
A Memory-efficient Technique to Train Large Models
...that even LLMs like GPTs and LLaMAs use.

The Web MCP is here with 5,000 Monthly Credits

Bright Data has launched a free tier of The Web MCP, the first and only MCP designed to give LLMs and autonomous agents unblocked, real-time access to the web.
Now you can: /scrape /search /crawl /navigate The live web with 5,000 free monthly credits.
Built for developers and researchers working with open-source tools:
Key features:
Integrates seamlessly with your workflow, integrates with LangChain, AutoGPT, OpenAgents, and custom stacks.
Enables agents to dynamically expand their context with live web data
All major LLMs and IDEs are supported (locally hosted, SSE, and Streamable HTTP)
No setup fees, no credit card required.
Whether you’re building agentic workflows, RAG pipelines, or real-time assistants, The Web MCP is the protocol layer that connects your models to the open web.
Start building with 5,000 free monthly credits here →
Thanks to Bright Data for partnering today!
A Memory-efficient Technique to Train Large Models
Activation checkpointing is one technique that’s common to the training procedure of almost all popular large models, GPTs, LLaMAs, etc.
In a gist, it’s super helpful to reduce the memory overhead of large neural networks.
Let’s understand this in more detail.
On a side note, while activation checkpointing is one way, we covered 15 techniques to optimize neural network training here: 15 Ways to Optimize Neural Network Training (With Implementation).
How does Activation checkpointing work?
Activation checkpointing is based on two key observations on how neural networks work:
The activations of a specific layer can be solely computed using the activations of the previous layer. For instance, in the image below, “Layer B” activations can be computed from “Layer A” activations only:

Updating the weights of a layer only depends on two things:
The activations of that layer.
The gradients computed in the next (right) layer (or rather, the running gradients).

Activation checkpointing exploits these two observations to optimize memory utilization.
Here’s how it works:
Step 1) Divide the network into segments before the forward pass:
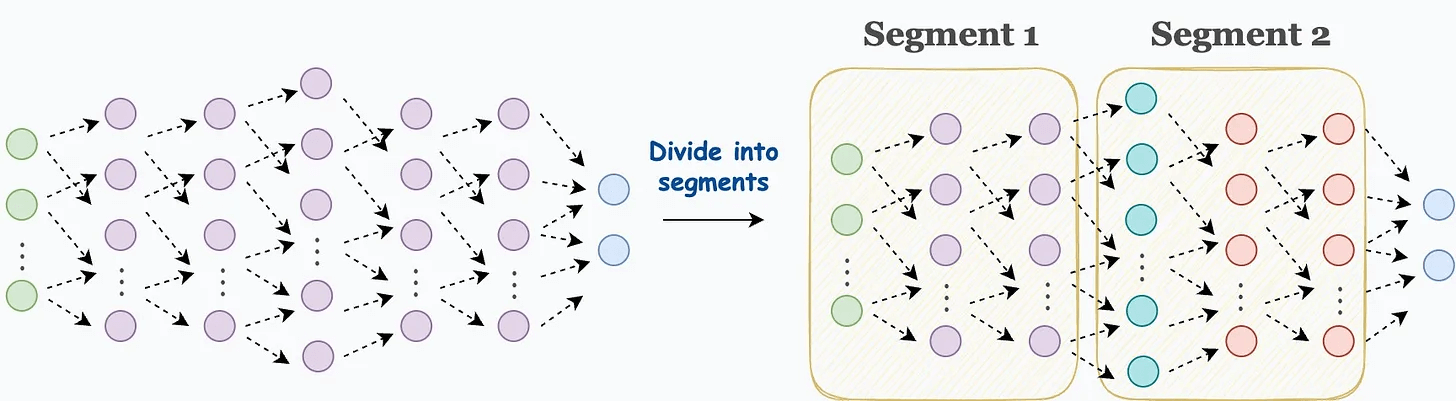
Step 2) During forward pass, store the activations of the first layer only in each segment. Discard the rest when they have been used to compute the activations of their subsequent layer.
