
A Memory-efficient Technique to Train Large Models
...that even LLMs like GPTs and LLaMAs use.

An Open-Source Autonomous BI Agent
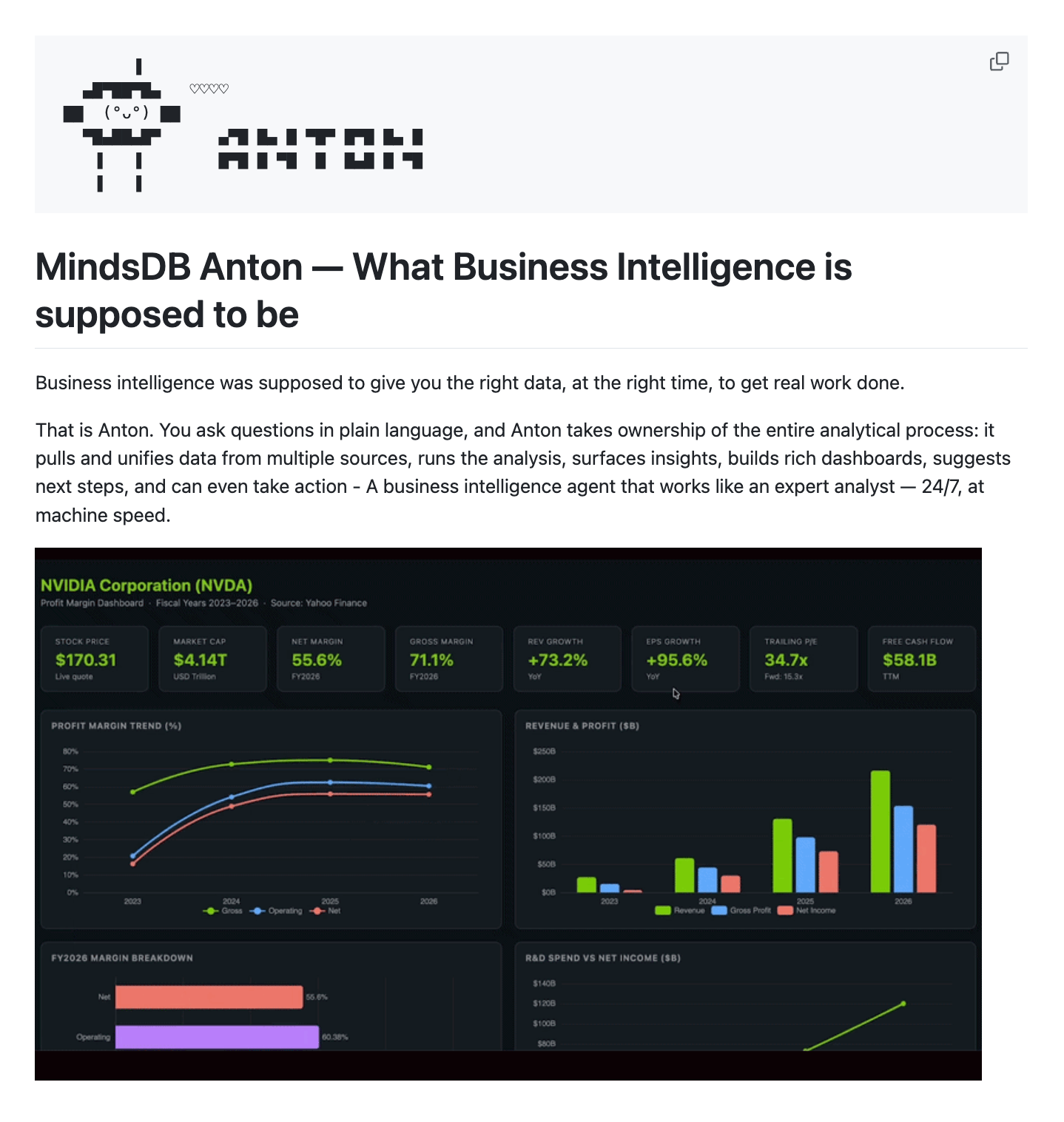
MindsDB just open-sourced Anton, an autonomous BI agent that turns plain-language questions into full dashboards.
You ask something like “Show me NVIDIA’s profit margins,” and Anton handles everything: figuring out the right data source, writing and executing the code, computing the metrics, and generating interactive visualizations.
Under the hood, it runs a sandboxed Python scratchpad that self-corrects on errors, and a memory system that learns your conventions and analysis patterns across sessions. It connects to Postgres, Snowflake, Salesforce, BigQuery, and more out of the box.
Check out Anton’s GitHub repo here →
A Memory-efficient Technique to Train Large Models
Activation checkpointing is one technique that’s common to the training procedure of almost all popular large models, GPTs, LLaMAs, etc.
In a gist, it’s super helpful to reduce the memory overhead of large neural networks.
Let’s understand this in more detail.
On a side note, while activation checkpointing is one way, we covered 15 techniques to optimize neural network training here: 15 Ways to Optimize Neural Network Training (With Implementation).
How does Activation checkpointing work?
