
A Counterintuitive Behaviour of PyTorch DataLoader
...which most PyTorch users aren't aware of.

Every PyTorch user heavily uses DataLoaders in their model training workflow.
However, there is one hidden detail, which, in my experience, isn’t known to most Pytorch users and, as a result, can adversely affect the training run-time.
I have been using PyTorch for several years, and even I accidentally learned this three weeks back while optimizing the training procedure.
What I am about to share will sound quite counterintuitive.
Let’s dive in!
Background
In PyTorch, the standard procedure to use a DataLoader is as follows:
First, we have some import statements:

Next, we define a custom dataset class, which is inherited from the
Datasetclass, and some magic methods to obtain the size of the dataset and fetch a training instance using its index:

Finally, we define the transformation object, instantiate the dataset object, and its
DataLoader, as follows:
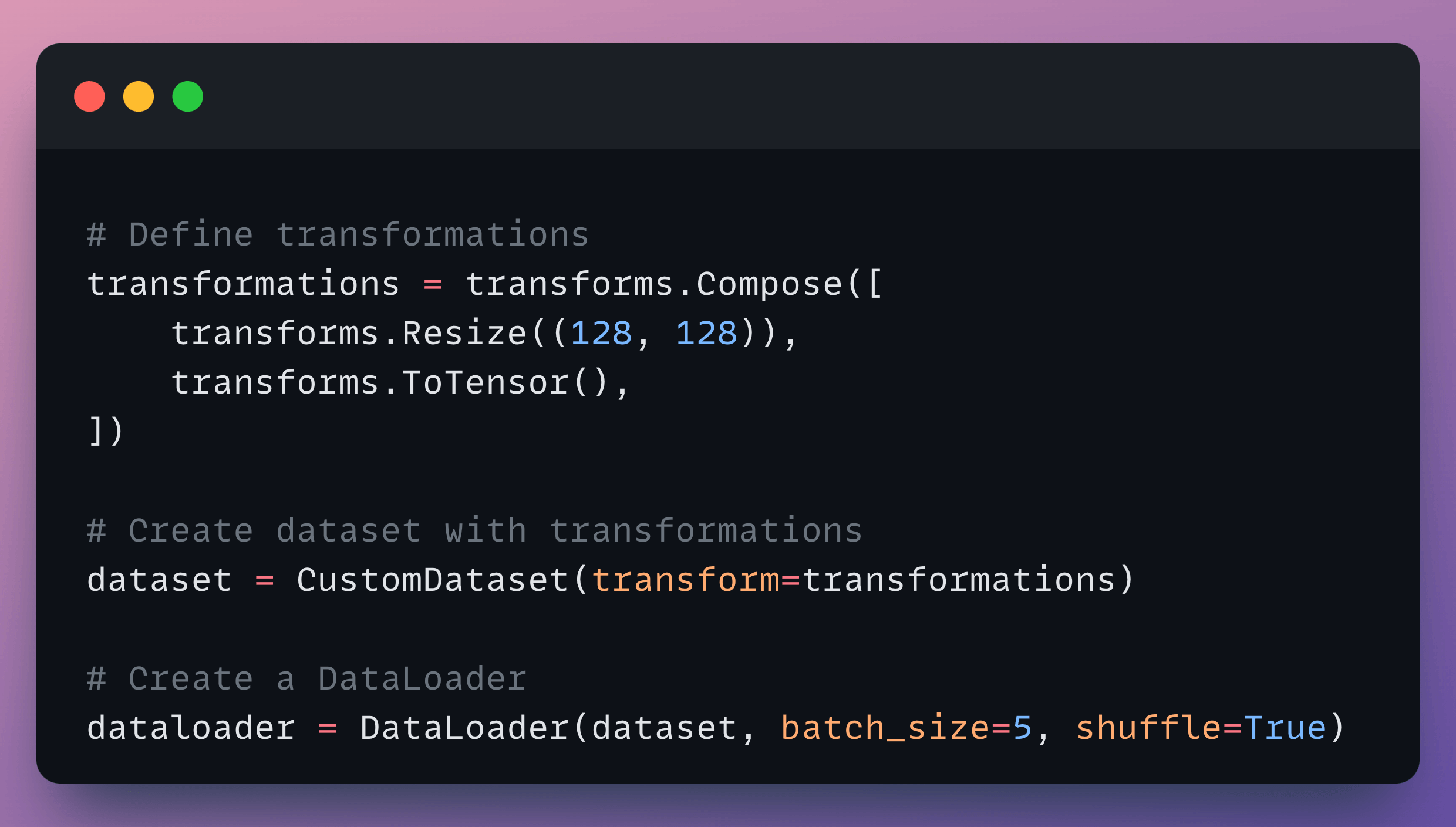
Done!
From here on, the standard procedure is to iterate over the above dataloader object, generate batches, and train the model as follows:

Since the dataset had 10 training instances and the batch size we defined in the dataloader was 5, we get 2 mini-batches, each with 5 training instances.
Looks good, right?
Well, not really, and let me show you what I mean.
Consider the dataset class we defined earlier, and let’s add an additional line of code here:

After redefining the dataloader object, look at the output we get this time when we iterate over it:

The highlighted output in the above image depicts that PyTorch is applying the transformation on the fly.
And the worst part is that the same input is transformed again in the next epoch, which, in many cases, might not be needed, leading to redundant computations.
The above observation is quite contrary to a pretty common belief (which even I had) that these transformations are always applied right at the time we define the dataloader object.
But this isn’t the case:

I discovered this pretty recently accidentally.
A single epoch on my dataset took approximately 30-35 minutes, which appeared too long.
So I profiled my code with PyTorch profiler, which highlighted that a significant proportion of computing was dedicated to iterating over the dataloader:

This appeared weird since I was not expecting fetching a mini-batch to be this intensive.
How I solved it?
I hardly found any clue about this in the PyTorch docs. But this answer on StackOverflow helped, and here’s what it suggested:
Transform the dataset beforehand using libraries like NumPy (or defined custom tensor operations using PyTorch.
Create the
dataloaderobject using the transformed dataset instead. Thus, no transformations should be specified when defining the dataset (if the transformation depends on the mini-batch, then it makes sense to use the standard procedure of PyTorch).
This solved the problem:

A departing note
Abstraction is heavily promoted as a core pillar of object-oriented programming in software projects (the other three being encapsulation, inheritance, and polymorphism).
Nothing wrong.
But in my experience, I have had some really terrible experiences (like the one I shared above) using open-source frameworks when so much functionality is abstracted from the programmer…
…and things get worse when the underlying details (or cautionary measures) that have been abstracted aren’t communicated by the developers/maintainers.
I hardly found any clue about this in the PyTorch docs.
Also, to the best of my knowledge, there’s no parameter to execute the transformations at the time of defining the dataloader.
Of course, there are some reasons why PyTorch adopted this design.
I will explain this in a newsletter issue in the future.
👉 In the meantime, it’s over to you: Can you tell why PyTorch dataloader performs transformations on the fly?
Hope you learned something new today!
That said, if ideas related to production and deployment intimidate you, here’s a quick roadmap to upskill you (assuming you know how to train a model):
First, you would have to compress the model and productionize it. Read these guides:
Model Compression: A Critical Step Towards Efficient Machine Learning.
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
If you use sklearn, here’s a guide that teaches you to optimize models like decision trees with tensor operations: Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Next, you move to deployment. Here’s a beginner-friendly hands-on guide that teaches you how to deploy a model, manage dependencies, set up model registry, etc.: Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
Although you would have tested the model locally, it is still wise to test it in production. There are risk-free (or low-risk) methods to do that. Read this to learn them: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
For those who want to build a career in DS/ML on core expertise, not fleeting trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 87,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Thanks 👍
I have a question. The hack you proposed is great, but we actually need the on-fly transformations every single epoch assuming that we are using a scholastic augmentation (e.g.RandAugment()) to expose the model to new alterations every single training step, which is the common approach everywhere as it significantly boosts model's generalization ability.