
A Crash Course on Building RAG Systems – Part 4
Beginner-friendly and with implementation.

Earlier this month, we started a crash course on building RAG systems.
Part 4 is now available, where we are building RAG on multimodal data.
Read here: A Crash Course on Building RAG Systems – Part 4 (With Implementation).

More specifically, in this part, we are looking at strategies that help us ingest complex documents in RAG that contain tables, texts, and images.

Read here: A Crash Course on Building RAG Systems – Part 4 (With Implementation).
What's in the crash course?
So far in this crash course series on building RAG systems, we’ve logically built on the foundations laid in the previous parts:
In Part 1, we explored the foundational components of RAG systems, the typical RAG workflow, and the tool stack, and also learned the implementation.
In Part 2, we understood how to evaluate RAG systems (with implementation).
In Part 3, we learned techniques to optimize RAG systems and handle millions/billions of vectors (with implementation).
[Latest part] In Part 4, we are diving into multimodality and covering techniques to build RAG systems on complex docs—ones that have images, tables, and texts (with implementation):

So even if you are a complete beginner at RAG, it has you covered.
Why care about RAG?
RAG is a key NLP system that got massive attention due to one of the key challenges it solved around LLMs.
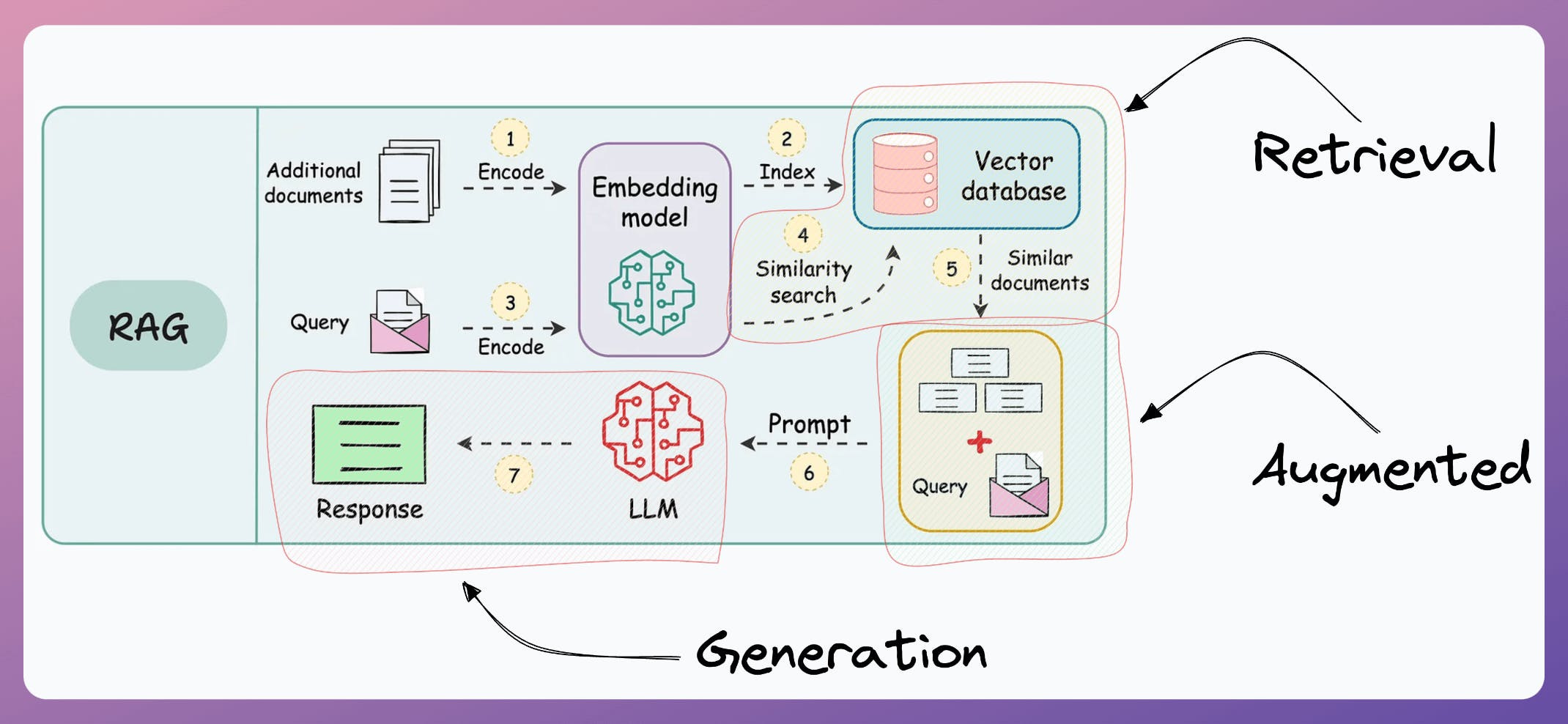
More specifically, if you know how to build a reliable RAG system, you can bypass the challenge and cost of fine-tuning LLMs.
That’s a considerable cost saving for enterprises.
And at the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
Thus, the objective of this crash course is to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
Read the first part here →
Read the second part here →
Read the third part here →
Read the fourth part here →
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 110,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.