
A Simplified and Intuitive Categorisation of Discriminative Models
A popular interview question.

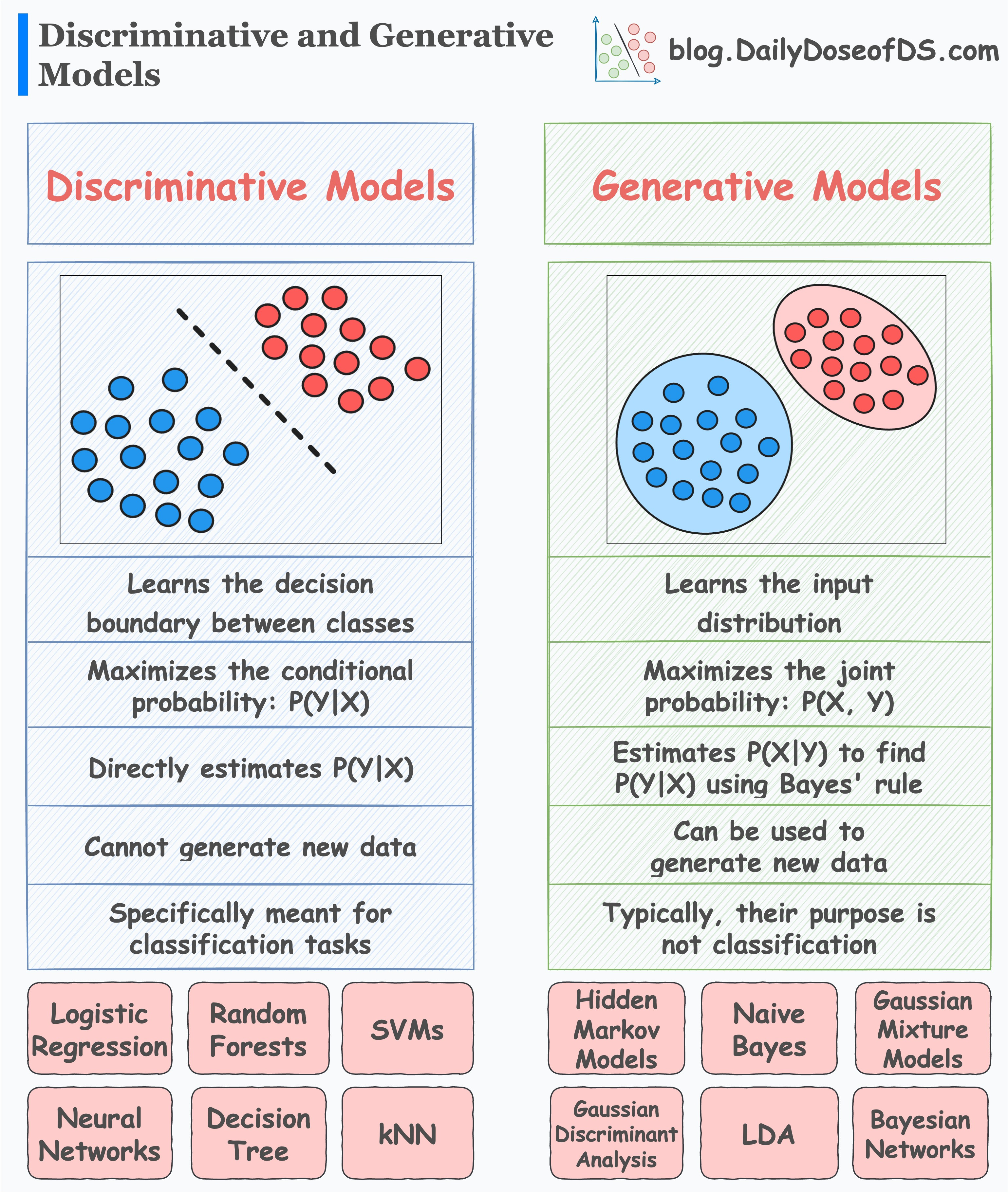
In yesterday’s post, we discussed Generative and Discriminative Models.
Here’s the visual from that post for a quick recap:
In today’s post, we shall dive into a further categorization of discriminative models.
A Quick Recap
Discriminative models:

learn decision boundaries that separate different classes.
maximize the conditional probability:
P(Y|X)— Given an input X, maximize the probability of label Y.are meant explicitly for classification tasks.
Generative models:

