
A Practical Deep Dive on LLM Inference and Optimization!
...covered with fundamentals, bottlenecks, and techniques!

After covering LLM fine-tuning techniques in the full LLMOps course, we now move to LLM inference and optimization.
Read Part 13 of the full LLMOps course here →
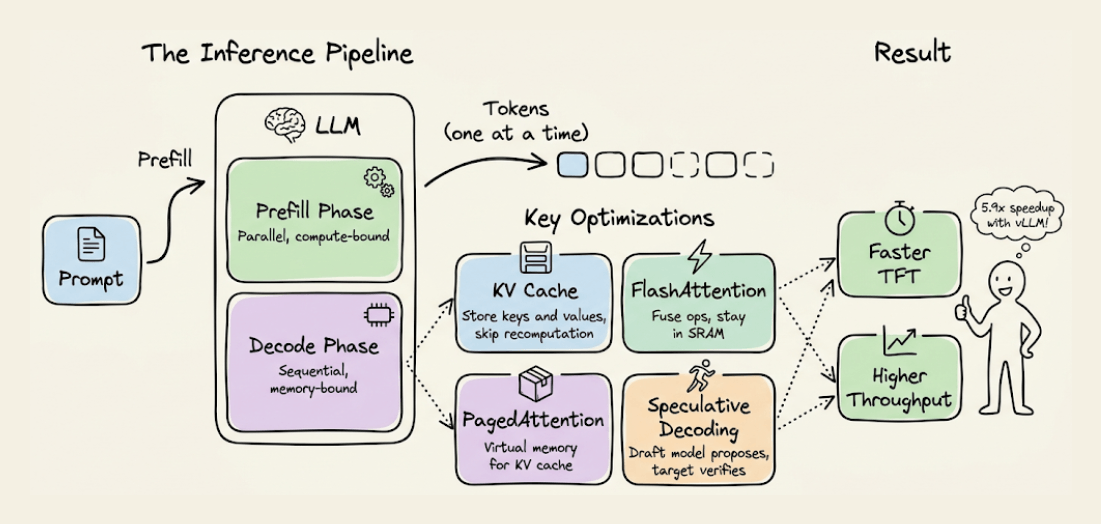
It covers how LLM inference actually works under the hood, the prefill and decode phases, KV caching and its optimizations like PagedAttention and prefix caching, attention-level optimizations like FlashAttention and GQA, speculative decoding, model parallelism strategies, and hands-on experiments comparing vLLM with standard inference.
Read Part 13 of the full LLMOps course here →
Why care?
Fine-tuning a model is only half the picture. If you cannot serve it efficiently, none of that effort translates to a usable product.
In production, inference costs often dwarf training costs. A model that takes too long to respond loses users. A model that cannot handle concurrent requests wastes GPU capacity. And a model that runs out of memory on long contexts breaks down entirely.
LLM inference optimization is what bridges the gap between a model that works in a notebook and a model that works at scale. Techniques like KV caching, PagedAttention, continuous batching, and speculative decoding are not optional extras. They are what make real-time LLM applications possible.
This chapter gives you a precise mental model of how inference works and the practical toolkit to make it faster, cheaper, and more scalable.
Read Part 2 on understanding the core building blocks of LLMs →
Read Part 11 on evaluation of multi-turn systems, tool use evaluations, tracing, and red teaming →
Over to you: What would you like to learn in the LLMOps course?
Thanks for reading!