
A Guide to Evaluating MCP-powered LLM Apps
...explained with step-by-step code.

Scrape the web based on search categories
With Firecrawl, you can now filter your searches by categories, like finding research papers, GitHub repos, etc.
Here’s how to do it:
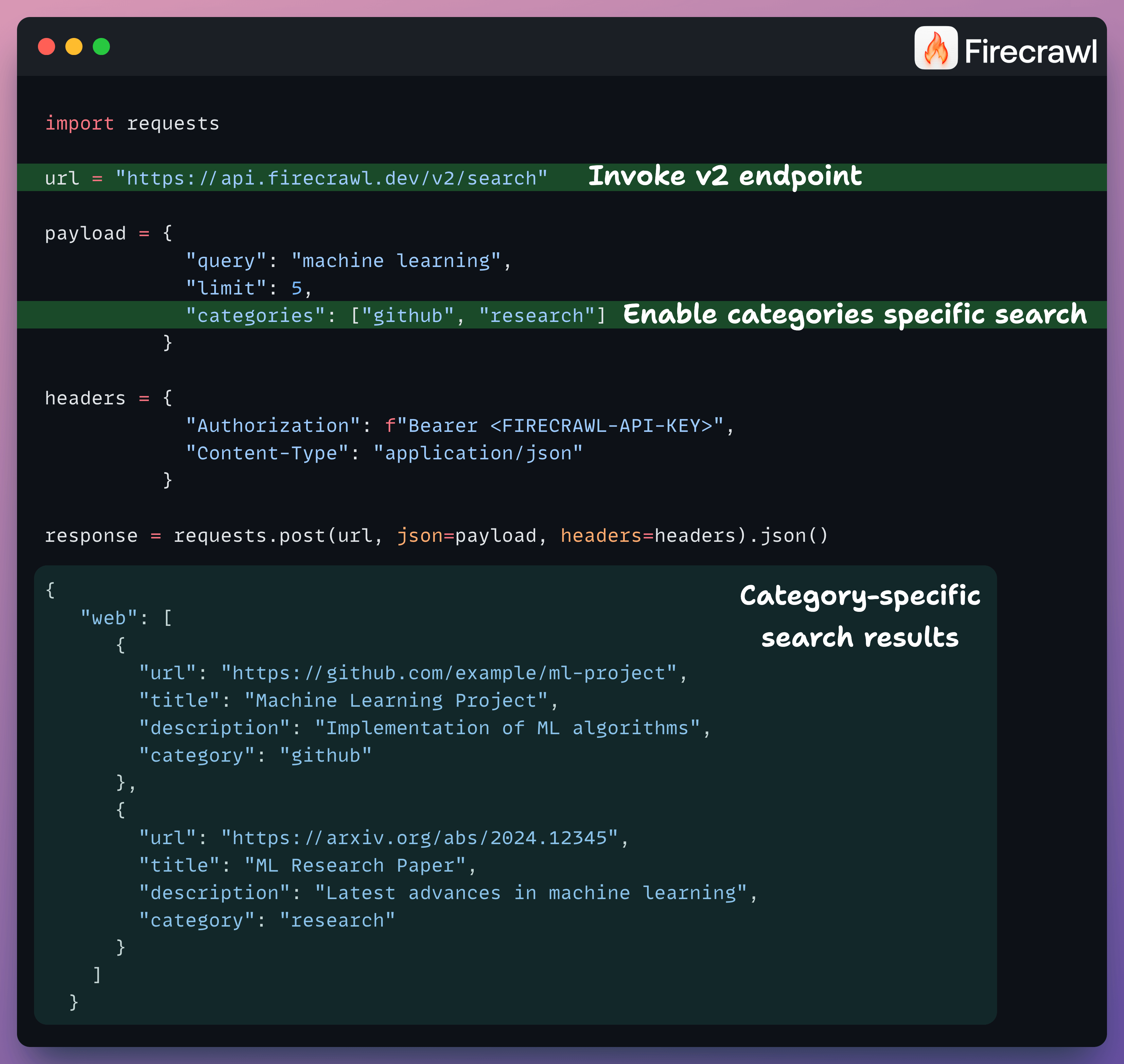
This gives much more targeted results by narrowing your search call to specific content types before you scrape them.