maximize the joint probability:
P(X, Y)learn the class-conditional distribution
P(X|Y)are typically not meant for classification tasks, but they can perform classification nonetheless.
Check yesterday’s post for more details: Generative and Discriminative Models.
Further distinction of discriminative models
In a gist, discriminative models directly learn the function f that maps an input vector (x) to a label (y).
They can be further divided into two categories:
Probabilistic models
Direct labeling models
The following visual neatly summarizes their differences:
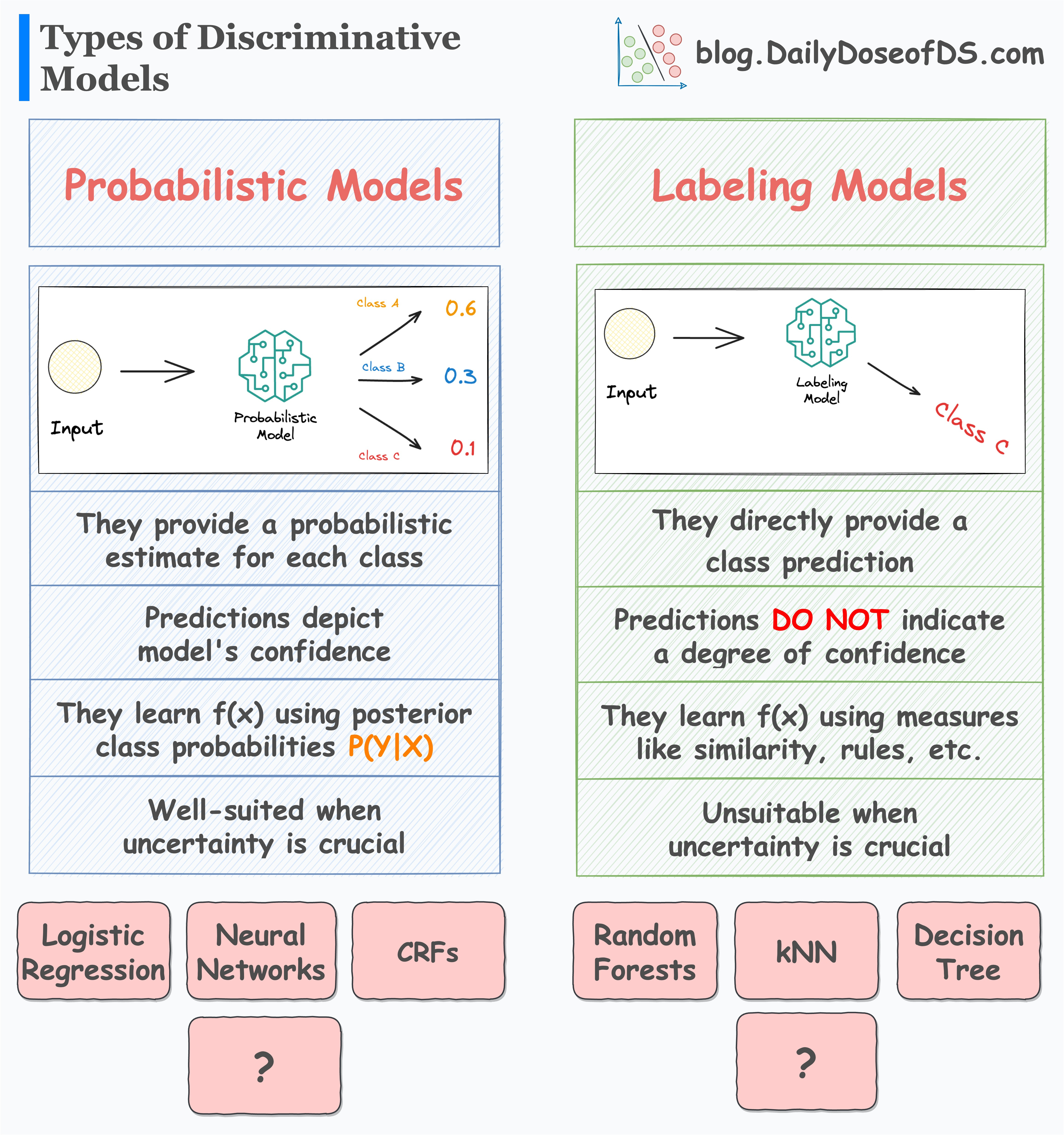
Probabilistic models
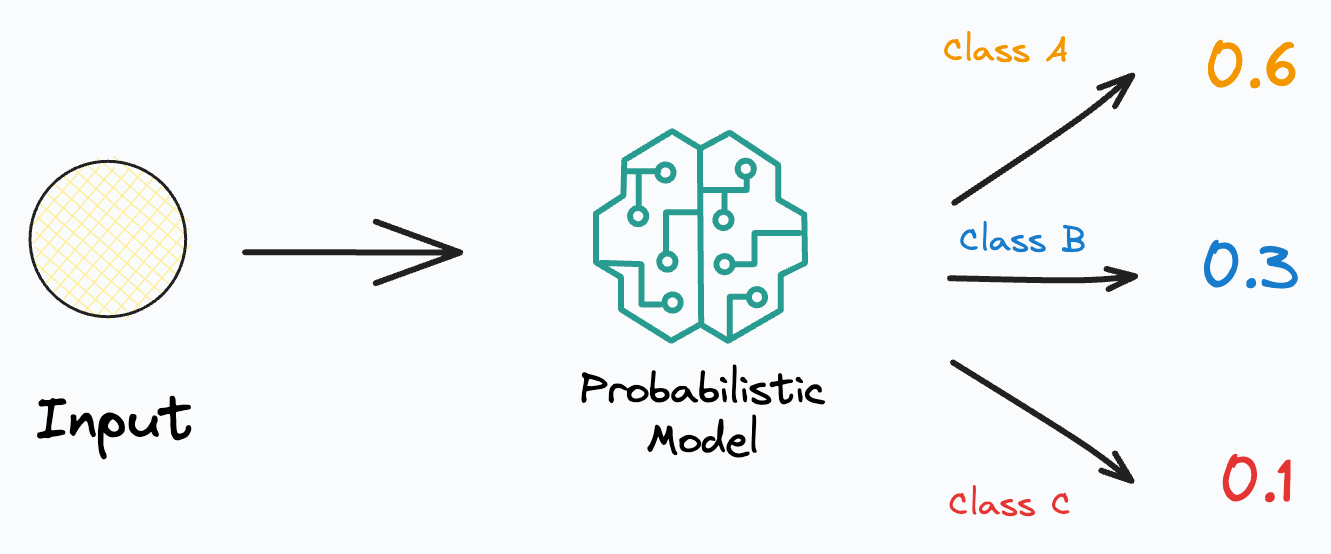
As the name suggests, probabilistic models provide a probabilistic estimate for each class.
They do this by learning the posterior class probabilities P(Y|X) — given an input X, what is the probability of a label Y.
As a result, their predictions depict the model’s confidence in predicting a specific class label.
This makes them well-suited in situations when uncertainty is crucial to the problem at hand.
Examples include:
Logistic regression
Neural networks
Conditional Random Fields (CRFs)
Labeling models

