
A Hands-on Guide to LLM Arena-as-a-Judge
...with step-by-step implementation.

Firecrawl Observer: Open-source website monitor

Firecrawl open-sourced a website monitoring tool that lets you track any page or entire site with powerful change detection.
Set custom intervals and receive instant webhook alerts on updates.
Thanks to Firecrawl for partnering today!
A hands-on guide to LLM Arena-as-a-Judge
Most LLM evals assume you’re scoring one output at a time in isolation, without understanding the alternative.
So when prompt A scores 0.72 and prompt B scores 0.74, you still don’t know which one’s actually “better”.
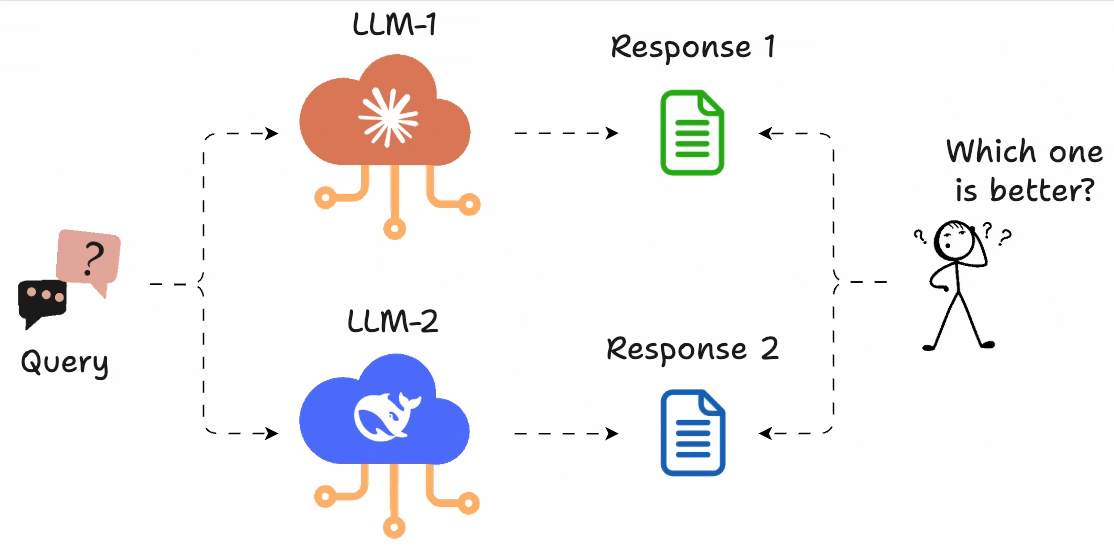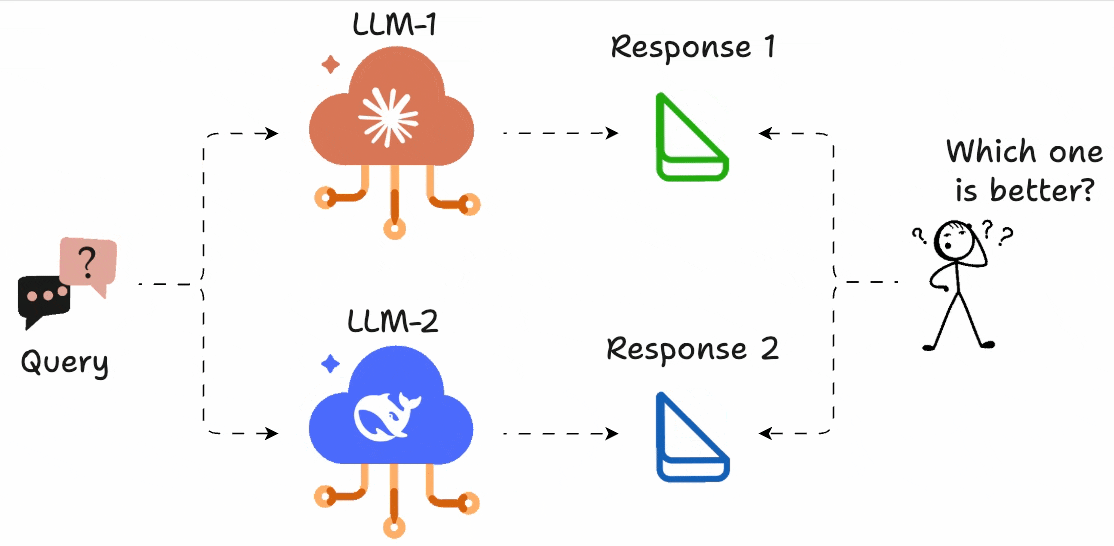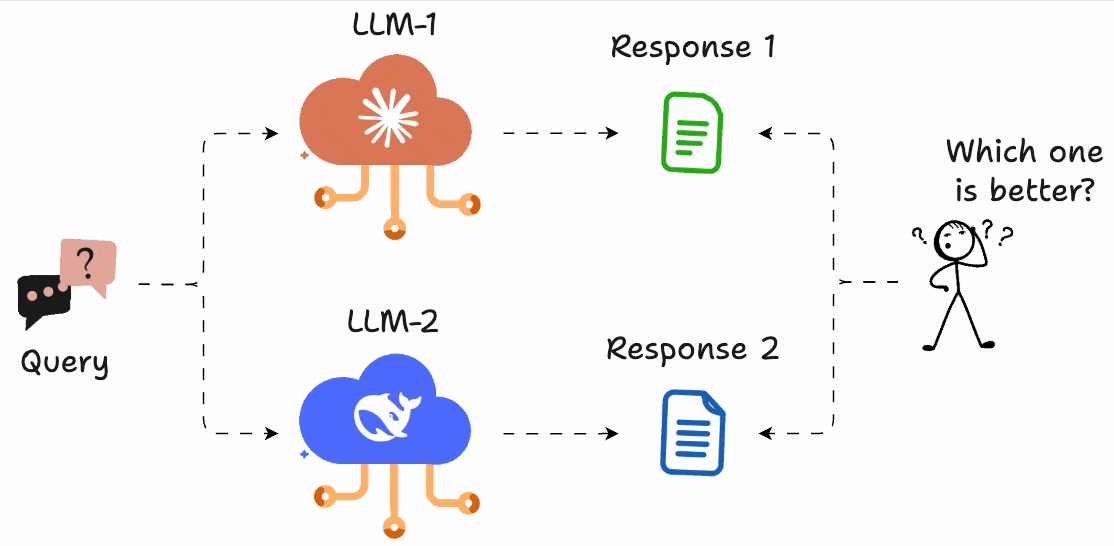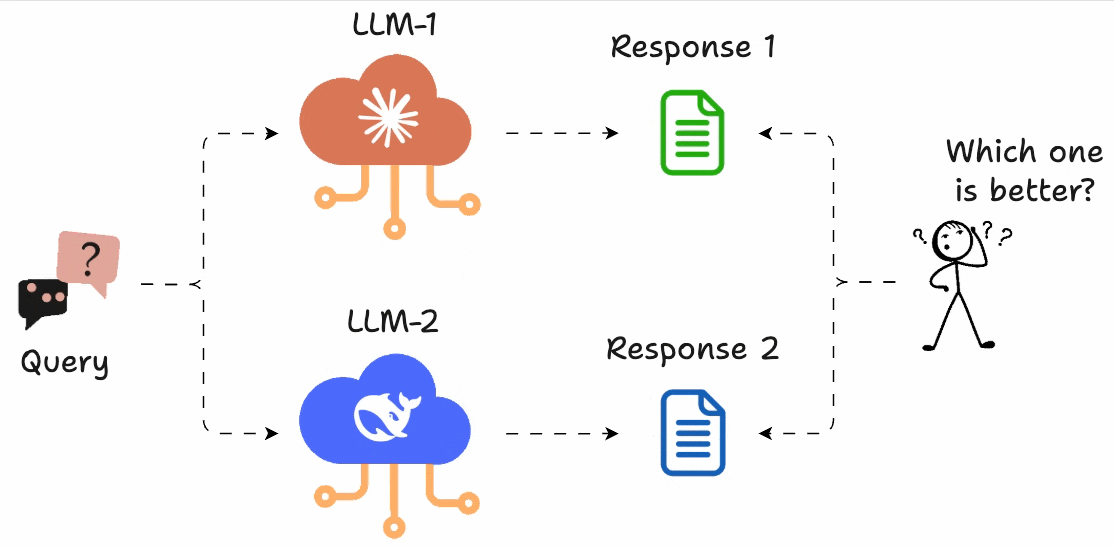
This adds complexity, and since outputs are judged in isolation, direct comparisons between them are difficult.