Evaluating MCP-powered LLM Apps
There are primarily 2 factors that determine how well an MCP app works:
If the model is selecting the right tool?
And if it's correctly preparing the tool call?
Today, let's learn how to evaluate any MCP workflow using DeepEval’s latest MCP evaluations (open-source).
This issue was written while referring to the DeepEval docs →
Here's the workflow:
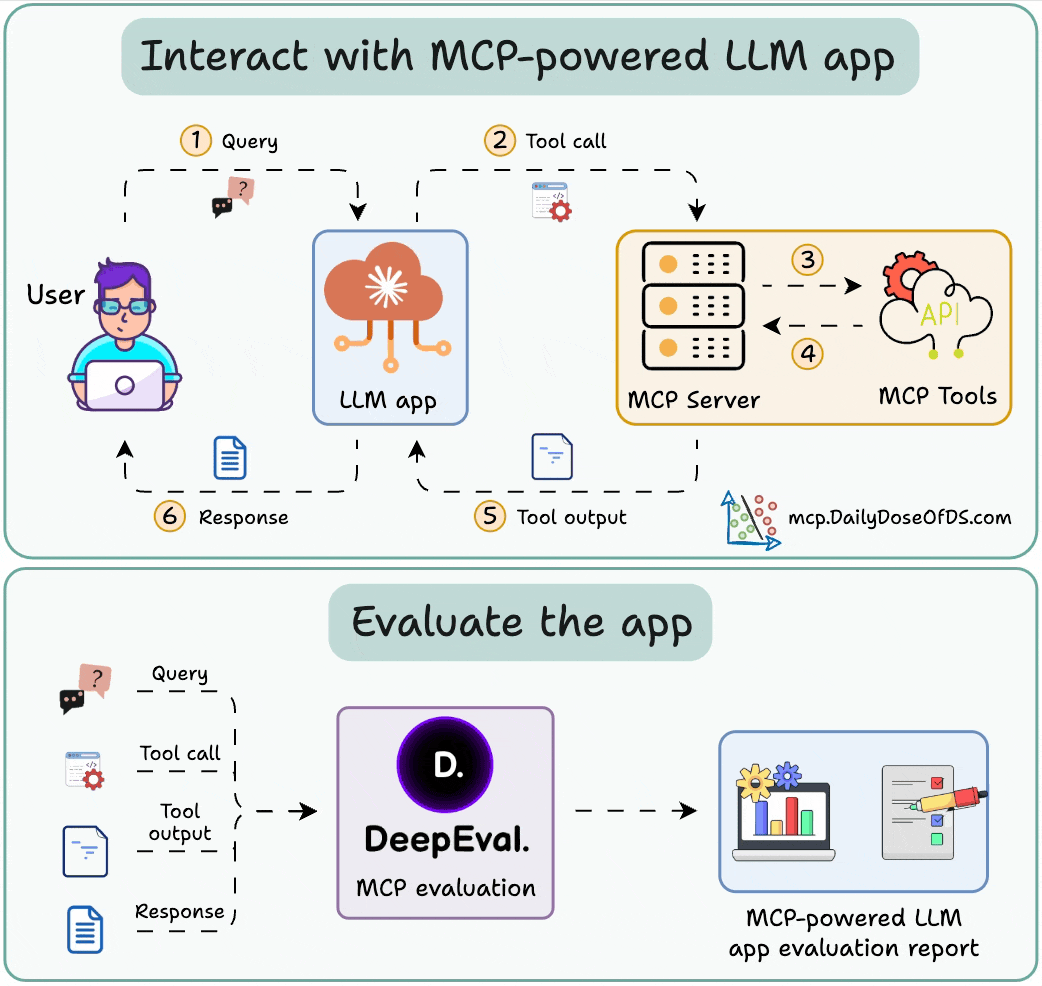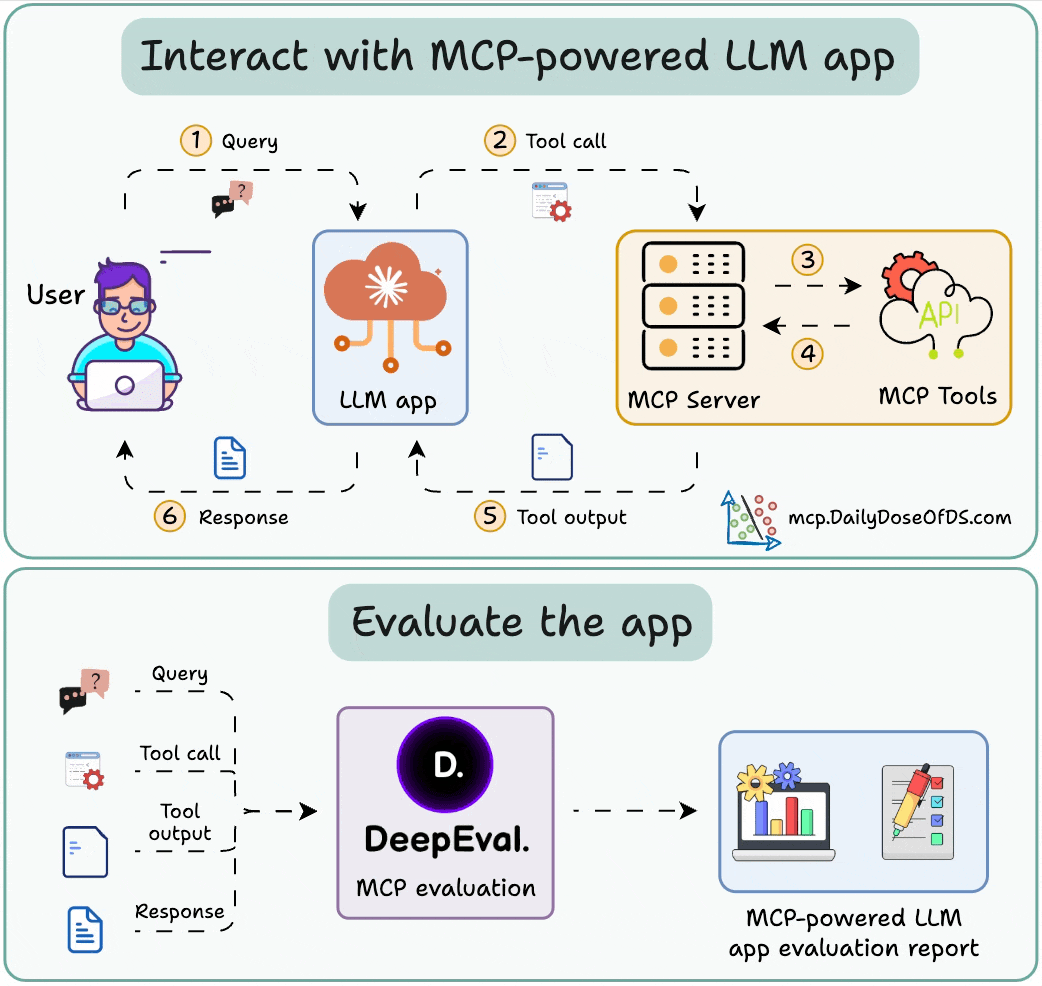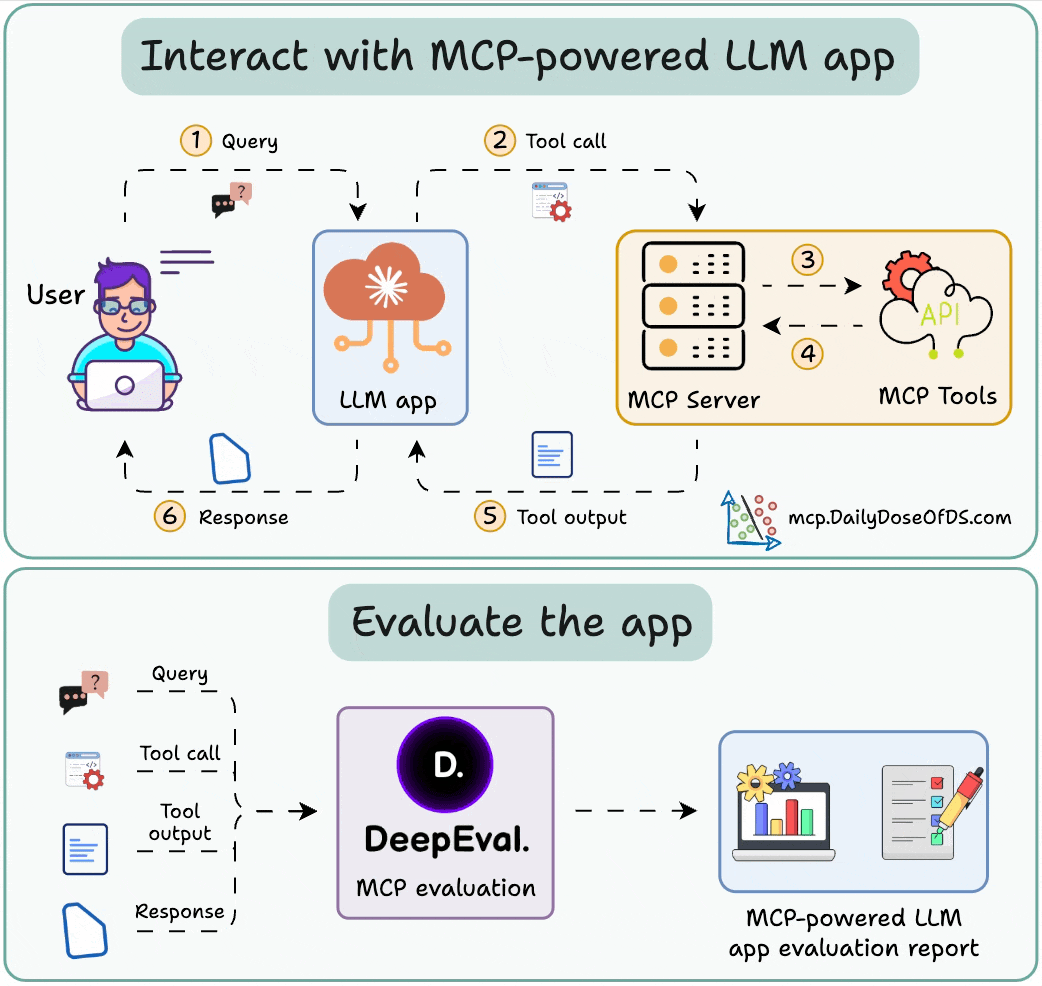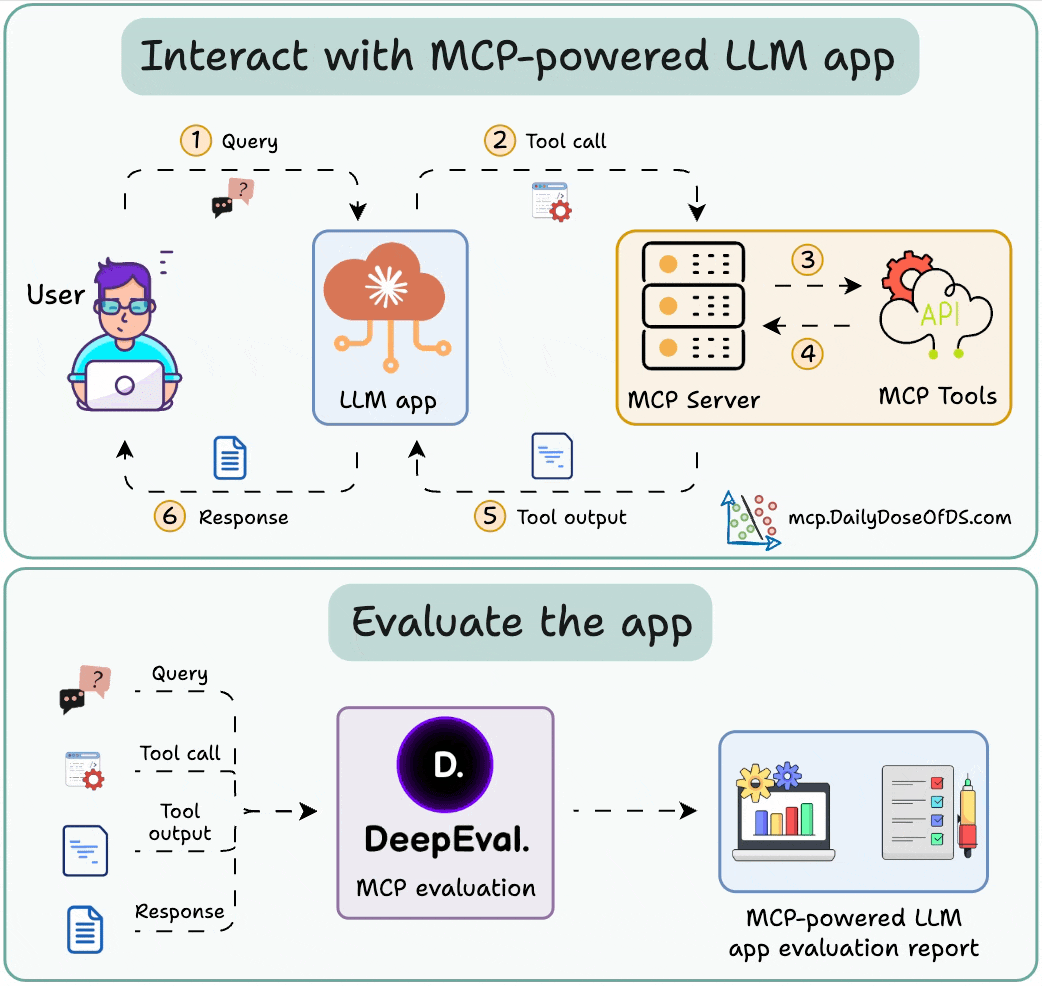
Integrate the MCP server with the LLM app.
Send queries and log tool calls, tool outputs in DeepEval.
Once done, run the eval to get insights on the MCP interactions.
Now let's dive into the code for this!
1️⃣ Setup
First, we install DeepEval to run MCP evals.

It's 100% open-source with 11k+ stars and implements everything you need to define metrics, create test cases, and run evals like:
component-level evals
multi-turn evals
LLM Arena-as-a-judge, etc.
2️⃣ Create an MCP server
Next, we define our own MCP server with two tools that the LLM app can interact with.
