
A Simple Implementation of Boosting Algorithm
A hands-on guide to understand how boosting is implemented.

Boosting is quite simple. The following visual summarizes it:

The subsequent model utilizes information from the previous model to form a more informed model.
While the idea is simple…
…many find it difficult to understand how this model is precisely trained and how information from a previous model is used by a subsequent model.
If you are one of them, let me show you a simple boosting implementation using the decision tree regressor of sklearn.
Let’s begin!
Firstly, you need to understand that there are a limited number of design choices that go into building a boosting model:
How you construct each tree → Which features to split on at each level and the splitting criteria.

How to construct the next tree based on the current trees → The variable here is the loss function. This guides the model on how to focus the next tree to correct the errors of the previous ones.


How to weigh the contribution of each tree in the final model → This determines the influence of each tree in the overall ensemble.
That’s mostly it!
Vary the design choice of these three factors and you get a different boosting algorithm.
Let me give you a simple demo of how this works.
Consider the following dummy dataset:

We construct the first tree on this dataset as follows:

Measuring the performance (R2), we get:

Now, we must construct the next tree. To do this, we fit another model on the residuals (true-predicted) of the first tree:

Yet again, we measure the performance of the current ensemble:

Tree1 captures some variance, and tree2 captures the residual not captured by tree1. So the final prediction is the sum of both predictions.The R2 score has jumped from 0.68 to 0.81.
Now, let’s construct another tree on the residuals (true-predicted) of the current ensemble:

Let’s measure the performance once again:

The R2 score has jumped from 0.81 to ~0.88.
We can continue to build the ensemble this way and generate better scores.
The implementation was simple, wasn’t it?
At this point, we can also visualize this performance improvement by incrementally plotting the fit obtained as we add more trees:
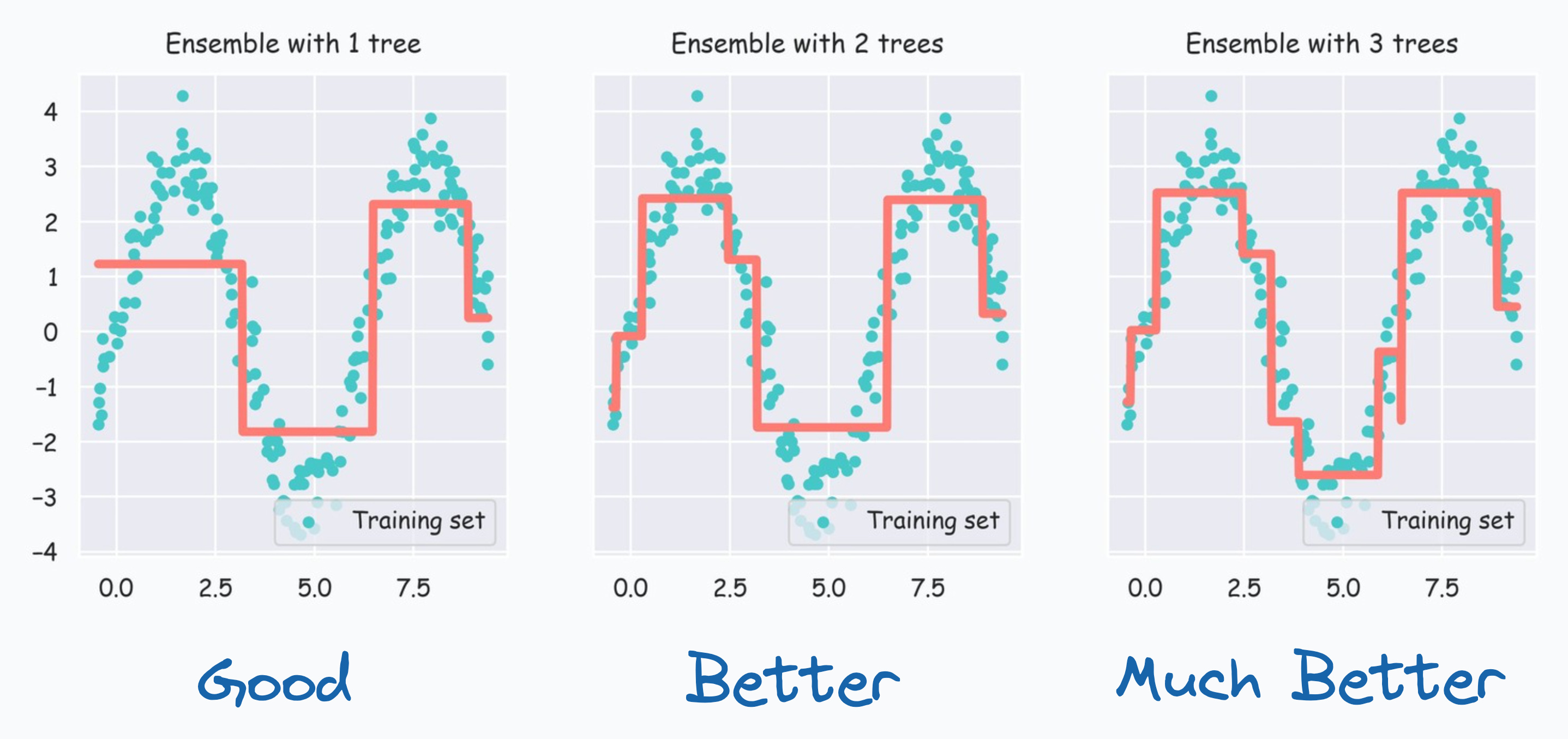
From the above diagram, it is clear that as we add more trees, the model tends to fit the dataset better.
And that is how Boosting is implemented.
Tree-based ensembles, or rather I should say, boosting algorithms, have been one of the most significant contributions to tabular machine learning in my opinion.
The reason why I did not mention bagging algorithms is because, in my personal experience, I have rarely found them to perform better than boosting algorithms.
And it isn’t quite hard to understand why I say so.
👉 Over to you: Can you tell why, typically, Boosting > Bagging?
To understand Bagging from a mathematical perspective, we covered it in detail here: Why Bagging is So Ridiculously Effective At Variance Reduction?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 85,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Great explanation! Thanks a lot!