LLM Arena-as-a-Judge is an idea that solves this!
In a gist…
Instead of assigning scores, you just run A vs. B comparisons and pick the better output.
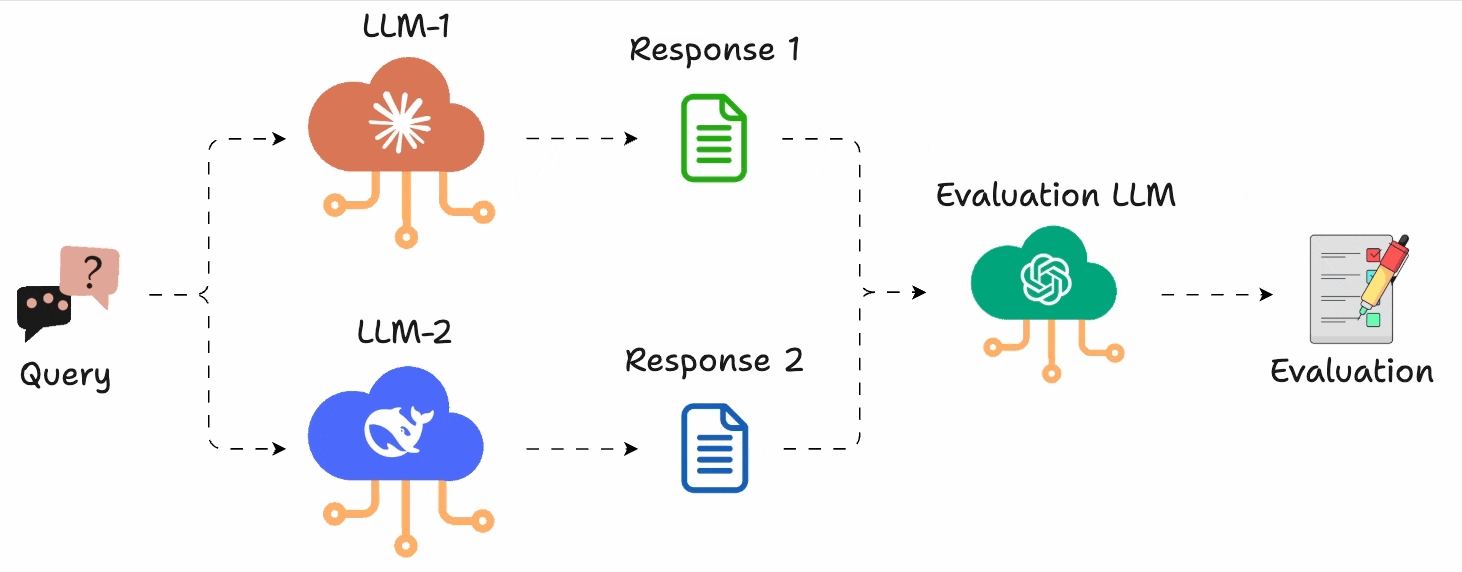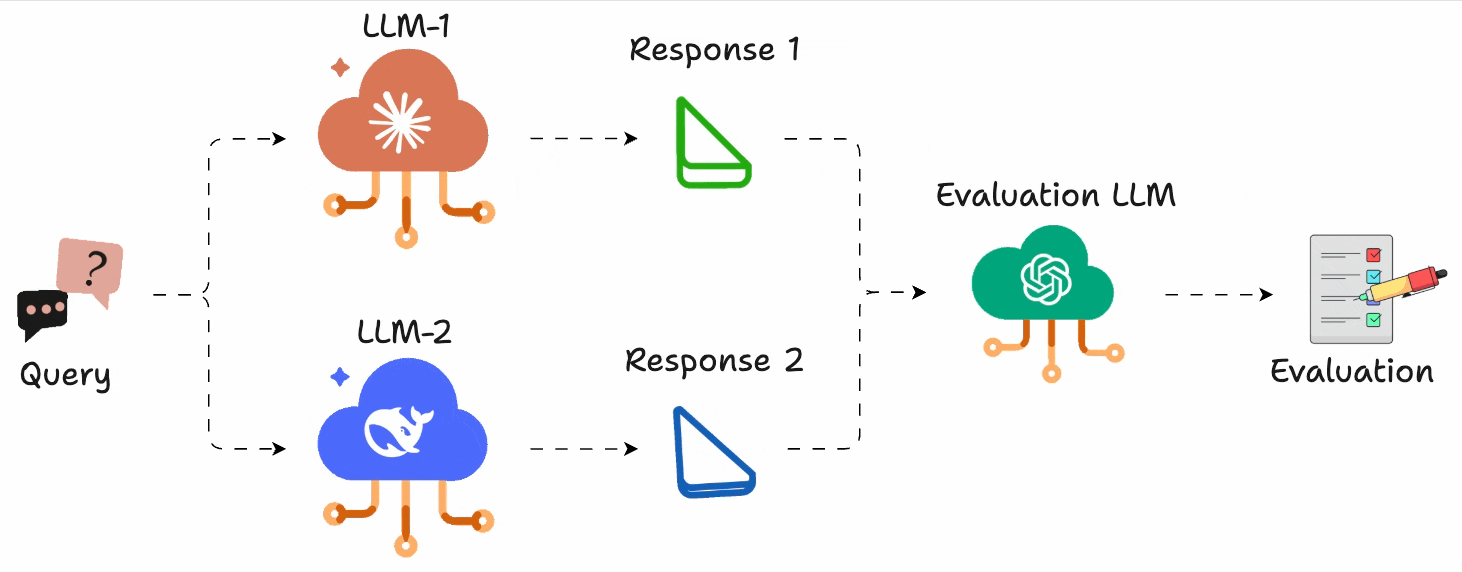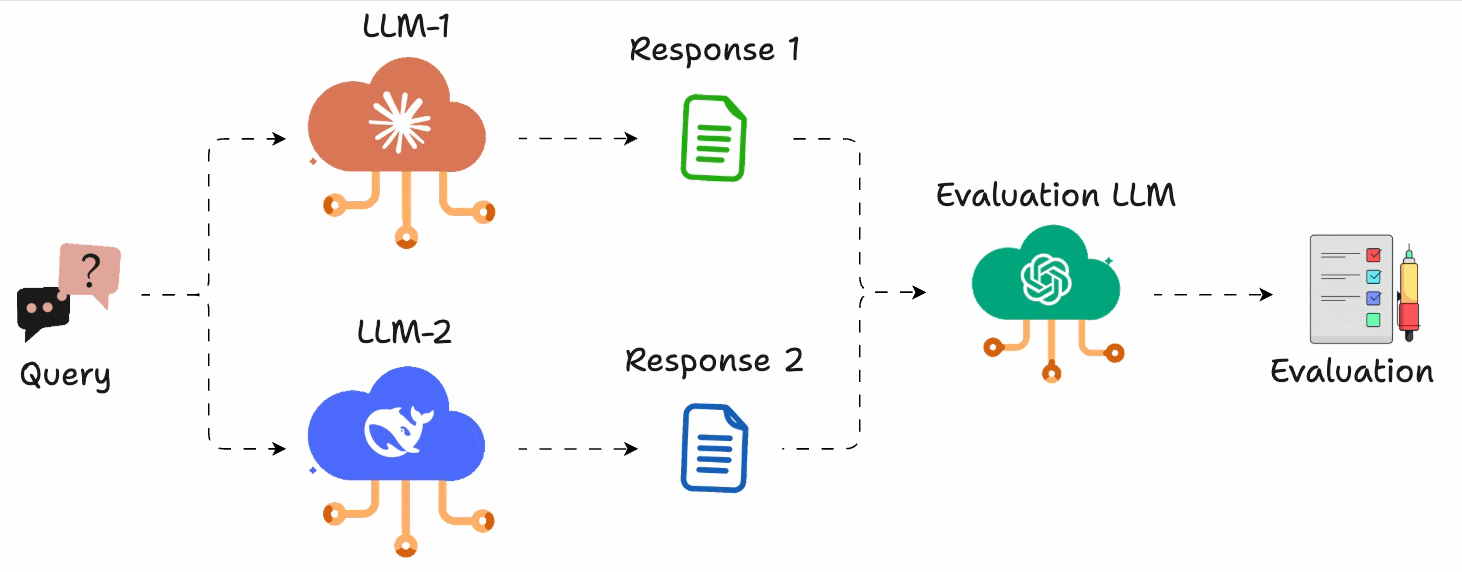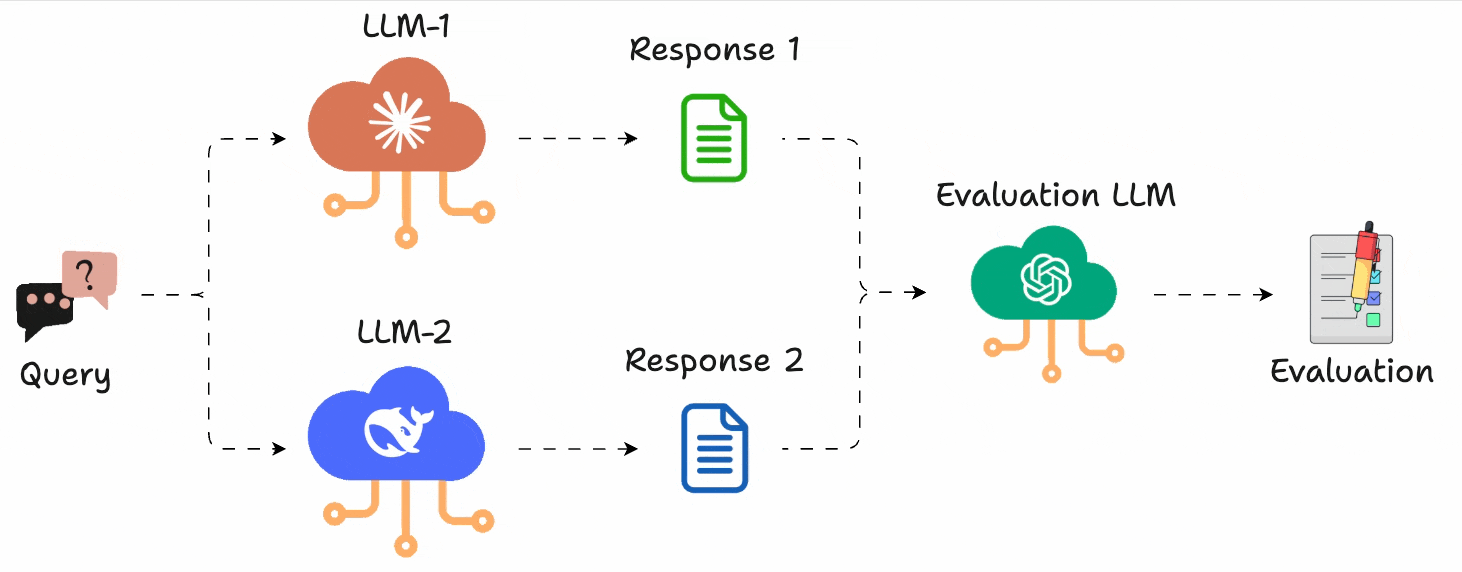
You can define what “better” means (e.g., more helpful, more concise, more polite), and use GPT-4 (or any model) to act as the judge.
Let’s see how we can use LLM Arena-as-a-Judge directly in DeepEval (open-source) in just 10 lines of code.
After installing DeepEval (pip install deepeval), create an ArenaTestCase , with a list of “contestants” and their respective LLM interactions:

Next, define your criteria for comparison using the Arena G-Eval metric, which incorporates the G-Eval algorithm for a comparison use case:

Finally, run the evaluation and print the scores:

Done!
We got the head-to-head comparison we were looking for.
Note that LLM Arena-as-a-Judge can either be referenceless or reference-based. If needed, you can specify an expected output as well for the given input test case and specify that in the evaluation parameters.
One good thing about Arena G-Eval is that it uses the existing G-Eval algorithm for choosing the winning contestant.
Thus, one can simply define what’s a “better” output in everyday language and get the evaluation scores.
You can read about LLM Arena-as-a-Judge evals in the docs here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.