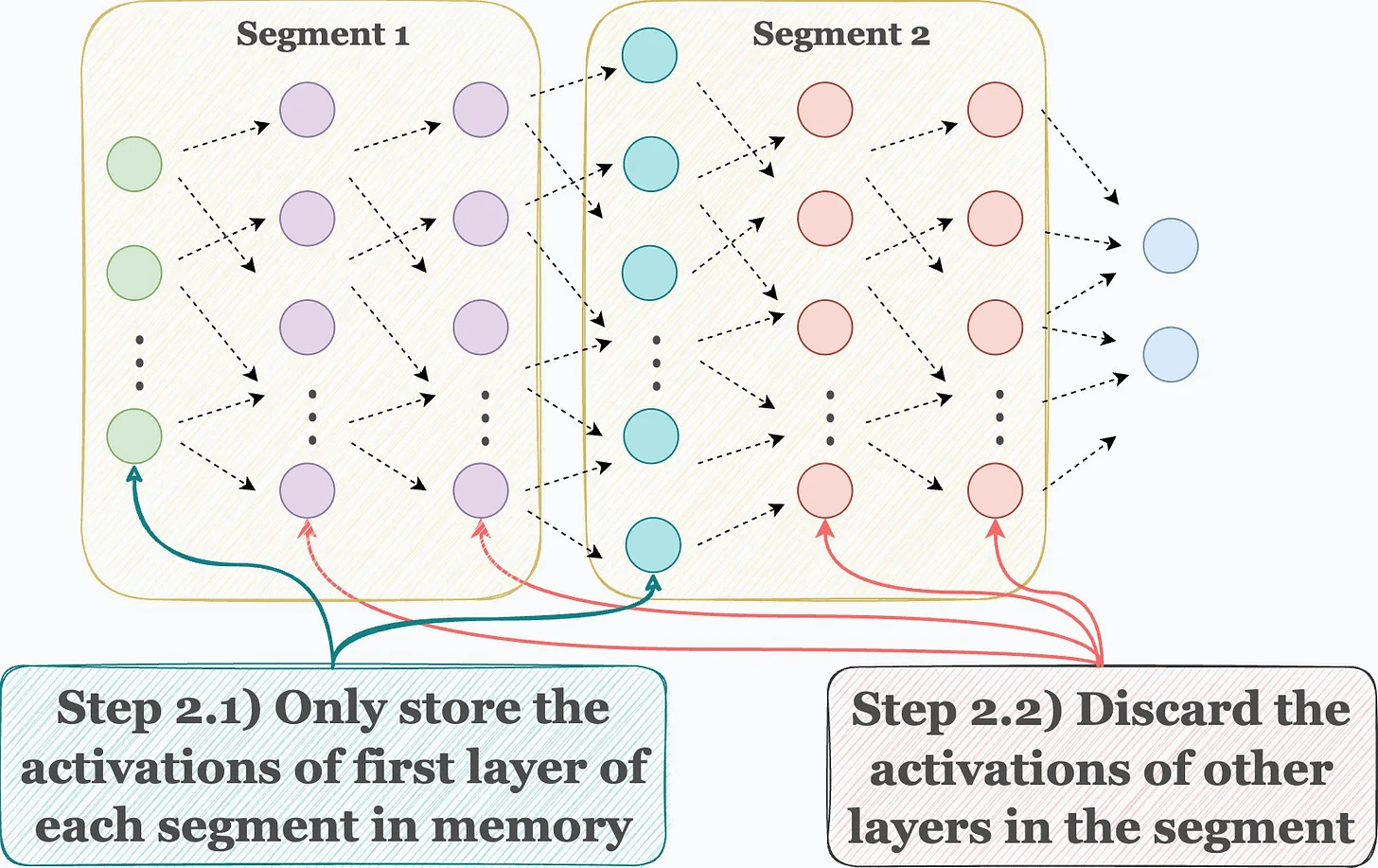
Step 3) Now comes backpropagation. To update the weights of a layer, we need its activations. Thus, we recompute those activations using the first layer in that segment.
For instance, as shown in the image below, to update the weights of the red layers, we recompute their activations using the activations of the cyan layer, which are already available in memory.