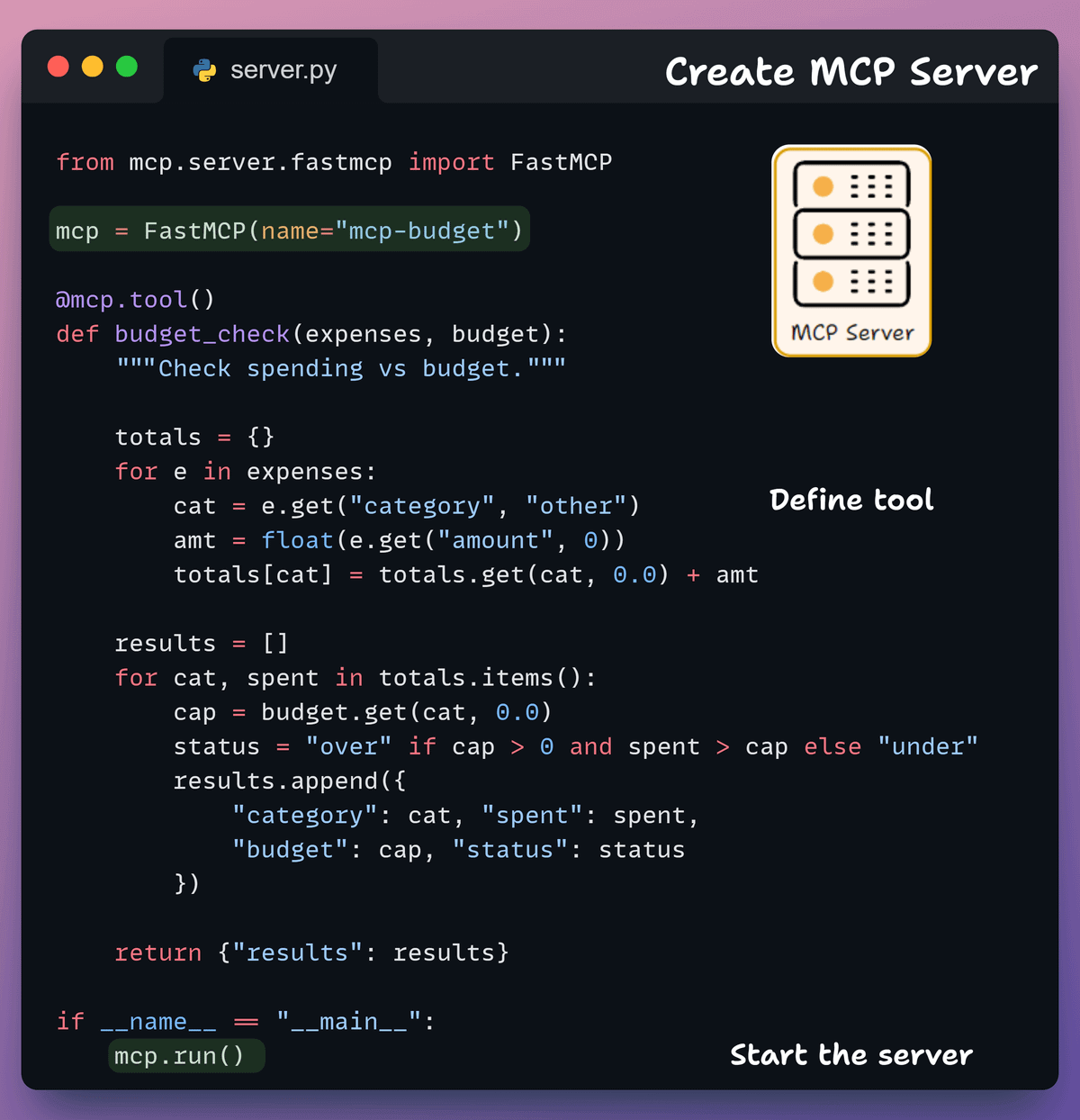
Notice that in our implementation, we intentionally avoid specifying any descriptive docstrings to make things tricky for the LLM.
3️⃣ Connect to MCP server
Moving on, we set up the client session that connects to the MCP server and manages tool interactions.

This is the layer that sits between the LLM and the MCP server.
4️⃣ Track MCP interactions
Next, we define a method that accepts a user query and passes that to Claude Opus (along with the MCP tools) to generate a response.

We filter the tool calls from the response to create an object of MCPToolCall class from DeepEval.
5️⃣ Create a test case
At this stage, we know:
the input query
all the MCP tools
all the tools invoked
and the final LLM response
Thus, after execution, we create an LLMTestCase using this info.

6️⃣ Define metric
We define an MCPUseMetric from DeepEval, which computes two things:

How well did the LLM utilize the MCP capabilities given to it?
How well did the LLM ensure argument correctness for tool call?
The minimum of both scores is the final score.