Activation checkpointing is based on two key observations on how neural networks work:
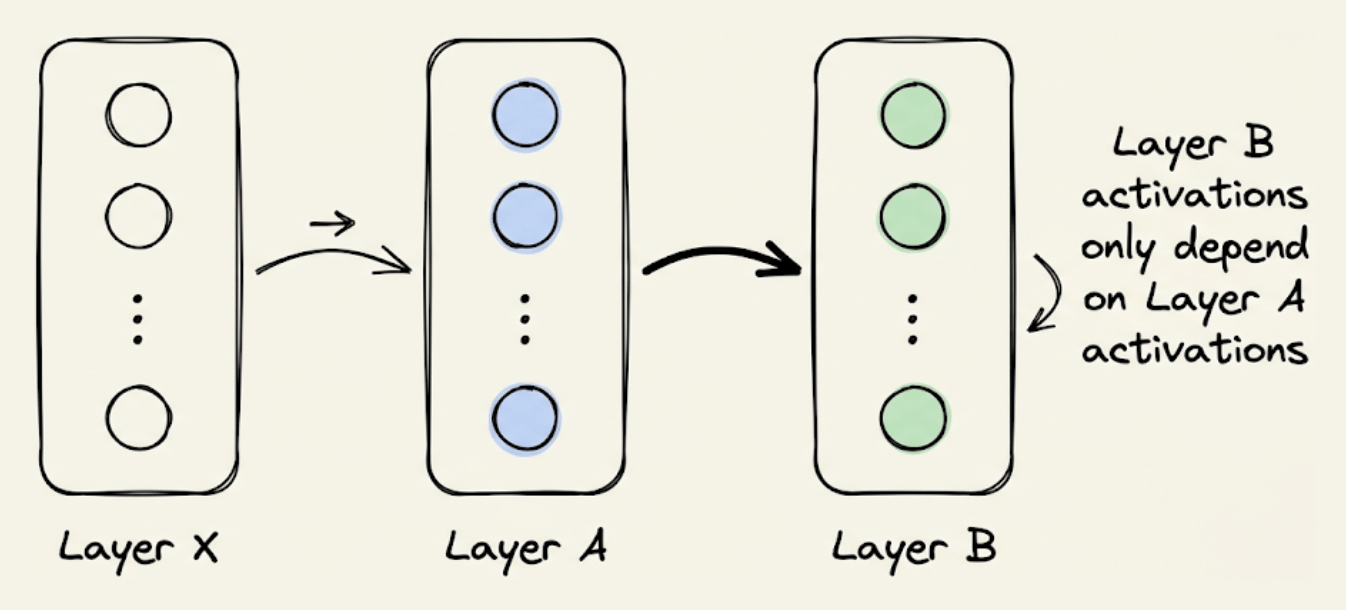
The activations of a specific layer can be solely computed using the activations of the previous layer. For instance, in the image below, “Layer B” activations can be computed from “Layer A” activations only:
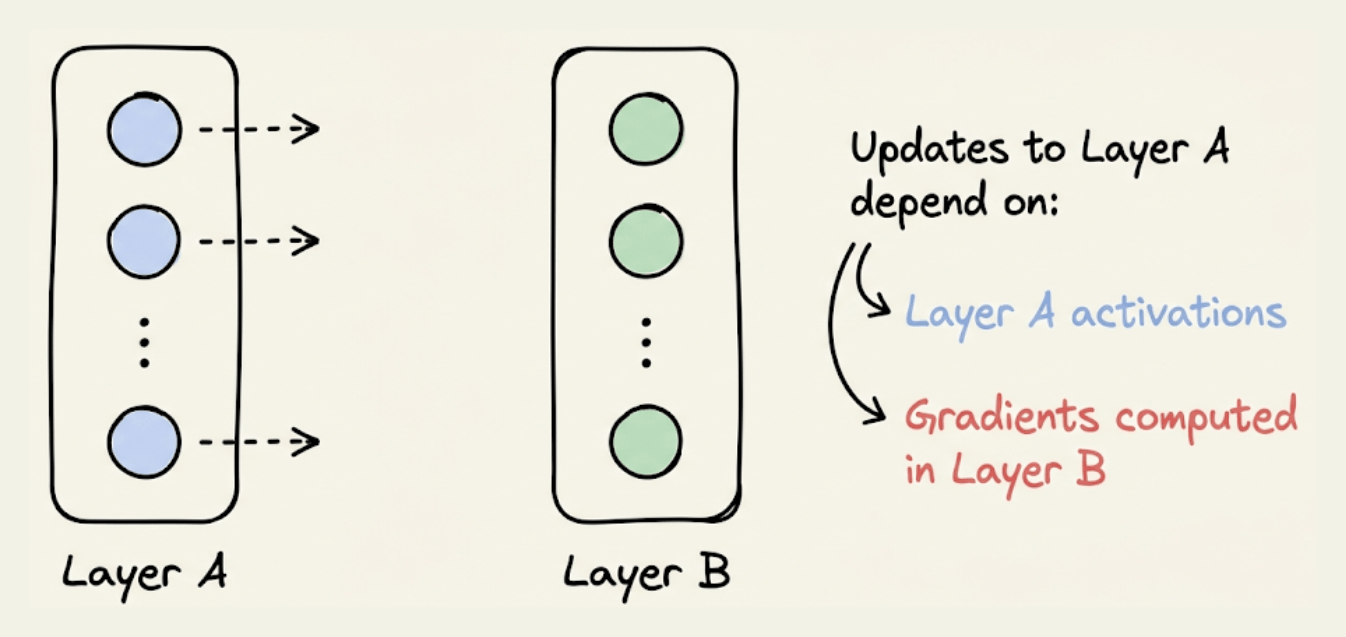
Updating the weights of a layer only depends on two things:
The activations of that layer.
