
A Lesser-Known Feature of Sklearn To Train Models on Large Datasets
Out-of-core learning with sklearn

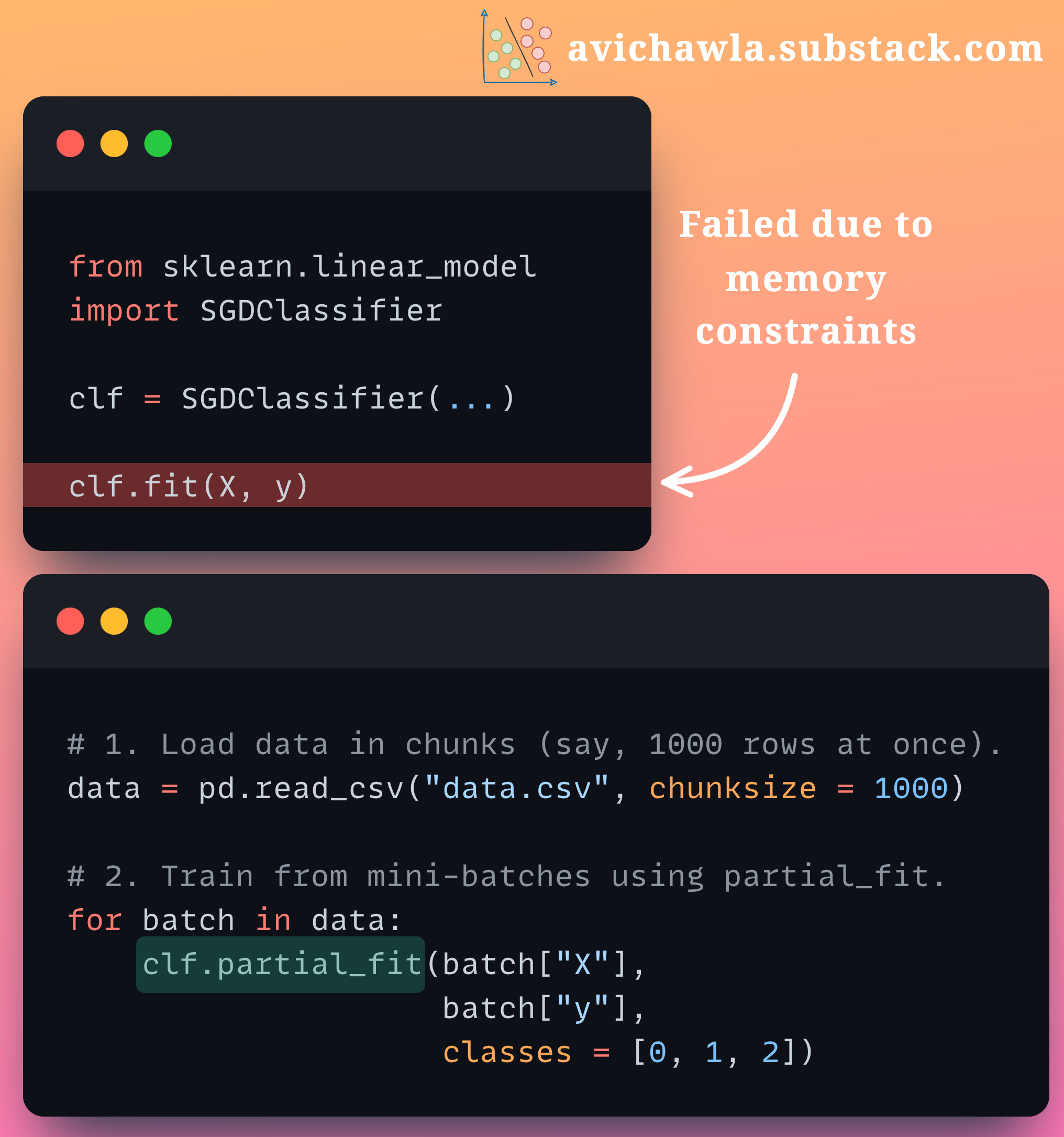
It is difficult to train models with sklearn when you have plenty of data. This may often raise memory errors as the entire data is loaded in memory. But here's what can help.
Sklearn implements the 𝐩𝐚𝐫𝐭𝐢𝐚𝐥_𝐟𝐢𝐭 API for various algorithms, which offers incremental learning.
As the name suggests, the model can learn incrementally from a mini-batch of instances. This prevents limited memory constraints as only a few instances are loaded in memory at once.

As shown in the main image, clf.fit(X, y) takes the entire data, and thus, it may raise memory errors. But, loading chunks of data and invoking the clf.partial_fit() method prevents this and offers seamless training.
Also, remember that while using the 𝐩𝐚𝐫𝐭𝐢𝐚𝐥_𝐟𝐢𝐭 API, a mini-batch may not have instances of all classes (especially the first mini-batch). Thus, the model will be unable to cope with new/unseen classes in subsequent mini-batches. Therefore, you should pass a list of all possible classes in the classes parameter.
Having said that, it is also worth noting that not all sklearn estimators implement the 𝐩𝐚𝐫𝐭𝐢𝐚𝐥_𝐟𝐢𝐭 API. Here's the list:

Yet, it is surely worth exploring to see if you can benefit from it :)
👉 Read what others are saying about this post on LinkedIn.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.