7️⃣ Run the evaluation
Finally, we invoke DeepEval’s evaluate() method to score the test case against the metric.

This outputs a score between 0-1 with a 0.5 threshold default.
We run multiple queries for evaluation.
The DeepEval dashboard displays the full trace, like:
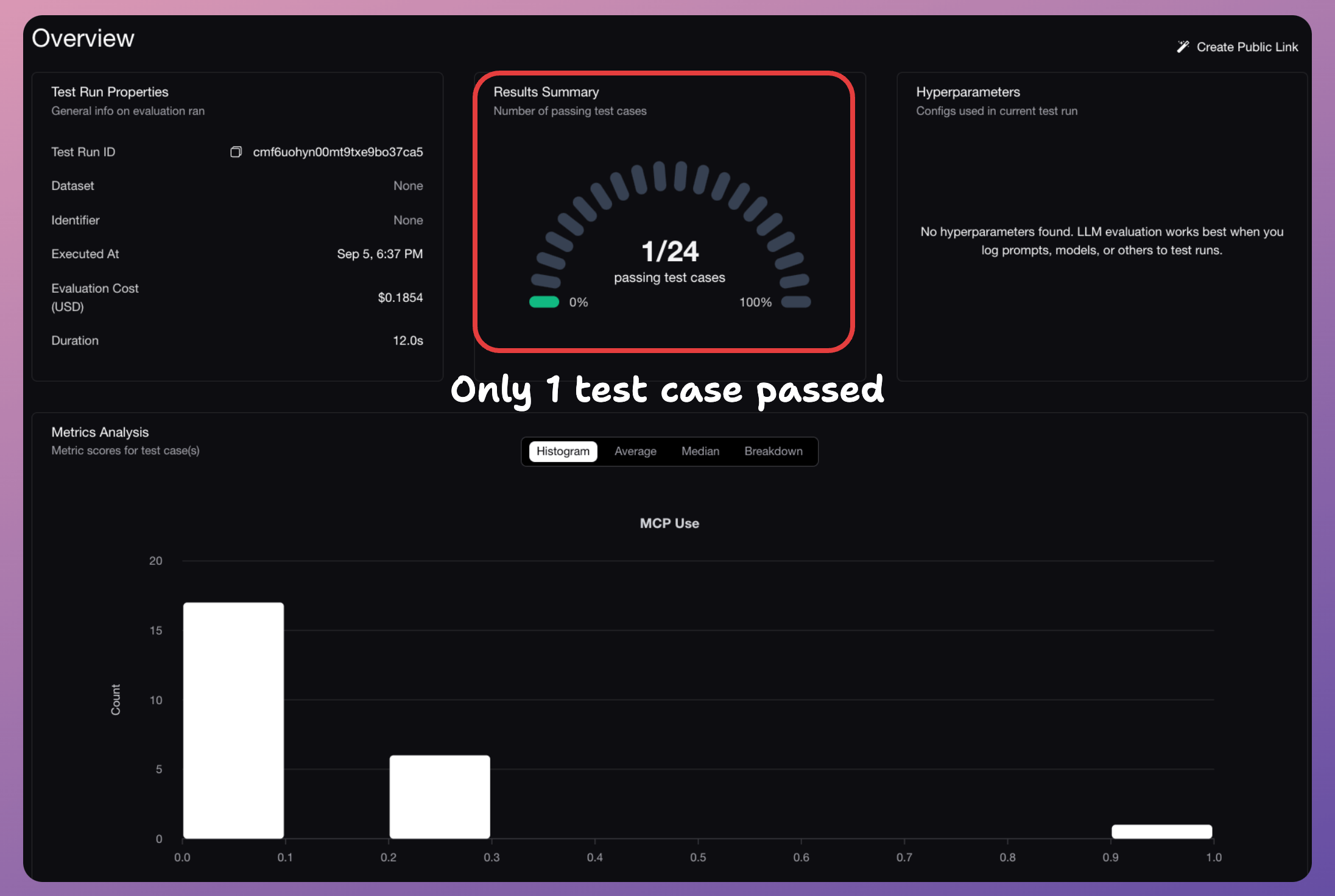
query
response
failure/success reason
tools invoked and params, etc.
