
A Common Mistake That Many Spark Programmers Commit and Never Notice
Extend your learnings from Pandas to Spark with caution.

When using Spark, many programmers commit a pretty common mistake that leads to severe performance bottlenecks.
In my experience, this mistake typically originates due to one’s familiarity with frameworks like Pandas, when they try to replicate their learnings from Pandas to Spark.

While they both operate on the same kind of data (tables), how they do so is significantly different, and it is essential to understand the distinction.
Let’s get into more detail in today’s issue.
Background
One can perform two types of operations in Spark:
Transformations: Creating a new DataFrame from an existing DataFrame.

Actions: These trigger the execution of transformations on DataFrames.

To give you more context, Spark utilizes actions because, unlike common DataFrame libraries like Pandas, Spark transformations follow lazy evaluation.
Lazy evaluation means that transformations do not produce immediate results.
Instead, the computations are deferred until an action is triggered, such as:
Viewing/printing the data.
Writing the data to a storage source.
Converting the data to Python lists, etc.
By lazily evaluating Spark transformations and executing them ONLY WHEN THEY ARE NEEDED, Spark can build a logical execution plan and apply any possible optimizations.
However, there is also an overlooked caveat here that can lead to redundant computations. As a result, it can drastically slow down the execution workflow of our Spark program, if not handled appropriately.
Let’s understand in more detail.
Issue with lazy evaluation
Consider reading a Spark DataFrame (A) from storage and performing a transformation on it, which produces another DataFrame (B).
Next, we perform two actions (count rows and view data) on DataFrame B, as depicted below:

This can be translated into the following code in PySpark:
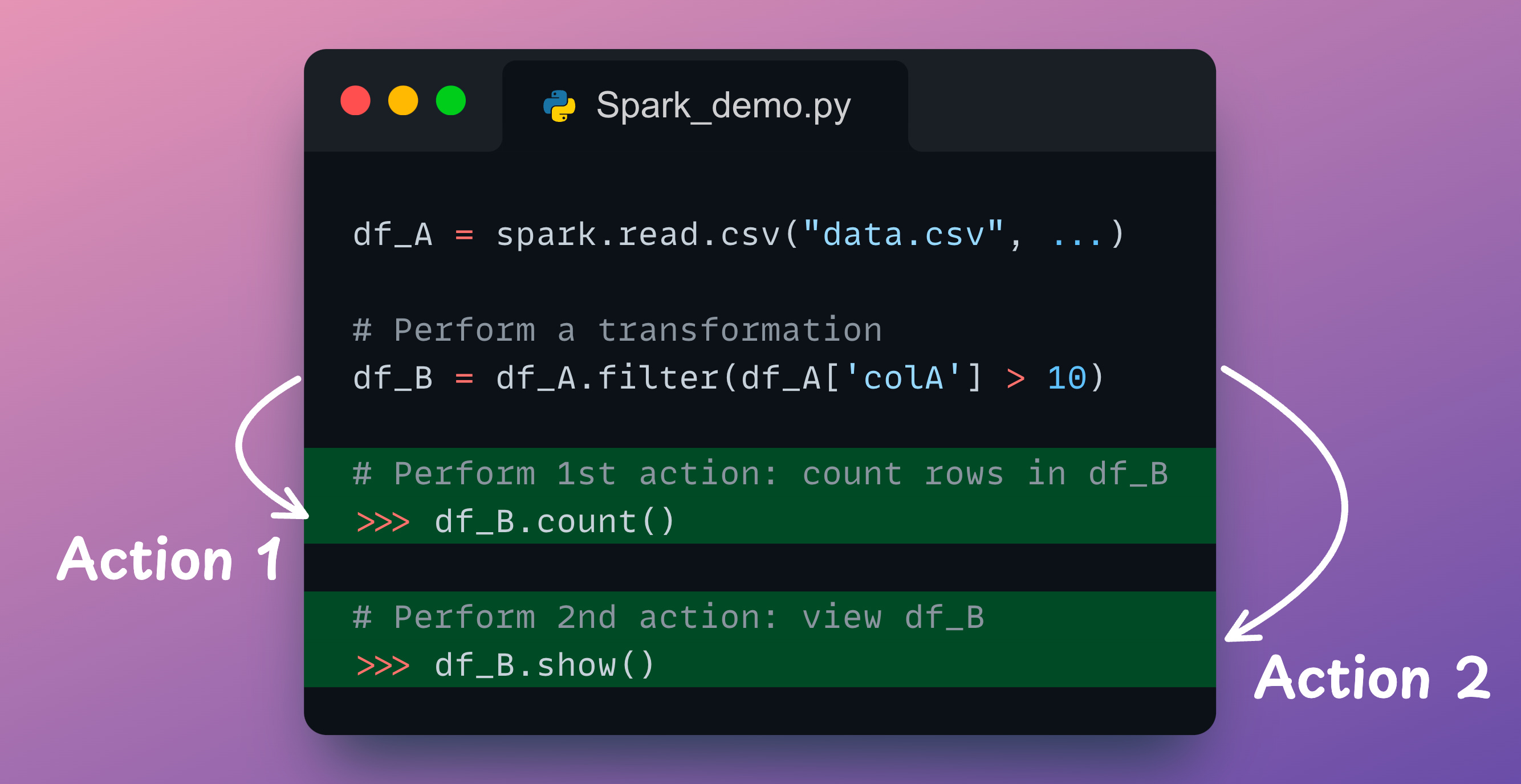
Now, recall what we discussed above: Actions trigger the execution of Spark transformations.
In the above code, the first action is df_B.count(), which triggers the CSV read operation and the filter transformation.
On a side note, as you may have already noticed, the execution methodology is quite different from how Pandas works. It does not provide lazy evaluation. Thus, every operation is executed right away.

