
A Reliable and Efficient Technique To Measure Feature Importance
Measure feature importance through chaos.

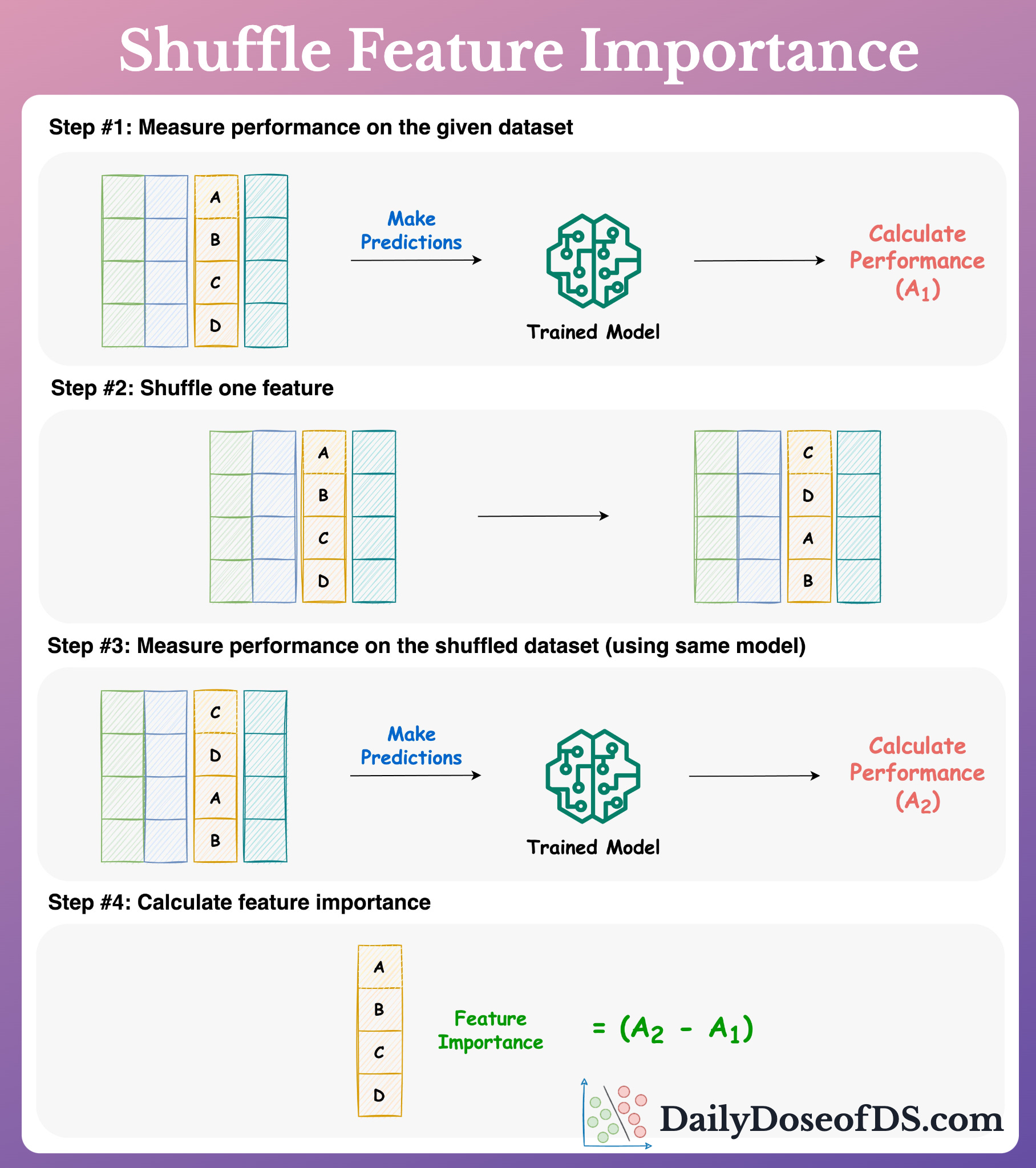
Here's a neat technique to quickly and reliably measure feature importance in any ML model.
Permutation feature importance observes how randomly shuffling a feature influences model performance.
Essentially, after training a model, we do the following:
Measure model performance (
A1) on the given dataset (test/validation/train).Shuffle one feature randomly.
Measure performance (
A2) again.Feature importance = (
A1-A2).Repeat for all features.
To eliminate any potential effects of randomness during feature shuffling, it is also recommended to shuffle the same feature multiple times.
Benefits of permutation feature importance:
No repetitive model training.
The technique is pretty reliable.
It can be applied to any model, as long as you can evaluate the performance.
It is efficient
Of course, there is one caveat to this approach.
Say two features are highly correlated and one of them is permuted/shuffled. In this case, the model will still have access to the feature through its correlated feature.
This will result in a lower importance value for both features.
One way to handle this is to cluster features that are highly correlated and only keep one feature from each cluster.
Here’s one of my previous guides on making this task easier: The Limitations Of Heatmap That Are Slowing Down Your Data Analysis.
👉 Over to you: What other reliable feature importance techniques do you use frequently?
Thanks for reading!
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Model Compression: A Critical Step Towards Efficient Machine Learning.
Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
Where Did The Assumptions of Linear Regression Originate From?
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!