
A crash course on RAG systems—Part 8
...with implementation.

Part 8 of our RAG crash course is now available.
Read here: A Crash Course on Building RAG Systems – Part 8 (With Implementation).
What's inside Part 8?
This time, we are working on improving rerankers, which are extremely critical in RAG systems:

Here, a sophisticated model evaluates and rearranges the retrieved chunks so that the most relevant ones are prioritized for response generation.
Traditionally, there have been ways to do so:
1) Cross-encoders → Highly accurate but no scalability.
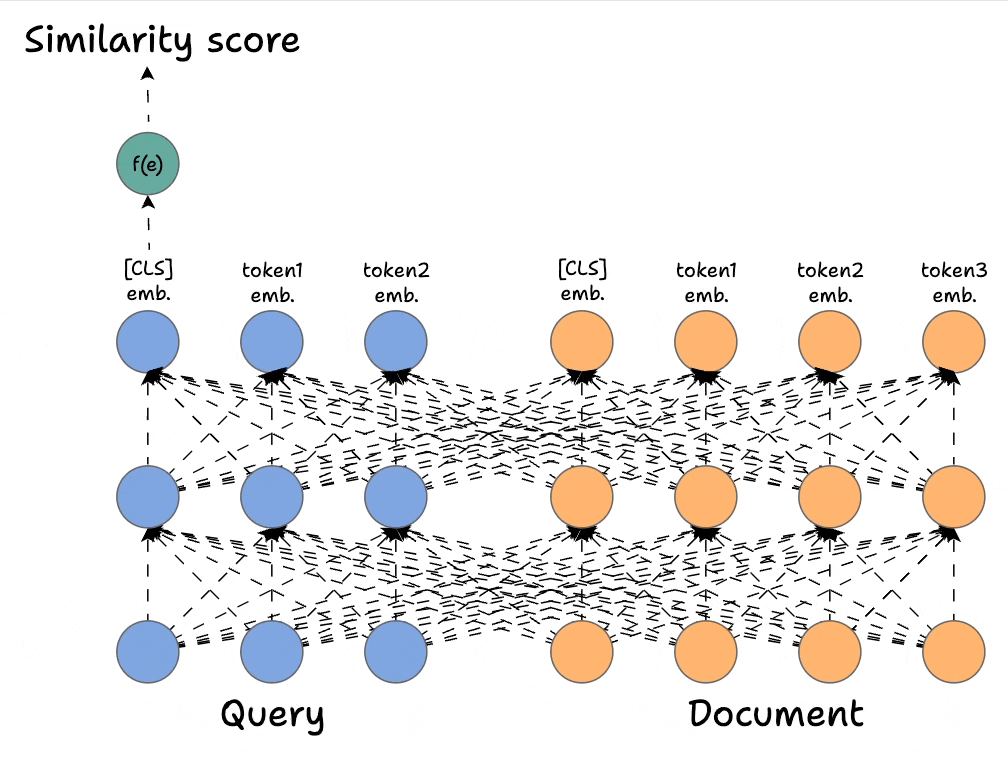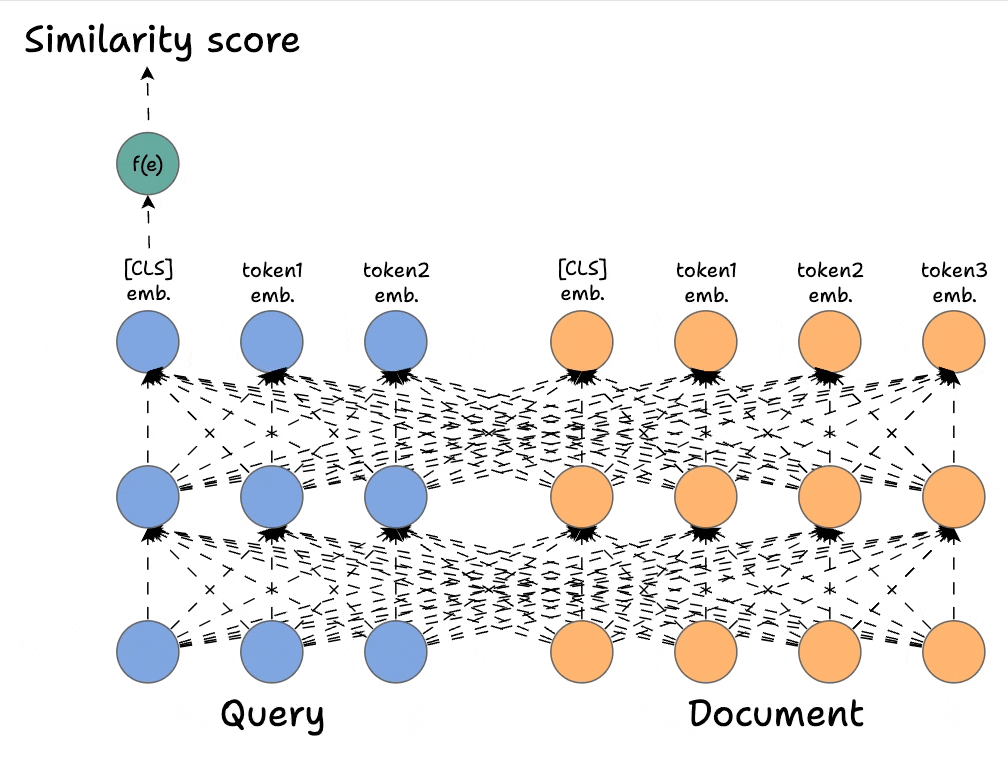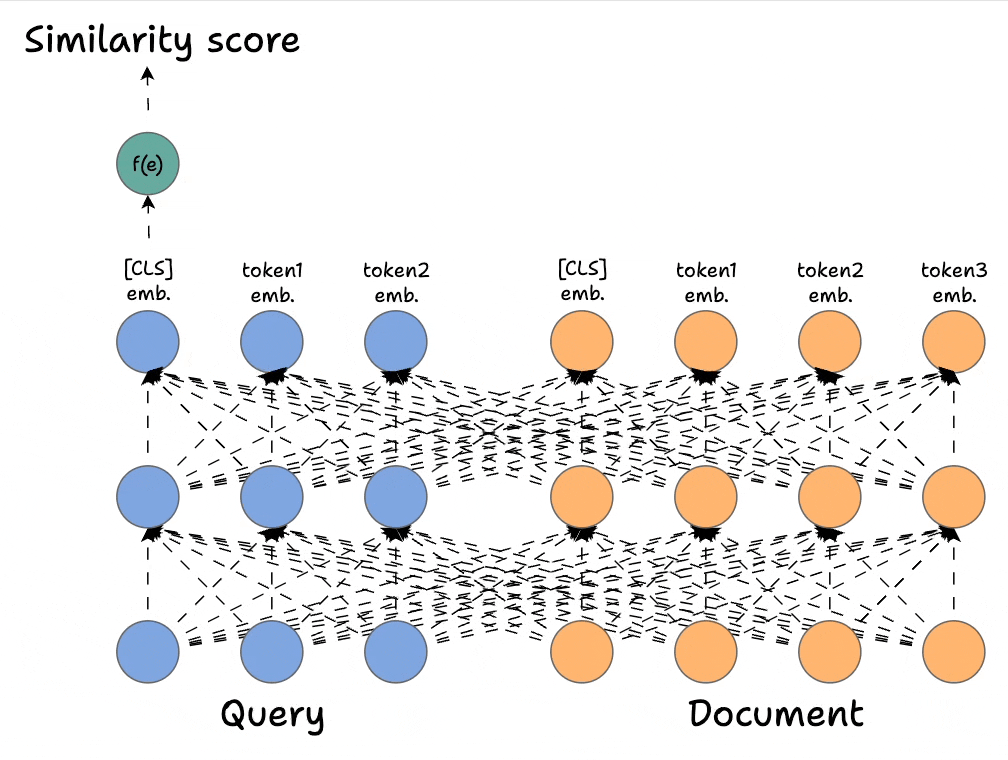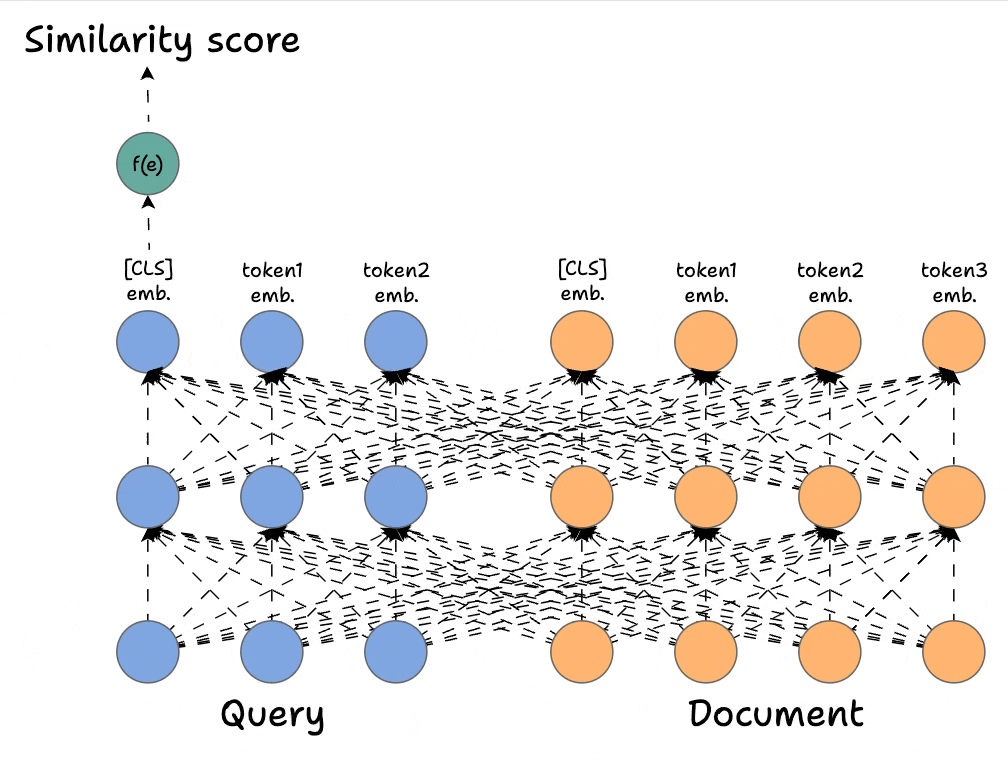
2) Bi-encoders → Highly scalable but largely compromise accuracy.
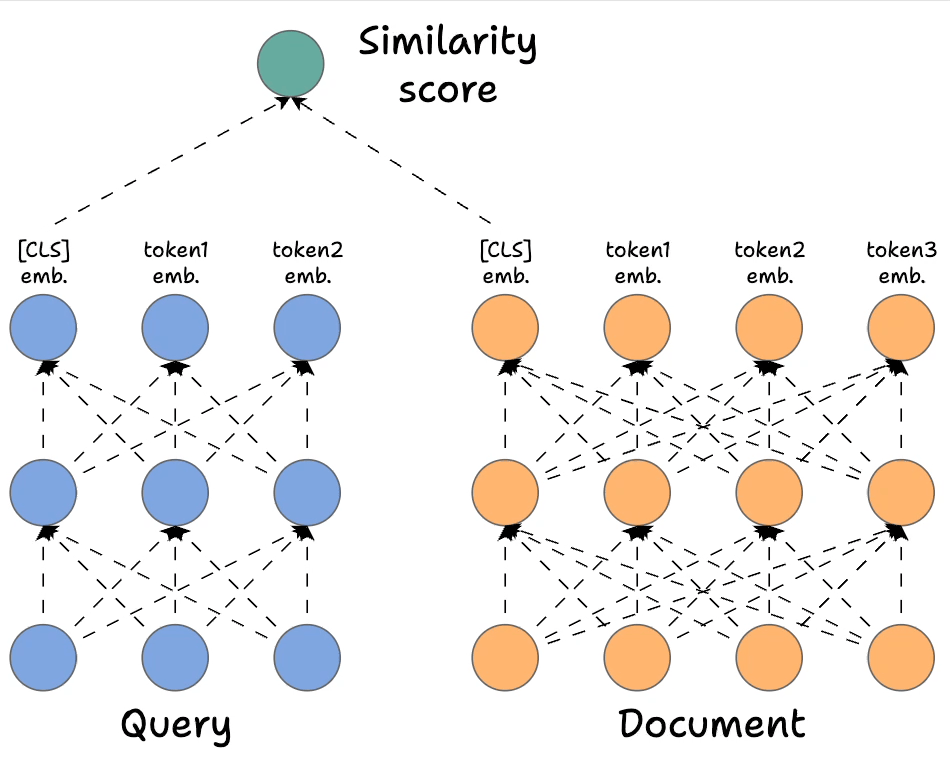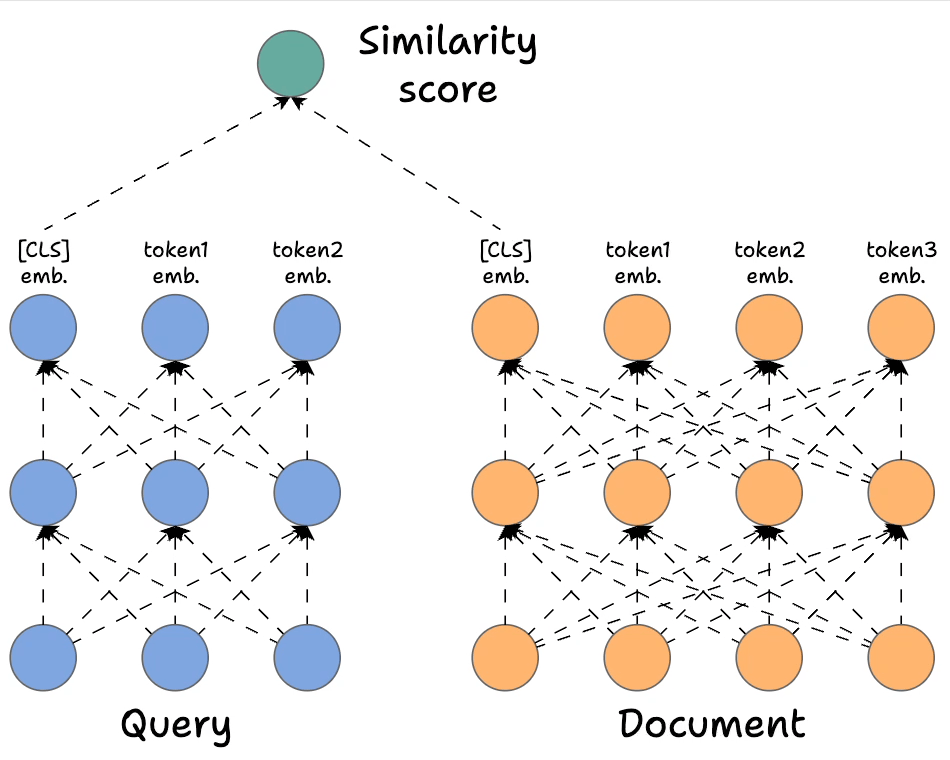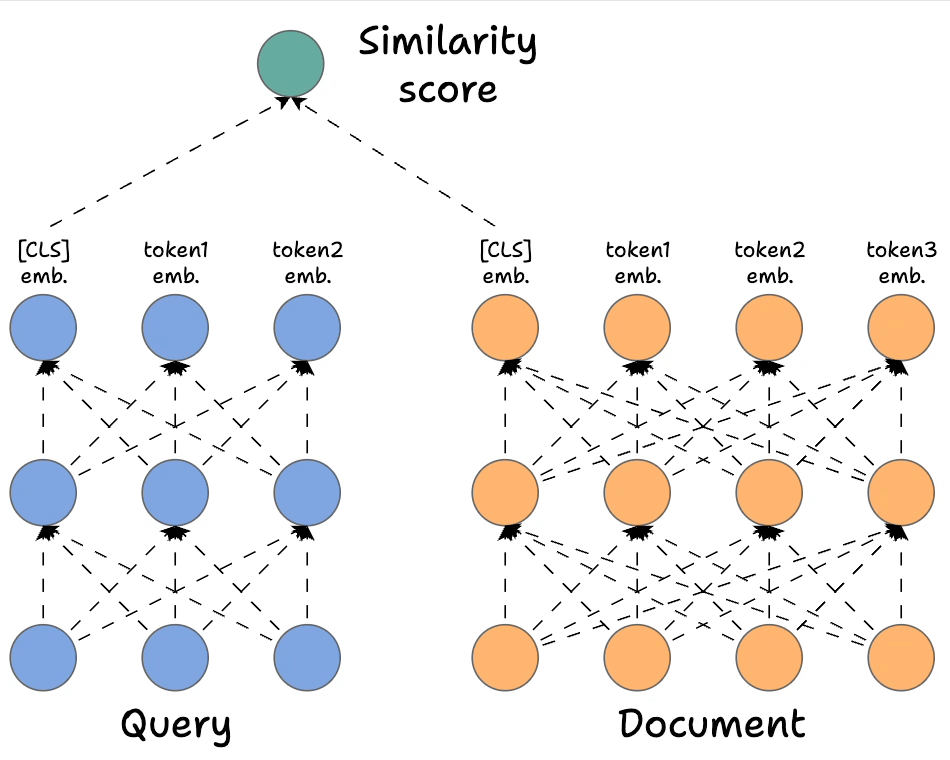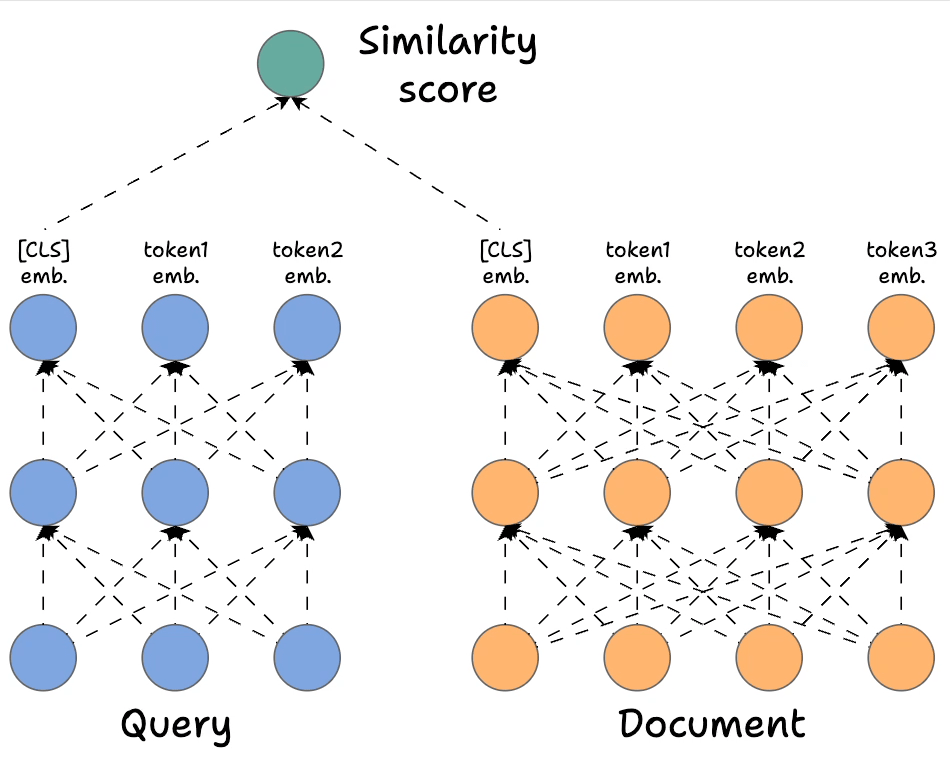
ColBERT takes the best of both.
In Part 8, we are doing a deep architectural breakdown of ColBERT, and how it offers a highly scalable and accurate solution for reranking modules in RAG.

Like always, we'll dive into the motivation of rerankers and then cover an implementation of the ColBERT in the RAG system, which is completely beginner-friendly.
Read here: A Crash Course on Building RAG Systems – Part 8 (With Implementation).
What's in the crash course?
So far in this crash course series on building RAG systems, we’ve logically built on the foundations laid in the previous parts:
In Part 1, we explored the foundational components of RAG systems, the typical RAG workflow, and the tool stack, and also learned the implementation.
In Part 2, we understood how to evaluate RAG systems (with implementation).
In Part 3, we learned techniques to optimize RAG systems and handle millions/billions of vectors (with implementation).
In Part 4, we understood multimodality and covered techniques to build RAG systems on complex docs—ones that have images, tables, and texts (with implementation)
In Part 5, we understood the fundamental building blocks of multimodal RAG systems that will help us improve what we built in Part 4.
In Part 6, we utilized the learnings from Part 5 to build a much more extensive multimodal RAG system.
In Part 7, we learned how to build graph RAG systems. Here, we utilized a graph database to store information in the form of entities and relations, and build RAG apps over.

