
A Hands-on Demo of Autoencoders
...along with applications.

AssemblyAI Universal-2: Speech Recognition at Superhuman Accuracy
It’s crazy hard to train reliable transcription models on speech/audio data since so many nuances go into the data, like accents, pauses, small utterances, murmurs, you name it.
AssemblyAI first trained Universal-1 on 12.5 million hours of audio, outperforming every other model in the industry (from Google, OpenAI, etc.) across 15+ languages.
Now, they released Universal-2, their most advanced speech-to-text model yet.

Here’s how Universal-2 compares with Universal-1:
24% improvement in proper nouns recognition
21% improvement in alphanumeric accuracy
15% better text formatting
Build flawless transcription apps with Universal-2 →
Thanks to AssemblyAI for partnering on today’s issue.
A Hands-on Demo of Autoencoders
One can do so many things with Autoencoders:
Dimensionality reduction.
Anomaly detection where if reconstruction error is high, something’s fishy!
Detect multivariate covariate shift, which we discussed here.
Data denoising (clean noisy data by training on noise).
They are simple yet so powerful!
At their core, Autoencoders have two main parts:
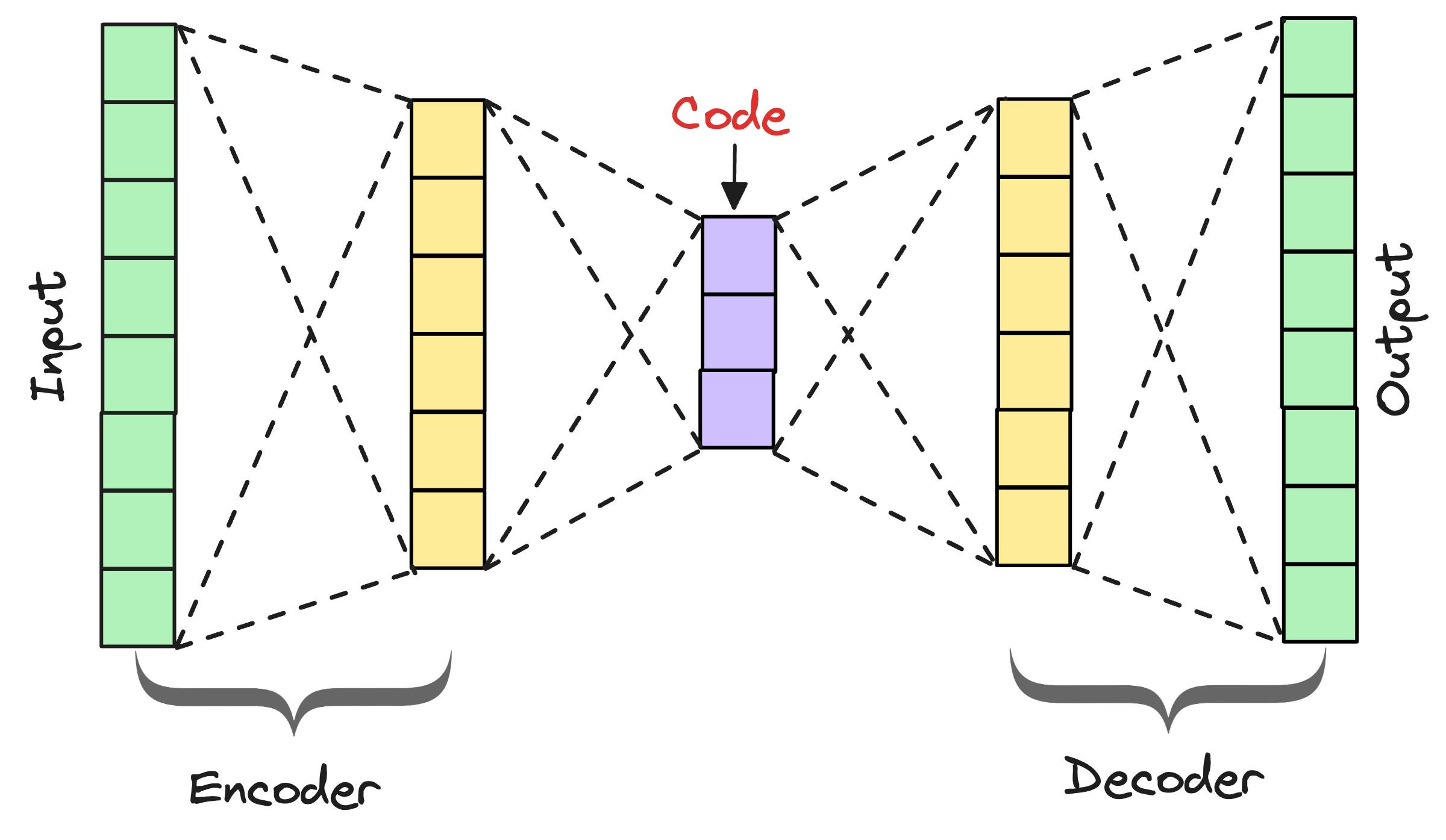
Encoder: Compresses the input into a dense representation (latent space).