Moving on, we have another action: df_B.show(). This action again triggers the CSV read operation and the filter transformation.
Do you see the problem?
We are reading the CSV file and performing the same transformation twice.
It is evident that when dealing with large datasets, this can lead to substantial performance bottlenecks.
Solution
One of the most common ways to address this is by using caching.
As the name suggests, it allows us to cache the results of Spark transformations in memory for later use.
The df.cache() method is the most common way to do this.
Note: In addition to
df.cache(), there’sdf.persist()method as well, which provides more flexibility for caching. But today we shall only discussdf.cache().
We can use the df.cache() method as follows:
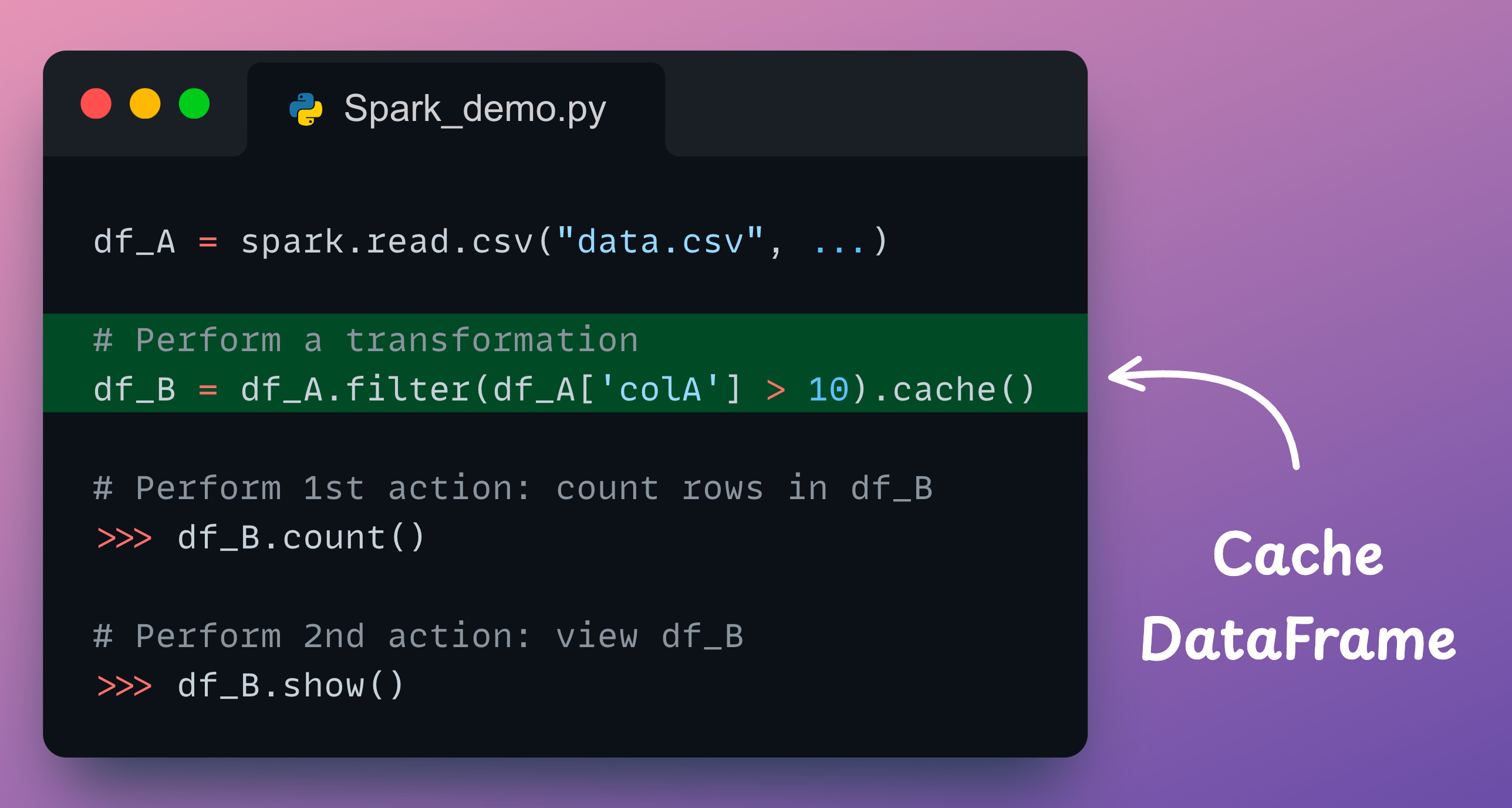
In this code, the first action (df_B.count()) triggers the CSV read operation and the filter transformation.
However, in contrast to the non-cached demonstration we discussed earlier, the results of the filter transformation get cached this time.
Moving on, the second action (df_B.show()) uses these cached results to show the contents of df_B.
It is easy to understand that caching eliminates redundant operations, which drastically improves the run-time.
Do note that the df.cache() method caches the DataFrame in memory.
Thus, it is advised to release the cached memory once it is no longer needed. We can use the df.unpersist() method for this:

That said, Spark is among the most sought-after skills by data science employers. Adding Spark to your skillset will be extremely valuable in your data science career ahead.

I recently wrote a complete deep dive (102 mins read) on PySpark: Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
If you are a complete beginner and have never used Spark before, it’s okay. The article covers everything.
👉 Over to you: What are some other overlooked Spark optimization techniques?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!