The gradients computed in the next (right) layer (or rather, the running gradients).
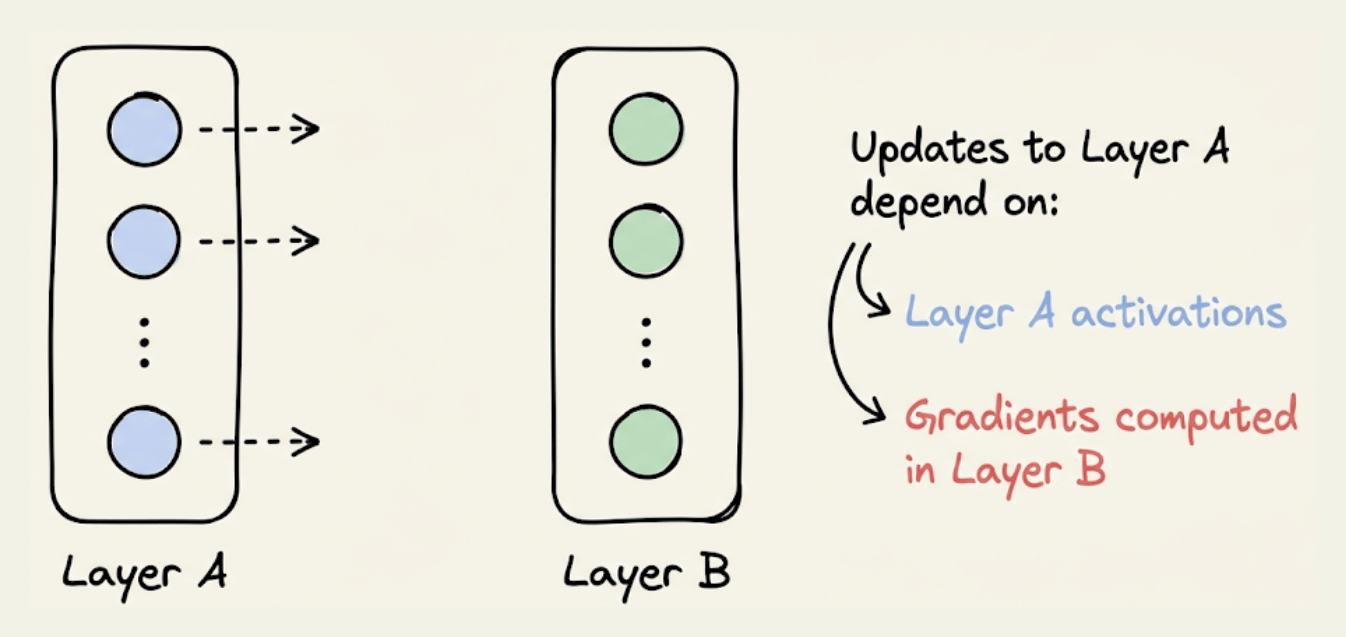
Activation checkpointing exploits these two observations to optimize memory utilization.
Here’s how it works:
Step 1) Divide the network into segments before the forward pass:
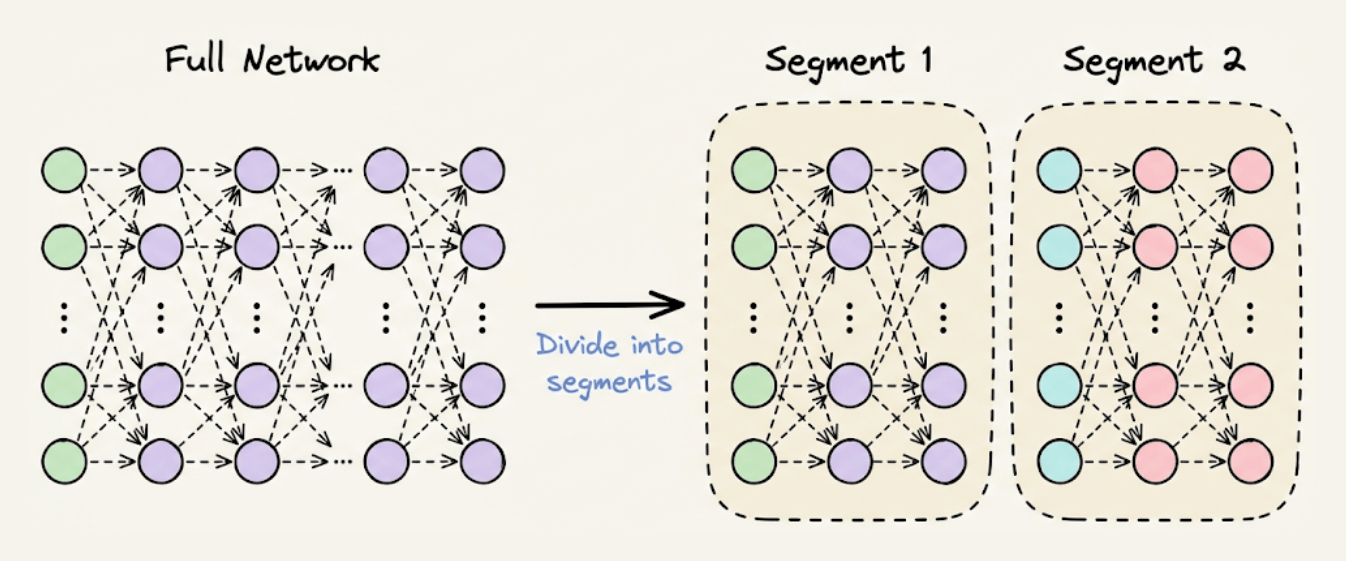
Step 2) During forward pass, store the activations of the first layer only in each segment. Discard the rest when they have been used to compute the activations of their subsequent layer.
