
A Hands-on Demo on Autoencoders
...along with applications.

A Python decorator is all you need to deploy AI apps [open-source]

Beam is an open-source alternative to Modal that makes deploying serverless AI workloads effortless with zero infrastructure overhead.
Just pip install beam and add a decorator to turn any function into a serverless endpoint!
Key features:
Lightning-fast container launches < 1s
Distributed volume storage support
Auto-scales from 0 to 100s of containers
GPU support (4090s, H100s, or bring your own)
Deploy inference endpoints with simple decorators
Spin up isolated sandboxes for LLM-generated code
Completely open-source!
Beam GitHub repo → (don’t forget to star)
A Hands-on Demo of Autoencoders
One can do so many things with Autoencoders:
Dimensionality reduction.
Anomaly detection where if reconstruction error is high, something’s fishy!
Detect multivariate covariate shift, which we discussed here.
Data denoising (clean noisy data by training on noise).
They are simple yet so powerful!
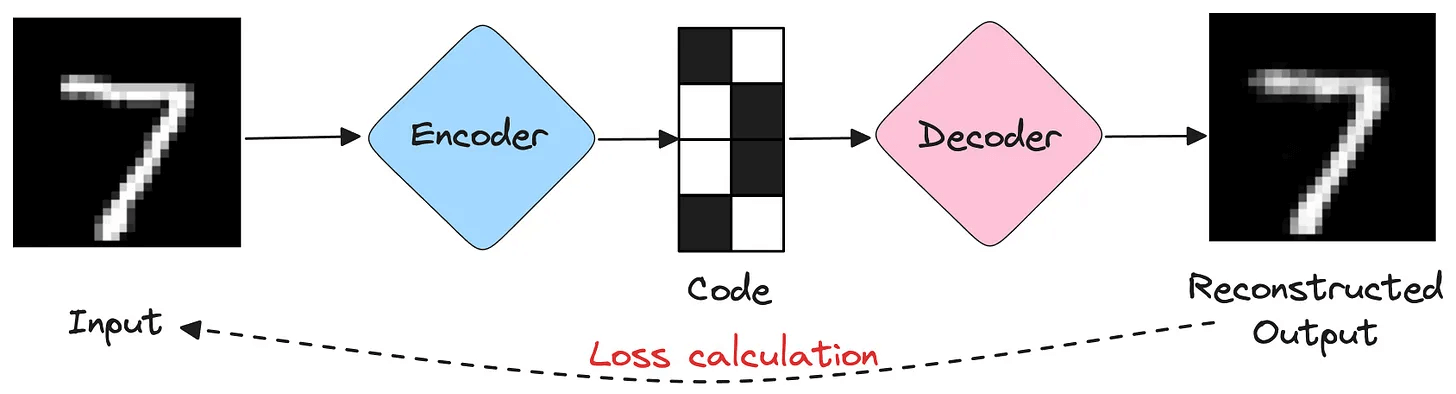
At their core, Autoencoders have two main parts:

Encoder: Compresses the input into a dense representation (latent space).
Decoder: Reconstructs the input from this dense representation.
And the idea is to make the reconstructed output as close to the original input as possible:
On a side note, here's how the denoising autoencoder works:
During training, add random noise to the original input, and train an autoencoder to predict the original input.

During inference, provide a noisy input and the network will reconstruct it.

Coming back to the topic...
Below, let's quickly implement an autoencoder:
We'll use PyTorch Lightning for this.
First, we define our autoencoder!

Next, we define our dataset (MNIST):