Decoder: Reconstructs the input from this dense representation.
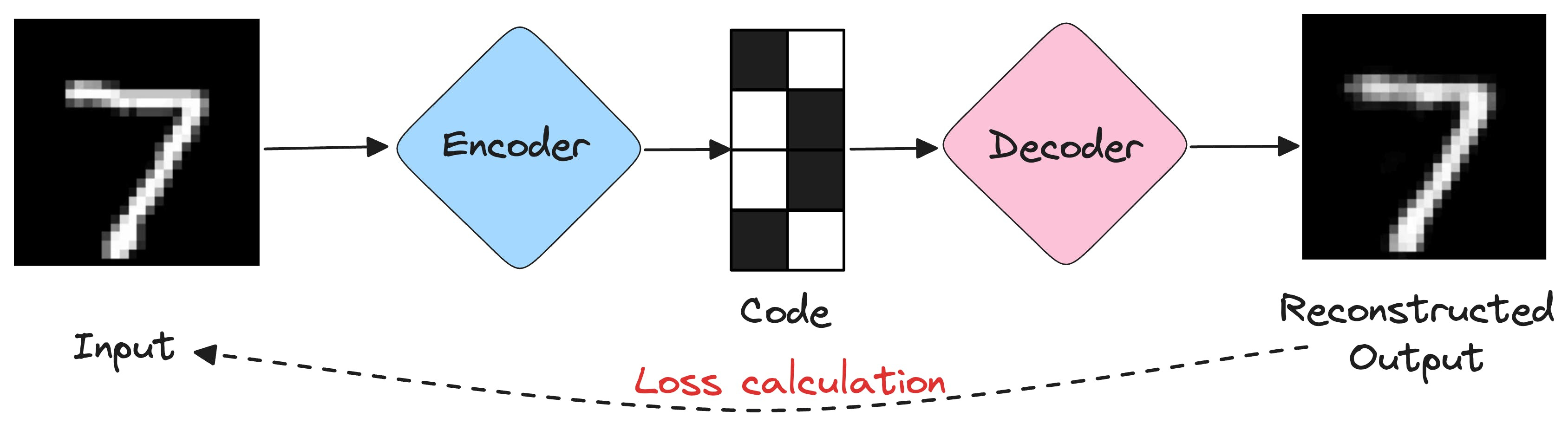
And the idea is to make the reconstructed output as close to the original input as possible:
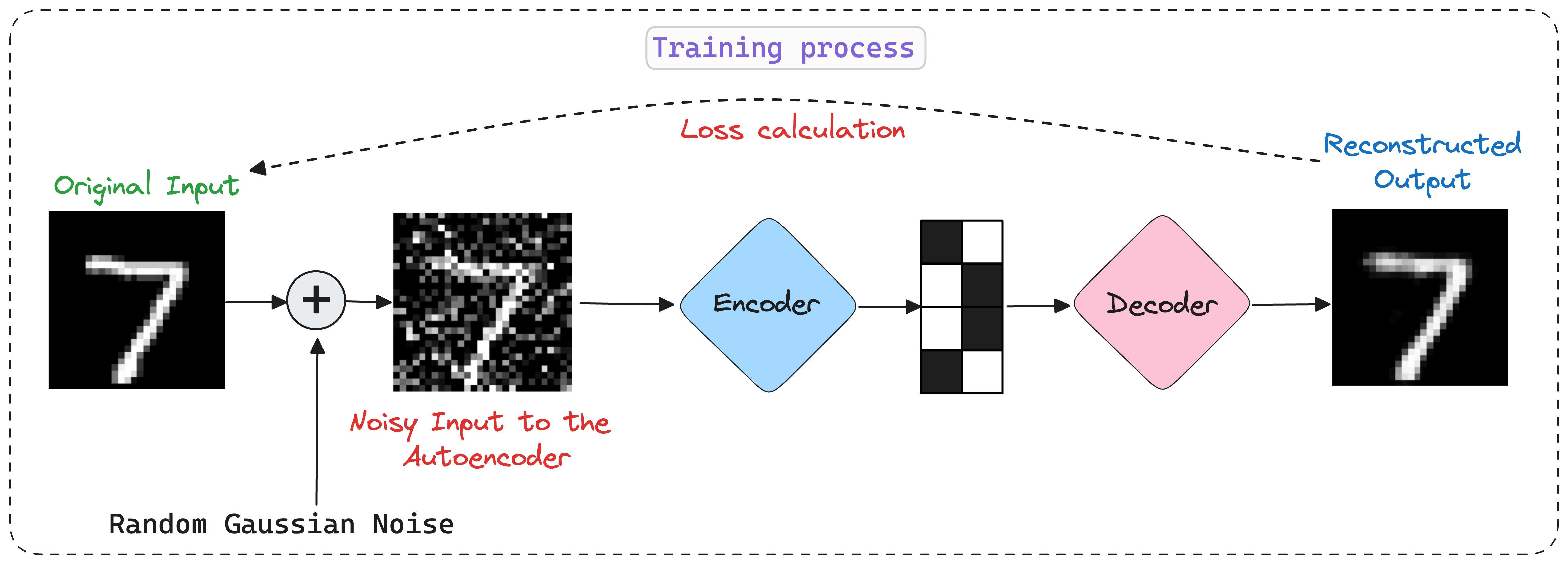
On a side note, here's how the denoising autoencoder works:
During training, add random noise to the original input, and train an autoencoder to predict the original input.
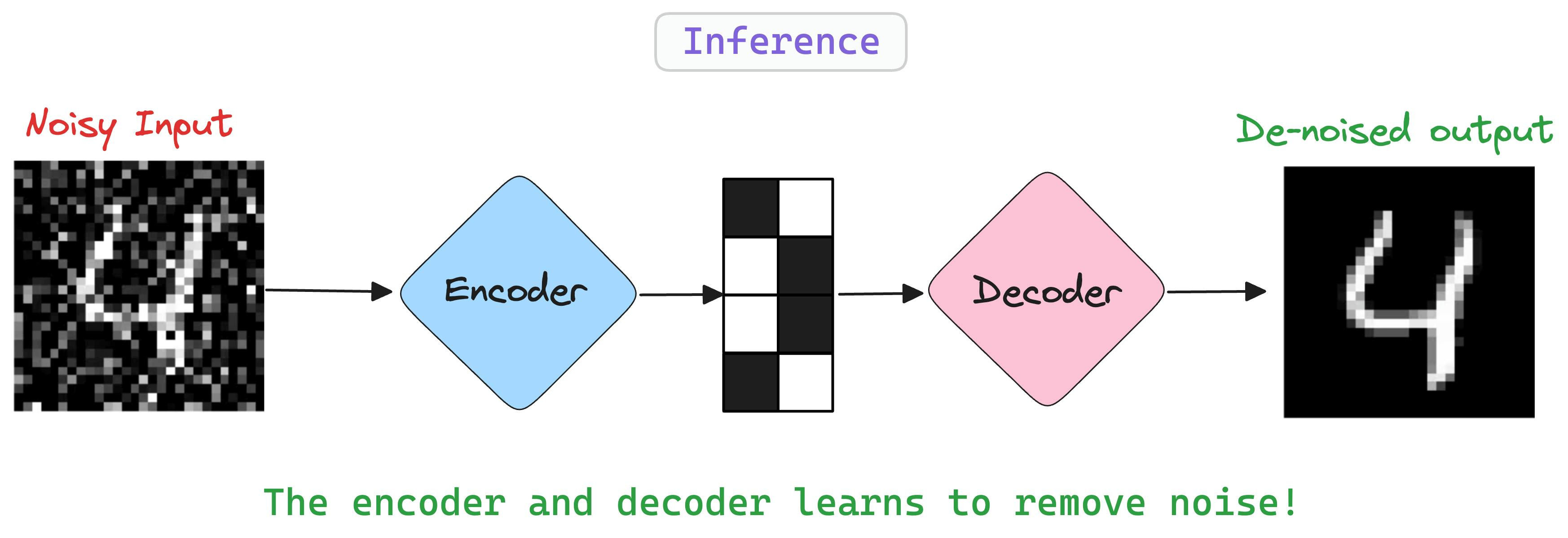
During inference, provide a noisy input and the network will reconstruct it.
Coming back to the topic...
Below, let's quickly implement an autoencoder:
We'll use PyTorch Lightning for this.
First, we define our autoencoder!