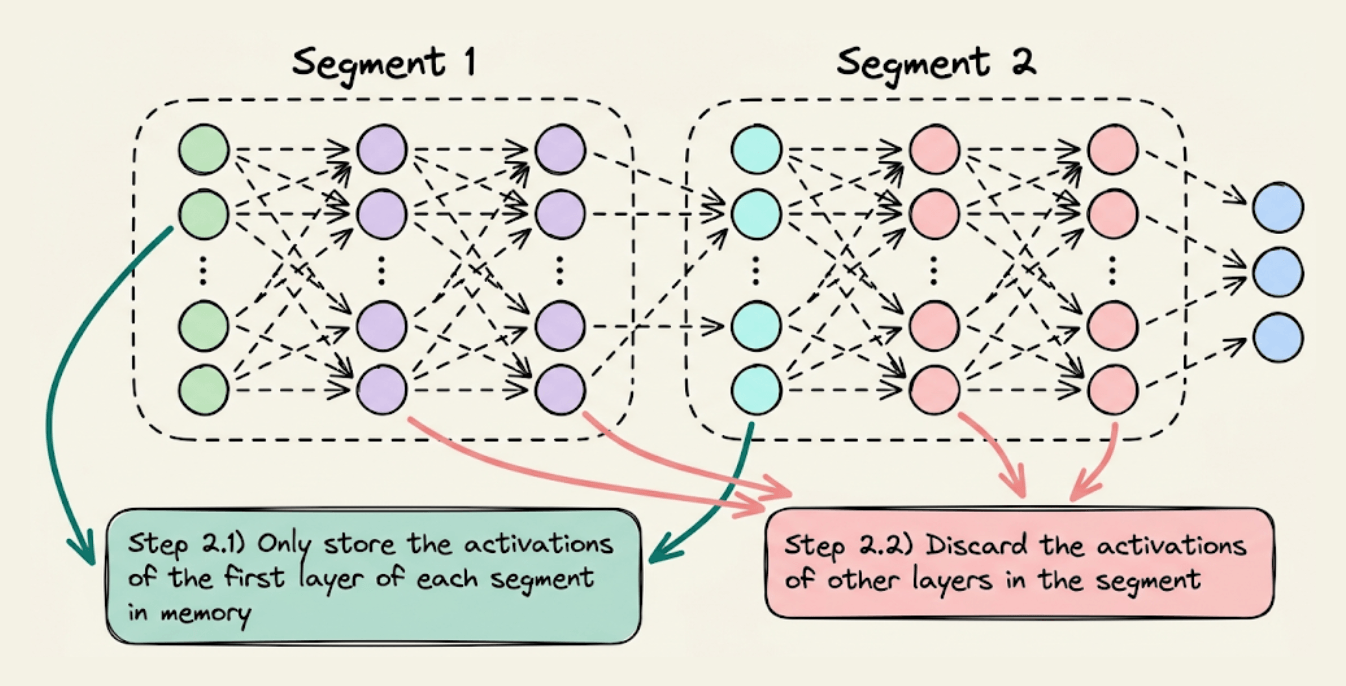
Step 3) Now comes backpropagation. To update the weights of a layer, we need its activations. Thus, we recompute those activations using the first layer in that segment.
For instance, as shown in the image below, to update the weights of the red layers, we recompute their activations using the activations of the cyan layer, which are already available in memory.