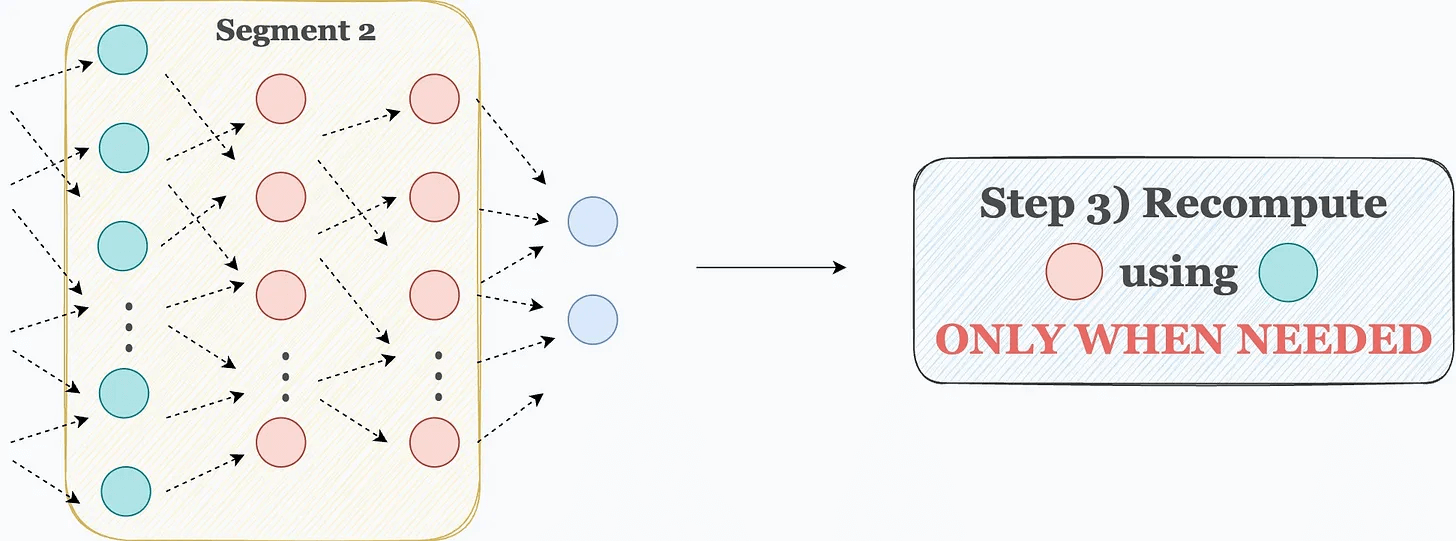
This is how Activation checkpointing works.
To summarize, the idea is that we don’t need to store all the intermediate activations in memory.
Instead, storing a few of them and recomputing the rest only when they are needed can significantly reduce the memory requirement.
Typically, activation checkpointing can reduce memory usage to sqrt(M), where M is the memory usage without activation checkpointing.
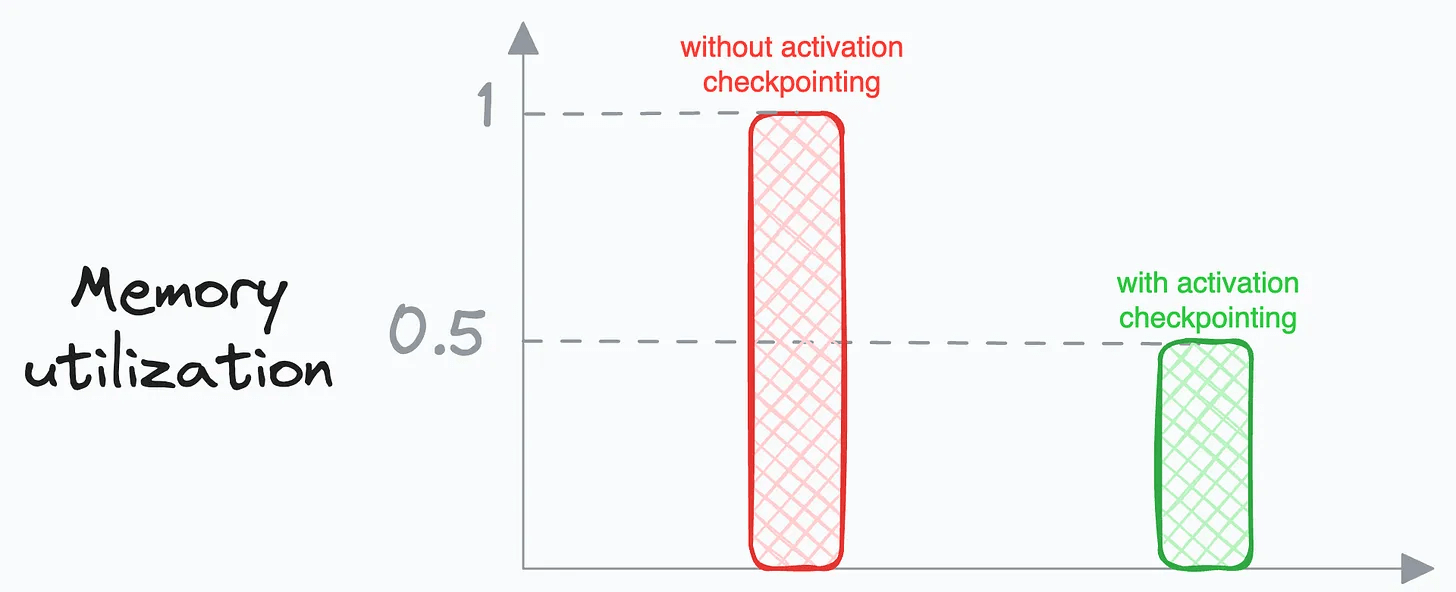