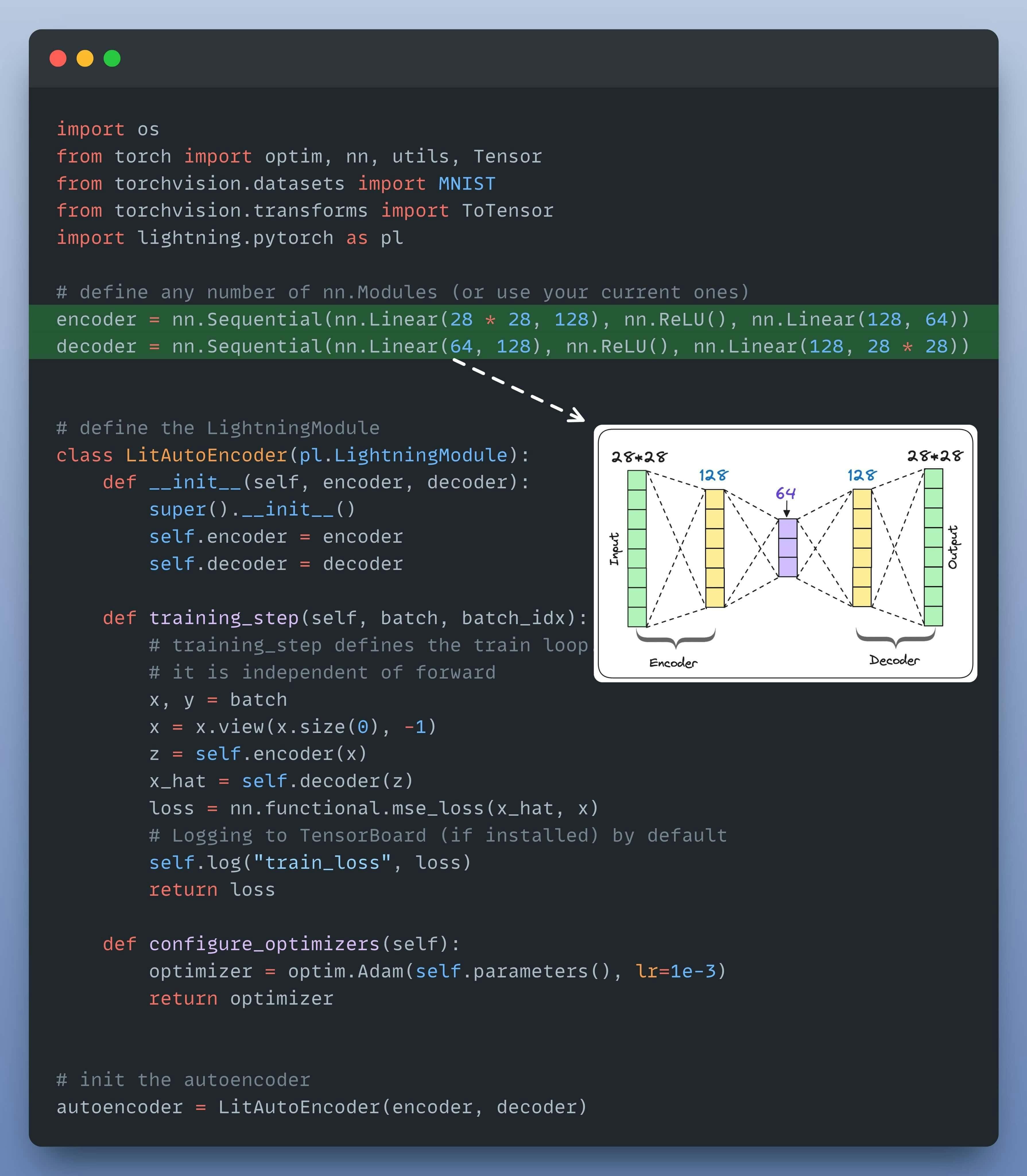
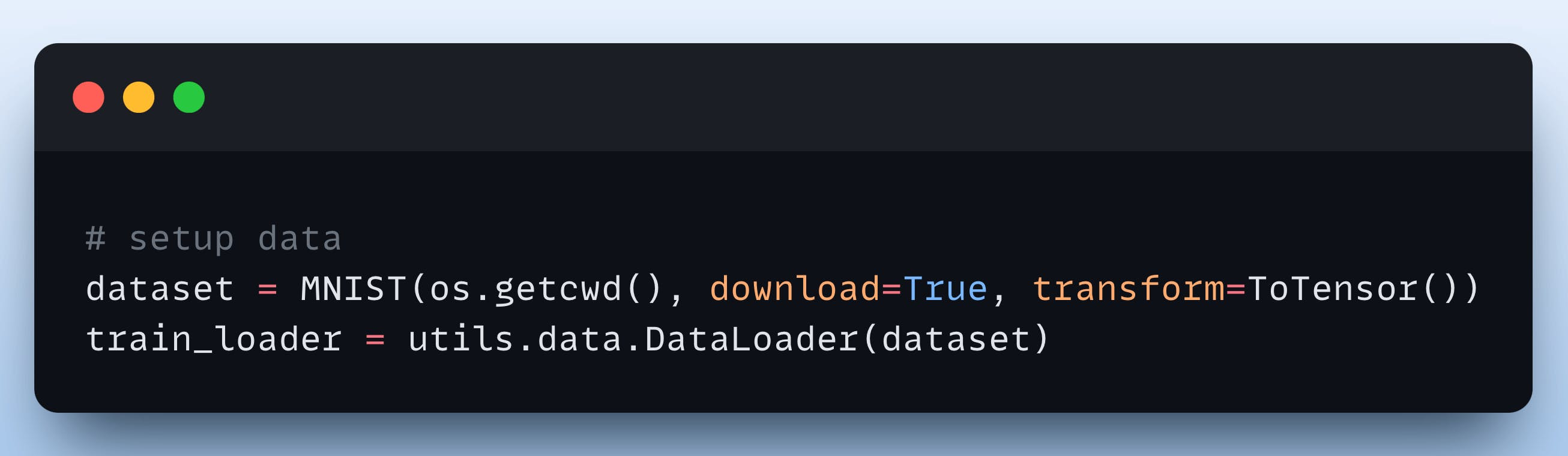
Next, we define our dataset (MNIST):
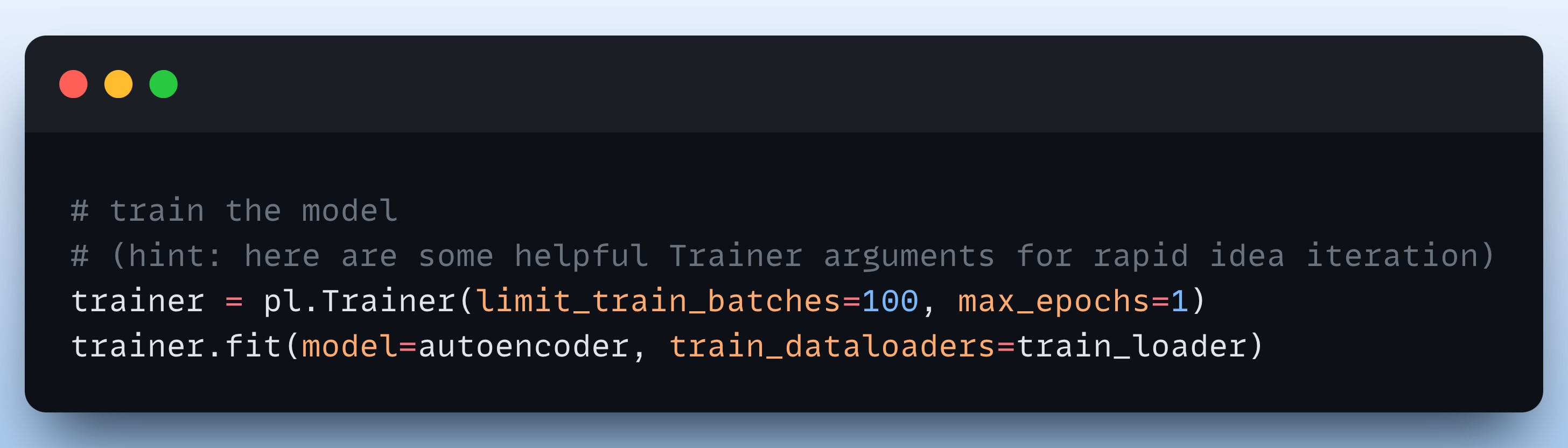
Finally, we train the model in two lines of code with PyTorch Lightning:
The Lightning Trainer automates 40+ training optimization techniques including:
Epoch and batch iteration
