem on a dataset of such massive size.
Finally, we can use our naive comparison algorithm on each individual bucket.

The optimized approach can run in just a few hours instead of taking years.
This way, we can drastically reduce the run time and still achieve great deduplication accuracy.
Isn’t that cool?
Of course, we would have to analyze the data thoroughly to come up with the above data split rules.
But what is a more wise thing to do:
Using the naive approach, which takes three years to run, OR,
Spending some time analyzing the data, devising rules, and running the deduplication approach in a few hours?
👉 Over to you: Can you further optimize this approach?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Formulating and Implementing the t-SNE Algorithm From Scratch.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Where Did The Assumptions of Linear Regression Originate From?
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
When I encountered fuzzy de-duplication in the past, it was usually sufficient to normalize the data. For phone numbers, you can remove all non-digit characters, and you can normalize addresses using a service like Smarty. Then do exact comparison. However, normalization might not be good enough for all types of data.
The method you provided is far from perfect. There are significantly better methods available for checking fuzzy matching with a specified number of errors. You can search for NMSLIB. We have developed our own method that surpasses NMSLIB, providing faster results and matching more strings. - Panna Lal Patodia, CEO, Patodia Infotech Private Limited