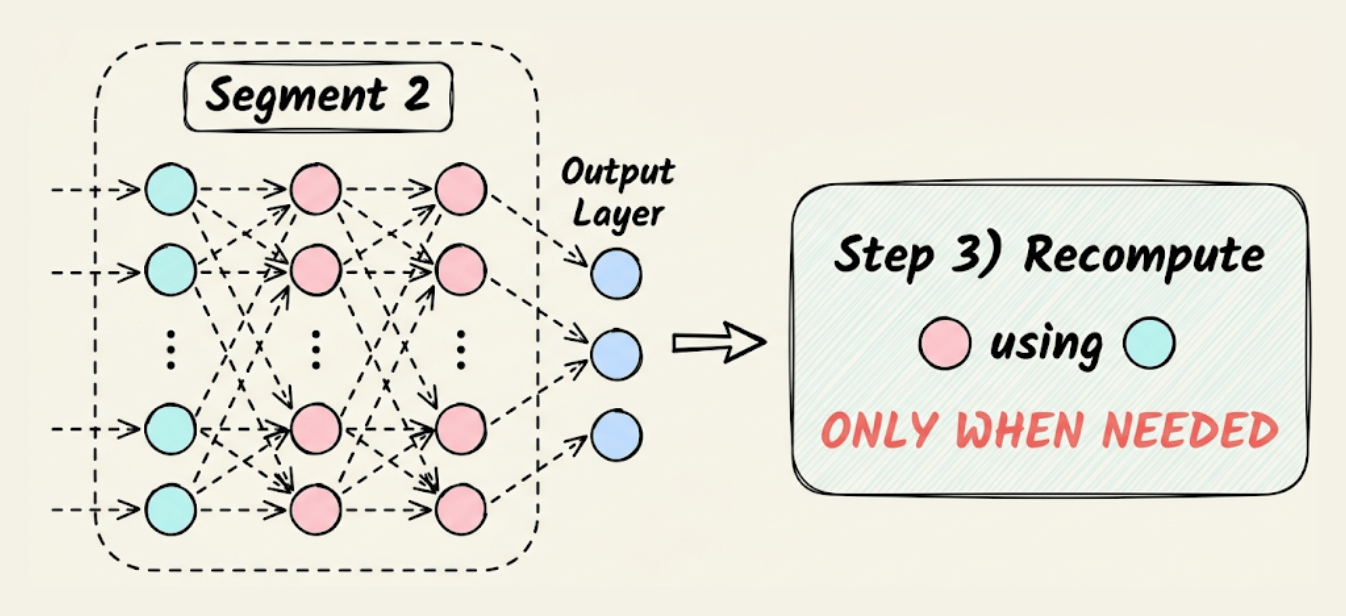
This is how Activation checkpointing works.
To summarize, the idea is that we don’t need to store all the intermediate activations in memory.
Instead, storing a few of them and recomputing the rest only when they are needed can significantly reduce the memory requirement.
Typically, activation checkpointing can reduce memory usage to sqrt(M), where M is the memory usage without activation checkpointing.
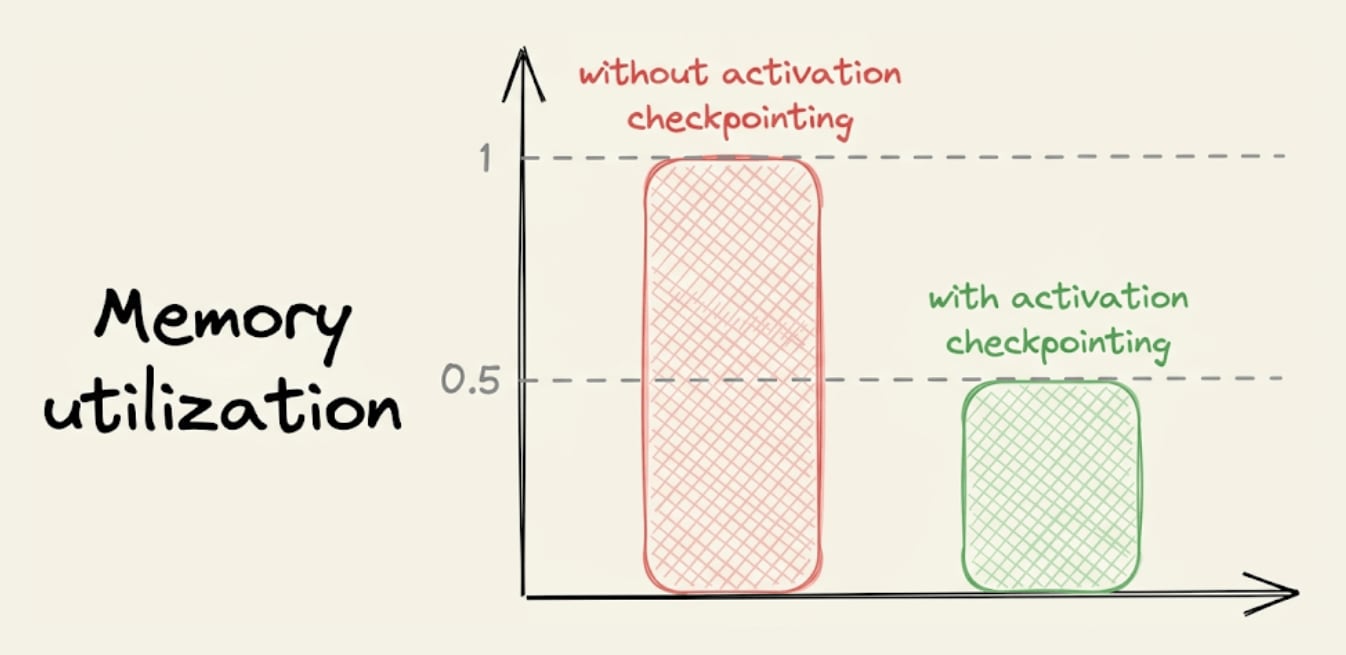
Of course, as we compute some activations twice, this does come at the cost of increased run-time, which can typically range between 15-25%.
So there’s always a tradeoff between memory and run-time.
That said, another advantage is that it allows us to use a larger batch size, which can counter the increased run-time.