optimizer.step(),loss.backward()etc.Calling
model.eval()enabling/disabling grads during evaluation
Checkpoint saving and loading
Multi-GPU
16-bit precision.
Since the model has been trained, we can visualize the performance.
Let's encode/decode an image using our trained model below:
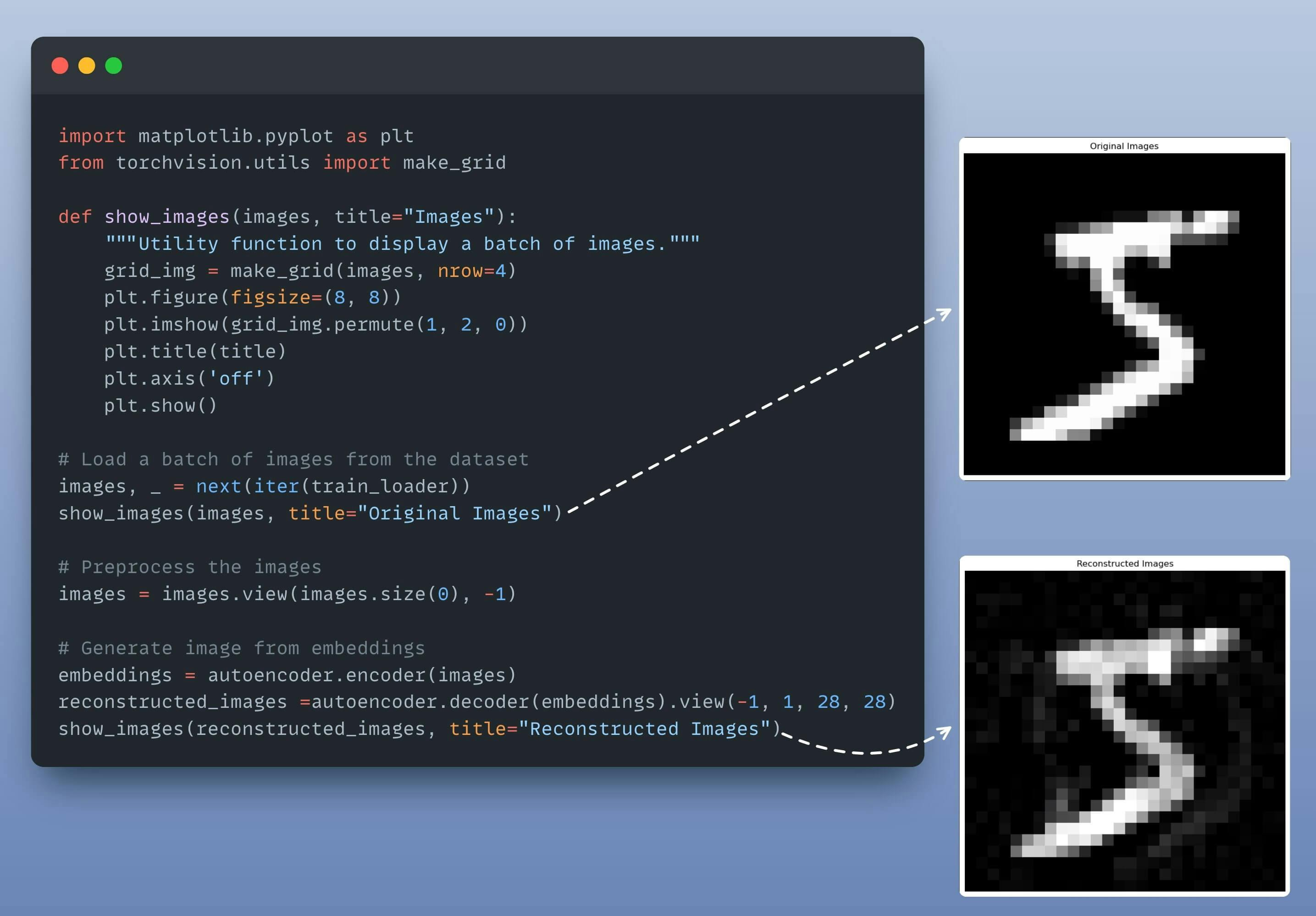
Done!
