
A Foundational Guide to Evaluation of LLM Apps
...covering challenges and practical taxonomy.

Part 9 of the full LLMOps course is now available, where we explore evaluation methods and approaches for LLM-based applications. This chapter, in particular, focuses on building a strong understanding of the fundamental concepts.
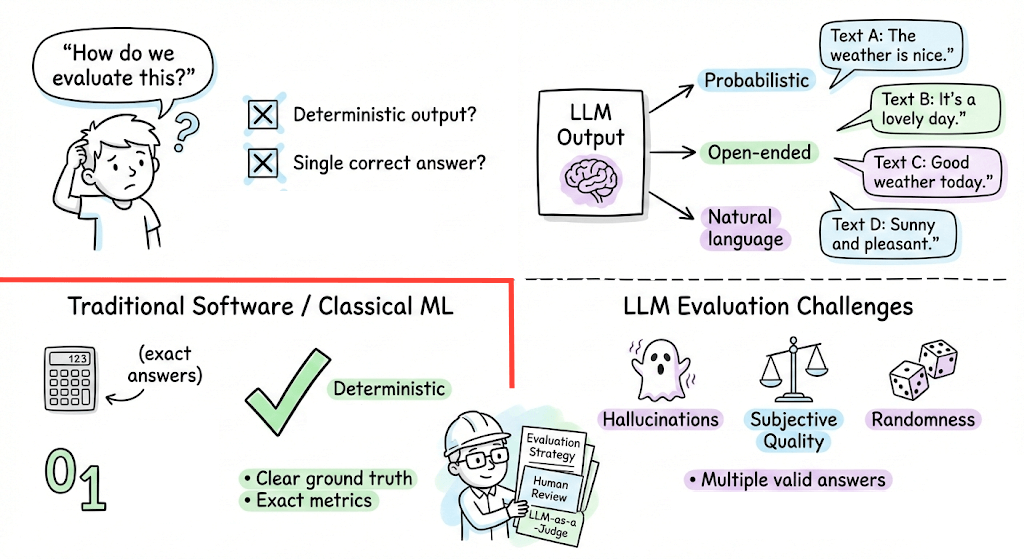
It also covers hands-on code demos to make the evaluation feel concrete, while covering the evolution of evaluation metrics for language-based applications over the years.
Why care?
The rules of production ML have been rewritten.
A few years ago, taking a model to production meant managing training pipelines, monitoring data drift, and versioning artifacts you fully controlled.
Today, the model is likely someone else’s. The inputs are natural language. The outputs are non-deterministic.
This shift broke a lot of assumptions. The practices that made traditional ML systems reliable don’t fully translate. New failure modes emerged, which most teams learn about the hard way.
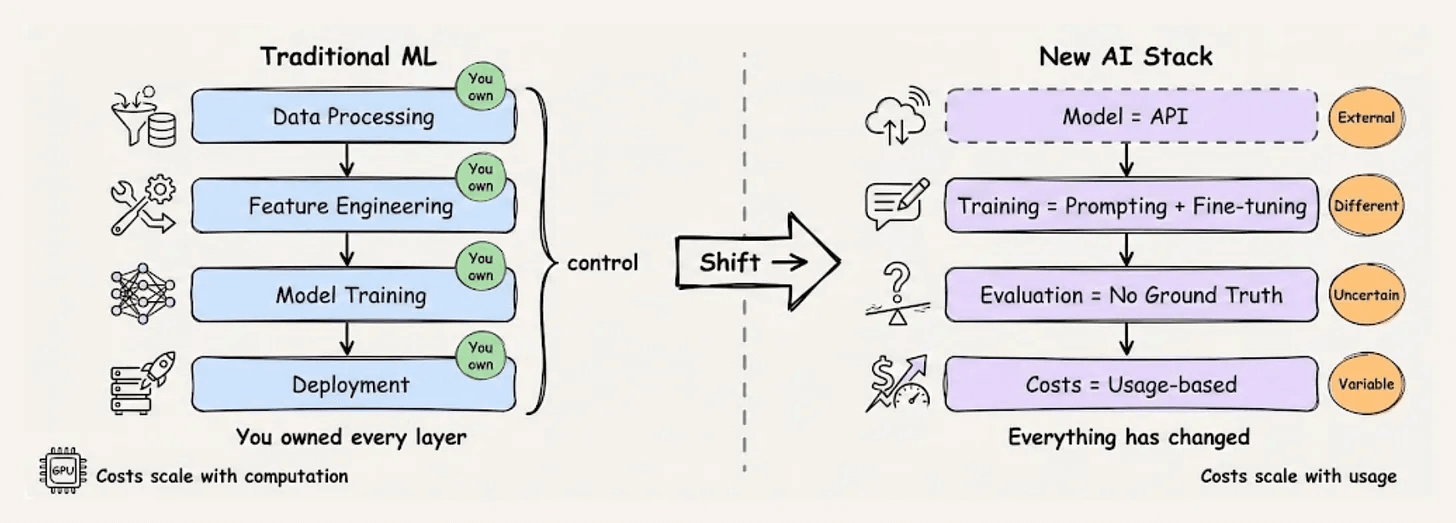
LLMOps is the emerging discipline addressing this gap. It’s not about abandoning what we learned from MLOps, but extending it for a world where foundation models are the building blocks.
This course builds that extended foundation, giving you the systems-level thinking and practical implementations to build LLM applications that hold up in production.
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
As we progress, we will see how we can develop the critical thinking required for taking our applications to the next stage and what exactly the framework should be for that.
👉 Over to you: What would you like to learn in the LLMOps course?
Thanks for reading!