
A Common Misconception About Feature Scaling and Standardization
From the perspective of skewness.

Dicey Tech offers personalized support to help people find their role in the age of AI.
Over the last 5 years, Dicey Tech has helped thousands of students and professionals to:
showcase their unique skills through engaging portfolios, and
access projects, hackathons, and job opportunities.

Build your portfolio, access practice projects & hackathons, network, and find your ideal role with companies all over the world.
👉 Get started today, build your portfolio and find your ideal role in a few clicks for free: Dicey Tech.
Feature scaling and standardization are common ways to alter a feature’s range.
For instance:
MinMaxScaler shrinks the range to [0,1]:
Standardization makes the mean zero and standard deviation one, etc.
It is desired because it prevents a specific feature from strongly influencing the model’s output. What’s more, it ensures that the model is more robust to variations in the data.
In the image above, the scale of Income could massively impact the overall prediction. Scaling (or standardizing) the data to a similar range can mitigate this and improve the model’s performance.
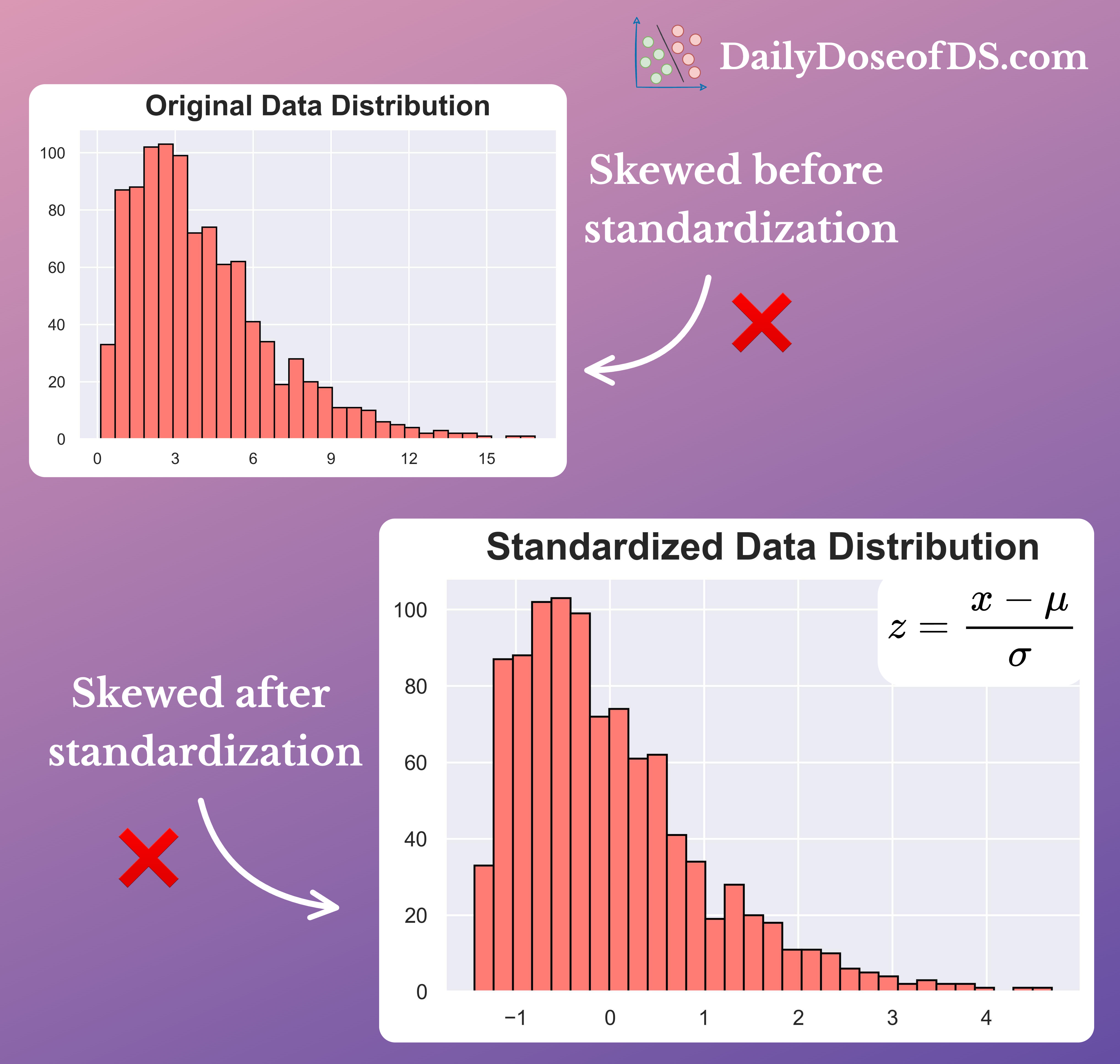
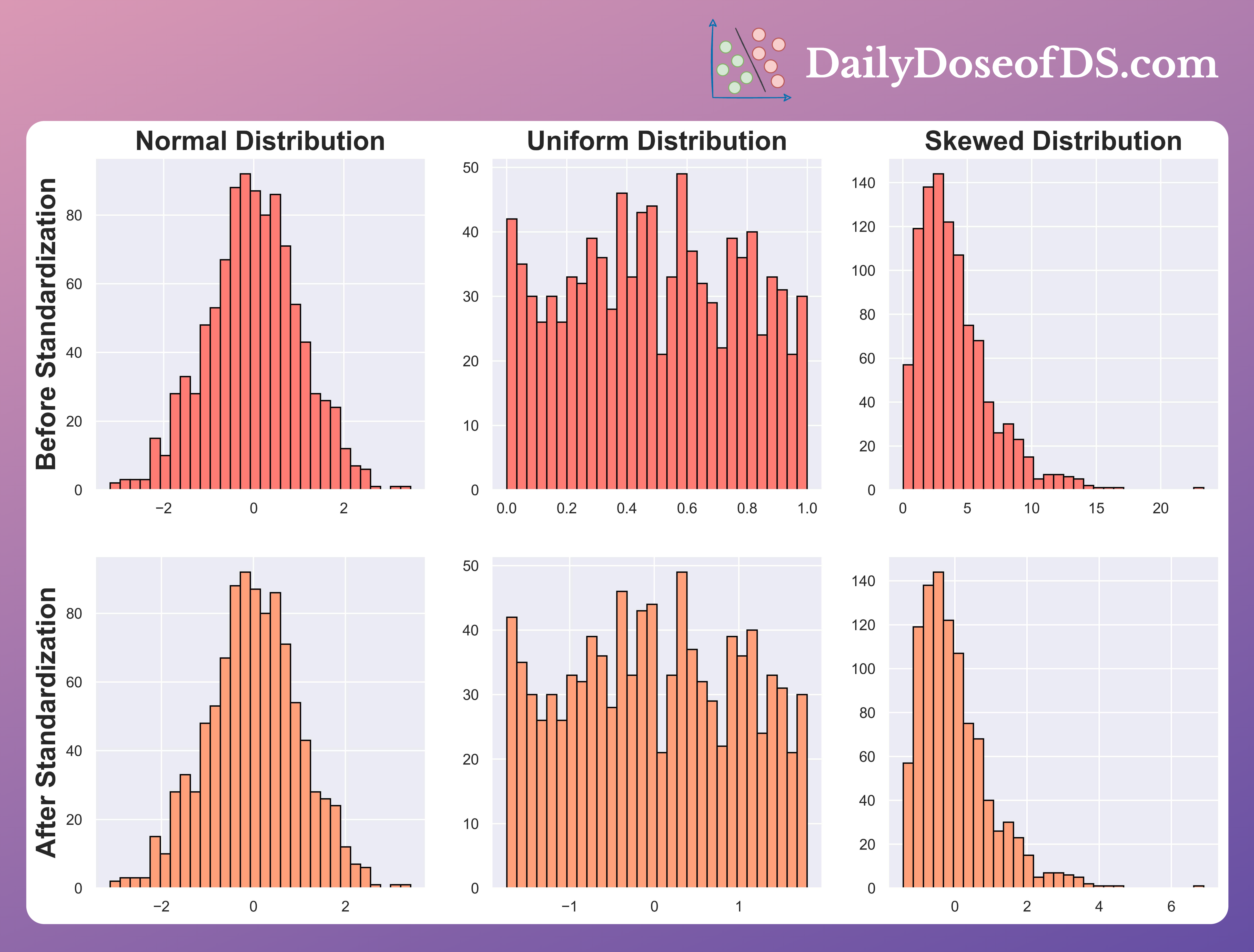
Yet, contrary to common belief, they NEVER change the underlying distribution.
Instead, they just alter the range of values.
Thus:
Normal distribution → stays Normal
Uniform distribution → stays Uniform
Skewed distribution → stays Skewed
and so on…
We can also verify this from the below illustration:
If you intend to eliminate skewness, scaling/standardization won’t help.
Try feature transformations instead.
I recently published a post on various transformations, which you can read here: Feature transformations.
👉 Over to you: While feature scaling is immensely helpful, some ML algorithms are unaffected by the scale. Can you name some algorithms?
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.