So, even if you are a complete beginner at RAG, it has you covered.
Why care about RAG?
RAG is a key NLP system that got massive attention due to one of the key challenges it solved around LLMs.
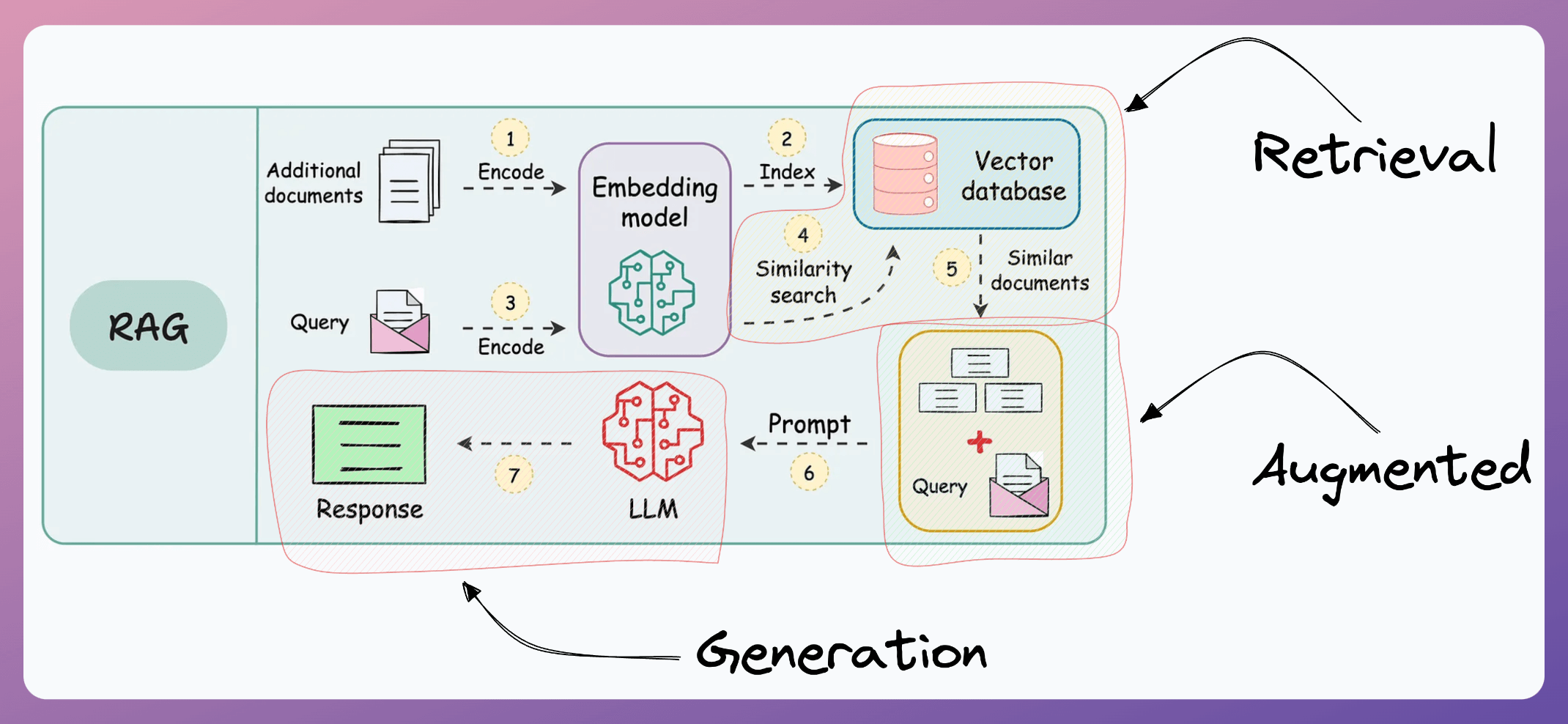
More specifically, if you know how to build a reliable RAG system, you can bypass the challenge and cost of fine-tuning LLMs.
That’s a considerable cost saving for enterprises.
And at the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
Thus, the objective of this crash course is to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
Read the first part here →
Read the second part here →
Read the third part here →
Read the fourth part here →
Read the fifth part here [OPEN ACCESS] →
Read the sixth part here →
Read the seventh part here →
Read the eighth part here →
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
Thanks for reading!