Of course, as we compute some activations twice, this does come at the cost of increased run-time, which can typically range between 15-25%.
So there’s always a tradeoff between memory and run-time.
That said, another advantage is that it allows us to use a larger batch size, which can counter the increased run-time.
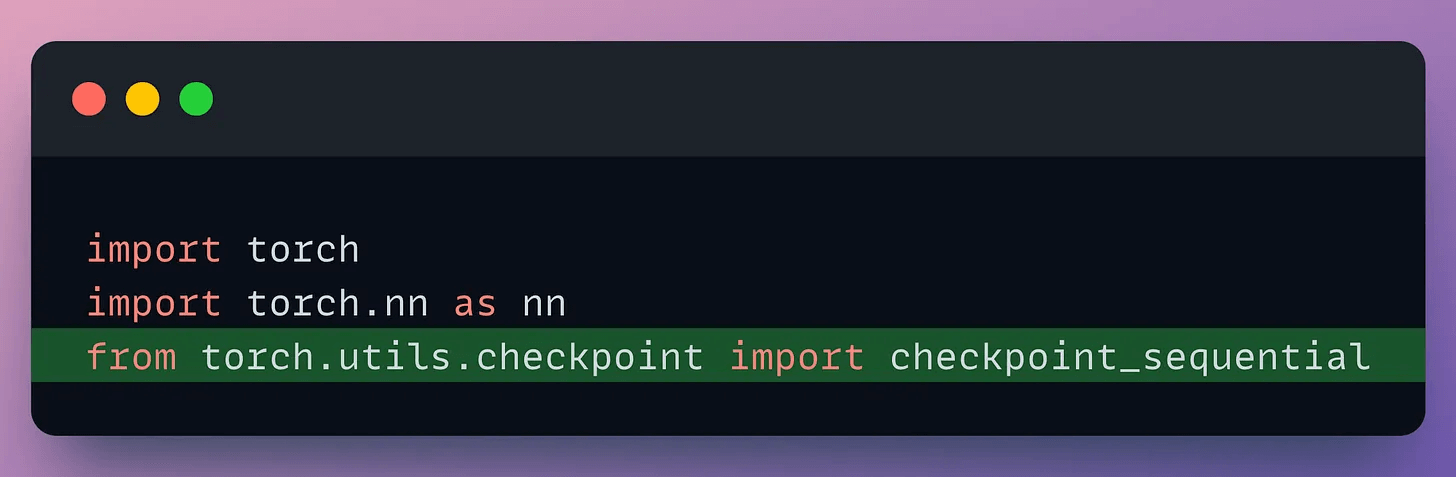
To utilize this, import the necessary libraries and functions:
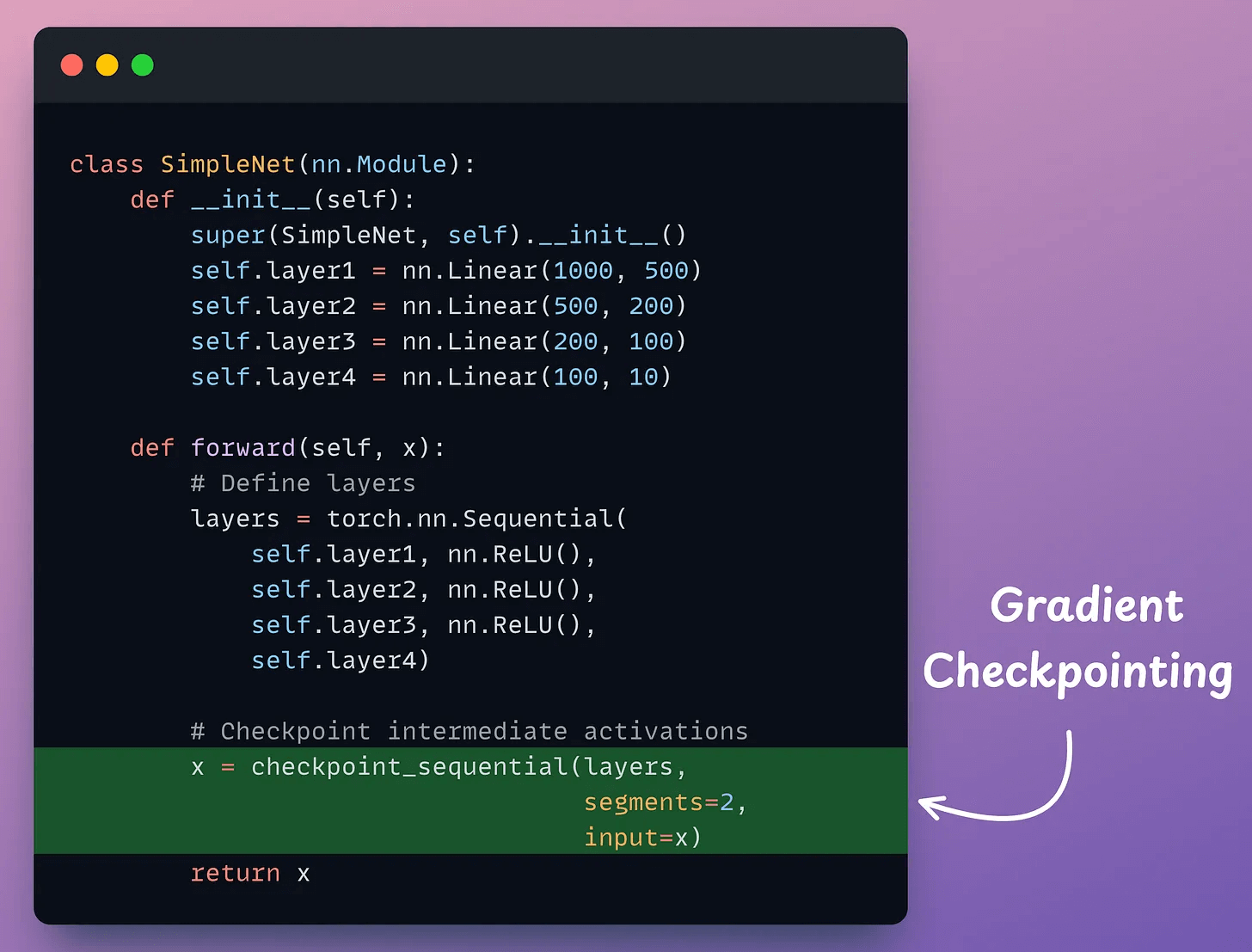
Next, define a neural network:
As demonstrated above, in the forward method, we use the checkpoint_sequential method to use activation checkpointing and divide the network into two segments.
Next, we can proceed with network training as we usually would.
While activation checkpointing is one way, we covered 15 techniques to optimize neural network training here: 15 Ways to Optimize Neural Network Training (With Implementation).
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.