Finally, we train the model in two lines of code with PyTorch Lightning:
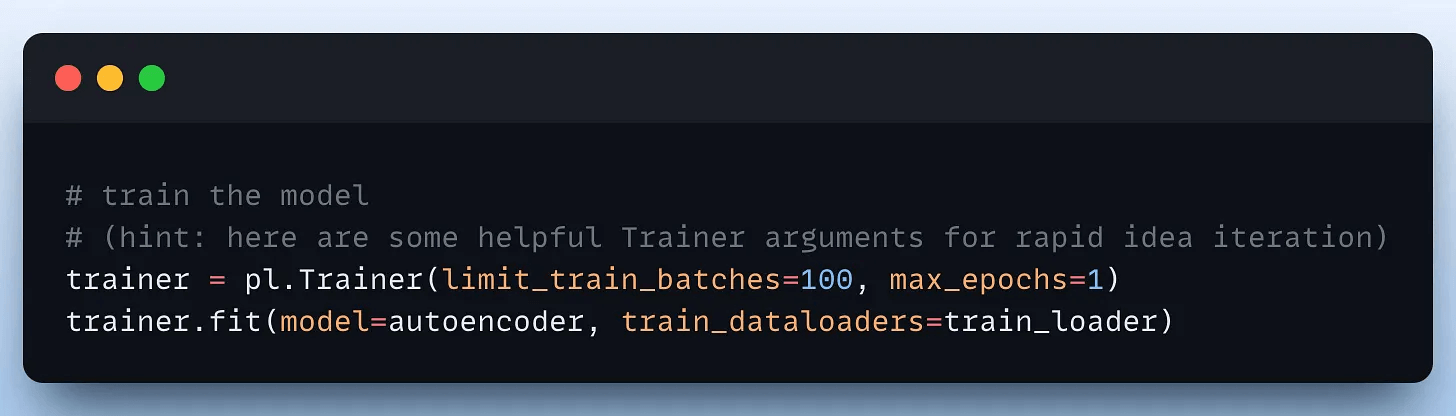
The Lightning Trainer automates 40+ training optimization techniques including:
Epoch and batch iteration
optimizer.step(),loss.backward()etc.Calling
model.eval()enabling/disabling grads during evaluation
Checkpoint saving and loading
Multi-GPU
16-bit precision.
Since the model has been trained, we can visualize the performance.
Let's encode/decode an image using our trained model below:

Done!
And that's how you train an autoencoder.
As mentioned earlier, autoencoders are incredibly helpful in detecting multivariate covariate shifts.
This is important to address since almost all real-world ML models gradually degrade in performance due to covariate shift.