In contrast to probabilistic models, labeling models (also called distribution-free classifiers) directly predict the class label, without providing any probabilistic estimate.
As a result, their predictions DO NOT indicate a degree of confidence.
This makes them unsuitable when uncertainty in a model’s prediction is crucial.
Examples include:
Random forests
kNN
Decision trees
That being said, it is important to note that these models, in some way, can be manipulated to output a probability.
For instance, Sklearn’s decision tree classifier does provide a predict_proba() method, as shown below:

This may appear a bit counterintuitive at first.
However, in this case, the model outputs the class probabilities by looking at the fraction of training class labels in a leaf node.

In other words, say a test instance reaches a specific leaf node for final classification. The model will calculate the probabilities as the fraction of training class labels in that leaf node.

Yet, these manipulations do not account for the “true” uncertainty in a prediction.
This is because the uncertainty is the same for all predictions that land in the same leaf node.
Therefore, it is always wise to choose probabilistic classifiers when uncertainty is paramount.
👉 Over to you: Can you add one more model for probabilistic and labeling models?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
About the probabilities computed from a decision tree you say: "Yet, these manipulations do not account for the “true” uncertainty in a prediction. This is because the uncertainty is the same for all predictions that land in the same leaf node." Can you explain this a bit further? What is the problem with this type of uncertainty?
Just to confirm XGBOOST and LightGBM are labelling models right? Can we say all ensemble based models are labelling models?