As expected, the app failed on most queries, and our MCPUseMetric spotted that correctly.
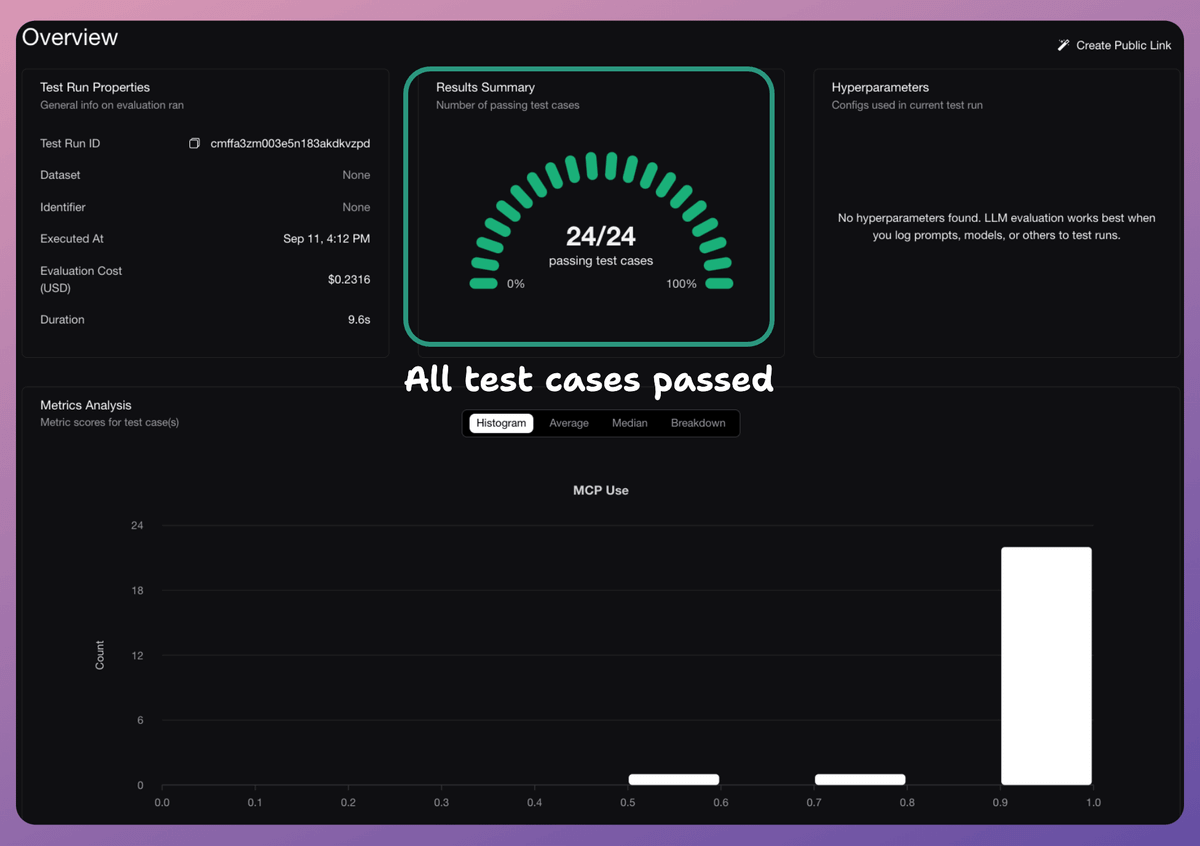
This evaluation helped us improve this app by defining better docstrings, and the app which initially passed only 1 or 2 out of 24 test cases, now achieves a 100% success rate:
This issue was written while referring to the DeepEval docs →
Find more details in DeepEval’s GitHub repo → (don’t forget to star it)
Thanks for reading!