It is a serious problem because we trained the model on one distribution, but it is being used to predict on another distribution in production.
Autoencoders help in addressing this, and we discussed it here.
👉 Over to you: What are some other use cases of Autoencoder?
[Hands-on] Build a Custom MCP Server for Cursor
Lately, there has been a lot of interest in MCPs.
Here's a step-by-step video walkthrough of creating your own MCP server!
It connects to Cursor and lets the Agent perform deep web searches and RAG over a specified directory.
Cursor IDE is our MCP host, and we connect it to our custom server.
Here’s the tech stack:
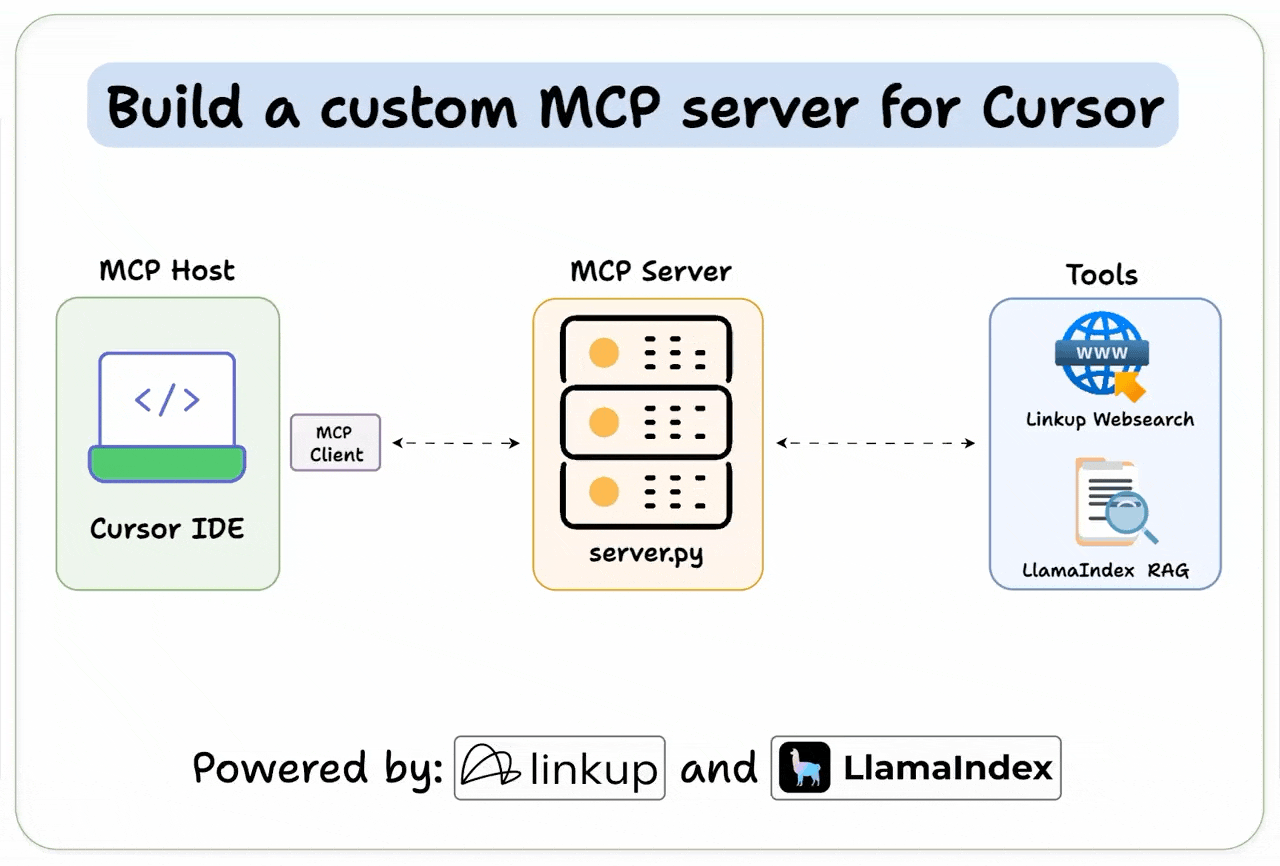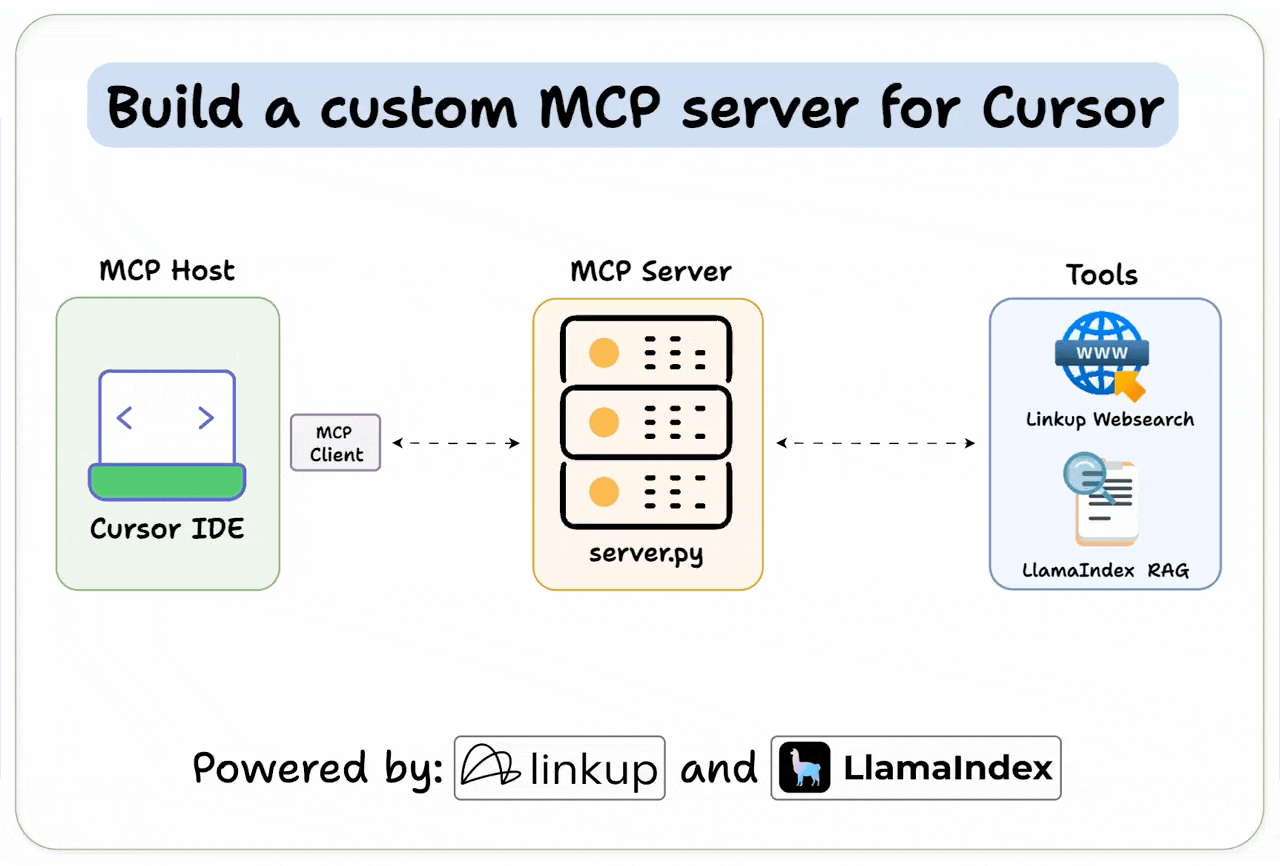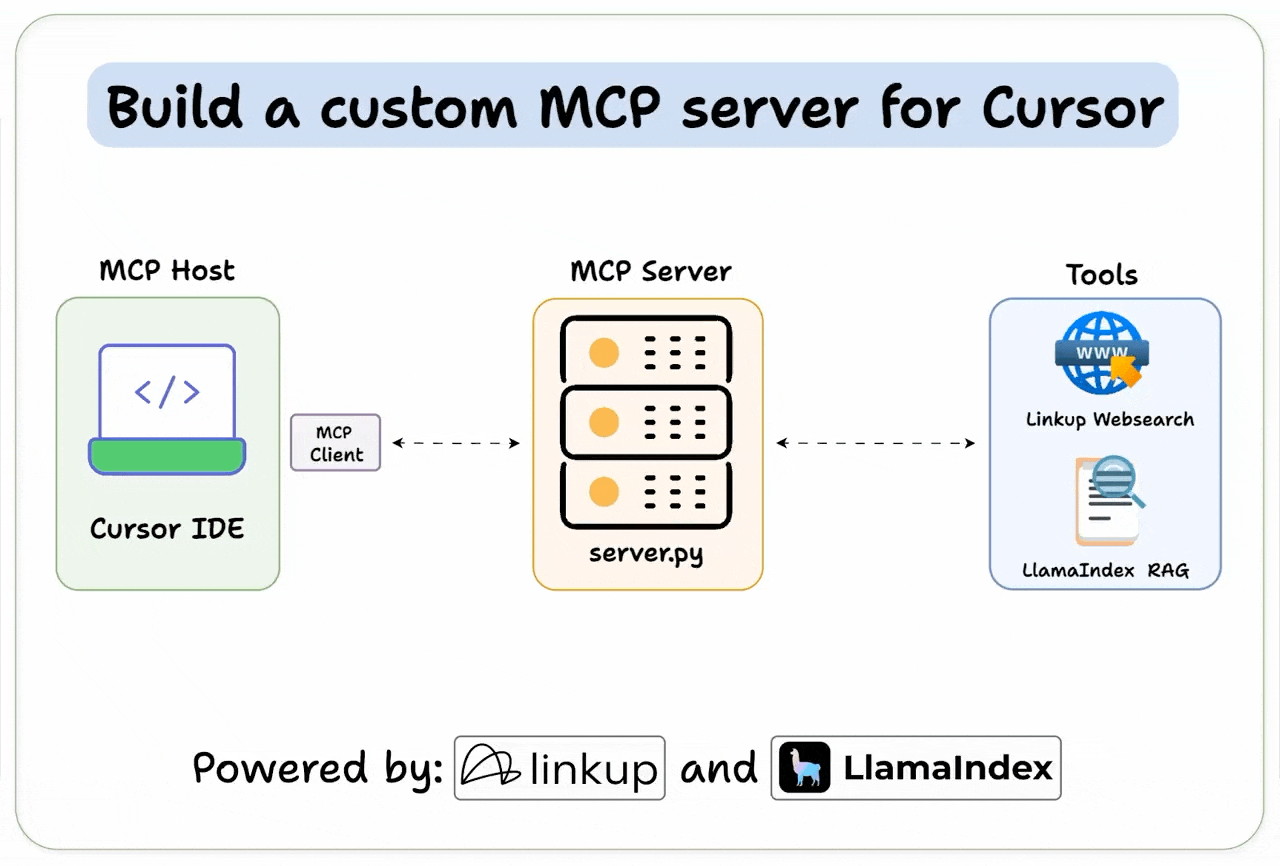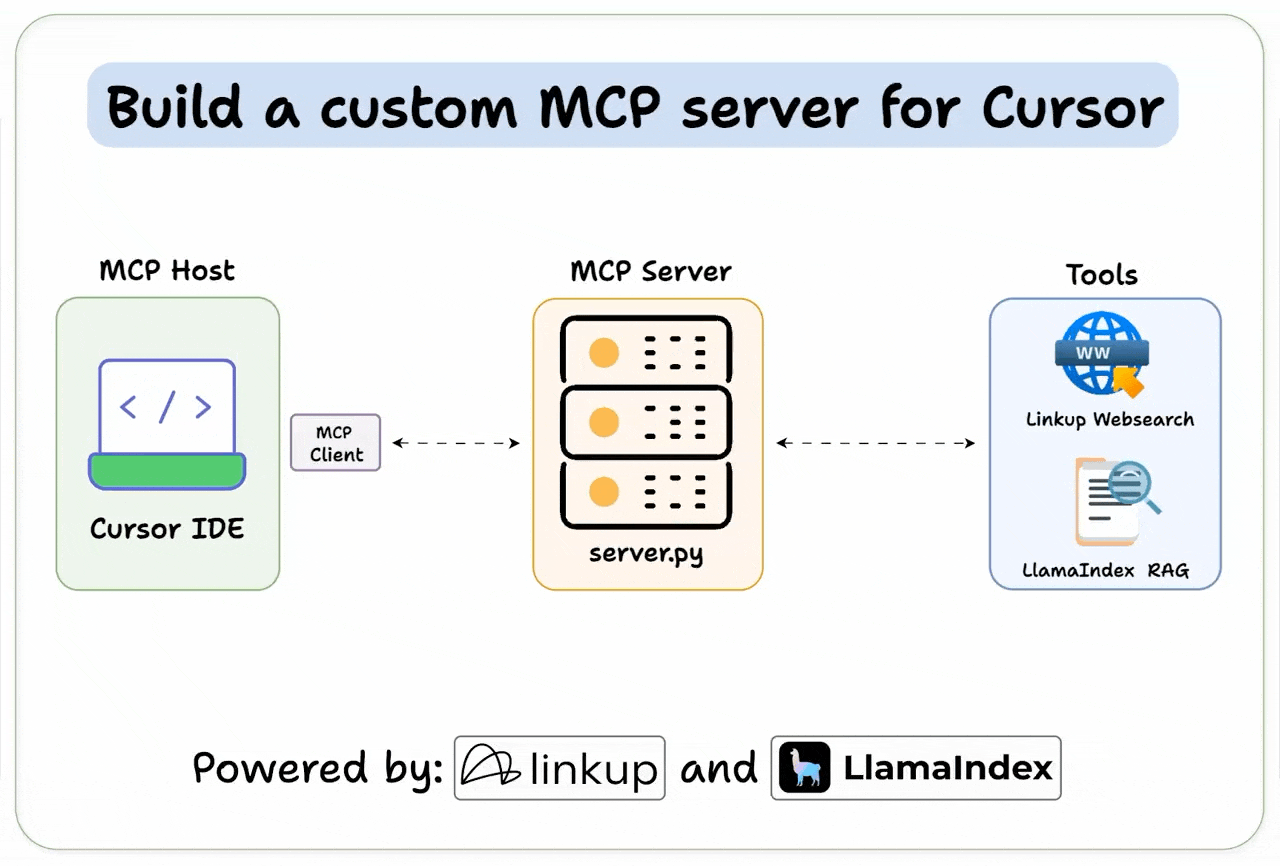
Linkup for deep web search.
Llama Index workflow to enable RAG.
Find the code on GitHub here → (don't forget to star the repo)
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.