And that's how you train an autoencoder.
As mentioned earlier, autoencoders are incredibly helpful in detecting multivariate covariate shifts.
This is important to address since almost all real-world ML models gradually degrade in performance due to covariate shift.
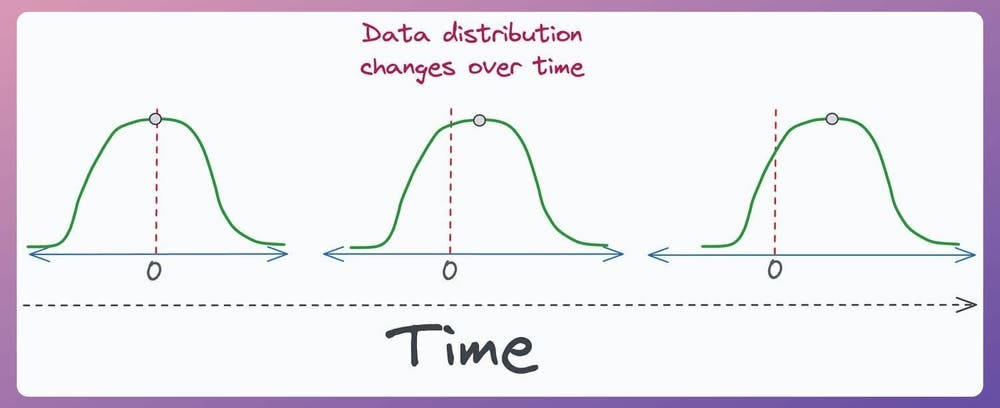
It is a serious problem because we trained the model on one distribution, but it is being used to predict on another distribution in production.
Autoencoders help in addressing this, and we discussed it here.
👉 Over to you: What are some other use cases of Autoencoder?
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 450k+ data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.