To utilize this, import the necessary libraries and functions:
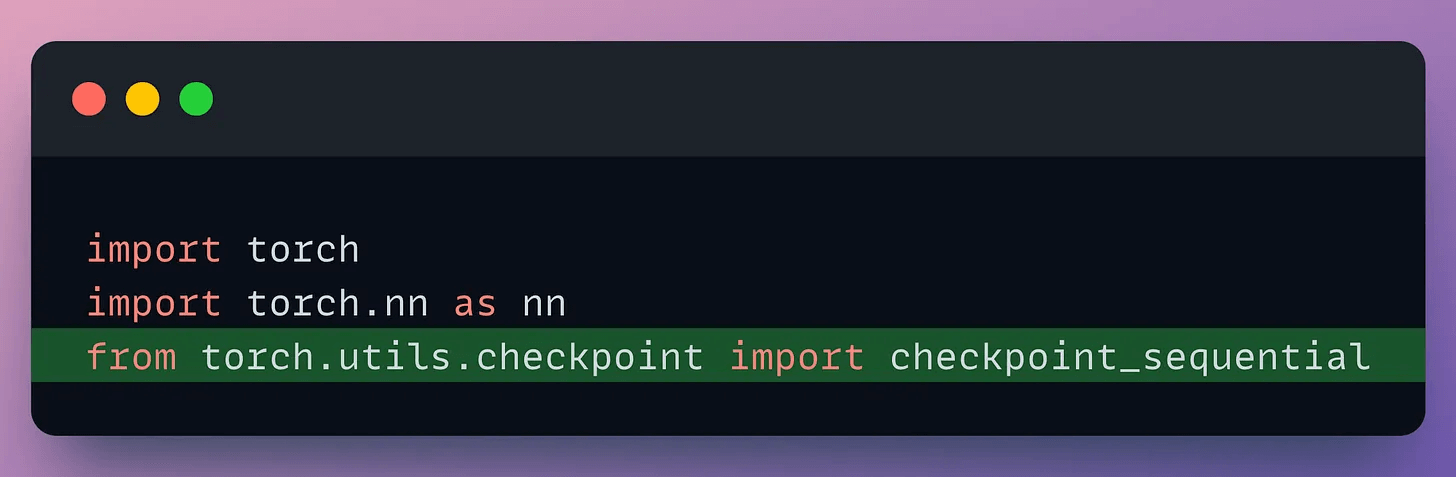
Next, define a neural network:
As demonstrated above, in the forward method, we use the checkpoint_sequential method to use activation checkpointing and divide the network into two segments.
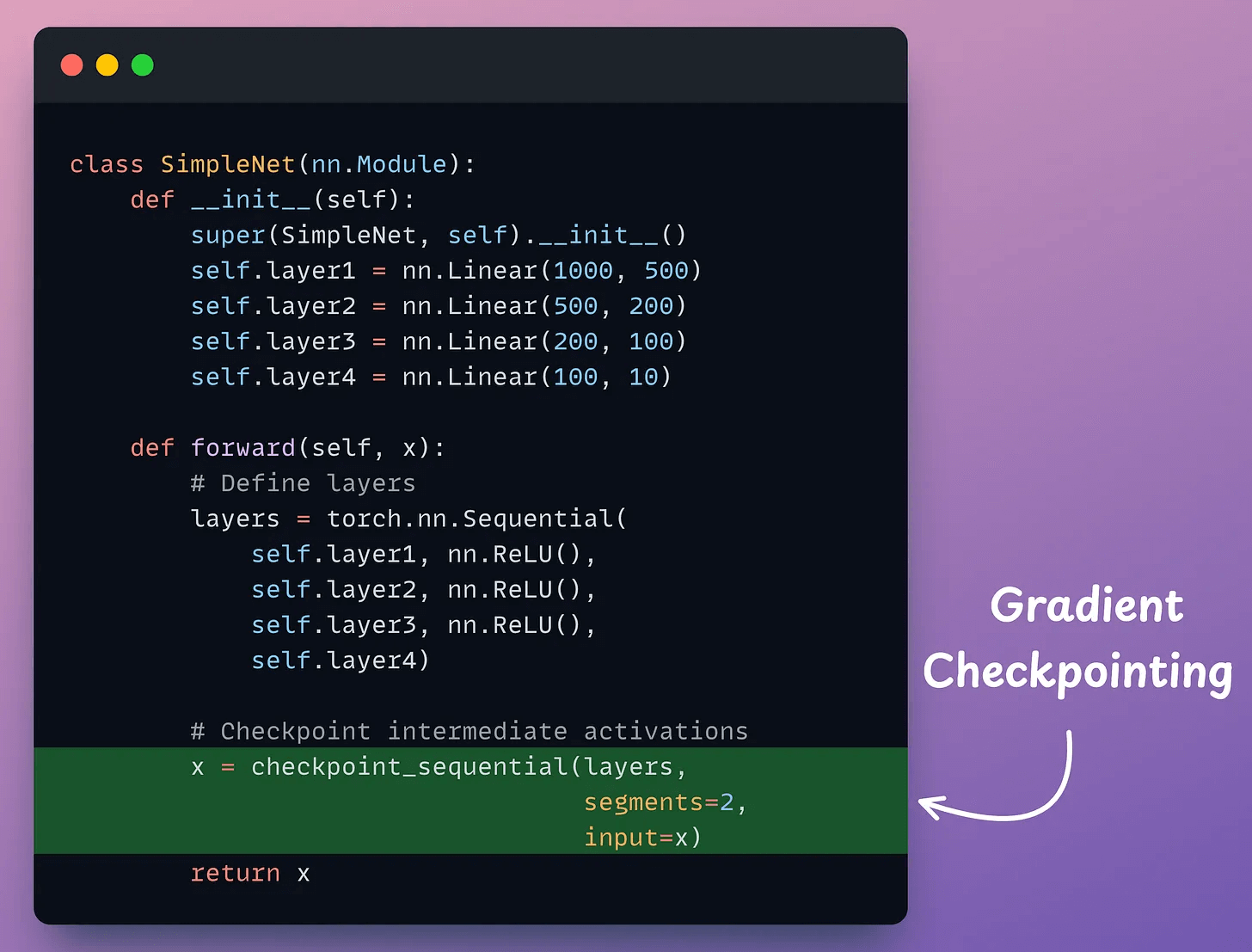
Next, we can proceed with network training as we usually would.
