
A More Robust and Underrated Alternative To Random Forests
Extra does not always mean more.


We know that Decision Trees always overfit.
This is because by default, a decision tree (in sklearn’s implementation, for instance), is allowed to grow until all leaves are pure.
As the model correctly classifies ALL training instances, this leads to:
100% overfitting, and
poor generalization
Random Forest address this by introducing randomness in two ways:
While creating a bootstrapped dataset.
While deciding a node’s split criteria by choosing candidate features randomly.
Yet, the chances of overfitting are still high.
The Extra Trees algorithm is an even more robust alternative to Random Forest.
👉 Note:
Extra Trees does not mean more trees.
Instead, it should be written as ExtRa, which means Extra Randomized.
ExtRa Trees are Random Forests with an additional source of randomness.
Here’s how it works:
Create a bootstrapped dataset for each tree (same as RF)
Select candidate features randomly for node splitting (same as RF)
Now, Random Forest calculates the best split threshold for each candidate feature.
But ExtRa Trees chooses this split threshold randomly.
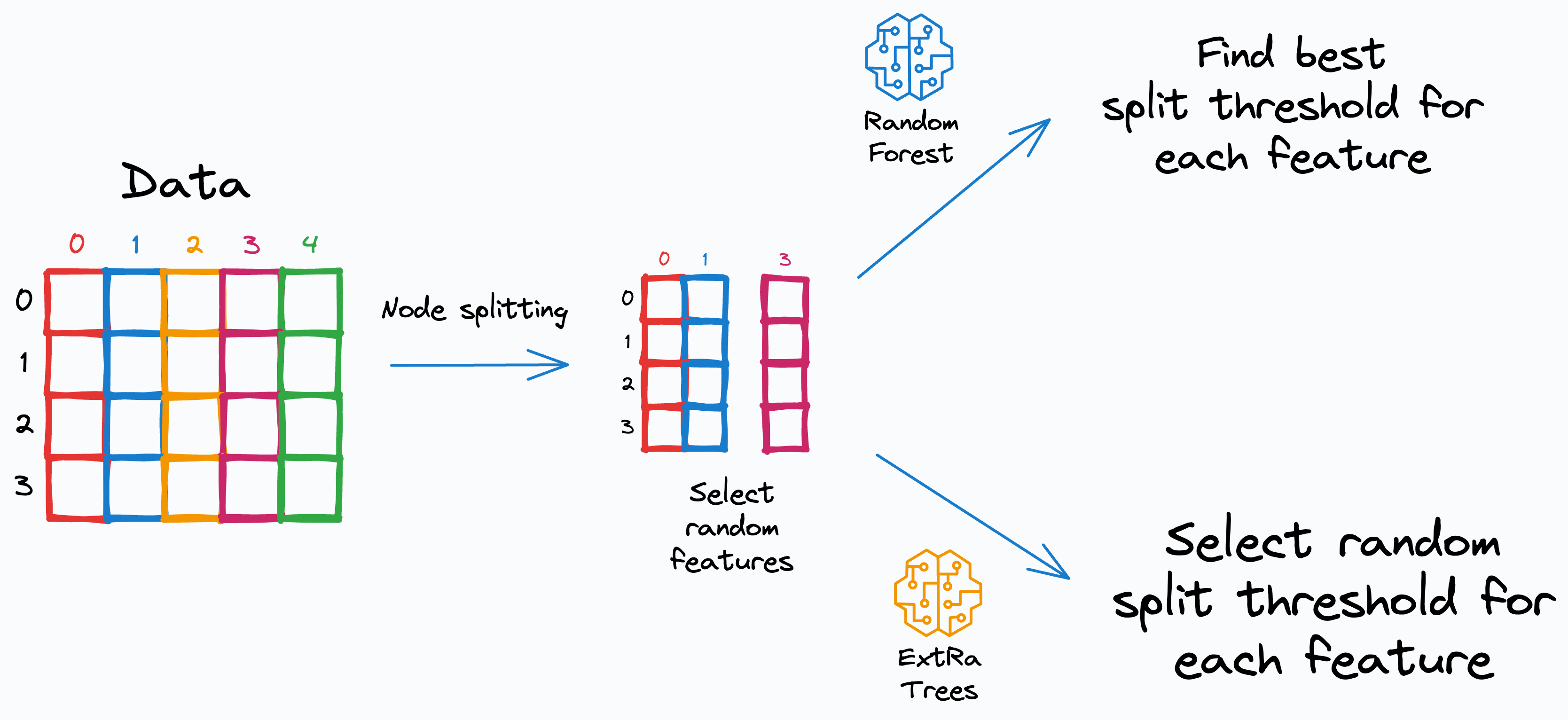
This is the source of extra randomness.
After that, the best candidate feature is selected.
This further reduces the variance of the model.
The effectiveness is evident from the image below:

Decision Trees entirely overfit
Random Forests work better
Extra Trees performs even better
⚠️ A cautionary measure while using ExtRa Trees from Sklearn.
By default, the bootstrap flag is set to False.

Make sure you run it with bootstrap=True, otherwise, it will use the whole dataset for each tree.
👉 Over to you: Can you think of another way to add randomness to Random Forest?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Whenever you’re ready, here are a couple of more ways I can help you:
Get the full experience of the Daily Dose of Data Science. Every week, receive two curiosity-driven deep dives that:
Make you fundamentally strong at data science and statistics.
Help you approach data science problems with intuition.
Teach you concepts that are highly overlooked or misinterpreted.
Promote yourself (or your brand) to 27,000 subscribers by sponsoring this newsletter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Really helpful!! Thank you so much for sharing!!
Very good , and concise explanation ! Thank you very much for the informative newsletter !