While activation checkpointing is one way, we covered 15 techniques to optimize neural network training here: 15 Ways to Optimize Neural Network Training (With Implementation).
Types of Memory in AI Agents
Agents without memory aren’t agents at all.
We often assume LLMs remember things. They feel like humans, but the truth is that LLMs are stateless.
If you want your agent to recall anything (past chats, preferences, behaviors), you have to build memory into it.
But how to do that?
Let’s understand this step-by-step!
Agent memory comes in two scopes:
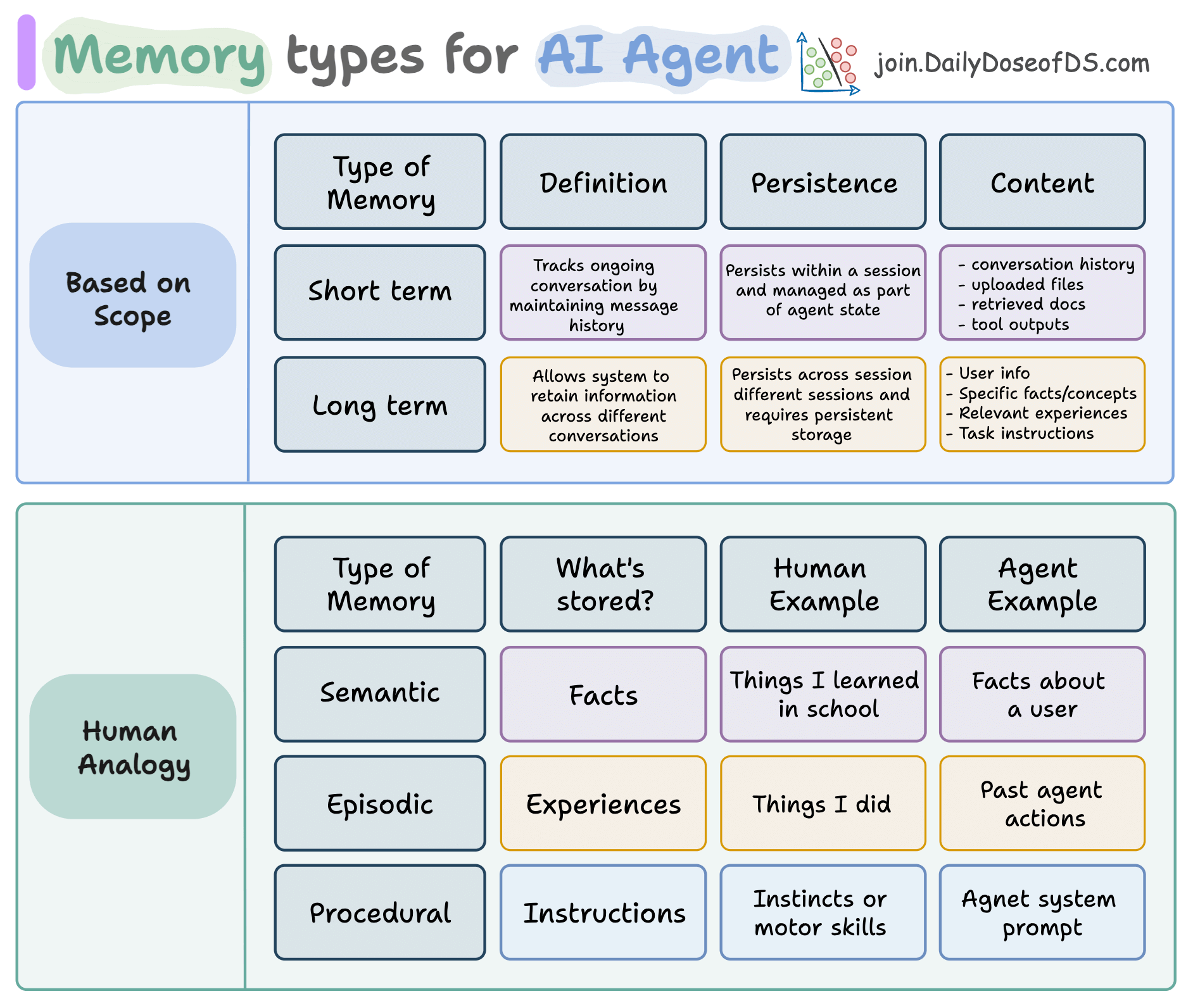
Short-term: Handles current conversations. Maintains message history, context, and state across a session.
Long-term: Spans multiple sessions. Remembers preferences, past actions, and user-specific facts.
But there’s more.
Just like humans, long-term memory in agents can be:
Semantic → Stores facts and knowledge
Episodic → Recalls past experiences or task completions
Procedural → Learns how to do things (think: internalized prompts/instructions)
This memory isn’t just nice-to-have; it enables agents to learn from past interactions without retraining the model.
This is especially powerful for continual learning: letting agents adapt to new tasks without touching LLM weights.
All this is actually implemented in Cognee, a popular open-source knowledge engine (~15k stars) that provides a graph-based, self-improving memory system for your agents.
It uses an ECL (Extract, Cognify, Load) pipeline to turn raw data into structured knowledge graphs with embeddings and relationships, making your agent’s memory both searchable by meaning and connected by relationships.
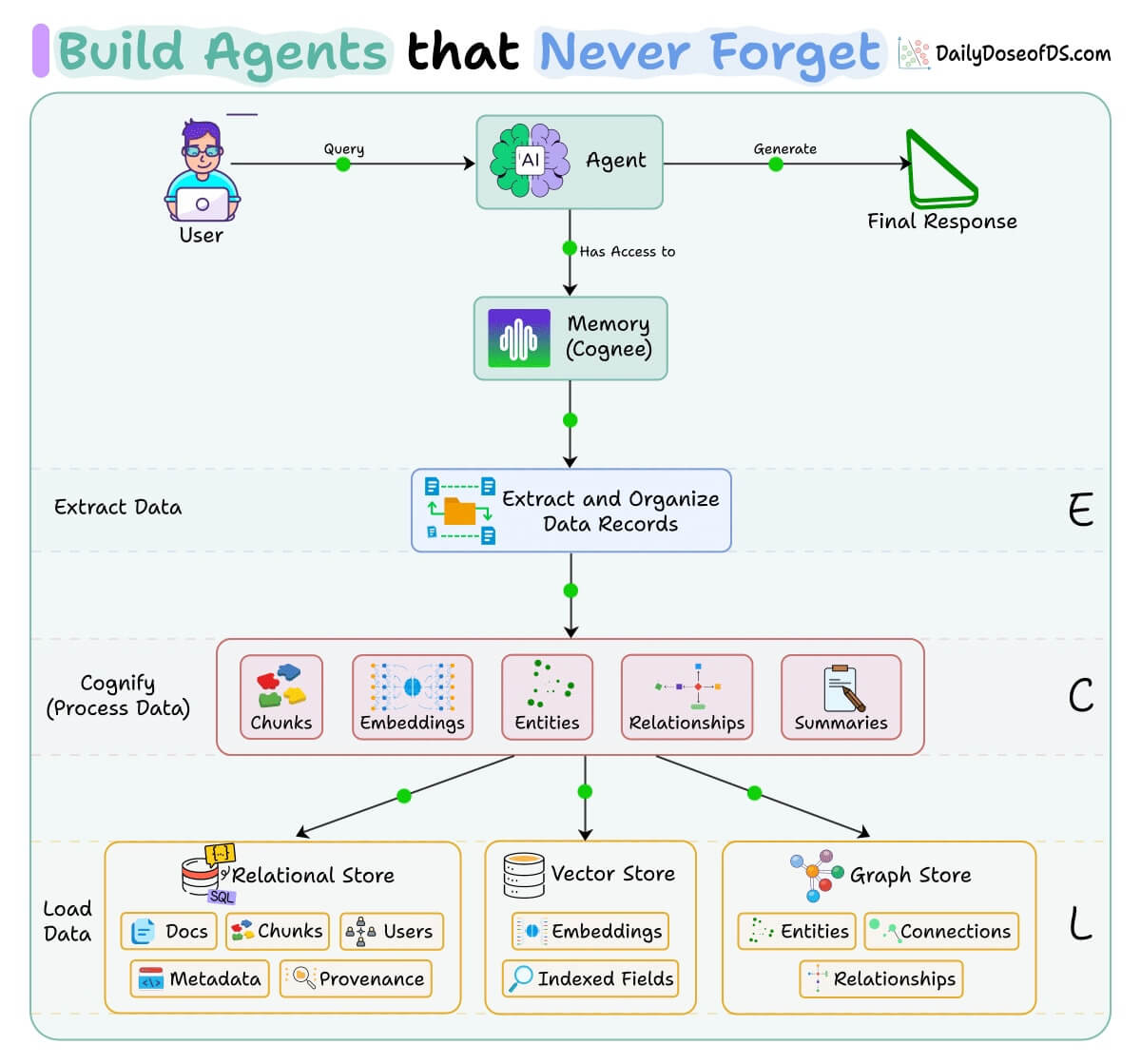
You can see the full implementation and try it yourself.
Here’s the repo → (don’t forget to star it)

Also, in Part 8 and Part 9 of the Agents’ crash course, we primarily focused on 5 types of Memory for AI agents, with implementation.
And in Part 15, Part 16 and Part 17, we covered practical ways to optimize the Agent’s memory in production use cases.
Thanks for reading!